数据分析实战1——小费数据的数据分析
1.对原始小费数据初步分析
(1)加载数据
import numpy as np
import pandas as pd
fdata=pd.read_excel('./tips.xls')
display(fdata)运行结果如下:

(2)分析数据
a.查看数据的描述信息。
fdata.describe()运行结果如下:

b.修改列名为汉字,并显示前5行数据。
#修改列名为汉字。
fdata.rename(columns=({'total_bill':'消费总额','tip':'小费','sex':'性别','smoker':'是否抽烟','day':'星期','time':'聚餐时间段','size':'人数'}),inplace=True)
display(fdata.head())运行结果如下:
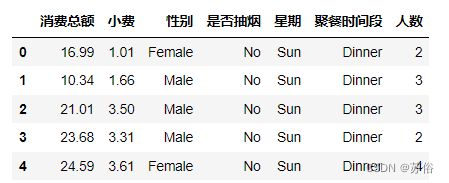
c.增加一列“人均消费”,并显示前5行数据。
fdata['人均消费']=round(fdata['消费总额']/fdata['人数'],2)
display(fdata.head())运行结果如下:

d.查询查询男性午餐人均消费大于10的数据。
# 方法1:
maledata=fdata[(fdata['性别']=='Male')&(fdata['聚餐时间段']=='Lunch')&(fdata['人均消费']> 10)]
# 方法2:
# fdata.query( '性别=="Male" & '聚餐时间段'=="Lunch" & 人均消费>10')
display(maledata)
maledata.describe()运行结果如下:

e. 查询女性午餐人均消费大于10的数据。
femaledata=fdata.query('性别=="Female"&聚餐时间段=="Lunch" & 人均消费>10')
display(femaledata)
femaledata.describe()运行结果如下:

从以上数据分析,可以看出男性顾客在午餐时间段的人均消费额比女性顾客高。
f.分析男性顾客和女性顾客谁人均消费水平更高。
fdata.groupby('性别')['人均消费'].mean()运行结果如下:
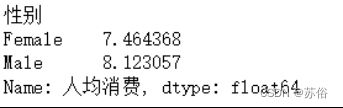
从以上数据分析,可以看出男性顾客的人均消费额比女性顾客多。
g.分析男性顾客和女性顾客谁更慷慨。
fdata.groupby('性别')['小费'].mean()运行结果如下:

从分析结果可以看出,男性顾客明显慷慨一些。
h.分析哪个聚餐时间生意更好。
fdata.groupby('聚餐时间段')[["小费","人均消费"]].mean()运行结果如下:

从以上数据分析,可以看出晚餐时间段的小费和人均消费水平均高于午餐时间段,晚餐时间段生意更好。
2.对随机修改后的小费数据进行数据预处理
(1)加载数据
加载待处理数据tips_mod.xls(见实验4附件),并显示前5行。
import pandas as pd
import numpy as np
fdata=pd.read_excel('./tips_mod.xls')
display(fdata)运行结果如下:

(2)预处理数据
a.查看数据的描述信息和缺失值信息。
print('规格大小如下:\n')
# 打印规格大小。
print(fdata.shape)
print('\n描述信息如下:')
# 打印描述信息。
print(fdata.describe())
print('\n缺失值信息如下:')
# 打印缺失值信息。
print(fdata.info())运行结果如下:

通过结果可以看出,共有244条记录,存在少量缺失数据。
b.修改拼写错误的字段值。
fdata.loc[fdata['time']=='Diner','time']='Dinner'
fdata.loc[fdata['time']=='Dier','time']='Dinner'
fdata['time'].unique()运行结果如下:
![]()
c.修改time列的数据为汉字。
fdata.loc[fdata['time']=='Dinner','time']='晚餐'
fdata.loc[fdata['time']=='Lunch','time']='午餐'
fdata['time'].unique()运行结果如下:
![]()
d.检测数据中的缺失值。
fdata.isnull().sum()运行结果如下:

e.删除一行内有两个缺失值的数据。
#删除一行内至少有两个缺失值(即一行内非空值数量小于6)的数据。
fdata.dropna(thresh=6,inplace=True)
fdata.isnull().sum()运行结果如下:

f.删除sex或time为空的行。
# 删除性别或者聚餐时间为空的行。
fdata.dropna(subset=['sex','time'],inplace=True)
fdata.isnull().sum()运行结果如下:

g.对剩余空缺的数值型数据用该列的均值替代。
fdata.fillna(fdata.mean(numeric_only=True),inplace=True)
fdata.isnull().sum()运行结果如下:

h.打印最新结果
display(fdata)运行结果如下:

i.修改sex列的数据为汉字。
fdata.loc[fdata['sex']=='Male','sex']='男'
fdata.loc[fdata['sex']=='Female','sex']='女'
fdata['sex'].unique()运行结果如下:
![]()
j.分析对比各个时间的客流量和销售额,并给出相应管理措施。
fdata.groupby(['time','sex','day'])[["total_bill","tip","size"]].mean()运行结果如下:
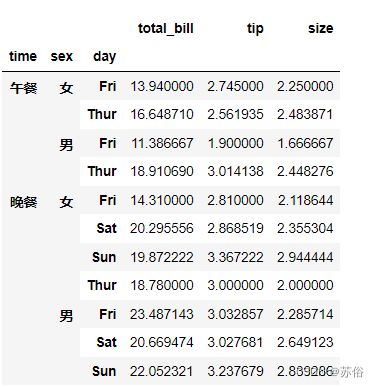
从以上数据分析,可以看出:
(1)晚餐时间段的消费总金额、小费和聚餐人数的水平均比午餐时间段高。
(2)男性顾客的消费总金额、小费的水平比女性顾客高。
(3)午餐聚会时间都在周五和周四,晚餐聚会时间在周四、周五、周六、周天。
(4)周末两天(周六和周天)的晚餐时间段是客流量最大的时间段,应加大人员配备和食材配备,以保证服务质量。
(5)每周的前三天(周一、周二和周三)是客流量最小的时间,应给出最大的优惠力度,吸引客源进店消费。
(6)每周的周四周五两天,聚餐的人气也比较旺,应适当加大优惠力度和宣传引流,最大化增大客流量。
数据文件和源码已上传资源,可免费下载。