NLP_BERT与GPT争锋
文章目录
- 介绍
- 小结
介绍
在开始训练GPT之前,我们先比较一下BERT和 GPT 这两种基于 Transformer 的预训练模型结构,找出它们的异同。
Transformer架构被提出后不久,一大批基于这个架构的预训练模型就如雨后春笋般地出现了。其中最重要、影响最深远的两个预训练模型当然就是GPT 和 BERT这两个模型。
在ChatGPT震惊世界之前,在自然语言处理领域影响最大的预训练模型是 BERT,很多科研工作都是围绕着BERT 展开的。由于BERT语言理解和推理能力很强,它也适用于很多下游任务。
初代的GPT和 BERT几乎是同时出现的,其实GPT还要稍微早一些。因此,在 BERT 的论文中,特意将二者进行了比较。在下文中,我将用你能够理解的方式来讲解二者的异同,这样你就明白BERT 和 GPT 这两个模型到底是怎么训练出来的了。
在对BERT 做无监督的预训练时,研究人员设计了两个目标任务:一个是将输入的文本中 k% 的单词遮住,然后让它预测被遮住的是什么单词,这个目标任务叫作掩码语言模型(Masked Language Model,MLM);另一个是预测一个句子是否会紧挨着另一个句子出现,这个目标任务叫作下一句预测(Next Sentence Prediction,NSP)。这两个任务在预训练时,数据集都是通过现成的语料文本构建的,标签也是原始语料自带的,所以属于无监督的预训练。其实,从模型参数优化的角度来讲,是有标签指导的。
掩码语言模型,举个例子:随机把“一二三四五,上山打老虎”中的“二”和“打”抠掉,被抠掉的词就成了标签,这样来训练模型的文本理解能力。
自然语言模型的预训练,最不缺的就是数据,比如维基百科、知乎、微博文本,这些平台中有海量的数据。预训练时在大量数据上基于这两个目标(MLM和NSP)对模型进行优化,就形成了预训练好的模型,然后,我们可以把这个基础模型(Foundation Model)的结构和参数一并下载下来,再针对特定任务进行微调,就可以解决下游问题了。BERT适合解决的NLP任务包括文本分类、命名实体识别、完形填空、关系抽取等推理性问题。
GPT也是一种基于Transformer架构的自然语言处理模型,但它与BERT有一些不同之处。
-
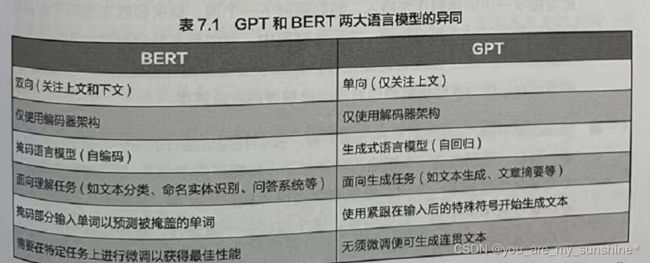
首先,GPT在训练时采用的是单向语境,也就是从左到右的顺序。而BERT则采用了双向的方式,即同时考虑上下文信息。这使得GPT在生成文本时更擅长保持连贯性,但可能在理解某些上下文时不如 BERT。
-
其次,在预训练任务上,GPT的主要任务是基于给定的上下文,预测出现的下一个词。这个任务就是我们之前反复介绍过的语言模型,也被称为语言建模(Language Modeling)。由于GPT 的预训练任务更简单,因此,它在生成文本方面通常表现得更好。
在实际应用中,GPT经过预训练后,可被用于解决各种下游任务,例如文本生成、文本分类、问答系统等,尤其是生成性问题。与BERT一样,GPT的预训练模型可以在大量文本数据上进行训练,然后根据特定任务进行微调,从而解决各种实际问题。
总之,GPT与BERT都是基于Transformer架构的NLP 模型,但在文本理解方式和预训练任务上有所不同。GPT采用单向语境和语言建模任务,而BERT采用双向语境和掩码语言建模及句子预测任务。在实际应用中,它们都可以通过预训练和微调的方式来解决各种 NLP 任务。
从BERT原始论文中的示意图来理解,这张图简单地说明了所谓单向和双向的区别。从宏观上看,BERT和GPT是相似的,图中蓝色的圈圈是Transformer 的隐藏层,其中的缩写Trm其实就是Transformer,而唯一的区别在于每个蓝色圈圈接收到的自注意力信息的方向。
-
BERT整体处理整个序列,既能够关注前面的信息,也能够关注后面的信息,所以是双向编码。在训练过程中,每个位置的向量表示都通过左右两侧的上下文信息一起学习,这样能更好地捕捉句子的语义。
-
GPT的理念就很不相同了。它是通过语言模型的思想,最大化语句序列出现的概率。你不是让我预测吗?那我只能翻来覆去看问题,不能先看答案啊!这就是生成式模型和填空式模型的不同。

总结一下,BERT和GPT 的两个主要区别。
-
第一,BERT是掩码语言模型;GPT 是生成式语言模型。我们这门课程一路以来讲的 N-Gram、Word2Vec、NPLM和 Seq2Seq预测的都是下一个词,其本质都是生成式语言模型。因此,生成式语言模型是语言模型的原始状态,而 BERT 的掩码语言模型“猜词”,是创新。
-
第二,BERT是双向语言模型,每个位置的向量表示都通过上下文信息来一起学习;GPT 是单向语言模型,在解码器的每个自注意力子层中引入了一个掩码(掩蔽)机制,以防止当前位置的注意力权重分配到后续位置。
-
第三, BERT只使用编码器架构;而GPT只使用解码器架构。
编码器的双向模型结构使得BERT能够充分利用上下文信息,因此BERT更适用于理解任务,如文本分类、命名实体识别和问答等,因为它可以同时关注输入序列中的所有单词,而不仅仅是一个方向的信息。
只有解码器架构的GPT是一个单向模型,具有自回归的特点。在训练过程中, GPT模型通过后续注意力掩码,确保每个位置只能看到当前位置之前的信息,这使得 GPT非常适合完成生成任务,如文本生成、文章摘要等。当生成一个序列时,GPT会根据之前生成的上下文信息生成下一个单词。
这两个模型的架构差异(见表7.1)使它们在不同类型的NLP任务中各有优势。 BERT 因其双向上下文关注和编码器架构在理解任务上表现出色,而GPT因其单向自回归特性和解码器架构在生成任务上具有较好的性能。
小结
BERT 因其双向上下文关注和编码器架构在理解任务上表现出色,而GPT因其单向自回归特性和解码器架构在生成任务上具有较好的性能。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…