机器学习:BN层介绍及深入理解

前言:BN在深度网络训练过程中是非常好用的trick,在笔试中也很常考,而之前只是大概知道它的作用,很多细节并不清楚,因此希望用这篇文章彻底解决揭开BN的面纱。
BN层的由来与概念
讲解BN之前,我们需要了解BN是怎么被提出的。在机器学习领域,数据分布是很重要的概念。如果训练集和测试集的分布很不相同,那么在训练集上训练好的模型,在测试集上应该不奏效(比如用ImageNet训练的分类网络去在灰度医学图像上finetune再测试,效果应该不好)。对于神经网络来说,如果每一层的数据分布都不一样,后一层的网络则需要去学习适应前一层的数据分布,这相当于去做了domain的adaptation,无疑增加了训练难度,尤其是网络越来越深的情况。
实际上,确实如此,不同层的输出的分布是有差异的。BN的那篇论文中指出,不同层的数据分布会往激活函数的上限或者下限偏移。论文称这种偏移为internal Covariate Shift,internal指的是网络内部。神经网络一旦训练起来,那么参数就要发生更新,**除了输入层的数据外(因为输入层数据,我们已经人为的为每个样本归一化),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。**以网络第二层为例:网络的第二层输入,是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变, 第一层输出变化了,势必会引起第二层输入分布的改变,模型拟合的效果就会变差,也会影响模型收敛的速度(例如我原本的参数是拟合分布A的,然后下一轮更新的时候,样本都是来自分布B的,对于这组参数来说,这些样本就会很陌生)
BN就是为了解决偏移的,解决的方式也很简单,就是让每一层的分布都normalize到标准高斯分布。(BN是根据划分数据的集合去做Normalization,不同的划分方式也就出现了不同的Normalization,如GN,LN,IN)
BN核心公式
I n p u t : B = { x 1... m } ; γ , β ( 这两个是可以训练的参数 ) O u t p u t : { y i = B N γ , β ( x i ) } μ B ← 1 m ∑ i = 1 m x i σ B 2 ← 1 m ∑ i = 1 m ( x i − μ B ) 2 x ~ i = x i − μ B σ B 2 + ε (分母加 ε 是为了防止方差为 0 ) y i = γ x ~ i + β Input:B=\{x_{1...m}\}; \gamma, \beta \quad (这两个是可以训练的参数) \\ Output : \{y_i = BN_{\gamma, \beta}(x_i)\} \\ \mu_{B} \leftarrow \frac{1}{m}\sum_{i=1}^{m}{x_i} \\ \sigma_B^2 \leftarrow \frac{1}{m}\sum_{i=1}^{m}{(x_i - \mu_B)^2} \\ \tilde{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \varepsilon}} \quad (分母加\varepsilon是为了防止方差为0)\\ y_i = \gamma \tilde{x}_i + \beta Input:B={x1...m};γ,β(这两个是可以训练的参数)Output:{yi=BNγ,β(xi)}μB←m1i=1∑mxiσB2←m1i=1∑m(xi−μB)2x~i=σB2+εxi−μB(分母加ε是为了防止方差为0)yi=γx~i+β
对上述公式的解释: B B B 即一个batch中的数据,先计算 B B B 的均值与方差,之后将 B B B 集合的均值、方差变换为0、1即标准正态分布,最后将 B B B 中的每个元素乘以 γ \gamma γ 再加上 β \beta β 然后输出, γ \gamma γ 和 β \beta β 是可训练的参数,这两个参数是BN层的精髓所在,为什么这么说呢?
和卷积层,激活层,全连接层一样,BN层也是属于网络中的一层。我们前面提到了,前面的层引起了数据分布的变化,这时候可能有一种思路是说:在每一层输入的时候,再加一个预处理就好。比如归一化到均值为0,方差为1,然后再输入进行学习。基本思路是这样的,然而实际上没有这么简单,如果我们只是使用简单的归一化方式:
x ~ i = x i − μ B σ B 2 + ε \tilde{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \varepsilon}} x~i=σB2+εxi−μB
对某一层的输入数据做归一化,然后送入网络的下一层,这样是会影响到本层网络所学习的特征的,比如网络中学习到的数据本来大部分分布在0的右边,经过RELU激活函数以后大部分会被激活,如果直接强制归一化,那么就会有大多数的数据无法激活了,这样学习到的特征不就被破坏掉了么?论文中对上面的方法做了一些改进:变换重构,引入了可以学习的参数 γ \gamma γ 和 β \beta β,这就是算法的关键之处(这两个希腊字母就是要学习的)。
y i = γ x ~ i + β y_i = \gamma \tilde{x}_i + \beta yi=γx~i+β
每个batch的每个通道都有这样的一对参数:(看完后面应该就可以理解这句话了)
γ = σ B 2 , β = μ B \gamma = \sqrt{\sigma_B^2} \quad, \quad \beta = \mu_B γ=σB2,β=μB
这样的时候可以恢复出原始的某一层学习到的特征的,因此我们引入这个可以学习的参数使得我们的网络可以恢复出原始网络所要学习的特征分布。
我们在一些源码中,可以看到带有BN的卷积层,bias设置为False,就是因为即便卷积之后加上了Bias,在BN中也是要减去的,所以加Bias带来的非线性就被BN一定程度上抵消了。
BN中的均值与方差通过哪些维度计算得到
神经网络中传递的张量数据,其维度通常记为[N, H, W, C],其中N是batch_size,H、W是行、列,C是通道数。那么上式中BN的输入集合 B B B 就是下图中蓝色的部分。

均值的计算,就是在一个批次内,将每个通道中的数字单独加起来,再除以 N ∗ H ∗ W N*H*W N∗H∗W 。举个栗子:该批次内有十张图片,每张图片有三个通道RGB,每张图片的高宽是 H 、 W H、W H、W 那么R通道的均值就是计算这十张图片R通道的像素数值总和再除以 10 ∗ H ∗ W 10*H*W 10∗H∗W ,其他通道类似,方差的计算也类似。
可训练参数 γ \gamma γ 和 β \beta β 的维度等于张量的通道数,在上述栗子中,RGB三个通道分别需要一个 γ \gamma γ 和 β \beta β,所以他们的维度为3。
也就是说在NHW维度做的均值,从而得到2C个训练参数。
训练与推理时BN中的均值和方差分别是多少
正确的答案是:
训练时:均值、方差分别是该批次内数据相应维度的均值与方差。
推理时:均值来说直接计算所有训练时batch的 μ B \mu_B μB 的平均值,而方差采用训练时每个batch的 σ B 2 \sigma_B^2 σB2 的无偏估计,公式如下:
E [ x ] ← E B [ μ B ] V a r [ x ] ← m m − 1 E B [ σ B 2 ] E[x] \leftarrow E_B[\mu_B] \\ Var[x] \leftarrow \frac{m}{m-1}E_B[\sigma_B^2] E[x]←EB[μB]Var[x]←m−1mEB[σB2]
但在实际实现中,如果训练几百万个Batch,那么是不是要将其均值方差全部储存,最后推理时再计算他们的均值作为推理时的均值和方差?这样显然太过笨拙,占用内存随着训练次数不断上升。为了避免该问题,后面代码实现部分使用了滑动平均,储存固定个数Batch的均值和方差,不断迭代更新推理时需要的 E [ x ] E[x] E[x] 和 V a r [ x ] Var[x] Var[x] 。
为了证明准确性,贴上原论文中的公式(这个图其实我都看不懂……符号好乱):

如上图第11行所示:最后测试阶段,BN采用的公式是:
y i = γ x ~ i + β = γ ( x i − μ B ) σ B 2 + ε + β = γ σ B 2 + ε ∗ x + ( β − γ μ B σ B 2 + ε ) 将其中的均值方差换为滑动平均即可 y = γ V a r [ x ] + ε ∗ x + ( β − γ E [ x ] V a r [ x ] + ε ) y_i = \gamma \tilde{x}_i + \beta= \frac{\gamma({x_i - \mu_B})}{\sqrt{\sigma_B^2 + \varepsilon}} + \beta= \frac{\gamma}{\sqrt{\sigma_B^2 + \varepsilon}}*x+(\beta - \frac{\gamma \mu_B}{\sqrt{\sigma_B^2+\varepsilon}})\\ 将其中的均值方差换为滑动平均即可\\ y = \frac{\gamma}{\sqrt{Var[x] + \varepsilon}}*x+(\beta - \frac{\gamma E[x]}{\sqrt{Var[x]+\varepsilon}}) yi=γx~i+β=σB2+εγ(xi−μB)+β=σB2+εγ∗x+(β−σB2+εγμB)将其中的均值方差换为滑动平均即可y=Var[x]+εγ∗x+(β−Var[x]+εγE[x])
测试阶段的 γ \gamma γ 和 β \beta β 是在网络训练阶段已经学习好了的,直接加载进来计算即可。
BN的优缺点
BN的好处
- 防止网络梯度消失:这个要结合sigmoid函数进行理解
- 加速训练,也允许更大的学习率:输出分布向着激活函数的上下限偏移,带来的问题就是梯度的降低,(比如说激活函数是sigmoid),通过normalization,数据在一个合适的分布空间,经过激活函数,仍然得到不错的梯度。梯度好了自然加速训练。
- 降低参数初始化敏感:以往模型需要设置一个不错的初始化才适合训练,加了BN就不用管这些了,现在初始化方法中随便选择一个用,训练得到的模型就能收敛。
原因:随着网络层数的增加,分布逐渐发生偏移,之所以收敛慢,是因为整体分布往非线性函数取值区间的上下限靠近。这会导致反向传播时梯度消失。BN就是通过规范化的手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值0方差1的标准正态分布,使得激活函数输入值落入非线性函数中比较敏感的区域。可以让梯度变大,学习收敛速度快,能大大加快收敛速度。 - 提高网络泛化能力防止过拟合:所以有了BN层,可以不再使用L2正则化和dropout。可以理解为在训练中,BN的使用使得一个mini-batch中的所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果。
面试解释:因为BN统计了一个batch内所有样本的信息,从而引入了一定的噪声,这个噪声也就起到了正则化的作用。 - 可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度)。
BN的缺点
局限1:如果Batch Size太小,则BN效果明显下降。
BN是严重依赖Mini-Batch中的训练实例的,如果Batch Size比较小则任务效果有明显的下降。那么多小算是太小呢?图10给出了在ImageNet数据集下做分类任务时,使用ResNet的时候模型性能随着BatchSize变化时的性能变化情况,可以看出当BatchSize小于8的时候开始对分类效果有明显负面影响。之所以会这样,是因为在小的BatchSize意味着数据样本少,因而得不到有效统计量,也就是说噪音太大。这个很好理解,这就类似于我们国家统计局在做年均收入调查的时候,正好把你和马云放到一个Batch里算平均收入,那么当你为下个月房租发愁之际,突然听到你所在组平均年薪1亿美金时,你是什么心情,那小Mini-Batch里其它训练实例就是啥心情。
局限2:对于有些像素级图片生成任务来说,BN效果不佳;
对于图片分类等任务,只要能够找出关键特征,就能正确分类,这算是一种粗粒度的任务,在这种情形下通常BN是有积极效果的。但是对于有些输入输出都是图片的像素级别图片生成任务,比如图片风格转换等应用场景,使用BN会带来负面效果,这很可能是因为在Mini-Batch内多张无关的图片之间计算统计量,弱化了单张图片本身特有的一些细节信息。
局限3:RNN等动态网络使用BN效果不佳,且使用起来不方便
对于RNN来说,尽管其结构看上去是个静态网络,但在实际运行展开时是个动态网络结构,因为输入的Sequence序列是不定长的,这源自同一个Mini-Batch中的训练实例有长有短。对于类似RNN这种动态网络结构,BN使用起来不方便,因为要应用BN,那么RNN的每个时间步需要维护各自的统计量,而Mini-Batch中的训练实例长短不一,这意味着RNN不同时间步的隐层会看到不同数量的输入数据,而这会给BN的正确使用带来问题。假设Mini-Batch中只有个别特别长的例子,那么对较深时间步深度的RNN网络隐层来说,其统计量不方便统计而且其统计有效性也非常值得怀疑。另外,如果在推理阶段遇到长度特别长的例子,也许根本在训练阶段都无法获得深层网络的统计量。综上,在RNN这种动态网络中使用BN很不方便,而且很多改进版本的BN应用在RNN效果也一般。
而LN关注句子内部的信息,不像关注句子间的无关信息,可以LN更加适合RNN。
代码实现BN层
完整代码见参考资料3
def batch_norm(is_training, X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 判断当前模式是训练模式还是推理模式
if not is_training:
# 如果是在推理模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要保持X的形状以便后面可以做广播运算
# torch.Tensor 高维矩阵的表示: (nSample)x C x H x W,所以对C维度外的维度求均值
mean = X.mean(dim=0, keepdims=True).mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
var = ((X - mean) ** 2).mean(dim=0, keepdims=True).mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
# 训练模式下用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 拉伸和偏移(变换重构)
return Y, moving_mean, moving_var
class BatchNorm(nn.Module):
def __init__(self, num_features, num_dims): # num_features就是通道数
super(BatchNorm, self).__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成0和1
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 不参与求梯度和迭代的变量,全在内存上初始化成0
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.zeros(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var, Module实例的traning属性默认为true, 调用.eval()后设成false
Y, self.moving_mean, self.moving_var = batch_norm(self.training,
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
其他的几种类似BN结构
当batch size越小,BN的表现效果也越不好,因为计算过程中所得到的均值和方差不能代表全局
其实深度学习中有挺多种归一化的方法,除BN外,还有LN、IN、GN和SN四种,其他四种大致了解下就行了,大同小异,这里推荐篇博客:深度学习中的五种归一化(BN、LN、IN、GN和SN)方法简介
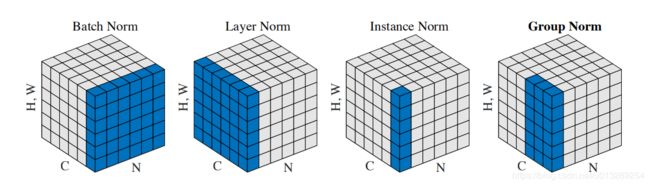
对于输入特征图(NCHW)
BN在C通道归一化:所有batch的同一特征图归一化(在NHW通道求均值,得到2C个参数)——c个均值方差**(gamma是c个)**
LN在N通道归一化:所有特征图在同一batch归一化,不受batchsize影响(在CHW求均值,得到2个参数)
IN在CN通道分别归一化:不同batch的不同特征图归一化,也就是每张特征图单独归一化(在HW求均值,得到2C个参数)
GN处于LN和IN之间:部分特征图在同一batch归一化(在HW和部分C求均值,得到大于2小于2C个参数)——如果分成Group组,那么就有 2 ∗ g r o u p 2*group 2∗group个均值方差(gamma是c个)
以上所有变种,他的训练参数 γ β \gamma \beta γβ都是2c个。
扩展
参数初始化
一般初始化方法为 γ = 1 , β = 0 \gamma=1,\beta=0 γ=1,β=0
对于resnet,将残差块后面接的 γ = 0 \gamma=0 γ=0,在初始化阶段可以简化网络,更快训练。
使用方法
- 训练阶段BN中的is_training设为True
- 模型保存时把BN中的参数也一并保存,主要是moving_mean和moving_variance相关的参数名称
- 预测阶段BN设为False
小技巧
- 如果你的待预测数据量比较大,每次都是一大批量的数据同时预测,可以设为训练模型,此时会直接从待预测数据计算其对应的均值和方差。
- 如果是单个数据或数据分布差异不大,建议在训练阶段保存BN 层的参数,特别是移动均值和方差,在预测阶段设为预测模型,此时会使用训练阶段的mean和var。
原因说明
- 若在预测阶段BN的is_training设为True
此时当改变需要预测数据的batchsize时预测的label也跟着变,因为使用的是该batch中的数据进行标准化操作,当预测的batchsize越大,假如你的预测数据集和训练数据集的分布一致,结果就越接近于训练结果,但如果batchsize=1,那BN层就发挥不了作用,结果很难看。 - 若在预测阶段BN的is_training设为False
那如果在预测时is_traning=false呢,但BN层的参数没有从训练中保存,那使用的就是随机初始化的参数,结果不堪想象。
GN(凯明初始化)
为什么提出GN(BN的缺点)
BN是在batch维度进行的归一化,严重依赖batchsize的大小,如果bs过小,BN的统计信息不准确,就会导致最终模型的效果变差。所以使用BN需要较大的bs,但这样显存就会不足。
另外,预测时使用的是训练集的均值和方差,当训练数据和测试数据分布不一致时,效果会变差。
GN优点
- 如果我们将组号设置为G = 1,则GN变为LN 。LN假设层中的所有通道都做出“类似的贡献”。GN比LN受限制更少,因为假设每组通道(而不是所有通道)都受共享均值和方差的影响; 该模型仍然具有为每个群体学习不同分布的灵活性。这导致GN相对于LN的代表能力提高。
(LN直接认为所有通道的共享方差和均值是相同的,但是GN是将这些通道又分为了多个组(多个群体),所以GN就可以为每个组学习了不同分布信息,相比LN更加灵活。) - 如果我们将组号设置为G = C(即每组一个通道),则GN变为IN。 但是IN只能依靠空间维度来计算均值和方差,并且错过了利用信道依赖的机会。
GN分组的原因
受传统图像处理方法的启发。
比如HOG、SIFT等,都会对图像进行分组然后归一化:HOG会统计一个cell的梯度直方图;多个cell组成block,然后block进行归一化,这里的block就等于一个group,即分group进行归一化。
导致分组(group)的因素有很多,比如频率、形状、亮度和纹理等,HOG特征根据orientation分组,也就是每组提取的特征可能很相似,但是不同组提取的特征不相同,所以分组归一化效果更好。
GN的代码实现
class GroupNorm(nn.Module):
def __init__(self, num_features, num_groups=32, eps=1e-5):
super(GroupNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(1, num_features, 1, 1)) # 这里一直都是1,c,1,1的维度
self.beta = nn.Parameter(torch.ones(1, num_features, 1, 1))
self.num_groups = num_groups
self.eps = eps
def forward(self, x)
N, C, H, W = x.shape
x = x.reshape(N, G, C//G, H, W) # 分成G组
mean = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True).mean(dim=4, keepdims=True)
var = ((x - mean)**2).mean(dim=2, keepdims=True).mean(dim=3, keepdims=True).mean(dim=4, keepdims=True)
x = (x - mean)/torch.sqrt(var+eps)
x = x.reshape(N, C, H, W)
y = x * self.gamma + self.beta
return y
参考链接
深度学习之17——归一化(BN+LN+IN+GN)
参考资料
1、六问透彻理解BN(Batch Normalization)
2、神经网络之BN层
3、BN层pytorch实现
4、BatchNorm的个人解读和Pytorch中BN的源码解析
5、对于BN层的理解