Prompt Tuning:深度解读一种新的微调范式
阅读该博客,您将系统地掌握如下知识点:
-
什么是预训练语言模型?
-
什么是prompt?为什么要引入prompt?相比传统fine-tuning有什么优势?
-
自20年底开始,prompt的发展历程,哪些经典的代表方法?
-
面向不同种类NLP任务,prompt如何选择和设计?
-
面向超大规模模型,如何借助prompt进行参数有效性训练?
-
面向GPT3,什么是In-Context Learning?什么是Chain-Of-Thought?
-
面向黑盒模型,如何使用prompt?
-
ChatGPT里有哪些prompt技术?
-
未来prompt的发展与研究前景
Prompt的由浅入深的理解:
-
1级:Prompt是一种对任务的指令;
-
2级:Prompt是一种对预训练目标的复用;
-
3级:Prompt本质是参数有效性训练;
热点预览
预训练语言模型的发展历程

截止23年3月底,语言模型发展走过了三个阶段:
-
第一阶段 :设计一系列的自监督训练目标(MLM、NSP等),设计新颖的模型架构(Transformer),遵循Pre-training和Fine-tuning范式。典型代表是BERT、GPT、XLNet等;
-
第二阶段 :逐步扩大模型参数和训练语料规模,探索不同类型的架构。典型代表是BART、T5、GPT-3等;
-
第三阶段 :走向AIGC(Artificial Intelligent Generated Content)时代,模型参数规模步入千万亿,模型架构为自回归架构,大模型走向对话式、生成式、多模态时代,更加注重与人类交互进行对齐,实现可靠、安全、无毒的模型。典型代表是InstructionGPT、ChatGPT、Bard、GPT-4等。
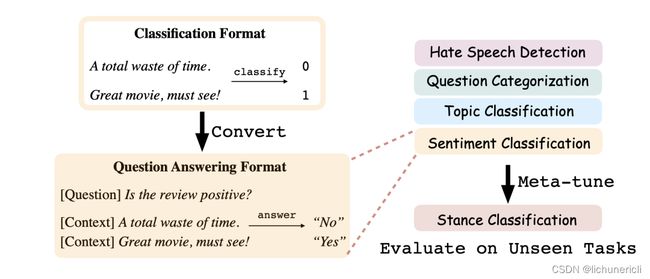
面向预训练语言模型的Prompt-Tuning技术发展历程
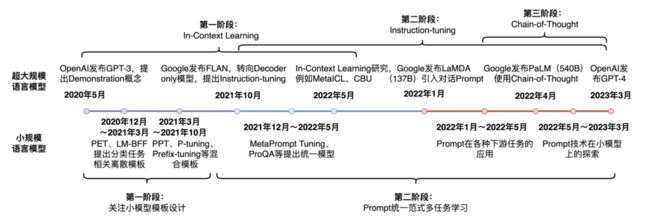
Prompt-Tuning自从GPT-3被提出以来,从传统的离散、连续的Prompt的构建、走向面向超大规模模型的In-Context Learning、Instruction-tuning和Chain-of-Thought。
自从GPT、EMLO、BERT的相继提出,以Pre-training + Fine-tuning 的模式在诸多自然语言处理(NLP)任务中被广泛使用,其先在Pre-training阶段通过一个模型在大规模无监督语料上预先训练一个 预训练语言模型(Pre-trained Language Model,PLM) ,然后在Fine-tuning阶段基于训练好的语言模型在具体的下游任务上再次进行 微调(Fine-tuning) ,以获得适应下游任务的模型。
这种模式在诸多任务的表现上超越了传统的监督学习方法,不论在工业生产、科研创新还是竞赛中均作为新的主流方式。然而,这套模式也存在着一些问题。例如,在大多数的下游任务微调时, 下游任务的目标与预训练的目标差距过大 导致提升效果不明显, 微调过程中依赖大量的监督语料 等。
至此,以GPT-3、PET为首提出一种基于预训练语言模型的新的微调范式——Prompt-Tuning ,其旨在通过添加模板的方法来避免引入额外的参数,从而让语言模型可以在小样本(Few-shot)或零样本(Zero-shot)场景下达到理想的效果。Prompt-Tuning又可以称为Prompt、Prompting、Prompt-based Fine-tuning等。
因此简单的来说,Prompt-Tuning的动机旨在解决目前传统Fine-tuning的两个痛点问题:
-
降低语义差异(Bridge the gap between Pre-training and Fine-tuning) :预训练任务主要以Masked Language Modeling(MLM)为主,而下游任务则重新引入新的训练参数,因此两个阶段的目标通常有较大差异。因此需要解决如何缩小Pre-training和Fine-tuning两个阶段目标差距过大的问题;
-
避免过拟合(Overfitting of the head) :由于在Fine-tuning阶段需要新引入额外的参数以适配相应的任务需要,因此在样本数量有限的情况容易发生过拟合,降低了模型的泛化能力。因此需要面对预训练语言模型的过拟合问题。
本文将深入解读Prompt-Tuning的微调范式,以综述+讨论的形式展开。
第一章:预训练语言模型
涉及知识点:
单向语言模型、双向语言模型;
Transformer;
预训练任务,包括MLM、NSP等;
NLP的任务类型以及fine-tuning;
预训练语言模型想必大家已经不再陌生,以GPT、ELMO和BERT为首的预训练语言模型在近两年内大放异彩。预训练语言模型主要分为单向和双向两种类型:
-
单向 :以GPT为首,强调 从左向右 的编码顺序,适用于Encoder-Decoder模式的自回归(Auto-regressive)模型;
-
双向 :以ELMO为首,强调从左向右和从右向左 双向编码 ,但ELMO的主体是LSTM,由于其是串形地进行编码,导致其运行速度较慢,因此最近BERT则以Transformer为主体结构作为双向语言模型的基准。
现如今常用的语言模型大多数是BERT及其变体,它的主体结构Transformer模型是由谷歌机器翻译团队在17年末提出的,是一种完全利用attention机制构建的端到端模型,具体算法详解可详情【预训练语言模型】Attention Is All You Need(Transformer)。
之所以选择Transformer,是因为 其完全以Attention作为计算推理技术 ,任意的两个token均可以两两交互,使得推理完全可以由矩阵乘机来替代,实现了 可并行化计算 ,因此Transformer也可以认为是一个全连接图, 缓解了序列数据普遍存在的长距离依赖和梯度消失等缺陷 。
在NLP领域中,Attention机制的目标是对具有强相关的token之间提高模型的关注度。例如在文本分类中,部分词对分类产生的贡献更大,则会分配较大的权重。
对句子的编码主要目标是为了让模型记住token的语义。传统的LSTM则只能通过长短期记忆的方法来捕捉token之间的关系,容易导致梯度消失或记忆模糊问题,而Transformer中,任意的token之间都有显式的连接,避免了长距离依赖性问题。当然Transformer也增加了position embedding以区分不同token的位置关系,
1.1 经典的Pre-trained任务
本文的目标是介绍Prompt-Tuning的方法,而Prompt-Tuning的动机则是进一步拉近微调与预训练阶段的任务目标,因此本部分则以常用的BERT为主,简单介绍Pre-training的经典方法,更加详细的解读,可参考:【预训练语言模型】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(BERT)。
(1)Masked Language Modeling(MLM)
传统的语言模型是以word2vec、GloVe为代表的词向量模型,他们主要是以词袋(N-Gram)为基础。例如在word2vec的CBOW方法中,随机选取一个固定长度的词袋区间,然后挖掉中心部分的词后,让模型(一个简单的深度神经网络)预测该位置的词,如下图所示:

Masked Language Modeling(MLM)则采用了N-Gram的方法,不同的是,N-Gram喂入的是被截断的短文本,而MLM则是完整的文本,因此MLM更能够保留原始的语义:

MLM是一种自监督的训练方法,其先从大规模的无监督语料上通过固定的替换策略获得自监督语料,设计预训练的目标来训练模型,具体的可以描述为:
-
替换策略:在所有语料中,随机抽取15%的文本。被选中的文本中,则有80%的文本中,随机挑选一个token并替换为
[mask],10%的文本中则随机挑选一个token替换为其他token,10%的文本中保持不变。 -
训练目标:当模型遇见
[mask]token时,则根据学习得到的上下文语义去预测该位置可能的词,因此,训练的目标是对整个词表上的分类任务,可以使用交叉信息熵作为目标函数。
因此以BERT为例,首先喂入一个文本It is very cold today, we need to wear more clothes. ,然后随机mask掉一个token,并结合一些特殊标记得到:[cls] It is very cold today, we need to [mask] more clothes. [sep] ,喂入到多层的Transformer结构中,则可以得到最后一层每个token的隐状态向量。MLM则通过在[mask]头部添加一个MLP映射到词表上,得到所有词预测的概率分布。
现如今有诸多针对MLM的改进版本,我们挑选两个经典的改进进行介绍:
-
Whole Word Masking(WWM) :来源于RoBERTa等,其认为BERT经过分词后得到的是word piece,而BERT的MLM则是基于word piece进行随机替换操作的,即Single-token Masking,因此被mask的token语义并不完整。而WWM则表示被mask的必须是一个完整的单词。
-
Entity Mention Replacement(EMR) :来源于ERNIE-BAIDU等,其通常是在知识增强的预训练场景中,即给定已知的知识库(实体),对文本中的整个实体进行mask,而不是单一的token或字符。
下面给出对比样例。以文本“Michael Jackson is one of the best-selling music artists of all time, with estimated sales of over 400 million records worldwide”为例:

(2)Next Sentence Prediction(NSP)
在BERT原文中,还添加了NSP任务,其主要目标是给定两个句子,来判断他们之间的关系,属于一种自然语言推理(NLI)任务。在NSP中则存在三种关系,分别是:
-
entailment(isNext):存在蕴含关系,NSP中则认为紧相邻的两个句子属于entailment,即isNext关系;
-
contradiction(isNotNext):矛盾关系,NSP中则认为这两个句子不存在前后关系,例如两个句子来自于不同的文章;
-
Neutral:中性关系,NSP中认为当前的两个句子可能来自于同一篇文章,但是不属于isNext关系的
而显然,构建NSP语料也可以通过自监督的方法获得,首先给定一个大规模无监督语料,按照文章进行分类。在同一篇文章里,随机挑选一个句子作为premise,因此entailment类对应的则是其下一个句子,另外再随机挑选同一篇文章中的其他句子作为Neutral类,其他文章中的句子作为contradiction类。
在BERT中,NSP任务则视为sentence-pair任务,例如输入两个句子S1:It is very cold today. 和 S2:We need to wear more clothes.,通过拼接特殊字符后,得到:[cls] It is very cold today. [sep] We need to wear more clothes. [sep],然后喂入到多层Transformer中,可以得到[cls]token的隐状态向量,同样通过MLP映射到一个3分类上获得各个类的概率分布:

在以ALBETR、RoBERTa等系列的模型,由于发现NSP对实验的效果并没有太多正向影响,因此均删除了NSP的任务,在后续的预训练语言模型中,也纷纷提出其他的预训练目标,本文不再过多赘述。在后续的Prompt-Tuning技术中,大多数则以MLM作为切入点。
1.2 Task-specific Fine-tuning
获得了预训练的语言模型后,在面对具体的下游任务时,则需要进行微调。通常微调的任务目标取决于下游任务的性质。我们简单列举了几种NLP有关的下游任务:
-
Single-text Classification(单句分类) :常见的单句分类任务有短文本分类、长文本分类、意图识别、情感分析、关系抽取等。给定一个文本,喂入多层Transformer模型中,获得最后一层的隐状态向量后,再输入到新添加的分类器MLP中进行分类。在Fine-tuning阶段,则通过交叉信息熵损失函数训练分类器;
短/长文本分类:直接对句子进行归类,例如新闻归类、主题分类、场景识别等;
意图识别:根据给定的问句判断其意图,常用于检索式问答、多轮对话、知识图谱问答等;
情感分析:对评论类型的文本进行情感取向分类或打分;
关系抽取:给定两个实体及对应的一个描述类句子,判断这两个实体的关系类型;
-
Sentence-pair Classification(句子匹配/成对分类) :常见的匹配类型任务有语义推理、语义蕴含、文本匹配与检索等。给定两个文本,用于判断其是否存在匹配关系。此时将两个文本拼接后喂入模型中,训练策略则与Single-text Classification一样;
语义推理/蕴含:判断两个句子是否存在推理关系,例如entailment、contradiction,neutral三种推理关系;
文本匹配与检索:输入一个文本,并从数据库中检索与之高相似度匹配的其他句子
-
Span Text Prediction(区间预测) :常见的任务类型有抽取式阅读理解、实体抽取、抽取式摘要等。给定一个passage和query,根据query寻找passage中可靠的字序列作为预测答案。通常该类任务需要模型预测区间的起始位置,因此在Transformer头部添加两个分类器以预测两个位置。
抽取式阅读理解:给定query和passage,寻找passage中的一个文本区间作为答案;
实体抽取:对一段文本中寻找所有可能的实体;
抽取式摘要:给定一个长文本段落,寻找一个或多个区间作为该段落的摘要;
-
Single-token Classification(字符分类) :此类涵盖序列标注、完形填空、拼写检测等任务。获得给定文本的隐状态向量后,喂入MLP中,获得每个token对应的预测结果,并采用交叉熵进行训练。
序列标注:对给定的文本每个token进行标注,通常有词性标注、槽位填充、句法分析、实体识别等;
完形填空:与MLM一致,预测给定文本中空位处可能的词
拼写检测:对给定的文本中寻找在语法或语义上的错误拼写,并进行纠正;
-
Text Generation(文本生成) :文本生成任务常用于生成式摘要、机器翻译、问答等。通常选择单向的预训练语言模型实现文本的自回归生成,当然也有部分研究探索非自回归的双向Transformer进行文本生成任务。BART等模型则结合单向和双向实现生成任务。
生成式摘要:在文本摘要中,通过生成方法获得摘要;
机器翻译:给定原始语言的文本,来生成目标语言的翻译句子;
问答:给定query,直接生成答案;
相关的任务类型、常见的Benchmark以及形式化定义如下图所示:

这几类任务基本可以涵盖现有的自然语言处理场景中,而这五类任务在Fine-tuning阶段几乎都涉及 在模型头部引入新参数 的情况,且都存在 小样本场景过拟合 的问题,因此Prompt-Tuning的引入非常关键。
第二章:Prompt-Tuning的定义
涉及知识点:
Template与Verbalizer的定义;
那么什么是Prompt呢?在了解预训练语言模型的基础,以及预训练语言模型在Pre-training和Fine-tuning之后,我们已经可以预想到 Prompt的目的是将Fine-tuning的下游任务目标转换为Pre-training的任务 。那么具体如何工作呢?
我们依然以二分类的情感分析作为例子,描述Prompt-tuning的工作原理。给定一个句子[CLS] I like the Disney films very much. [SEP] 传统的Fine-tuning方法是将其通过BERT的Transformer获得 [CLS]表征之后再喂入新增加的MLP分类器进行二分类,预测该句子是积极的(positive)还是消极的(negative),因此需要一定量的训练数据来训练。
而Prompt-Tuning则执行如下步骤:
-
构建模板(Template Construction) :通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有
[MASK]标记的模板。例如It was [MASK].,并拼接到原始的文本中,获得Prompt-Tuning的输入:[CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]。将其喂入BERT模型中,并复用预训练好的MLM分类器(在huggingface中为BertForMaskedLM),即可直接得到[MASK]预测的各个token的概率分布; -
标签词映射(Label Word Verbalizer) :因为
[MASK]部分我们只对部分词感兴趣,因此需要建立一个映射关系。例如如果[MASK]预测的词是“great”,则认为是positive类,如果是“terrible”,则认为是negative类。
此时会有读者思考,不同的句子应该有不同的template和label word,没错,因为每个句子可能期望预测出来的label word都不同,因此如何最大化的寻找当前任务更加合适的template和label word是Prompt-tuning非常重要的挑战。
-
训练 :根据Verbalizer,则可以获得指定label word的预测概率分布,并采用交叉信息熵进行训练。此时因为只对预训练好的MLM head进行微调,所以避免了过拟合问题
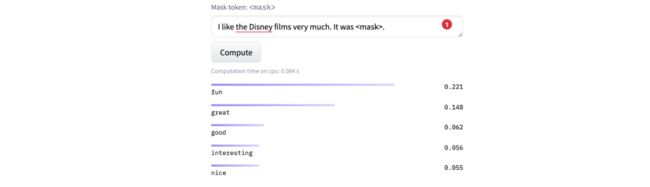
在hugging face上也可以直接进行测试:
-
I like the Disney films very much.
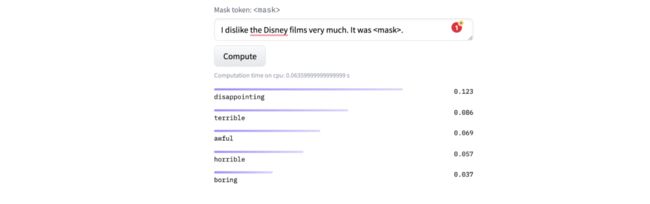
-
I dislike the Disney films very much.
其实我们可以理解,引入的模板和标签词本质上也属于一种数据增强,通过添加提示的方式引入先验知识
第三章:Prompt-Tuning的研究进展
涉及知识点:
GPT-3;
Prompt的形式化定义、Prompt的集成;
经典的Template的构建方法——启发式、生成式、连续提示、混合提示;
经典的Verbalizer的构建方法——启发式、连续式。
那么Prompt-Tuning具体如何实现,其有什么挑战和困难呢,本节将详细描述Prompt-Tuning在学术上的发展历程。由于Prompt-Tuning发展很迅猛,因此很难保证完全涵盖所有论文和学术报告,因此我们挑选一些具有代表性的工作进行介绍。
3.1 Prompt-Tuning的鼻祖——GPT-3与PET
Prompt-Tuning起源于GPT-3的提出《Language Models are Few-Shot Learners》(NIPS2020),其认为超大规模的模型只要配合好合适的模板就可以极大化地发挥其推理和理解能力。
其开创性提出 in-context learning 概念,即无须修改模型即可实现few-shot/zero-shot learning。同时引入了demonstrate learning,即让模型知道与标签相似的语义描述,提升推理能力。
-
In-context Learning :是Prompt的前身。其通过从训练集中挑选一些样本作为任务的提示提示(Natural Language Prompt),来实现免参数更新的模型预测;
-
Demonstration Learning :添加一些新的文本作为提示。例如在对“I like the Disney film. It was [MASK]”进行情感分析时,可以拼接一些相似场景的ground-truth文本“I like the book, it was great.”、“The music is boring. It is terrible for me.”等。此时模型在根据新添加的两个样例句子就可以“照葫芦画瓢”式地预测结果了。
不过以GPT-3为首的这类方法有一个明显的缺陷是—— 其建立在超大规模的预训练语言模型上 ,此时的模型参数数量通常超过100亿, 在真实场景中很难应用 ,因此众多研究者开始探索GPT-3的这套思路在小规模的语言模型(BERT)上还是否适用?事实上,这套方法在小规模的语言模型上是可行的,但是需要注意几点:
-
模型参数规模小了,Prompt直接用在Zero-shot上效果会下降,因此需要考虑将in-context learning和demonstrate learning应用在Fine-tuning阶段;
-
GPT-3中提供的提示(Natural Language Prompt)过于简单,并不难使用在一些具体的任务场景,因此需要单独设计一套组件实现。
因此,大名鼎鼎的PET模型问世,PET(Pattern-Exploiting Training)出自《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》(EACL2021),根据论文题目则可以猜出,Prompt-Tuning启发于文本分类任务,并且试图将所有的分类任务转换为与MLM一致的完形填空。
PET详细地设计了Prompt-Tuning的重要组件——Pattern-Verbalizer-Pair(PVP),并描述了Prompt-tuning如何实现Few-shot/Zero-shot Learning,如何应用在全监督和半监督场景(iPET)。PET的详细讲解可参考PET的论文解读。


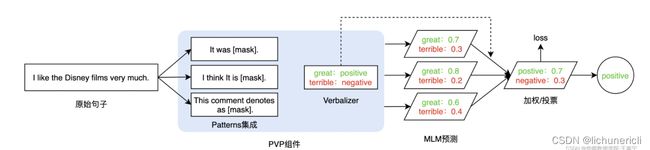



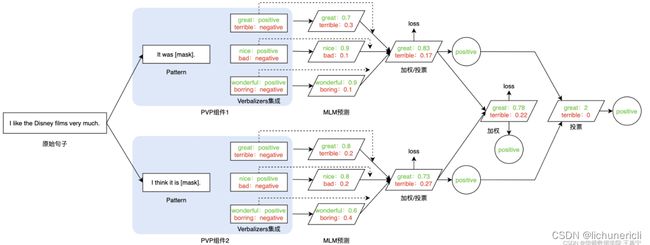
PET还提供了半监督的学习方法——iterative PET(iPET),如下图所示:
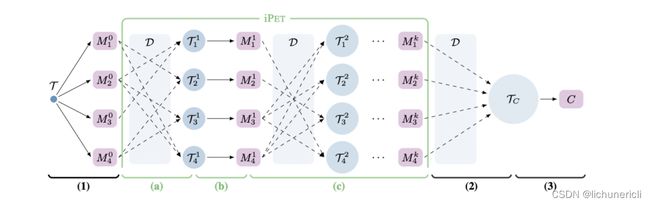


3.2 如何挑选合适的Pattern?
自2020年底至今,学术界已经涌现出一批基于Prompt-Tuning的方案试图探索如何自动构建PVP。本节主要总结几种成熟的Pattern(Template)构建方法。可以罗列为如下几点:
-
人工构建(Manual Template) :在前文已经描述过,不再详细说明;
-
启发式法(Heuristic-based Template) :通过规则、启发式搜索等方法构建合适的模板;
-
生成(Generation) :根据给定的任务训练数据(通常是小样本场景),生成出合适的模板;
-
词向量微调(Word Embedding) :显式地定义离散字符的模板,但在训练时这些模板字符的词向量参与梯度下降,初始定义的离散字符用于作为向量的初始化;
-
伪标记(Pseudo Token) :不显式地定义离散的模板,而是将模板作为可训练的参数;
前面3种也被称为 离散的模板构建 法(记作 Hard Template 、 Hard Prompt 、 Discrete Template 、 Discrete Prompt ),其旨在直接与原始文本拼接显式离散的字符,且在训练中 始终保持不变 。这里的保持不变是指 这些离散字符的词向量(Word Embedding)在训练过程中保持固定 。通常情况下, 离散法不需要引入任何参数 。
后面2种则被称为 连续的模板构建 法(记作 Soft Template 、 Soft Prompt 、 Continuous Template 、 Continuous Prompt ),其旨在让模型在训练过程中根据具体的上下文语义和任务目标对模板参数进行连续可调。这套方案的动机则是认为离散不变的模板无法参与模型的训练环节,容易陷入局部最优,而如果将模板变为可训练的参数,那么不同的样本都可以在连续的向量空间中寻找合适的伪标记,同时也增加模型的泛化能力。因此, 连续法需要引入少量的参数并让模型在训练时进行参数更新 。
下面简单介绍几个经典的方法:
(1)启发式法构建模板
启发式法一般是采用规则、正则化模板的方法自动构建出相应的Pattern,或者直接通过启发式搜索的方法获得Pattern。这一类方法在程序设计时只需要编写规则和少量的模板即可快速的获得Pattern。
给定一个具体的任务(例如分类任务),可以实现定义若干个模板(例如正则化工具),然后根据具体的句子内容,向模板中填充相关实体,以贴合句子实际的描述。例如清华大学刘知远团队提出的 PTR (PTR: Prompt Tuning with Rules for Text Classification)利用启发式的规则定义若干子模板(sub-prompt),并通过若干子模板的组合来形成最终的Pattern。

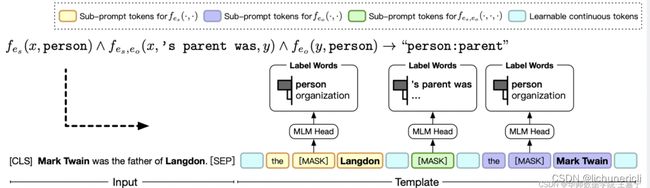 PTR的详细解读请参考博主的论文解读:论文解读:PTR: Prompt Tuning with Rules fo Text Classification:https://wjn1996.blog.csdn.net/article/details/120256178
PTR的详细解读请参考博主的论文解读:论文解读:PTR: Prompt Tuning with Rules fo Text Classification:https://wjn1996.blog.csdn.net/article/details/120256178
因此不论给定哪个句子,模板不会完全固定不变,而是根据不同的实体而相应改变模板的字符序列。
相比之下, AutoPrompt 则是另一种典型的方法,其由加州大学提出《AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts(EMNLP2021),如下图所示,给定原始的输入,额外定义若干离散的字符作为trigger,并组成Template,喂入MLM中预测对应label word的概率。而这些trigger最终通过梯度搜索的方法进行挑选。

(2)生成法构建模板
基于规则的方法构建的模板虽然简单,但是这些模板都是“ 一个模子刻出来的 ”,在语义上其实挺难做到与句子贴合。因此一种策略就是 直接让模型来生成合适的模板 ,因为文本生成本质上就是去理解原始文本的语义,并获得在语义上较为相关的文本。这样不论给定什么句子,我们可以得到在语义层面上更加贴合的模板。
陈丹琦团队提出 LM-BFF 则作为该类方法的典范,其出自于《Making Pre-trained Language Models Better Few-shot Learners》(ACL2021)。LM-BFF提出了基于生成的方法来构建Pattern,而给定相应的Pattern之后,再通过搜索的方法得到相应的Verbalizer。如下图所示:
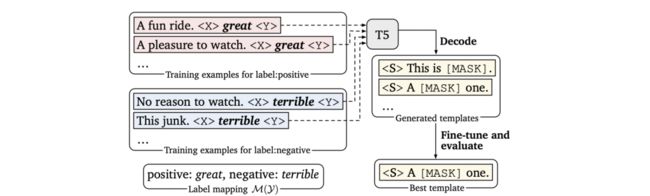
首先定义一个Template的母版(有点类似于PTR中的含有占位符的子模板),将这些母版与原始文本拼接后喂入T5模型(T5模型属于自回归式的生成模型)后在
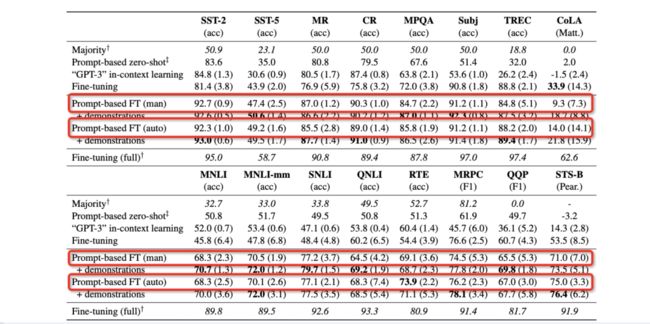
通过多个任务的小样本场景测试(分类任务,每个类只有16个样本),整体观察可发现这种基于生成的方法明显比人工构建的效果更好,如图所示:
LM-BFF的详细内容请参考博主的论文解读:论文解读:Making Pre-trained Language Models Better Few-shot Learners(LM-BFF):https://wjn1996.blog.csdn.net/article/details/115640052
(3)连续提示模板
不论是启发式方法,还是通过生成的方法,都需要为每一个任务单独设计对应的模板,因为这些模板都是可读的离散的token(这类模板我们称作Discrete Prompt或Hard Prompt。),这导致很难寻找到最佳的模板。
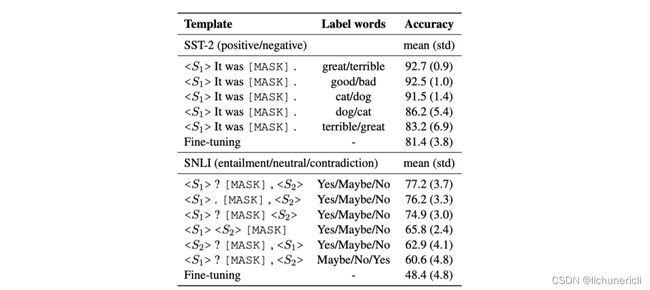
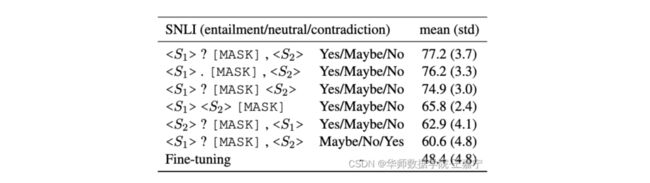
另外,即便是同一个任务,不同的句子也会有其所谓最佳的模板,而且有时候,即便是人类理解的相似的模板,也会对模型预测结果产生很大差异。例如下图,以SNLI推断任务为例,仅仅只是修改了模板,测试结果差异很明显,因此离散的模板存在方差大、不稳定等问题。
如何避免这种问题呢,一种新的 “连续提示” 被提出,称作Continuous Prompt或Soft Prompt,其将模板转换为可以进行优化的连续向量,换句话说,我们不需要显式地指定这些模板中各个token具体是什么,而只需要在语义空间中表示一个向量即可。
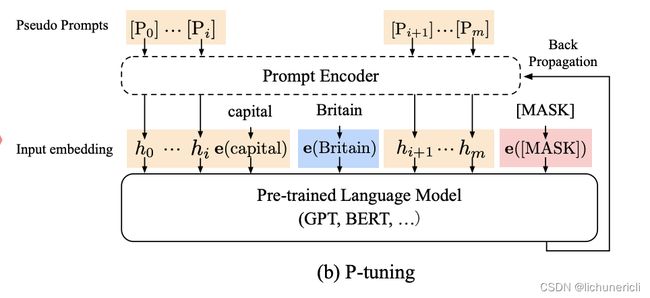
这样,不同的任务、数据可以自适应地在语义空间中寻找若干合适的向量,来代表模板中的每一个词,相较于显式的token,这类token称为 伪标记(Pseudo Token) 。下面给出基于连续提示的模板定义:

Prompt Tuning
该方法率先提出了伪标记和连续提示的概念,以让模型在能过动态地对模板在语义空间内进行调整,使得模板是可约的(differentiate)。形式化的描述如下:



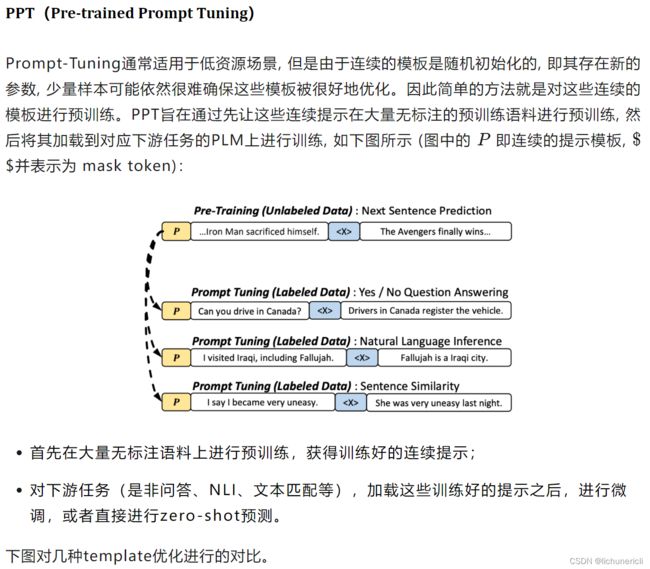

(4)Template优化进阶
我们为任务设计的模板都是建立在一个假设上:即模板都是尽可能是可读的,即满足人类语言的语法形态。然而最近也有工作认为,最优的模板可能是不符合语法的乱语 (Ungrammatical Gibberish Text),即人类可读的模板,模型也许不可读。虽然这很反直觉,但是我们不能否认这种情况的存在。论文《RLPROMPT: Optimizing Discrete Text Prompts with Reinforcement Learning》给出了相应的发现,并提出了一种基于强化学习的方法RLPROMPT来寻找最优的模板。
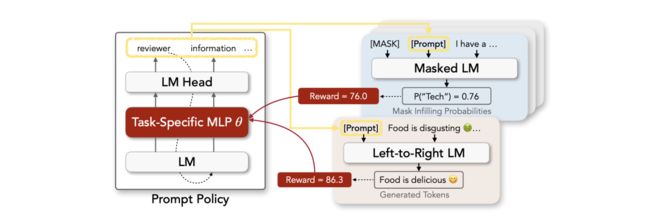
上图为RLPROMPT框架,左侧为策略网络,右侧分别为双向预训练模型(Masked LM)和生成式预训练模型(Left-to-Right LM),分别对应于分类任务和生成任务。RLPROMPT的原理如下:
Step1 :给定一个句子(例如“I have ...”),一个 [mask] token,以及一个用于待生成的模板占位符 [Prompt]。
Step2 :如果是分类任务,则将输入句子喂入一个双向语言模型中获得 [mask] 位置的预测token,并通过verbalizer映射到对应类别的概率分布,如果是在训练阶段,真实标签是已知的,其概率可以作为当前模板的反馈(reward)。如果是生成任务,则喂入生成模型中,获得生成token的预测概率(或者其他文本生成的指标)并作为反馈。
Step3 :根据当前的反馈,使用强化学习的policy gradient方法训练一个决策函数。基于这个决策函数可以对[Prompt]生成一个离散的模板词。决策函数本质上是一个预训练语言模型,通过LM head来生成一个token。
Step4 :生成一个模板词之后,重复Step2~Step3,直到生成足够的模板词。
基于RLPROMPT,最终可以得到一些离散的模板,相比连续的提示更加有解释性。取几个常用的评测任务,对比不同方法生成的模板的区别:

3.3 如何挑选合适的Verbalizer?
除了Template以外,Verbalizer是直接关系到预测的结果是什么,不同的Verbalizer会对最终预测效果产生较大的影响,不同的任务会有不同的合适的label word。例如在电影评论任务中,positive类别的label word比较合适的是wonderful,而在美食点评任务中,positive比较合适的是testy。因此label word的选择也是Prompt-Tuning中关键的部分。如下图所示,以SST-2为例,相同的模板条件下,不同的label word对应的指标差异很大。

传统的方法是人工设计(Manual Design),即可以根据对每个任务的经验来人工指定这些label word。但是人工设计需要依赖大量的人力,且对于一些具有专业性的任务还需要依赖于专家,使得Prompt-Tuning的效率很低。
为了缓解这个问题,一些工作开始研究如何根据不同的任务自动地选择合适的label word。受到Template的离散和连续两种类型优化的启示,Verbalizer也可以分为离散和连续两种类型。本文分别介绍两个具有代表性的工作:
-
领域知识指导搜索离散的label word:《Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification》,代表方法为KPT;
-
原型网络动态生成label representations:《Prototypical Verbalizer for Prompt-based Few-shot Tuning》,代表方法为ProtoVerb。
KPT(Knowledgeable Prompt Tuning)
KPT的详细内容请参考博主的论文解读:论文解读:Knowledgeable Prompt-tuning: Incorporation Knowledge into Prompt Verbalizer for Text Classification:https://wjn1996.blog.csdn.net/article/details/120790512
针对不同的任务,都有其相应的领域知识,为了避免人工选择label word,该方法提出基于知识图谱增强的方法,如下图所示:

具体思路如下:
-
首先通过一些已有的字典工具,从词表中获得与给定label相关的词。如何建模这种相关性呢,该方法引入知识库,依赖于知识库中的三元组来衡量。例如SCIENCE在知识库中是一个实体,与该实体存在多挑关系的词可能有science、mathematics等等;
-
第一步可以获得大量的词,但是也容易引入噪声,因此需要进行提炼(Refine),可以设计一系列的启发式方法来度量每个词与label的相关度,最后获得指定数量的若干个合适的label word;
-
对于选定的label word,采用Verbalizaer集成的方法获得最终的预测结果。
ProtoVerb
回顾在Template的构建中,离散的模板是无法在训练过程中被优化的,从而引入了连续的模板。同理,离散label word也是只能在训练之前被指定,而在后续训练中无法被改变。因此,为了让label word也可以自适应的变化,提出连续的label word。
ProtoVerb巧妙的运用了原型网络(Prototypical Network)的思路,将每个类别的所有样本的表征的期望作为该类的原型向量,并使用该原型向量代替连续的label word。
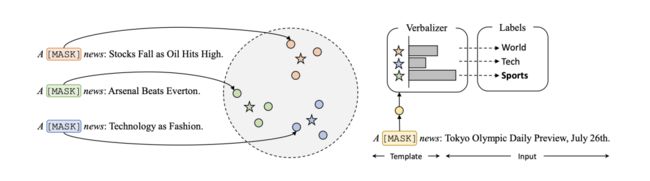
如上图,以新闻分类为例,首先定义固定的模板“A [mask] news.”,并拼接到原始的输入句子上。喂入BERT模型中,获得 [mask] 位置的表征向量代表句子向量。在训练过程中的label是已知的,所以可以求得同一label对应所有句子向量的均值来表示这个label的表征(图中的五角星)。
在测试阶段,则只需要计算测试句子的表征与各个类别的原型向量的相似度,并取最大相似度对应的label作为预测结果。
通过这种连续的label word,基本避免了显式获取label word的过程,使得模型的训练一气呵成。相似的做法也在《PromptBERT: Improving BERT Sentence Embeddings with Prompts》中被提及。
第四章:Prompt-Tuning的本质
涉及知识点:
元学习与prompt;
基于Prompt的NLP任务的统一范式;
基于生成模型的Prompt;
Prompt与参数有效性学习;
前面章节介绍了大量与Prompt相关的内容,我们可以发现,最初的Prompt Tuning是旨在设计Template和Verbalizer(即Pattern-Verbalizer Pair)来解决基于预训练模型的小样本文本分类,然而事实上,NLP领域涉及到很多除了分类以外其他大量复杂的任务,例如抽取、问答、生成、翻译等。这些任务都有独特的任务特性,并不是简单的PVP就可以解决的,因而, 我们需要提炼出Prompt Tuning的本质,将Prompt Tuning升华到一种更加通用的范式上 。
博主根据对Prompt-Tuning两年多的研究经验,总结了三个关于Prompt的本质,如下:
-
Prompt的本质是一种对任务的指令;
-
Prompt的本质是一种对预训练任务的复用;
-
Prompt的本质是一种参数有效性学习;
4.1 Prompt是一种针对任务的指令
Prompt本质上是对下游任务的指令,可以作为一种信息增强 。
简单的来说,就是告诉模型需要做什么任务,输出什么内容。上文我们提及到的离散或连续的模板,本质上就是一种对任务的提示。当数据集不同(乃至样本不同)的时候,我们期望模型能够自适应的选择不同的模板,这也相当于说不同的任务会有其对应的提示信息。
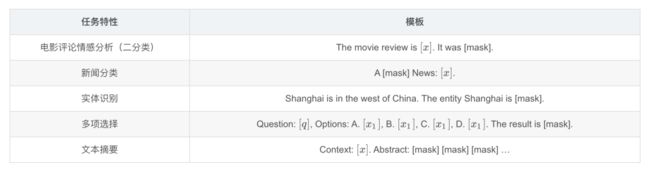
例如在对电影评论进行二分类的时候,最简单的提示模板是“. It was [mask].”,但是其并没有突出该任务的具体特性,我们可以为其设计一个能够突出该任务特性的模板,例如“The movie review is . It was [mask].”,然后根据mask位置的输出结果通过Verbalizer映射到具体的标签上。这一类具备任务特性的模板可以称之为 指令(Instruction) 。
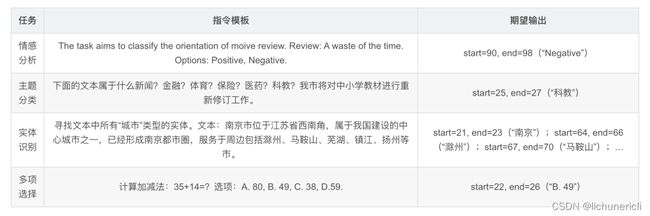
下面展示几个任务设计的指令模板:
看似设计指令是一件容易的事情,但是在真实使用过程中,预训练模型很难“理解”这些指令,根据最近研究工作发现,主要总结如下几个原因:
-
预训练模型不够大 :我们常使用的BERT-base、BERT-large、RoBERTa-base和RoBERTa-large只有不到10亿参数,相比于现如今GPT-3、OPT等只能算作小模型,有工作发现,小模型在进行Prompt Tuning的时候会比Fine-tuning效果差,是因为小模型很容易受到模板的影响
对比一下传统的Fine-tuning,每个样本的输入几乎都是不同的,然而基于Prompt的方法中,所有的样本输入都会包含相同的指令,这就导致小模型很容易受到这些指令带来的干扰。
-
缺乏指令相关的训练 :这些小模型在预训练阶段没有专门学习过如何理解一些特殊的指令。
我们回顾一下上面章节,不论是生成离散的模板还是连续的模板,都是在向现有的预训练语言模型进行“妥协”,即找到能够让当前预训练语言模型在小样本上效果最好的模板,或者说是站在已有预训练模型的基础上寻找模板。然而这种寻找到的模板不可读也不可解释,或者过于通用,不具备任务特性,无法很好地在真实场景下使用。因此,我们需要的是先设计好任务相关的指令,使得这些指令是可读的,可在真实场景下使用的。不过由于预训练模型没见过这些指令,所以很难在小样本上快速理解它们。
也许读者想到了前面所讲到的Pre-trained Prompt Tuning(PPT),即再次对预训练语言模型进行一次Continual Pre-training。然而我们忽略了一点,即 我们期望预训练模型不止是在我们已经设计好的指令上进行学习,还应该在未知的指令上具备一定的泛化性能 ,也就是说在一个完全新的任务上,只需要少量样本(甚至是零样本),也能过很好地理解这个指令。
为了达到这个目的,最常用的方法是 元学习(Meta Learning) ,我们介绍几个代表性的工作:
-
《TransPrompt: Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification》:代表方法TransPrompt,利用迁移学习提升预训练语言模型在不同类型任务上的泛化性能;
-
《Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections》:代表方法:MPT,统一分类任务范式,并采用元学习进行训练;
TransPrompt
该方法是面向连续提示模板的,其对P-tuning做了如下几个改进:
-
引入Cross-task Learning :原来P-tuning只对单一任务进行Prompt Tuning,而TransPrompt则对同一类别多个任务进行Cross-task Learning。例如情感分析有SST-2、MR和CR三个任务,则为每一个任务设计一个Task-specific Prompt Encoder。为了捕捉任务之间的共同知识,也额外设计以恶搞Universal Prompt Encoder。
在训练过程中,所有任务的数据集样本直接混合起来,每一个样本都会对应一个任务的标记。在喂入模型时,一个batch内会有来自多个任务的样本,根据任务类型的标记,分别使用对应的Task-specific Prompt Encoder来表征连续的模板,所有的样本都喂入Universal Prompt Encoder以获得通用的连续模板。
-
引入去偏(De-basing)技术 :不论是小样本还是全量数据,即便是统计分布上完全一致,不同的任务的难易程度是不一样的,因此模型在训练的时候可能极易偏向于一些简单任务。为了确保任务之间训练的平衡性,引入两个去偏技术,分别是Prototypical-based Debiasing和Entropy-based Debiasing,具体的做法详见原文。


4.2 复用预训练目标——实现基于Prompt的统一范式
我们需要思考,上述所讲的内容为什么要设计Template(和Verbalizer)?为什么都要包含mask token?
回顾第一节我们介绍的几个预训练语言模型,我们发现目前绝大多数的双向预训练语言模型都包含Masked Language Modeling(MLM),单向预训练语言模型都包含Autoregressive Language Modeling(ALM),这些任务是预训练目标,本质上是预测被mask的位置的词,在训练时让模型理解语言的上下文信息。之所以设计Template和指令,就是希望在下游任务时能够复用这些预训练的目标,避免引入新的参数而导致过拟合。因此,我们可以将Prompt升华到一个新的高度,即 Prompt Tuning的本质是复用预训练语言模型在预训练阶段所使用的目标和参数 。
基于Huggingface的预训练模型仓库中,我们一般称之为LMhead,本质上就是一个MLP,输入为一个大小为[batch_size, sequence_length, hidden_size]的张量,输出为[batch_size, sequence_length, vocab_size]的概率分布。
由于绝大多数的语言模型都采用MLM或ALM进行训练,所以我们现如今所看到的大多数基于Prompt的分类都要设计Template和Verbalizer。那么我们是否可以极大化地利用MLM和ALM的先验知识在不同的下游任务上获得更好的表现?是否可以设计一个全新的预训练任务来满足一些下游任务的需求呢?
我们介绍两个充分利用这个思想的方法:
-
万物皆可生成 :将所有任务统一为文本生成,极大化利用单向语言模型目标;
-
万物皆可抽取 :将所有任务统一为抽取式阅读理解,并设计抽取式预训练目标;
-
万物皆可推理 :将所有任务建模为自然语言推断(Natural Language Inference)或相似度匹配任务。
(1)万物皆可生成——基于生成的Prompt范式统一
在含有单向Transformer的语言模型中(例如GPT、BART),都包含自回归训练目标,即基于上一个token来预测当前的token,而双向语言模型中的MLM可以视为只生成一个token的自回归模型。
为此,我们则可以将分类任务视为一种特殊的文本生成,并配上Verbalizer,这样,所有的NLP任务都可以统一为生成任务。针对不同的任务,只需要提供对应的指令和模板即可(由于是使用单向语言模型,因此没有mask token,需要生成的部分置于文本末尾)。下面给出几个示例:

利用此思想,有很多工作致力于通过Prompt与生成的思想将各类任务进行统一。以问答领域为例,问答包括生成式问答、抽取式问答、多项选择等,我们可以将各种类型的问答建模为生成任务。
典型的方法例如:《UNIFIEDQA: Crossing format boundaries with a single QA system》、《ProQA- Structural Prompt-based Pre-training for Unified Question Answering》,其采用端到端的预训练语言模型(例如BART、T5),并复用预训练阶段的训练目标。
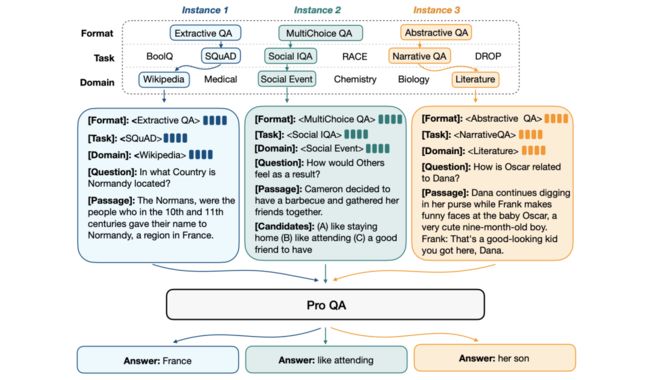
最近大火的ChatGPT则是基于“万物皆可生成”的思想,将单向语言模型的ALM发挥到极致,实现对所有任务的大一统,与之为代表的还有In-Context Learning、Instruction-Tuning和Chain-of-Thought,将在第5章节介绍。
(2)万物皆可抽取——基于抽取式阅读理解的Prompt范式统一

可以发现,如果是分类型的任务,只需要通过指令和模板的形式将所有类别罗列起来即可。在训练时,可以采用两种方法:
-
设计抽取式预训练目标,在无标注语料上进行自监督训练;
-
按照阅读理解的形式统一所有任务范式,并混合所有任务进行Cross-task Learning,再在新的任务上进行测试。
经典的方法比如《Unifying Question Answering, Text Classification, and Regression via Span Extraction》,苏剑林提出的Global Pointer。博主也运用该思想在2022年AIWIN春季赛“中文保险小样本”中获得第二名成绩。
基于MRC的范式统一方法则是提出新的预训练目标——区间抽取,并巧妙的集成了一些比较复杂的任务,例如实体识别,同时抽取式方法也可以很好地运用在多标签分类问题上,同理,实体识别和多区间抽取QA也属于类似多标签问题,即需要抽取出数量不等的区间。但是缺点是无法运用到生成问题上,且依赖于候选项。
(3)万物皆可推理——基于NLI的Prompt范式统一
另外一个方法则是将所有任务建模为NLI形式,其与上文介绍的MPT比较类似,除了MPT以外,《Entailment as Few-Shot Learner》(EFL)和NSP-BERT也是类似的方法,其思想是复用BERT中的Next Sentence Prediction(NSP)的预训练目标。下面给出几个事例:

通常可以直接使用NSP对应的LMhead进行微调,在训练过程中还需要考虑如何进行负采样,一般方法是直接选择其他类别作为负样本。


可以发现,两种Prompt-Tuning方法的共同点是都是复用了预训练阶段所使用的目标和参数,不同点是对任务建模的方式和指令模板的设计有所不同。在复用NSP时,则需要罗列所有的类别并与输入样本做拼接,从而将多类分类问题转换为判断输入与标签是否存在蕴含关系(Entailment)。
另外,该思想也在最近大火的多模态模型CLIP模型中应用,通过设计Prompt的形式对文本和图像进行匹配,并设计对比学习目标进行预训练。
4.3 Prompt的本质是参数有效性学习
根据前文的讲解,我们可以发现,实现Prompt-Tuning只需要考虑如何设计模板或指令,而模型和训练目标则都是复用预训练阶段的,即在整个训练过程中,无须添加任何参数(或只需要添加非常少量的与模板有关的参数),而其他参数都是训练好的。基于这个思想,我们再一次将Prompt升华到更高的层面—— Prompt的本质是参数有效性学习(Parameter-Efficient Learning,PEL) 。
参数有效性学习的背景 :在一般的计算资源条件下,大规模的模型(例如GPT-3)很难再进行微调,因为所有的参数都需要计算梯度并进行更新,消耗时间和空间资源。为了解决这个问题,参数有效性学习被提出,其旨在确保模型效果不受太大影响的条件下尽可能地提高训练的时间和空间效率。参数有效性训练 :在参数有效性学习过程中,大模型中只需要指定或额外添加少量的可训练参数,而其余的参数全部冻结,这样可以大大提高模型的训练效率的同时,确保指标不会受到太大影响。
常见经典的参数有效性学习有Adapter-Tuning、Prefix-Tuning、BitFit。下面进行简单的介绍。
(1)Adapter-Tuning
Adapter-Tuning在2019年提出,其面向预训练语言模型的参数有效性学习。在多层Transformer模型中,在微调过程中所有的参数都需要更新,显然并不是有效的。为了提高效率,该方法提出固定Transformer的全部参数,然后在Transformer的每一个Block里嵌入一些新初始化的Adapter Network。如下图所示:
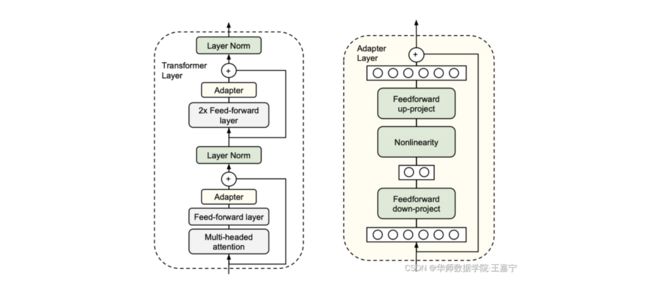
Adapter位于Feed-Forward Layer之后、残差连接之前。Adapter本质上就是两层MLP,分别负责将Transformer的表征降维和升维(右图)。基于Adapter的方法, 只需要添加不到5%的可训练参数,即可以几乎达到全参数训练的效果 ,在训练过程中大大节省了训练时间,做到时间有效性。因此在真实场景应用时, 不同的任务我们不需要重新对整个预训练模型进行微调,我们只需要保存Adapter即可 ,而预训练模型的其他参数都是原始预训练的,这样就做到了空间的有效性。
(2)Prefix-Tuning
Prefix-Tuning也是很经典的参数有效性学习,其是受到Prompt-Tuning的启发。我们说Prompt-Tuning的本质是参数有效性学习,是因为整个预训练模型参数可以全部固定,只需要对Template对应的少量参数(例如连续模板的Prompt Encoder、伪标记对应的Embedding等)进行训练。在Prefix-Tuning中,则是除了对输入层添加模板外,还对Transformer的每一层添加“模板”。Prefix-Tuning与传统Fine-tuning的对比图如下所示:
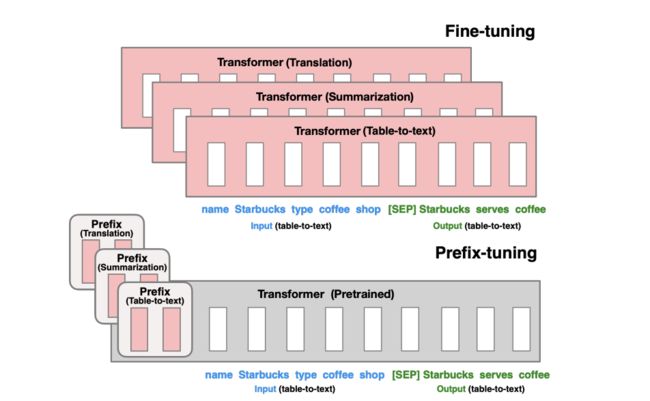
可以看到,Transformer的参数完全固定,而我们只需要对Prefix部分进行训练即可,对于不同的任务训练不同的Prefix,在实际使用时,挑选任务相关的Prefix和Transformer进行组装,实现可插拔式的应用。
与Prefix-Tuning类似的方法还有P-tuning V2,不同之处在于Prefix-Tuning是面向文本生成领域的,P-tuning V2面向自然语言理解。但本质上完全相同。下图针对Prefix-tuning(P-tuning V2)与Prompt-Tuning对比(黄色部分表示可训练的参数,蓝色表示被冻结的参数):

左图表示的是基于连续提示的Prompt-Tuning(例如P-tuning),我们可以发现只有输入层对应模板部分的Embedding和MLP参数是可训练的,右图部分表示Prefix-Tuning(P-tuning V2),Transformer的每一层的前缀部分也是可训练的,可以抽象的认为是在每一层添加了连续的模板。但是实际上,Prefix-Tuning(P-tuning V2)并不是真正的在每一层添加模板,而是通过HuggingFace框架内置的past_key_value参数控制。其本质上与Adapter类似,是在Transformer内部对Key和Value插入可训练的两个MLP。
有相关工作对Adapter、Prefix-Tuning、LoRA等参数有效性学习进行了集成,因为 这些参数有效性学习方法本质上都是插入少量的新的参数,这些新的参数可以对预训练模型起到提示作用,只不过并不是以人类可读的离散的模板形式体现而已 。
下图是《UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning》提出将这些参数有效性方法进行统一,提出UniPELT框架:

(3)BitFit
BitFit的思想更简单,其不需要对预训练模型做任何改动,只需要指定神经网络中的偏向(Bias)为可训练参数即可,BitFit的参数量只有不到2%,但是实验效果可以接近全量参数。
介绍了上述的一些参数有效性方法,我们发现,Prompt-Tuning也符合其主旨。基于参数有效性的思想,也有许多工作致力于Prompt与参数有效性的结合,例如《Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models》、《LiST: Lite Prompted Self-training Makes Parameter-efficient Few-shot Learners》、《Making Parameter-efficient Tuning More Efficient: A Unified Framework for Classification Tasks》、《P-Adapters- Robustly Extracting Factual Information from Language Models with Diverse Prompts》、《Context-Tuning: Learning Contextualized Prompts for Natural Language Generation》,由于相关工作非常多而且更新频繁,这里不一一介绍。
第五章:面向超大规模模型的Prompt-Tuning
Prompt-Tuning发展的两年来,有诸多工作发现,对于超过10亿参数量的模型来说,Prompt-Tuning所带来的增益远远高于标准的Fine-tuning,小样本甚至是零样本的性能也能够极大地被激发出来,得益于这些模型的 参数量足够大 ,训练过程中使用了 足够多的语料 ,同时设计的 预训练任务足够有效 。最为经典的大规模语言模型则是2020年提出的GPT-3,其拥有大约1750亿的参数,且发现只需要设计合适的模板或指令即可以 实现免参数训练的零样本学习 。
2022年底到2023年初,国内外也掀起了AIGC的浪潮,典型代表是OpenAI发布的ChatGPT、GPT-4大模型,Google发布的Bard以及百度公司发布的文心一言等。超大规模模型进入新的纪元,而这些轰动世界的产物,离不开强大的Prompt-Tuning技术。本文默认以GPT-3为例,介绍几个面向超大规模的Prompt-Tuning方法,分别为:
-
上下文学习 In-Context Learning(ICL) :直接挑选少量的训练样本作为该任务的提示;
-
指令学习 Instruction-tuning :构建任务指令集,促使模型根据任务指令做出反馈;
-
思维链 Chain-of-Thought(CoT) :给予或激发模型具有推理和解释的信息,通过线性链式的模式指导模型生成合理的结果。
5.1 In-Context Learning(上下文学习)
In-Context learning(ICL)最早在GPT-3中提出, 旨在从训练集中挑选少量的标注样本,设计任务相关的指令形成提示模板,用于指导测试样本生成相应的结果 。ICT的工作原理如下所示:



(1)样本的Input-Output Mapping的正确性是否对ICL有何影响?
In-Context Example主要是由训练样本组成的,通常包含Input和Output两个部分。其中Input(Input Text)表示输入的文本,Output表示输出的文本或者标签(Label)。那么Input-Output的形式是否会对ICL产生影响呢,下面介绍两个来自EMNLP2022针对样本挑选的分析型工作:
-
《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》(简称 Rethinking )
-
《Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations》(简称 Ground-Truth )
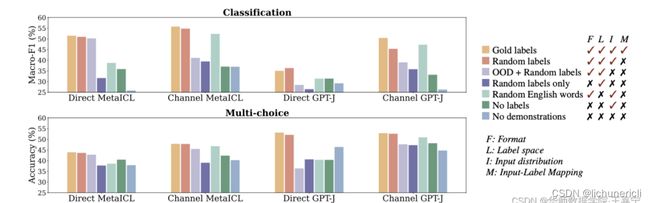
Rethinking
该工作使用GPT-3和GPT-J等大模型,根据API的多次调用进行实验。首先探索了 这些挑选样本的输入句子与标签(Input-Output Mapping)是否正确对预测存在影响 ,其定义三个Baseline,所有样本均为随机采样:
-
No Demonstration :没有任何训练样本,相当于零样本场景;
-
Demonstration w/ glod labels :标准的in-context learning,每个标注样本和标签是正确对应的
-
Demonstration w/ random labels :In-context Example的标签被随机替换为错误的标签;

通过实验发现:
-
使用Demonstration比不使用的效果好 ,说明demonstration example确实可以提升性能;
-
random label对模型性能的破坏并不是很大 ,说明in-context learning更多的是去学习Task-specific的Format,而不是Input-Output Mapping
-
MetaICL是包含对ICL进行meta-training的方法,但实验结果也表明random label对效果影响很小。说明在meta-training时,模型也不会过多关注Demonstration example的Input-Output Mapping,而是关注其他方面。
MetaICL是一种通过任务统一范式并使用元学习进行训练的方法,其重要增加了多任务的训练来改进ICL在下游任务零样本推理时的泛化性能,该算法将在下文讲解。
另外进一步探索被挑选的 个训练样本中, 正确的Input-Output Mapping的比例 是否也有影响。实验结果发现影响较小,如下图:


(1)样本的Input-Output Mapping的正确性是否对ICL有何影响?
In-Context Example主要是由训练样本组成的,通常包含Input和Output两个部分。其中Input(Input Text)表示输入的文本,Output表示输出的文本或者标签(Label)。那么Input-Output的形式是否会对ICL产生影响呢,下面介绍两个来自EMNLP2022针对样本挑选的分析型工作:
-
《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》(简称 Rethinking )
-
《Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations》(简称 Ground-Truth )
Rethinking
该工作使用GPT-3和GPT-J等大模型,根据API的多次调用进行实验。首先探索了 这些挑选样本的输入句子与标签(Input-Output Mapping)是否正确对预测存在影响 ,其定义三个Baseline,所有样本均为随机采样:
-
No Demonstration :没有任何训练样本,相当于零样本场景;
-
Demonstration w/ glod labels :标准的in-context learning,每个标注样本和标签是正确对应的
-
Demonstration w/ random labels :In-context Example的标签被随机替换为错误的标签;
通过实验发现:
-
使用Demonstration比不使用的效果好 ,说明demonstration example确实可以提升性能;
-
random label对模型性能的破坏并不是很大 ,说明in-context learning更多的是去学习Task-specific的Format,而不是Input-Output Mapping
-
MetaICL是包含对ICL进行meta-training的方法,但实验结果也表明random label对效果影响很小。说明在meta-training时,模型也不会过多关注Demonstration example的Input-Output Mapping,而是关注其他方面。
MetaICL是一种通过任务统一范式并使用元学习进行训练的方法,其重要增加了多任务的训练来改进ICL在下游任务零样本推理时的泛化性能,该算法将在下文讲解。
另外进一步探索被挑选的 个训练样本中, 正确的Input-Output Mapping的比例 是否也有影响。实验结果发现影响较小,如下图:


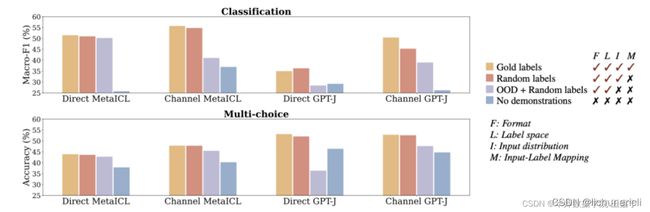
从实验结果来看,部分情况下影响还是有的,说明输入样本在语义空间内的分布是会影响ICL的结果。
更多分析可阅读博主的博文:【In-Context Learning】Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?:https://blog.csdn.net/qq_36426650/article/details/129818361?spm=1001.2014.3001.5501

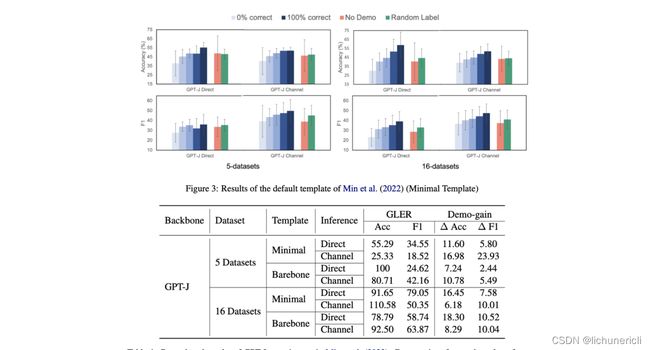
作者认为,不同的实验设置(例如Template的不同、数据集的不同等),Random Label与No Label所产生的效果差异是不同的,因此不能直接做出“In-context example mapping does not affect in-context learning performance much”片面的判定。
综合Rethinking和Ground-Truth两个工作,我们可以得出结论,对后续ICL的研究和应用都具有一定的启发作用:
-
Input-Output Mapping对ICL是有影响的 ,主要体现在Input Text的分布、Label的准确性等;
-
不论是缺少Input Text还是缺少Label,都会对ICL的效果产生影响 ,说明ICL会得到Demonstration的形式的指导,对后面的预测起到引导作用;
(2)In-Context Example的选择与顺序对ICL有什么影响
In-Context Example的选择方法最简单的便是随机采样,即将每个样本视为独立且等概率的,因此每个训练样本都有一定概率被选中。同时,被选中的这些样本如何排序,也会对ICL的预测产生一些影响(因为Demonstration的构建是将这些Input-Output Pair按照一定顺序线性拼接而成)。然而有工作发现,随机采样的方法会面临方差大的风险。先通过一个简单的预实验来说明这一点。

实验结果表明, 挑选不同的样本对ICL的性能影响不同,而同样的样本不同的排列也会产生很大的差异 ,最大准确率的差异超过了40%,验证了ICL的性能对样本的选择和排列很敏感,完全随机的样本挑选和排列使得ICL性能不稳定、方差大。所以,在真实应用时,如果使用完全随机的方法,对预测的结果是无法保证的。那么如何弥补这一点呢,下面介绍来自ACL2022的两个经典工作:
-
《What Makes Good In-Context Examples for GPT-3?》:代表方法KATE;
-
《Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity》:简称Fantastically
KATE
该工作也在SST-2的预实验中发现不同的In-Context Example会得到不同的准确率,说明样本的挑选很重要。另外作者在Natural Question数据集上进行测试,发现当挑选的In-Context Example如果在Embedding空间中与Test Example更近,将会带来更好的效果。因此提出KATE(Knn-Augmented in-conText Example selection),即基于近邻原则挑选In-Context Example。
关于KATE更详细的解读可参考博主的博文:【In-Context Learning】What Makes Good In-Context Examples for GPT-3?:https://wjn1996.blog.csdn.net/article/details/129816707?spm=1001.2014.3001.5502




Encoder的选择可以是预训练的BERT、RoBERTa,也可以是在目标任务数据上进行自监督的模型,例如Sentence-BERT、SimCSE等。
实验发现,基于KATE的样本挑选算法可以提升ICL的性能,并且降低方差。
Fantastically
该工作发现样本的排列对ICL影响很大,而且模型越小方差越大。如下图所示:
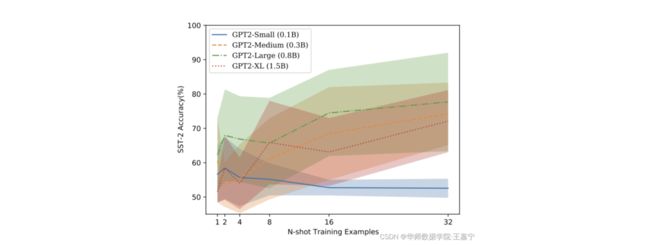
因此,该工作提出旨在从众多的排列中挑选合适的排列,提出三阶段的方法:
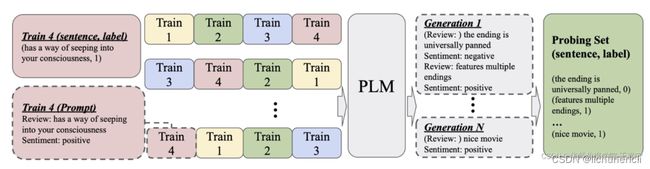

(1)ICL的提升——引入自监督(Self-supervised ICL)
不论是大模型还是小模型,如果直接用ICL的目标来训练模型会怎么样?下面这一篇工作尝试讲ICL加入到自监督训练过程中。
-
《Improving In-Context Few-Shot Learning via Self-Supervised Training》[45]
首先引入两个定义: example定义 :表示一个input-output pair。input和output text前面分别添加“Input”和“Output”标记,每个example之间通过newline分隔。
instance定义 :表示若干example的线性拼接,如下图所示:
![]()
按照ICL的模式,拼接若干个样本。对于每个样本添加模板,例如Input、Output。红色部分则为Label。
按照这一模式,定义不同的预训练任务:

Next Sentence Generation(NSG)
给定一个original text,划分为两个子句。前面的句子作为input输入模型,后面的句子作为output,旨在模型根据input来生成output。
Masked Word Prediction(MWP)
类似于MLM,对输入的文本随机挑选1~20个词,并分别随机替换如下几个之一的special token(___, 〈〈〉〉, @@@, (()), $$$, %%%, ###, ***, and +++.)。任务旨在预测被覆盖的词。
Last Phrase Prediction(LPP)
给定一个文本(缺乏末尾词)以及若干passage text,任务旨在生成/分类末尾词。该任务可以建模为生成式任务或分类任务:
-
生成任务:让模型生成last phrase
-
分类任务:给定一个答案,让模型判断答案是否正确(生成True/False)
Classification
与Next sentence prediction和Sentence orddering prediction类似,考虑四种类型的输入(如下图)

-
Original Sentence:原始文本不做改动,此时为True
-
Multiple Documents:随机对50%的句子从其他document中挑选并替换;此时每个句子之间语义不同,为False
-
Shuffled Sentence:打乱句子顺序,但不改变整个文档语义,为True。
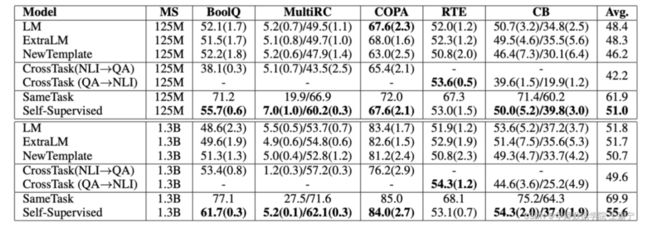
训练阶段使用MOE进行预训练。预训练语料:BOOK-CORPUS plus Wikipedia, CC-NEWS, OPENWEB- TEXT, and STORIES。分别对每个语料抽取100k句子(STORIES只抽取10k)。最终大约有100w个句子,每个类型的self-supervised task平均25w个样本。
作者在很多任务上进行了实验,这里只展示SuperGLUE上的效果,可以发现引入ICL自监督训练是可以大大提升效果的。
(2)ICL的提升——统一范式+元学习(MetaICL)
除了将ICL的模板与自监督训练结合外,是否可以直接使用ICL来训练一个具体的任务呢?答案是可以的,下面两篇工作将ICL的模板与下游任务相结合,并提出基于元学习的ICL训练方法:
-
《Meta-learning via Language Model In-context Tuning》[46]:提出In-Context Tuning方法;
-
《MetaICL: Learning to Learn In Context》[47]:提出MetaICL方法。
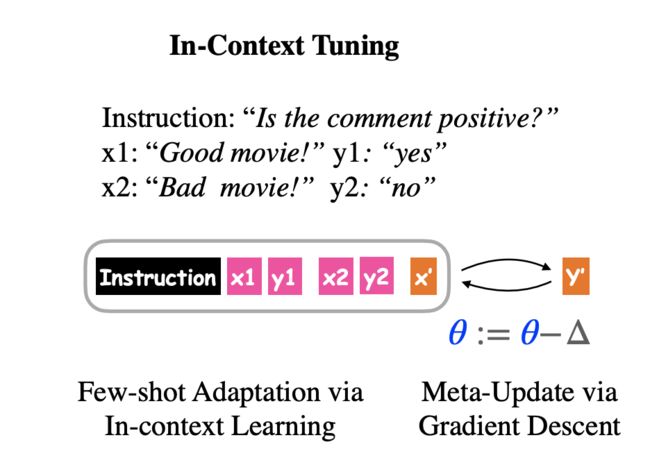
In-Context Tuning
目前,向语言模型通过prompting可以在小样本场景下得到很大的成功,例如GPT-3。然而原始的语言模型在预训练时并没有针对in-context进行优化。先前工作发现prompting会过度受到(oversensitive)样本选取以及instruction本身影响。因此该工作提出In-Context Tuning,旨在通过多任务训练的方式直接对预训练模型微调ICL任务目标。
在训练(fine-tuning)阶段,给定一系列的训练task,每一个task都有相应的instruction,以及该task对应的少量样本(输入/输出对)。在测试阶段,给定一个新的unseen task,以及该task对应的instruction和少量样本(输入/输出对),旨在让模型能够对测试样本预测其类别。
如下图,给定一个情感分析task:

MetaICL
大规模的语言模型可以被用于in-context learning(例如GPT-3)。只需要给定目标任务的少量标注样本作为提示,即可实现无参数训练地对其他样本进行预测。然而目前in-context learning依然与普通的fine-tuning有一定差距,且预测的结果方差很大,同时也需要花费时间考虑template的构建。传统的In-context learning可能效果并不理想,可能因为target task与预训练的阶段的训练目标差异太大,或模型太小。为了改进上述问题,该工作提出MetaICL方法,先在若干task的训练集上进行训练,试图让模型学习到如何根据in-context的语义来预测。
方法很简单,如下所示:

与GPT-3一样,在训练时,模型的输入包含当前task的 个样本,以及第 个样本输入,使用交叉熵更新模型。在测试阶段,给定unseen target task,无需再次更新模型,只需要将对应的K个样本拼接输入模型即可对其他样本预测。
(3)ICL的提升——对预测进行矫正(Calibrate Before Use)

5.2 Instruction-tuning(指令学习)
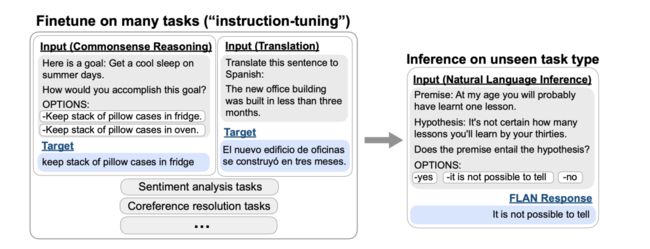
面向超大规模模型第二个Prompt技术是指令学习。在上文我们介绍过,Prompt的本质之一是任务的一种指令,因此,在对大规模模型进行微调时,可以为各种类型的任务定义指令,并进行训练,来提高模型对不同任务的泛化能力。
什么是指令呢?如下图所示:

假设是一个Question Generation任务,那么可以为这个任务定义一些指令,例如:
-
Title:任务的名称;
-
Definition:任务的定义,说明这个任务的本质和目的;
-
Things to avoid:说明这个任务的注意事项,例如需要避免什么等等;
-
Positive / Negative Examples:给出正确和错误的例子,作为提示;
-
Prompt:当前任务的提示信息;
当许多任务都按照这种模式定义好模板,让模型在指令化后的数据上进行微调,模型将可以学会如何看到指令做预测。
下面介绍一些典型的基于Instruction的方法,包括FLAN、LaMDA和InstructionGPT,它们都是遵循Instruction-tuning实现统一范式。
FLAN
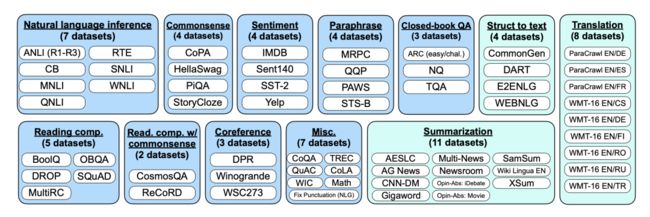
例如基于Instruction-Tuning训练的 FLAN模型 ,其在62个任务上进行多任务训练,每个任务都设计了Instruction,最后得到137B的大模型,如下图所示:
LaMDA
谷歌提出的LaMDA模型,其完全采用自回归生成式模型,并在大量的对话语料上进行预训练,得到137B的大模型。为了提高模型的安全性和事实性,LaMDA涉及到两个微调策略,一个是通过人工标注形式标注一些存在安全隐患的数据。期望模型生成过程中考虑四种因素:

另一种微调策略则是引入互联网搜索机制,提高模型生成结果的事实性:

最近与ChatGPT类似的Bard大模型则是基于LaMDA微调的模型。
InstructionGPT
另外一个典型的例子是OpenAI的InstructionGPT,其主要流程如下:

-
Step1 :先采样一些demonstration数据,其包括prompt和labeled answer。基于这些标注的数据,对GPT-3进行fine-tuning,得到SFT(Supervised Fine-tuning);
雇佣40名标注人员完成prompt的标注。此时的SFT模型在遵循指令/对话方面已经优于 GPT-3,但不一定符合人类偏好。
-
Step2 :Fine-tuning完之后,再给一个prompt让SFT模型生成出若干结果(可以通过beam search等方法),例如生成ABCD四种结果,通过人工为其排序,例如D>C>A=B,可以得到标注的排序pair;基于标注的排序结果,训练一个Reward Model;
对多个排序结果,两两组合,形成多个训练数据对。RM模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
-
Step3 :继续用生成出来的结果训练SFT,并通过强化学习的PPO方法,最大化SFT生成出排序靠前的answer。

5.3 Chain-of-Thought(思维链)
思维链在2022年初由谷歌团队提出,其旨在进一步提高超大规模模型在一些复杂任务上的推理能力。其认为现有的超大规模语言模型可能存在下面潜在的问题:
-
增大模型参数规模对于一些具有挑战的任务(例如算术、常识推理和符号推理)的效果并未证明有效;
Scaling up model size alone has not proved sufficient for achieving high performance on challenging tasks such as arithmetic, commonsense, and symbolic reasoning.
-
期望探索如何对大模型进行推理的简单方法:
对于算术类推理任务,期望生成自然语言逻辑依据来指导并生成最终答案;但是获得逻辑依据是比较复杂昂贵的。It is costly to create a large set of high quality rationales, which is much more complicated than simple input–output pairs used in normal machine learning
对某个task,为大模型提供一些上下文in-context example作为prompt;简单的示例可能并非能够提升推理能力。It works poorly on tasks that require reasoning abilities, and often does not improve substantially with increasing language model scale
因此,提出 思维链(Chain-of-Thought) 。思维链的定义如下:A chain of thought is a series of intermediate natural language reasoning steps that lead to the final output, and we refer to this approach as chain-of-thought prompting.
直观理解很简单,思维链是一种特殊的In-Context Learning,对于每个挑选的In-Context Example,除了给出Input-Output Mapping外,还需要给出一个推理过程,称为Relationale或Reasoning Path,其是一个具有逻辑推理过程的短文本,如下图蓝色部分。
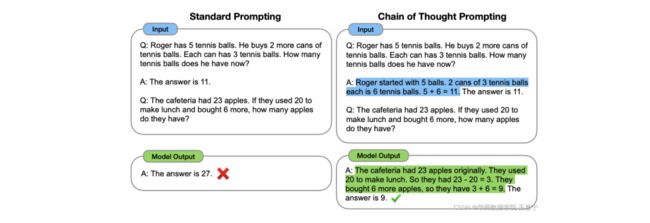
通过引入推理路径作为提示,可以激发大模型按照这种推理的模式生成出合理的结果,引导大模型如何思考、如何推理。
下面介绍几个经典的CoT方法:
(1)Self-consistency Improves Chain Of Thought Reasoning in Language Models:https://arxiv.org/abs/2203.11171
Self-consistency(自我一致性) 建立在一个直觉基础上:即 一个复杂的推理任务,其可以有多种推理路径(即解题思路),最终都能够得到正确的答案 。即所谓 条条大路通罗马 。一个问题越需要深思熟虑的思考和分析,那么七可以得出答案的推理路径就越多样化。
具体方法如下图所示。先从大模型的decoder中采样出一系列个reasoning path,每一个path都能够对应一个最终的答案,我们 可以挑选那些能够得到一致答案的较多的path ,作为我们的采样得到的reasoning path。基于这种直接投票策略,比较符合人类的直觉,即如果很多reasoning path都能得到对应的一个答案,那么这个答案的置信度会比较大。
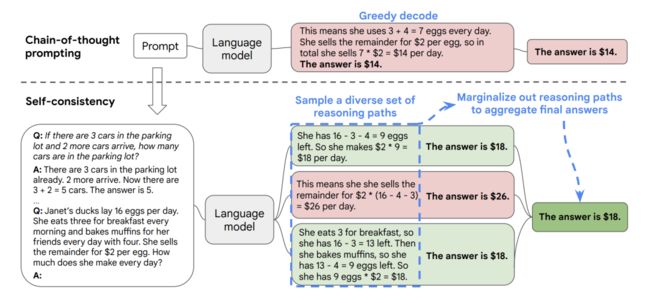
作者也探索了一些其他的投票策略,例如根据logit进行加权等,发现直接投票更合适:

(2)Large Language Models are Zero-Shot Reasoners:https://arxiv.org/abs/2205.11916
CoT需要涉及到人工标注prompt。该工作则发现只需要添加一个固定的prompt:“Lets think step by step” 即可以促使大模型一步步推理来生成结果。
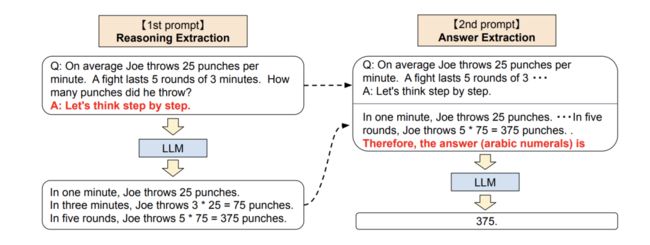
主要包括两个核心步骤:
-
1st prompt:reasoning extraction :先构建模板,得到 ,然后喂入大模型中生存结果 ;
-
2nd prompt:answer extraction :将 拼接起来,再次喂入大模型中,直接生成结果。
(3)Automatic Chain of Thought Prompting in Large Language Models:http://arxiv.org/abs/2210.03493
先前的chain-of-thought包括两种,一种是Zero-shot CoT(let's think step by step),另一种是Manual-CoT(拼接若干样本作为demonstration)。我们发现不论是何种prompt模式,大模型都会生成错误的chains。为了避免这个问题,我们考虑提出一种自动化构建demonstration的方法——Auto-CoT。
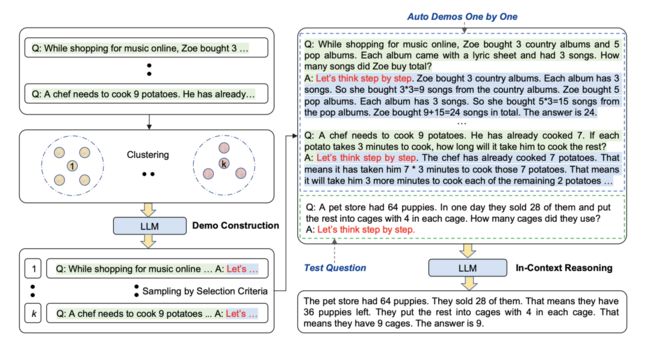
主要包括两个步骤:
(1)Queston Clustering:
使用sentence-BERT对每个question获得表征,然后通过K-means获得若干簇。对于每个簇,按照其距离簇中心距离的大小升序排列。算法如下所示:

(2)Demonstration Sampling:
根据Cluster的结果,采样得到合适的prompt。对于每个簇,采样一个question,并与Let's think step-by-step拼接起来,喂入大模型中生存relationale。最后将 个relationale与对应的question、answer拼接,并拼接目标测试样本,促使大模型生成测试样本的relationale。

Auto-CoT旨在自动选择样本,然后让大模型依次生成出relationale,然后最后拼接所有relationale作为测试样本的提示。
(4)Least-to-Most Prompting Enables Complex Reasoning in Large Language Models:https://arxiv.org/abs/2205.10625
最近CoT的提出进一步拉近了人类与机器智能的距离,通过natural language rationales和self-consistency来提升大模型在推理任务上的性能。然而CoT依然存在一些不足:即其很难对超出demonstration example难度程度的问题进行解答。为此,该工作尝试将一个复杂的任务分解为若干简单的子任务。

在对每个子问题进行预测时,是一个渐近的过程。
-
第一个子问题是最简单的;
-
解决第二个子问题时,会将上一个子问题以及答案附加在当前子问题的前面,而且第二个子问题会比第一个子问题难;
-
最后一个子问题就是原始的问题,此时其会有前面所有子问题的解答作为提示。最简单的情况,就是将一个问题分解为两个子问题,前面所有的子问题可以作为后面子问题的in-context demonstration。
未完待续,期待更多
第六章:ChatGPT与Prompt-Tuning
第七章:Prompt-Tuning技术的应用
第八章:Prompt-Tuning的未来发展
本文参考资料
[1] 【预训练语言模型】Attention Is All You Need(Transformer): https://blog.csdn.net/qq_36426650/article/details/112222115
[2] 【预训练语言模型】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(BERT): https://blog.csdn.net/qq_36426650/article/details/112223838
[3] 《Language Models are Few-Shot Learners》(NIPS2020): https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html
[4] 《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》(EACL2021): https://doi.org/10.18653/v1/2021.eacl-main.20
[5] PET的论文解读: https://wjn1996.blog.csdn.net/article/details/120788059
[6] PTR: Prompt Tuning with Rules for Text Classification: https://arxiv.org/abs/2105.11259
[7] 论文解读:PTR: Prompt Tuning with Rules fo Text Classification: https://wjn1996.blog.csdn.net/article/details/120256178
[8] 《AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts(EMNLP2021): https://aclanthology.org/2020.emnlp-main.346.pdf
[9] 《Making Pre-trained Language Models Better Few-shot Learners》(ACL2021): https://doi.org/10.18653/v1/2021.acl-long.295
[10] 论文解读:Making Pre-trained Language Models Better Few-shot Learners(LM-BFF): https://wjn1996.blog.csdn.net/article/details/115640052
[11] 《The Power of Scale for Parameter-Efficient Prompt Tuning》: https://aclanthology.org/2021.emnlp-main.243.pdf
[12] 《GPT Understands, Too》: https://arxiv.org/pdf/2103.10385
[13] 《PPT: Pre-trained Prompt Tuning for Few-shot Learning》: https://aclanthology.org/2022.acl-long.576.pdf
[14] 论文解读:GPT Understands, Too: https://wjn1996.blog.csdn.net/article/details/120802305
[15] 《RLPROMPT: Optimizing Discrete Text Prompts with Reinforcement Learning》: https://arxiv.org/pdf/2205.12548.pdf
[16] 《Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification》: https://aclanthology.org/2022.acl-long.158.pdf
[17] 《Prototypical Verbalizer for Prompt-based Few-shot Tuning》: https://aclanthology.org/2022.acl-long.483.pdf
[18] 论文解读:Knowledgeable Prompt-tuning: Incorporation Knowledge into Prompt Verbalizer for Text Classification: https://wjn1996.blog.csdn.net/article/details/120790512
[19] 《PromptBERT: Improving BERT Sentence Embeddings with Prompts》: https://arxiv.org/pdf/2201.04337
[20] 《TransPrompt: Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification》: https://aclanthology.org/2021.emnlp-main.221.pdf
[21] 《Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections》: https://aclanthology.org/2021.findings-emnlp.244.pdf
[22] UNIFIEDQA: Crossing format boundaries with a single QA system: https://aclanthology.org/2020.findings-emnlp.171.pdf
[23] ProQA- Structural Prompt-based Pre-training for Unified Question Answering: https://aclanthology.org/2022.naacl-main.313.pdf
[24] 《Unifying Question Answering, Text Classification, and Regression via Span Extraction》: https://arxiv.org/pdf/1904.09286
[25] Global Pointer: https://spaces.ac.cn/archives/8373
[26] 《Entailment as Few-Shot Learner》(EFL): https://arxiv.org/pdf/2104.14690.pdf
[27] NSP-BERT: https://blog.csdn.net/qq_36426650/article/details/122255324
[28] CLIP: https://zhuanlan.zhihu.com/p/512546830
[29] Adapter-Tuning: http://proceedings.mlr.press/v97/houlsby19a.html
[30] Prefix-Tuning: https://aclanthology.org/2021.acl-long.353.pdf
[31] BitFit: https://aclanthology.org/2022.acl-short.1.pdf
[32] P-tuning V2: https://blog.csdn.net/qq_36426650/article/details/120806554
[33] 《UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning》: https://aclanthology.org/2022.acl-long.433.pdf
[34] 《Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models》: https://aclanthology.org/2022.acl-long.433.pdf
[35] 《LiST: Lite Prompted Self-training Makes Parameter-efficient Few-shot Learners》: https://aclanthology.org/2022.findings-naacl.174.pdf
[36] 《Making Parameter-efficient Tuning More Efficient: A Unified Framework for Classification Tasks》: https://aclanthology.org/2022.findings-naacl.174.pdf
[37] 《P-Adapters- Robustly Extracting Factual Information from Language Models with Diverse Prompts》: https://openreview.net/forum?id=DhzIU48OcZh
[38] 《Context-Tuning: Learning Contextualized Prompts for Natural Language Generation》: https://aclanthology.org/2022.coling-1.552.pdf
[39] 《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》: https://aclanthology.org/2022.emnlp-main.759.pdf
[40] 《Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations》: https://aclanthology.org/2022.emnlp-main.155.pdf
[41] 【In-Context Learning】Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?: https://blog.csdn.net/qq_36426650/article/details/129818361?spm=1001.2014.3001.5501
[42] 《What Makes Good In-Context Examples for GPT-3?》: https://aclanthology.org/2022.deelio-1.10.pdf
[43] 《Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity》: https://aclanthology.org/2022.acl-long.556.pdf
[44] 【In-Context Learning】What Makes Good In-Context Examples for GPT-3?: https://wjn1996.blog.csdn.net/article/details/129816707?spm=1001.2014.3001.5502
[45] 《Improving In-Context Few-Shot Learning via Self-Supervised Training》: https://aclanthology.org/2022.naacl-main.260.pdf
[46] 《Meta-learning via Language Model In-context Tuning》: https://doi.org/10.18653/v1/2022.acl-long.53
[47] 《MetaICL: Learning to Learn In Context》: https://github.com/facebookresearch/MetaICL
[48] Self-consistency Improves Chain Of Thought Reasoning in Language Models: https://arxiv.org/abs/2203.11171
[49] Large Language Models are Zero-Shot Reasoners: https://arxiv.org/abs/2205.11916
[50] Automatic Chain of Thought Prompting in Large Language Models: http://arxiv.org/abs/2210.03493
[51] Least-to-Most Prompting Enables Complex Reasoning in Large Language Models: https://arxiv.org/abs/2205.10625