2.13学习总结
1.出差(Bleeman—ford)(spfa)
(dijkstra)
2.最小生成树(prim)(Kruskal)
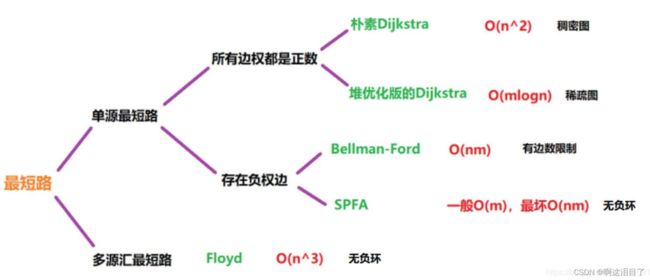
最短路问题:
出差https://www.luogu.com.cn/problem/P8802
题目描述
AA 国有 �N 个城市,编号为 1…�1…N 小明是编号为 11 的城市中一家公司的员工,今天突然接到了上级通知需要去编号为 �N 的城市出差。
由于疫情原因,很多直达的交通方式暂时关闭,小明无法乘坐飞机直接从城市 11 到达城市 �N,需要通过其他城市进行陆路交通中转。小明通过交通信息网,查询到了 �M 条城市之间仍然还开通的路线信息以及每一条路线需要花费的时间。
同样由于疫情原因,小明到达一个城市后需要隔离观察一段时间才能离开该城市前往其他城市。通过网络,小明也查询到了各个城市的隔离信息。(由于小明之前在城市 11,因此可以直接离开城市 11,不需要隔离)
由于上级要求,小明希望能够尽快赶到城市 NN, 因此他求助于你,希望你能帮他规划一条路线,能够在最短时间内到达城市 �N 。
输入格式
第 11 行:两个正整数 �,�N,M 表示 A 国的城市数量, �M 表示末关闭的路线数量。
第 22 行: �N 个正整数,第 �i 个整数 ��Ci 表示到达编号为 ii 的城市后需要隔离的时间。
第 3…�+23…M+2 行: 每行 33 个正整数, �,�,�u,v,c, 表示有一条城市 �u 到城市 �v 的双向路线仍然开通着,通过该路线的时间为 �c。
输出格式
第 11 行:11 个正整数,表示小明从城市 11 出发到达城市 �N 的最短时间。(到达城市 �N,不需要计算城市 �N 的隔离时间)
输入输出样例
输入 #1复制
4 4
5 7 3 4
1 2 4
1 3 5
2 4 3
3 4 5输出 #1复制
13
说明/提示
【样例说明】
【评测用例规模与约定】
对于 100%100% 的数据, 1≤�≤1000,1≤�≤10000,1≤��≤200,1≤�,�≤1≤N≤1000,1≤M≤10000,1≤Ci≤200,1≤u,v≤ �,1≤�≤1000N,1≤c≤1000

Dijkstra算法:
主要是利用邻接表和优先队列实现,总复杂度是O(nlongn)
实现:起点先入队,然后找到所有的邻居入队(除了已经标记了找到最短路的),找后序点的时候,优先选择路径短的点(用优先队列实现)


#include
using namespace std;
#define lowbit(x) (x& - (x))
#define int long long
#define INF 0x3f3f3f3f
const int N=20010;
int n,m;
int t[N],dist[N];
struct edge{
int to;
int w;
edge(int a,int b) {
to=a;
w=b;
}
};
vectore[N];
struct node{
int id;
int n_dis;
node(int aa,int bb){
id=aa;
n_dis=bb;
}
bool operator < (const node& a)const{
return n_dis > a.n_dis;
}
};
void dijkstra(){
bool done[N]; //标记数组,用于确定是否该节点找到最短路径
for (int i=1;i<=n;++i){
done[i]=false;
dist[i]=INF;
}
dist[1]=0; //初始化,起点到起点的距离为0
priority_queueq;
q.push(node(1,dist[1]));
while (!q.empty()){
node p=q.top(); q.pop();
if (done[p.id]) continue;
done[p.id]=true;
for (int i=0;i p.n_dis+w+res){ //当前节点y到起点的最短路径大于路过p点到y点的路径
dist[y]=p.n_dis+w+res;
q.push(node(y,dist[y]));
}
}
}
}
signed main(){
cin>>n>>m;
for (int i=1;i<=n;++i) cin>>t[i];
for (int i=0;i>a>>b>>c;
e[a].push_back(edge(b,c));
e[b].push_back(edge(a,c));
}
dijkstra();
cout< Bleeman—ford算法:

复杂度的是O(n^2),相比与floyd算法,该算法主要是找相邻节点,每一轮操作会找到一个最短路径的点,由于有n个点,所以需要进行n次,然后每次需要遍历所有的边。
#include
using namespace std;
#define lowbit(x) (x& - (x))
#define int long long
int INF=0x3f3f3f3f;
const int N=20010;
int t[N],dist[N];
struct edge{
int a;
int b;
int c;
}e[N];
signed main(){
int n,m;
cin>>n>>m;
for (int i=1;i<=n;++i) cin>>t[i];
for (int i=0;i>a>>b>>c;
e[i].a=a,e[i].b=b,e[i].c=c;
e[i+m].a=b,e[i+m].b=a,e[i+m].c=c;
}
memset(dist,INF,sizeof(dist));
dist[1]=0;
for (int k=1;k<=n;++k){
for (int i=0;i<2*m;++i){ //双向的
int u=e[i].a,v=e[i].b;
int res=t[v];
if (v==n)res=0;
dist[v]=min(dist[v],dist[u]+res+e[i].c);
}
}
cout< SPFA算法:算法复杂度和Dijkstra一样,但是在最坏的情况下会达到O(n^2)是Bleeman—ford的优化,只更新上一轮有变化的点,不更新所有的点

#include
using namespace std;
#define lowbit(x) (x& - (x))
#define int long long
#define INF 0x3f3f3f3f
const int N=20010;
int n,m;
int t[N],dist[N];
struct edge{
int to;
int w;
edge(int a,int b) {
to=a;
w=b;
}
};
vectore[N];
int inq[N]; //判断是否在队列内
void spfa(){
memset(dist,INF,sizeof(dist));
dist[1]=0;
queueq; //队列内存放的是节点号
q.push(1);
inq[1]=1;
while (!q.empty()){
int u=q.front(); q.pop();
inq[u]=0;
for (int i=0;ires+dist[u]+w){ //只处理更新的节点
dist[v] =dist[u]+w+res;
if (!inq[v]){
inq[v]=1;
q.push(v);
}
}
}
}
}
signed main(){
cin>>n>>m;
for (int i=1;i<=n;++i) cin>>t[i];
for (int i=0;i>a>>b>>c;
e[a].push_back(edge(b,c));
e[b].push_back(edge(a,c));
}
spfa();
cout< 最小生成树:
最小生成树https://www.luogu.com.cn/problem/P3366
题目描述
如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出
orz。输入格式
第一行包含两个整数 �,�N,M,表示该图共有 �N 个结点和 �M 条无向边。
接下来 �M 行每行包含三个整数 ��,��,��Xi,Yi,Zi,表示有一条长度为 ��Zi 的无向边连接结点 ��,��Xi,Yi。
输出格式
如果该图连通,则输出一个整数表示最小生成树的各边的长度之和。如果该图不连通则输出
orz。输入输出样例
输入 #1复制
4 5
1 2 2
1 3 2
1 4 3
2 3 4
3 4 3输出 #1复制
7
说明/提示
数据规模:
对于 20%20% 的数据,�≤5N≤5,�≤20M≤20。
对于 40%40% 的数据,�≤50N≤50,�≤2500M≤2500。
对于 70%70% 的数据,�≤500N≤500,�≤104M≤104。
对于 100%100% 的数据:1≤�≤50001≤N≤5000,1≤�≤2×1051≤M≤2×105,1≤��≤1041≤Zi≤104。
样例解释:
所以最小生成树的总边权为 2+2+3=72+2+3=7。
Prim算法和Kruskal算法的异同
同:都是利用贪心的方式
异:
Prim算法原理:“最小的邻居一定在树上”,从任意一个点u开始,把距离最近的v加入最小生成树中,下一步把距离{u,v}最近的w加入到树中,并且在生成的过程中保证不会生成环路,直到所有的点都在树上

代码与Dijkstra类似
#include
using namespace std;
#define lowbit(x) (x& - (x))
#define int long long
#define INF 0x3f3f3f3f
const int N=4e5+5;
struct edge{
int to;
int w;
edge(int a,int b){
to=a;
w=b;
}
};
vectore[N];
int n,m,ans;
struct node{
int id;
int n_dis; //区别在于Dijkstra这里存的是该节点到起点的最短距离,而Prim中存的是边长(该节点与其他邻居节点的最短边长)
node(int a,int b): id(a),n_dis(b){}
bool operator < (const node &a)const{
return n_dis>a.n_dis;
}
};
priority_queueq;
bool done[N];
int dis[N];
void prim(){
for (int i=1;i<=n;++i){
done[i]=false;
dis[i]=INF;
}
dis[1]=0;
q.push(node(1,dis[1]));
while (!q.empty()){
node p=q.top(); q.pop();
if (done[p.id]) continue;
done[p.id]=true;
ans+=dis[p.id];
for (int i=0;i w){
dis[v]=w;
q.push(node(v,w));
}
}
}
for (int i=1;i<=n;++i){
if (!done[i]){
cout<<"orz";
return;
}
}
cout<>n>>m;
for (int i=0;i>a>>b>>c;
e[a].push_back(edge(b,c));
e[b].push_back(edge(a,c));
}
prim();
} Kruskal算法原理:
“最短的边一定在最小生成树上”,从最短的边开始操作,以此加到树中。
算法步骤:先对所有的节点关系进行排序,然后依次把最小的边放到最小生成树中,其中对于是否成环(连通性问题)的判定,可以用并查集实现

#include
using namespace std;
#define lowbit(x) (x& - (x))
#define int long long
#define INF 0x3f3f3f3f
const int N=4e5+5;
int f[N];
struct edge{
int from;
int to;
int dis;
};
edge e[N];
bool cmp(const edge& a,const edge& b){
return a.dis>n>>m;
for (int i=1;i<=m;++i){
cin>>e[i].from>>e[i].to>>e[i].dis;
}
Kruskal();
}