Go很适合用来开发高性能网络应用,但仍然需要借助有效的工具进行性能分析,优化代码逻辑。本文介绍了如何通过go test benchmark和pprof进行性能分析,从而实现最优的代码效能。原文: Profiling Go Applications in the Right Way with Examples

什么是性能分析?
性能分析(Profiling) 是分析应用程序从而识别阻碍应用性能的瓶颈的基本技术,有助于检测代码的哪些部分执行时间太长或消耗太多资源(如CPU和内存)。
分析方法
有三种分析方法。
- Go test(包含基准测试)
- 基于runtime/pprof的运行时分析
- 基于net/http/pprof的Web分析
分析类型
- CPU (收集应用程序CPU使用情况的数据)
- 堆(Heap)/内存(Memory) (收集应用程序内存使用情况的数据)
- Goroutine (识别创建最多Goroutine的函数)
- 阻塞 (识别阻塞最多的函数)
- 线程 (识别创建线程最多的函数)
- 互斥锁 (识别有最多锁竞争的函数)
本文将主要关注使用上述方法进行CPU和内存分析。
1. 基准测试(Benchmarking)
我想实现著名的两数之和算法,这里不关注实现细节,直接运行:
go test -bench=.-bench参数运行项目中的所有基准测试。

根据上面的输出,与其他方法相比,TwoSumWithBruteForce是最有效的方法。别忘了结果取决于函数输入,如果输入一个大数组,会得到不同的结果。
如果输入go help testflag,将看到许多参数及其解释,比如count、benchtime等,后面将解释最常用的参数。
- 如果要运行特定函数,可以通过如下方式指定:
go test -bench='BenchmarkTwoSumWithBruteForce'- 默认情况下,基准测试函数只运行一次。如果要自定义,可以使用
count参数。例如,
go test -bench='.' -count=2输出如下所示。

- 默认情况下,Go决定每个基准测试操作的运行时间,可以通过自定义
benchtime='2s'指定。
可以同时使用count和benchtime参数,以便更好的度量基准函数。请参考How to write benchmarks in Go。
示例代码请参考Github。
在现实世界中,函数可能既复杂又长,计时毫无作用,因此需要提取CPU和内存分析文件以进行进一步分析。可以输入
go test -bench='.' -cpuprofile='cpu.prof' -memprofile='mem.prof'然后通过pprof工具对其进行分析。
1.1 CPU分析
如果输入
go tool pprof cpu.prof并回车,就会看到pprof交互式控制台。

我们来看看最主要的内容。
- 输入
top15查看执行期间排名前15的资源密集型函数。 (15表示显示的节点数。)

为了解释清楚,假设有一个A函数。
func A() {
B() // 耗时1s
DO STH DIRECTLY // 耗时4s
C() // 耗时6s
}flat值和cum值计算为: flat值为A=4, cum值为A=11(1s + 4s + 6s) 。
- 如果要基于cum进行排序,可以键入
top15 -cum。也可以分别使用sort=cum和top15命令。 - 如果通过
top获得更详细的输出,可以指定granularity选项。例如,如果设置granularity=lines,将显示函数的行。

得益于此,我们可以识别导致性能问题的函数的特定行。
- 输出还显示了运行时函数和用户自定义函数。如果只想关注自己的函数,可以设置
hide=runtime并再次执行top15。

可以通过输入hide=来重置。
- 此外,可以使用
show命令。例如,输入show=TwoSum

- 如果只关注指定节点,可以使用
focus命令。例如关注TwoSumOnePassHashTable,显示为

可以输入focus=来重置。
- 如果需要获取该功能的详细信息,可以使用
list命令。例如,想获得关于TwoSumWithTwoPassHashTable函数的详细信息,输入list TwoSumWithTwoPassHashTable

- 如果要查看图形化的调用栈,可以键入
web。


后面将提供更多关于分析图表的细节。
- 还可以键入
gif或pdf以与他人共享相应格式的分析数据。
1.2 内存分析
如果输入go tool pprof mem.prof并回车


注意,上面提到的flat和cum是相同的东西,只是测量不同的东西(CPU单位ms,内存单位MB)。
- list命令

- web命令

可以使用CPU分析部分中提到的所有命令。
下面看一下另一个方法,runtime/pprof。
2. 基于runtime/pprof的运行时分析
基准测试对单个函数的性能很有用,但不足以理解整体情况,这时就需要用到runtime/pprof。
2.1 CPU分析
基准测试内置CPU和内存分析,但如果需要让应用程序支持运行时CPU分析,必须首先显示启用。

如果执行go run .,将看到生成的cpu.prof文件,可以通过基准测试部分提到的go tool pprof cpu.prof对齐进行分析。
本节将介绍我最喜欢的特性之一pprof.Labels。此特性仅适用于CPU和goroutine分析。
如果要向特定函数添加一个或多个标签,可以使用pprof.Do函数。
pprof.Do(ctx, pprof.Labels("label-key", "label-value"), func(ctx context.Context) {
// 执行标签代码
})例如,

在pprof交互式控制台中,键入tags,将显示带了有用信息的标记函数。

可以用标签做很多事情,阅读Profiler labels in Go可以获得更多信息。
pprof还有很棒的web界面,允许我们使用各种可视化方式分析数据。
输入go tool pprof -http=:6060 cpu.prof,localhost:6060将被打开。 (为了更清楚,我去掉了pprof.Labels)
让我们深入探讨图形表示。

节点颜色、字体大小、边缘粗细等都有不同含义,参考pprof: Interpreting the Callgraph获取更多细节。可视化使我们能够更容易识别和修复性能问题。
单击图中的节点,可以对其进行细化,我们可以根据自己的选择对可视化进行过滤。下面展示了部分内容(focus、hide等)。

还可以看到其他可视化选项。

上面出现了peek和source(作为list命令),因此下面将介绍火焰图(Flame Graph)")。火焰图提供了代码时间花费的高级视图。

每个函数都用一个彩色矩形表示,矩形的宽度与该函数花费的时间成正比。

可以访问Github获取源码。
2.2 内存分析
如果需要向应用程序添加运行时内存分析,必须显式启用。
可以访问Github获取源码。
如果执行go run .,将看到生成的mem.prof文件,可以用之前基准测试部分提到的go tool pprof mem.prof对齐进行分析。
下面将介绍两个更有用的命令tree和peek。
tree显示了执行流的所有调用者和被调用者。

从而帮助我们识别执行流并找出消耗最多内存的对象。 (不要忘记使用granularity=lines,它提供了更可读的格式。)
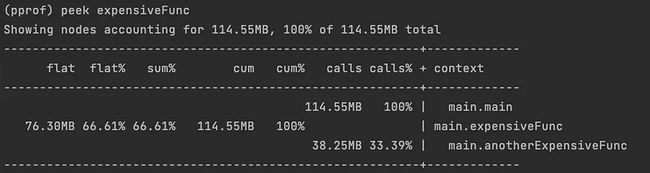
- 如果希望查看特定函数的执行流程,可以使用
peek命令。例如,peek expensiveFunc显示如下
- 还可以使用pprof web界面进行内存分析。输入
go tool pprof -http=:6060 mem.prof,打开localhost:6060。

3. 基于net/http/pprof的Web分析
runtime/pprof包提供了Go程序性能分析的低级接口,而net/http/pprof为分析提供了更高级的接口,允许我们通过HTTP收集程序分析信息,所需要做的就是:

输入localhost:5555/debug/pprof,就能在浏览器上看到所有可用的分析文件。如果没有使用stdlib,可以查看fiber、gin或echo的pprof实现。

文档里记录了所有用法和参数,我们看一下最常用的。
获取CPU分析数据及技巧
go tool pprof http://localhost:5555/debug/pprof/profile?seconds=30在CPU分析期间,请注意
runtime.mallogc → 表示可以优化小堆分配的数量。
syscall.Read或者syscall.Write → 表示应用程序在内核模式下花费了大量时间,为此可以尝试I/O缓冲。
获取堆(采样活跃对象内存分配)分析数据及技巧
go tool pprof http://localhost:5555/debug/pprof/heap
go tool pprof http://localhost:5555/debug/pprof/heap?gc=1就我个人而言,我喜欢用GC参数诊断问题。例如,如果应用程序有内存泄漏问题,可以执行以下操作:
- 触发GC(浏览器访问/debug/pprof/heap?gc=1)
- 下载堆数据,假设下载文件名为file1
- 等待几秒或几分钟
- 再次触发GC(浏览器访问/debug/pprof/heap?gc=1)
- 再次下载堆数据,假设下载文件名为file2
- 使用diff_base进行比较
go tool pprof -http=:6060 -diff_base file2 file1
获取内存分配(抽样过去所有的内存分配)分析数据及技巧
go tool pprof http://localhost:5555/debug/pprof/allocs在内存分配分析期间,可以这样做
- 如果看到
bytes.growSlice,应该考虑使用sync.Pool。 - 如果看到自定义函数,请检查是否在切片或映射中定义了固定容量。
延伸阅读
- pprof Github Readme
- Profiling Go Programs by Russ Cox
- pprof man page
- GopherCon 2019: Dave Cheney — Two Go Programs, Three Different Profiling Techniques
- GopherCon 2021: Felix Geisendörfer — Go Profiling and Observability from Scratch
- GopherConAU 2019 — Alexander Else — Profiling a go service in production
- Practical Go Lessons Profiling Chapter
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!
本文由mdnice多平台发布