政安晨:【完全零基础】认知人工智能(二)【超级简单】的【机器学习神经网络】—— 底层算法
如果小伙伴第一次看到这篇文章,可以先浏览一下我这个系列的上一篇文章:
政安晨:【完全零基础】认知人工智能(一)【超级简单】的【机器学习神经网络】 —— 预测机 https://blog.csdn.net/snowdenkeke/article/details/136139504
https://blog.csdn.net/snowdenkeke/article/details/136139504
导入
神经元是神经网络的基本组成单元,其底层算法主要包括输入加权和激活函数两个部分。
首先,神经元接收来自其他神经元传递过来的输入信号,并对每个输入信号进行加权求和。
每个输入信号都有一个对应的权重,用来表示该信号在神经元中的重要性,加权求和的过程可以用下面的公式表示:
[ \text{{加权和}} = \sum_{{i=1}}^n w_i \cdot x_i ]
其中,(w_i)是第(i)个输入信号的权重,(x_i)是第(i)个输入信号的值,(n)是输入信号的数量。
然后,神经元将加权和输入到激活函数中进行处理。激活函数通常是非线性函数,其作用是引入非线性特性,使得神经网络可以学习复杂的问题。激活函数可以是 sigmoid、ReLU、tanh 等。
常用的 sigmoid 激活函数公式如下:
[ f(x) = \frac{1}{1 + e^{-x}} ]
激活函数的输出值被传递给下一层神经元或作为最终的输出结果。
这些底层算法的组合使得神经元能够对输入信号进行权重加权和非线性激活处理,从而实现了神经网络的学习和推理功能。
上面这些复杂的概念,其实可以从简单的理解开始。
开始
每个神经元都与其前后层的每个神经元相互连接的三层神经元,看起来让人相当惊奇。
但是,计算信号如何经过一层一层的神经元,从输入变成输出,这个过程似乎有点令人生畏,这好像是一种非常艰苦的工作。
即使此后,我们将使用计算机做这些工作,但是我认为,这仍然是一项艰苦的工作。
但是这对说明神经网络如何工作非常重要,这样我们就可以知道在神经网络内部发生了什么事情。
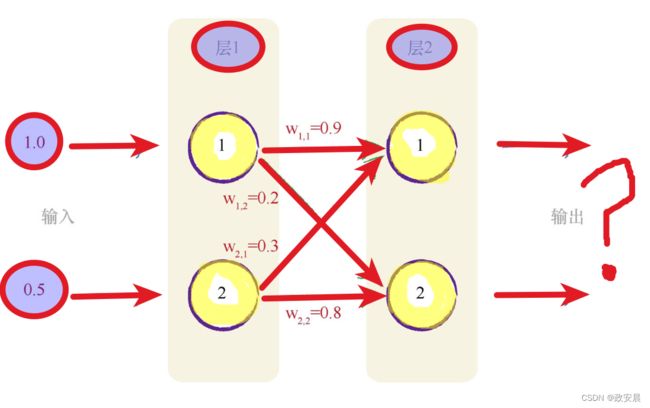
正因如此,咱们尝试使用只有两层、每层两个神经元的较小的神经网络,来演示神经网络如何工作,如下图所示:

咱们想象一下,两个输入值分别为1.0和0.5。
这些值输入到这个较小的神经网络,如下所示:
每个节点使用激活函数,将输入转变成输出。
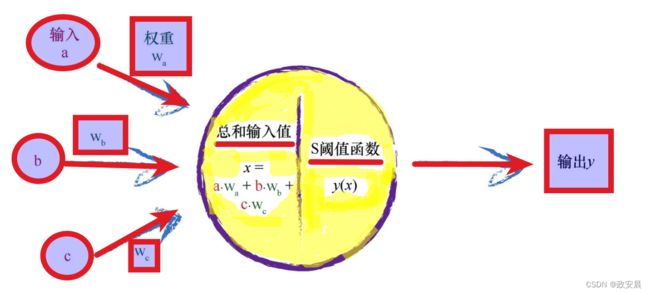
我们还将使用先前看到的S函数 ![]() ,其中神经元输入信号的总和为x,神经元输出为y。
,其中神经元输入信号的总和为x,神经元输出为y。
权重是什么?权重的初始值应该为多少?
让我们使用一些随机权重:
· w1,1=0.9
· w1,2=0.2
· w2,1=0.3
· w2,2=0.8
随机初始值是个不错的主意,这也是我们在先前简单的线性分类器中选择初始斜率值时所做的事情,随着分类器学习各个样本,随机值就可以得到改进。对于神经网络链接的权重而言,这也是一样的。
在这个小型的神经网络中,由于连接每一层中两个节点的组合就只有四种连接方式,因此只有四个权重。
如下图所示:
咱们开始计算如下:
第一层节点是输入层,这一层不做其他事情,仅表示输入信号。
也就是说,输入节点不对输入值应用激活函数。这没有什么其他奇妙的原因,自然而然地,历史就是这样规定的,神经网络的第一层是输入层,这层所做的所有事情就是表示输入,仅此而已。
第一层输入层很容易,此处,无需进行计算。
接下来第二层,我们需要做一些计算。对于这一层的每个节点,我们需要算出组合输入。
还记得上述S函数 ![]() 吗?这个函数中的x表示一个节点的组合输入。此处组合的是所连接的前一层中的原始输出,但是这些输出得到了链接权重的调节。
吗?这个函数中的x表示一个节点的组合输入。此处组合的是所连接的前一层中的原始输出,但是这些输出得到了链接权重的调节。
下图就是我们先前所看到的一幅图,但是现在,这幅图包括使用链接权重调节输入信号的过程:
因此,首先让我们关注第二层的节点1:
第一层输入层中的两个节点连接到了这个节点,这些输入节点具有1.0和0.5的原始值。
来自第一个节点的链接具有0.9的相关权重,来自第二个节点的链接具有0.3的权重。
因此,组合经过了权重调节后的输入,如下所示:
x=(第一个节点的输出 * 链接权重)+(第二个节点的输出 * 链接权重)
x=(1.0 * 0.9)+(0.5 * 0.3)
x=0.9+0.15
x=1.05
咱们不希望看到:不使用权重调节信号,只进行一个非常简单的信号相加1.0+0.5。
权重是神经网络进行学习的内容,这些权重持续进行优化,得到越来越好的结果。
至此,咱们已经得到了x=1.05,这是第二层第一个节点的组合调节输入。最终,我们可以使用激活函数![]() 计算该节点的输出(我的上一篇文章谈到:e的值为 2.71828 ……)。
计算该节点的输出(我的上一篇文章谈到:e的值为 2.71828 ……)。
您甚至可以使用计算器来进行这个计算。
答案为y=1 /(1+0.3499)=1 / 1.3499,因此,y=0.7408。
这个工作真很有意义!
现在,我们得到了神经网络两个输出节点中的一个的实际输出。
让我们继续计算剩余的节点,即第二层第二个节点。
组合调节输入x为:
x=(第一个节点的输出*链接权重)+(第二个节点的输出*链接权重)
x=(1.0 * 0.2)+(0.5 * 0.8)
x=0.2+0.4
x=0.6
因此,现在我们可以使用S激活函数y=1/(1+0.5488)=1/1.5488
计算节点输出,得到y=0.6457。
现在咱们通过计算,将刚刚那一幅神经网络的图补充完整(输出已经补充完整啦)。

从一个非常简化的网络得到两个输出值,这个工作量相对较小。
对于一个相对较大的网络,咱们不希望使用手工进行计算。
好在计算机在进行大量计算方面表现非常出色,并且不知疲倦和厌烦,即便如此,对于具有多于两层,每一层有4、8甚至100个节点的网络,我也不希望编写计算机指令来对这样的网络进行计算。
即使只是写出所有层次和节点的计算指令,也会让我感到枯燥,让我犯错,更不用说手工进行这些计算了。
好在,即使是面对一个具有很多层、众多节点的神经网络,数学可以帮助我们以非常简洁的方式写下计算出所有输出值的指令。由于这种简洁性,指令变得非常短,执行起来也更有效率,因此这种简洁性不仅仅对人类读者有益处,对计算机而言,也一样大有裨益。
这一简洁方法就是使用矩阵,接下来,咱们就尝试矩阵。
矩阵
矩阵很多时候让人闻风丧胆。
它们也唤起了我的记忆,我记得在学校进行矩阵乘法时,那种让人咬牙切齿、枯燥费力的工作,以及那毫无意义的时间流逝。
现在回头来看,还是因为认知的维度不够,站在更高的维度看待矩阵,一切都豁然开朗。
刚刚,我们手工对两层(每一层只有两节点)的神经网络进行计算。
对人类而言,这样的工作量也是足够大了,但是,请你想象一下,我们要对五层、每层100个节点的网络进行相同的计算,这是一种什么感受?单单是写下所有必要的计算,也是一个艰巨的任务……对每一层每一个节点,计算所有这些组合信号的组合,乘以正确的权重,应用S激活函数……
那么,矩阵如何帮助我们简化计算呢?
矩阵在两个方面帮助了我们:
首先,矩阵允许我们压缩所有这些计算,把它们变成一种非常简单的缩写形式。
由于人类不擅长于做大量枯燥的工作,而且也很容易出错,因此矩阵对人类帮助很大。
第二个好处是,许多计算机编程语言理解如何与矩阵一起工作,计算机编程语言能够认识到实际的工作是重复性的,因此能够高效高速地进行计算。
总之,矩阵允许我们简洁、方便地表示我们所需的工作,同时计算机可以快速高效地完成计算。
尽管我们在学校学习矩阵时有一段痛苦的经历,但是现在大家知道咱们为什么要使用矩阵了吧。
让我们开始使用矩阵,揭开矩阵的神秘面纱,矩阵仅仅是一个数字表格、矩形网格而已。
对于矩阵而言,其实已经没有更多复杂的内容了。
以下就是用表格表达的矩阵:

上面的这些就是一张表格或一个数字网格,与下面大小为“2乘以3”的示例矩阵一样:

第一个数字代表行,第二个数字代表列,这是约定,因此,我们不说这是“3乘以2”的矩阵,而是说这是“2乘以3”的矩阵。
(其实这种方式是有好处的,在机器学习领域,我们还把放到最前面的称为样本数)
一些人使用方括号表示矩阵,另一些人与我们一样,使用圆括号表示矩阵。
其实,矩阵的元素也不必是数字,它们也可以是我们命名的、但还未赋予实际的数值的一个量。
因此,以下是这样一个矩阵:
每个元素都是一个变量,具有一定的意义。虽然每个元素也可以具有一个数字数值,但是我们只是还未说明这些数值为多少。

矩阵对机器学习的神经网络很有用处,让我们看看它们是如何相乘的:

这种矩阵的点积运算并不是是简单地将对应的元素进行相乘,而是有着它特有的规则,咱们详细看一下:
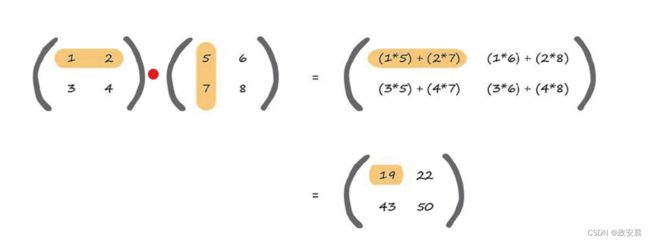
您可以看到:
左上角的元素是通过第一个矩阵的顶行和第二个矩阵的左列计算得出的:
顺着这些行和列,将你遇到的元素进行相乘,并将所得到的值加起来。
因此,为了计算左上角元素的答案,我们开始沿着第一个矩阵的第一行移动,我们找到数字1,当我们开始沿着第二个矩阵的左列移动,我们找到数字5,我们将1和5相乘,得到5。
我们继续沿着行和列移动,找到数字2和7,将2和7相乘,我们得到14,保留这个数字。
我们已经到达了行和列的末尾,因此我们将所有得到的数字相加,即5+14,得到19。
这就是结果矩阵中左上角的元素。虽然这描述起来非常啰嗦,但是,在操作时,这很容易观察得到。
小伙伴们自己可以试一试。
用同样的方式,咱们再看一下右下角元素是如何计算得出的:
在下图中,你可以观察到我们尝试计算的所对应的行和列(在这个示例中,是第二行和第二列),我们得到(3×6)和(4×8),最后得到18+32=50。
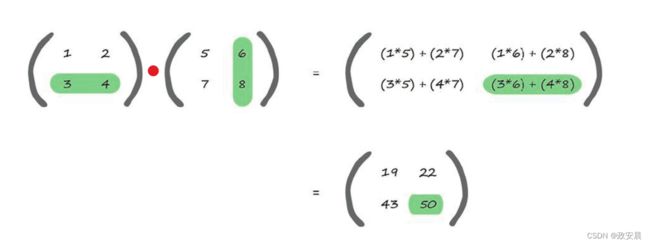
左下角的元素计算公式为(3 * 5)+(4 * 7)=15+28=43。
同样地,右上角元素的计算公式为(1 * 6)+(2 * 8)=6+16=22。
下面我们使用变量,而不是数字,来详细说明规则:
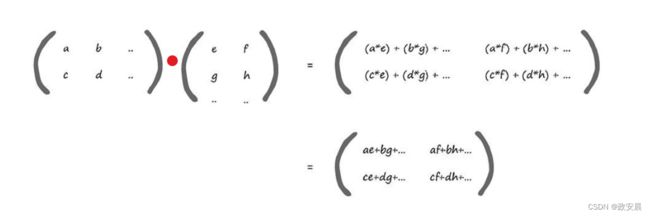
这是我们说明矩阵相乘方法的另一种方式。
使用代表任意数字的字母,我们可以更加清晰地理解矩阵相乘的一般规则。
这种规则可以应用到各种大小的矩阵上,因此是一种通用规则。
虽然我们说这种方法适用于不同大小的矩阵,但这里有一个重要的限制:
你不能对两个任意矩阵进行乘法运算,这两个矩阵需要互相兼容。
你可能已经观察到了:第一个矩阵的行和第二个矩阵的列,这两者应该是互相匹配的。
如果行元素的数量与列元素的数量不匹配,那么这种方法就行不通了。
你不能将“2乘以2”的矩阵与“5乘以5”的矩阵相乘。你可以尝试一下,就明白为什么这行不通了。为了能够进行矩阵相乘,第一个矩阵中的列数目(一行中的元素数)应该等于第二个矩阵中的行数目(一列中的元素数)。
在机器学习的神经网络领域里,你会经常看到这样的矩阵乘法称为点乘(dot product)或内积(inner product)。实际上,对于矩阵而言,有不同类型的乘法,比如叉乘,但是我们此处所指的是点乘。
请仔细观察,如果我们将字母换成对神经网络更有意义的单词,那么会发生什么情况呢?
虽然第二个矩阵是2乘以1的矩阵,但是乘法规则是相同的。
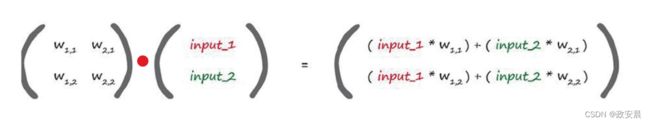
关键点来了:
第一个矩阵包含两层节点之间的权重。
第二个矩阵包含第一层输入层的信号。
通过两个矩阵相乘,我们得到的答案是输入到第二层节点组合调节后的信号,仔细观察,你就会明白这点。
由权重w1,1调节的input_1加上由权重w2,1调节的input_2,就是第二层第一个节点的输入值。
这些值就是在应用S函数之前的x的值。
见下图:

这件事非常有用,而且是人工智能神经网络里最重要的事之一。
为什么呢?
因为我们可以使用矩阵乘法表示所有计算,计算出组合调节后的信号x,输入到第二层的节点中。
我们可以使用下式,非常简洁地表示:
X=W·I
此处,W是权重矩阵,I是输入矩阵,X是组合调节后的信号,即输入到第二层的结果矩阵。
矩阵通常使用斜体显示,表示它们是矩阵,而不是单个数字。
现在,我们不需要在乎每一层有多少个节点。
如果我们有较多的节点,那么矩阵将会变得较大,但是,我们不需要写出长长的一串数字或大量的文字。
我们可以简单地写为W·I,不管I有2个元素还是有200个元素。
现在,如果计算机编程语言可以理解矩阵符号,那么计算机就可以完成所有这些艰辛的计算工作,算出 X=W·I,而无需我们对每一层的每个节点给出单独的计算指令。
只要努力一点,理解矩阵乘法,就可以找到如此强大的工具,这样我们无需花费太多精力就可以实现神经网络了。
有关激活函数,我们该了解些什么呢?
激活函数其实很简单,并不需要矩阵乘法。
我们所需做的,是对矩阵X的每个单独元素应用S函数 ![]() 。
。
此处,我们不需要组合来自不同节点的信号,我们已经完成了这种操作,答案就在X中。
虽然这听起来如此简单,但是这是正确的。
正如我们先前看到的,激活函数只是简单地应用阈值,使反应变得更像是在生物神经元中观察到的行为:
因此,来自第二层的最终输出是:
O=sigmoid(X)
斜体的O代表矩阵,这个矩阵包含了来自神经网络的最后一层中的所有输出。
表达式 X=W·I 适用于前后层之间的计算。
比如说,我们有3层,我们简单地再次进行矩阵乘法,使用第二层的输出作为第三层的输入。
当然,这个输出应该使用权重系数进行调节并进行组合,理论已经足够了,现在,让我们看看这如何在一个真实示例中工作。
总之,
通过神经网络向前馈送信号所需的大量运算可以表示为矩阵乘法。
不管神经网络的规模如何,将输入输出表达为矩阵乘法,使得我们可以更简洁地进行书写。
一些计算机编程语言理解矩阵计算,并认识到潜在的计算方法的相似性,这允许计算机高速高效地进行这些计算。