生成对抗网络 Generative Adversarial Nets(GAN)详解
生成对抗网络 Generative Adversarial Nets(GAN)详解
近几年的很多算法创新,尤其是生成方面的task,很大一部分的文章都是结合GAN来完成的,比如,图像生成、图像修复、风格迁移等等。今天主要聊一聊GAN的原理和推导。
github: http://www.github.com/goodfeli/adversarial
论文: https://arxiv.org/abs/1406.2661
背景介绍
在GAN算法出来之前,关于生成的task表现一直都不太好,因为之前的方法由于在最大似然估计和相关策略中出现的许多棘手的概率计算难以近似。而GAN呢,直接绕过了这些问题,用两个对抗的网络对数据进行生成对抗学习,通过零和游戏的形式来直接用网络来拟合数据的分布,从而对数据进行生成。(统计学里,任何数据都可以看成分布,任何数据都是同不同的分布中进行采样得到)
零和游戏的概念主要出现在博弈论里面,核心思想就是,两个玩家进行对抗游戏,最后会陷入一个那纳什均衡的状态。什么是纳什均衡?就是说最后两个玩家,他们都会选择最优的策略进行游戏,但是当两个玩家只要有一个人的决策从这个“最优决策”里跳出来,那么他就得不到最多的好处。通过这种方式,实现最终的平衡。而这一思想也深深的渗透到这个算法之中。
这两个网络,一个是生成器(generator)一个是判别器(discriminator),生成器G的角色就是要学习到数据的分布,能够实现生成以假乱真的数据。而鉴别器D的目的就是要鉴别数据的来源是真实的样本分布还是通过生成得到的。G和D之间的对抗,主要是:1.G想要骗过D,就是让D分辨不出来这个数据是从真实样本里来的还是从G生成的;2.D的目标就是分辨这个数据到底是G生成的还是真实的样本。
目标函数
生成对抗网络的核心就是极小极大游戏( two-player minimax game),这里G是生成器,生成假数据,D是鉴别器,可以理解为二分类的分类器(当然后面有很多变体,这里不讨论),对应的目标函数如下:
min G max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min _{G} \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))] minGmaxDV(D,G)=Ex∼pdata (x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
E x ∼ p data ( x ) [ log D ( x ) ] \mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})] Ex∼pdata (x)[logD(x)] 的意思就是对真实的数据分布进行采样,然后求函数 log D ( x ) \log D(\boldsymbol{x}) logD(x)的期望。
E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))] Ez∼pz(z)[log(1−D(G(z)))]同理,从高斯噪声中进行采样,并且求 log ( 1 − D ( G ( z ) ) ) \log (1-D(G(\boldsymbol{z}))) log(1−D(G(z)))的期望。
整个目标函数是通过交替迭代优化的形式,来对G和D进行更新,很像就是两个人下棋一样,你一下我一下。这样想就会比较好理解。
这里首先更新D,所以我们将G的参数都看成常数,那么目标函数就变成:
max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))] maxDV(D,G)=Ex∼pdata (x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))],
目的是优化能够让这个目标函数最大化的D的参数,所以是 max D \max _{D} maxD。那既然是max这个目标函数,那么我们就可以知道 D ( x ) D(\boldsymbol{x}) D(x)越接近1越好,对应的 D ( G ( z ) ) D(G(\boldsymbol{z})) D(G(z))就是越接近0越好。那么咱就可以理解了,这个时候G是不动的,看成常数,对应的就是更新D的参数,D呢就是要分出真实数据和生成的数据,分的越开越好。
然后我们再更新G,那么对应的目标函数,现在变成这样:
min G V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min _{G} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))] minGV(D,G)=Ex∼pdata (x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
这里同样的,就把D看成常数,咱只更新G的参数,所以这回G是主角。这个目标函数就是说优化出最小化目标函数下,对应G的参数。由于D在这是常数,所以咱就把前面半个公式撇了,可得:
min G V ( D , G ) = E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min _{G} V(D, G)=\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))] minGV(D,G)=Ez∼pz(z)[log(1−D(G(z)))]
为了最小化这个目标函数,这个时候,G就要优化自己,让 G ( z ) G(\boldsymbol{z}) G(z)的生成结果尽可能的得到较高的分数,及 D ( G ( z ) ) D(G(\boldsymbol{z})) D(G(z))越接近1越好,所以对应的你会发现 log ( 1 − D ( G ( z ) ) ) \log (1-D(G(\boldsymbol{z}))) log(1−D(G(z)))被最小化,如果 D ( G ( z ) ) D(G(\boldsymbol{z})) D(G(z))趋近于1。
然后两个模型继续循环往复迭代,你一下,我一下…
那么如果是这样训练下来,这个过程中他们的分布是怎样变化的呢?
理想状态下,他们的关系如下: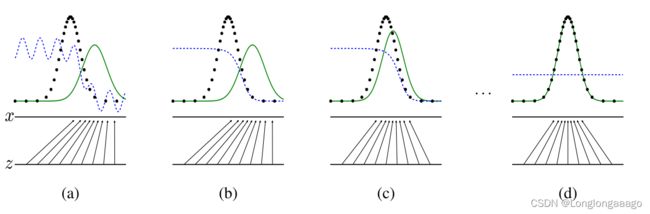
这里直接放了论文里的图, z \boldsymbol{z} z是高斯噪声的域domain, x \boldsymbol{x} x是真实样本的域。黑色的点表示真实样本的分布 p x p_{\boldsymbol{x}} px,蓝色的点表示分类器分类的表现;绿色的线表示生成数据的分布 p g p_{\boldsymbol{g}} pg,由噪声 z \boldsymbol{z} z通过 x = G ( z ) \boldsymbol{x}=G(\boldsymbol{z}) x=G(z)映射而来。(a)一开始分类器的表现,好像能够大概分开两个分布的样子。(b)对D进行优化,那么D达到了最优的分类状态 D ∗ ( x ) = p data ( x ) p data ( x ) + p g ( x ) D^{*}(\boldsymbol{x})=\frac{p_{\text {data }}(\boldsymbol{x})}{p_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})} D∗(x)=pdata (x)+pg(x)pdata (x).(c)这个时候G通过D的参数,进一步对自身优化,然后往真实样本进行靠近。(d)最终,生成模型生成的数据和真实样本一致,鉴别器D无法准确划分, D ∗ ( x ) = 1 2 D^{*}(\boldsymbol{x})=\frac{1}{2} D∗(x)=21.
训练伪代码

这里的伪代码已经在目标函数上进行了解释,主要这里更加详细,实际上就是目标函数部分解释的内容, ∇ θ d \nabla_{\theta_{d}} ∇θd就是对应鉴别器参数的梯度,这里用随机梯度下降法对模型参数进行更新,根据目标函数。 ∇ θ g \nabla_{\theta_{g}} ∇θg同理,是生成器G的参数梯度,结合上述目标函数 进行理解。
理论推导
咱这里直接顺着论文的顺序,进行进一步的梳理。首先是上面提到的,为什么当G固定的时候,最优的D应该是如下形式:
D G ∗ ( x ) = p data ( x ) p data ( x ) + p g ( x ) D_{G}^{*}(\boldsymbol{x})=\frac{p_{\text {data }}(\boldsymbol{x})}{p_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})} DG∗(x)=pdata (x)+pg(x)pdata (x)
论文也给出了对应的证明,这里着重给出对应的解释:
首先我们回看目标函数,求期望实际上也可以写成这种积分的形式:
V ( G , D ) = ∫ x p data ( x ) log ( D ( x ) ) d x + ∫ z p z ( z ) log ( 1 − D ( g ( z ) ) ) d z = ∫ x p data ( x ) log ( D ( x ) ) + p g ( x ) log ( 1 − D ( x ) ) d x \begin{aligned} V(G, D) &=\int_{\boldsymbol{x}} p_{\text {data }}(\boldsymbol{x}) \log (D(\boldsymbol{x})) d x+\int_{z} p_{\boldsymbol{z}}(\boldsymbol{z}) \log (1-D(g(\boldsymbol{z}))) d z \\ &=\int_{\boldsymbol{x}} p_{\text {data }}(\boldsymbol{x}) \log (D(\boldsymbol{x}))+p_{g}(\boldsymbol{x}) \log (1-D(\boldsymbol{x})) d x \end{aligned} V(G,D)=∫xpdata (x)log(D(x))dx+∫zpz(z)log(1−D(g(z)))dz=∫xpdata (x)log(D(x))+pg(x)log(1−D(x))dx
这里可以看到后半部分稍稍改动了一下,就是说直接将 x = g ( z ) x=g(\boldsymbol{z}) x=g(z)进行替代,对 p z p_{\boldsymbol{z}} pz进行采样等价于对 x \boldsymbol{x} x进行采样,所以就可以写成下面的式子,这里需要注意的是我们并不知道 p g p_{\boldsymbol{g}} pg和 p d a t a p_{\boldsymbol{data}} pdata的真实分布。不过我们能够知道 p g p_{\boldsymbol{g}} pg和 p d a t a p_{\boldsymbol{data}} pdata都是属于[0,1]之间的值,我们要求的就是 D ( x ) D(\boldsymbol{x}) D(x)的值,这个公式下,我们将其替换成如下形式:
f ( y ) = a log ( y ) + b log ( 1 − y ) f(y) = a \log (y)+b \log (1-y) f(y)=alog(y)+blog(1−y)
我们把 a = p d a t a , b = p g , y = D ( x ) a=p_{data},b=p_{g},y=D(x) a=pdata,b=pg,y=D(x),然后这里就变成关于 y y y的一个函数。然后我们要记得的是,在G固定的时候,为了求得最大化下的D的参数,所以就是最大化这个 f ( y ) f(y) f(y)。可以知道这个 f ( y ) f(y) f(y)是一个凸函数:
f ′ ( y ) = a y − b 1 − y f^{\prime}(y)=\frac{a}{y}-\frac{b}{1-y} f′(y)=ya−1−yb
f ′ ′ ( y ) = − a y 2 − b ( 1 − y ) 2 ≤ 0 f^{\prime\prime}(y)=-\frac{a}{y^{2}}-\frac{b}{(1-y)^{2}} \leq 0 f′′(y)=−y2a−(1−y)2b≤0
有个定理就是说,如果 f ′ ′ ( y ) f^{\prime\prime}(y) f′′(y)是正定矩阵,那么他就一定是凸函数。这里就是把向量简化成了标量。注意因为我们这里是求极大值,加上一个负号就是求极小,这个二阶导加一个负号就是正定矩阵(原本是负定)。说了那么多直接画个图好了:

这里可以看到假设 a = 0.8 , b = 1 a=0.8,b=1 a=0.8,b=1出来的图就是这副样子。
令 f ′ ( y ) = 0 f^{\prime}(y)=0 f′(y)=0,可得 y = a a + b y=\frac{a}{a+b} y=a+ba,相当于极值就是这个。这里就是说明了当给定任意的G,在这一步最优的D的最优解就应该是 y = a a + b y=\frac{a}{a+b} y=a+ba,即 D ( x ) = p d a t a p d a t a + p g D(x)=\frac{p_{data}}{p_{data}+p_{g}} D(x)=pdata+pgpdata.
好的,这里已经证明在优化D的时候,D应该是什么样子,接着我们再看看如果是再最小化目标函数是,固定D的时候,G应该是多少呢?先给出公式
C ( G ) = max D V ( G , D ) = E x ∼ p data [ log D G ∗ ( x ) ] + E z ∼ p z [ log ( 1 − D G ∗ ( G ( z ) ) ) ] = E x ∼ p data [ log D G ∗ ( x ) ] + E x ∼ p g [ log ( 1 − D G ∗ ( x ) ) ] = E x ∼ p data [ log p data ( x ) P data ( x ) + p g ( x ) ] + E x ∼ p g [ log p g ( x ) p data ( x ) + p g ( x ) ] \begin{aligned} C(G) &=\max _{D} V(G, D) \\ &=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}}\left[\log D_{G}^{*}(\boldsymbol{x})\right]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}}\left[\log \left(1-D_{G}^{*}(G(\boldsymbol{z}))\right)\right] \\ &=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}}\left[\log D_{G}^{*}(\boldsymbol{x})\right]+\mathbb{E}_{\boldsymbol{x} \sim p_{g}}\left[\log \left(1-D_{G}^{*}(\boldsymbol{x})\right)\right] \\ &=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}}\left[\log \frac{p_{\text {data }}(\boldsymbol{x})}{P_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}\right]+\mathbb{E}_{\boldsymbol{x} \sim p_{g}}\left[\log \frac{p_{g}(\boldsymbol{x})}{p_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}\right] \end{aligned} C(G)=DmaxV(G,D)=Ex∼pdata [logDG∗(x)]+Ez∼pz[log(1−DG∗(G(z)))]=Ex∼pdata [logDG∗(x)]+Ex∼pg[log(1−DG∗(x))]=Ex∼pdata [logPdata (x)+pg(x)pdata (x)]+Ex∼pg[logpdata (x)+pg(x)pg(x)]
这里公式的意思就是假定 max D V ( G , D ) \max _{D} V(G, D) maxDV(G,D)已经算完了,那么接下来要继续最小化 C ( G ) C(G) C(G),G的应该是什么样子的呢?
上面的公式已经将 D G ∗ ( x ) D_{G}^{*}(\boldsymbol{x}) DG∗(x)给带掉了,就是假定我们已经优化过了D,直接将上面的结果带入就可以得到最后一条公式
C ( G ) = E x ∼ p data [ log p data ( x ) P data ( x ) + p g ( x ) ] + E x ∼ p g [ log p g ( x ) p data ( x ) + p g ( x ) ] C(G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}}\left[\log \frac{p_{\text {data }}(\boldsymbol{x})}{P_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}\right]+\mathbb{E}_{\boldsymbol{x} \sim p_{g}}\left[\log \frac{p_{g}(\boldsymbol{x})}{p_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}\right] C(G)=Ex∼pdata [logPdata (x)+pg(x)pdata (x)]+Ex∼pg[logpdata (x)+pg(x)pg(x)]
咱现在就是要最小化这个公式(优化G),这里再把它写成积分的形式:
C ( G ) = ∫ x p data ( x ) log p data ( x ) P data ( x ) + p g ( x ) + ∫ x p g ( x ) log p data ( x ) P data ( x ) + p g ( x ) d x C(G)=\int_{\boldsymbol{x}} p_{\text {data }}(\boldsymbol{x}) \log \frac{p_{\text {data }}(\boldsymbol{x})}{P_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}+\int_{\boldsymbol{x}}p_{g}(\boldsymbol{x}) \log \frac{p_{\text {data }}(\boldsymbol{x})}{P_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})} d x C(G)=∫xpdata (x)logPdata (x)+pg(x)pdata (x)+∫xpg(x)logPdata (x)+pg(x)pdata (x)dx 因为 P data ( x ) + p g ( x ) {P_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})} Pdata (x)+pg(x)并不是一个分布,求积分=2,所以这里要改成如下形式,才能套到KL散度的公式中:
C ( G ) = ∫ x p data ( x ) log p data ( x ) 1 2 ( P data ( x ) + p g ( x ) ) 1 2 + ∫ x p g ( x ) log p data ( x ) 1 2 ( P data ( x ) + p g ( x ) ) 1 2 d x C(G)=\int_{\boldsymbol{x}} p_{\text {data }}(\boldsymbol{x}) \log \frac{p_{\text {data }}(\boldsymbol{x})}{\frac{1}{2}(P_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x}))}\frac{1}{2}+\int_{\boldsymbol{x}}p_{g}(\boldsymbol{x}) \log \frac{p_{\text {data }}(\boldsymbol{x})}{\frac{1}{2}(P_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x}))}\frac{1}{2} d x C(G)=∫xpdata (x)log21(Pdata (x)+pg(x))pdata (x)21+∫xpg(x)log21(Pdata (x)+pg(x))pdata (x)21dx 然后把 1 2 \frac{1}{2} 21提出来:
C ( G ) = − log ( 4 ) + K L ( p data ∥ p data + p g 2 ) + K L ( p g ∥ p data + p g 2 ) C(G)=-\log (4)+K L\left(p_{\text {data }} \| \frac{p_{\text {data }}+p_{g}}{2}\right)+K L\left(p_{g} \| \frac{p_{\text {data }}+p_{g}}{2}\right) C(G)=−log(4)+KL(pdata ∥2pdata +pg)+KL(pg∥2pdata +pg)这里就可以看到两个KL散度,KL散度是大于等于0的,只有当两个分布完全一样的时候,KL散度才等于0。这里又可以进一步转化变成对称的JS散度:
C ( G ) = − log ( 4 ) + 2 ⋅ J S D ( p data ∥ p g ) C(G)=-\log (4)+2 \cdot J S D\left(p_{\text {data }} \| p_{g}\right) C(G)=−log(4)+2⋅JSD(pdata ∥pg)
只有当 p d a t a = p g p_{data}=p_{g} pdata=pg的时候,我们才能得到这个式子的最小化结果就是 − log ( 4 ) -\log (4) −log(4)。
所以可以看到最终这个目标函数,能够让G不断拟合分布,使得生成的数据的分布接近真实样本的分布。
当然GAN现在发展已经好几年了,已经有很多优化的方法被提出,下次再讨论~
 如果觉得不错,记得关注哟!一起来学习深度学习,机器学习等前沿算法!!
如果觉得不错,记得关注哟!一起来学习深度学习,机器学习等前沿算法!!
转载请注明出处,尊重劳动成果,维护美好社区谢谢!