什么是MVCC
数据库的四种事务隔离级别,可以通过加锁的方式来实现,只是效率太低,事实上,MySQL 是通过 MVCC(多版本并发控制)来实现的。
具体原理有一点点复杂,需要你用点心才能看懂,今天我们就以「可重复读隔离级别」为例来详细说明其具体原理。
假设数据库有如下记录。

我们都知道 InnoDB 引擎下,每一个事务都有一个事务 ID,叫做 transaction id,是在事务开始时系统自动分配的,且该 id 是递增的。同时这个 id 也会记录在数据行上面。言外之意就是数据库表的每行记录是有多个版本的,用事务 ID 来标示这行记录是属于哪个事务操作的。既然是有多个版本,那怎么拿到旧版本的数据记录呢,答案就是在添加一个指针,指向前一个事务 ID 标识的记录。
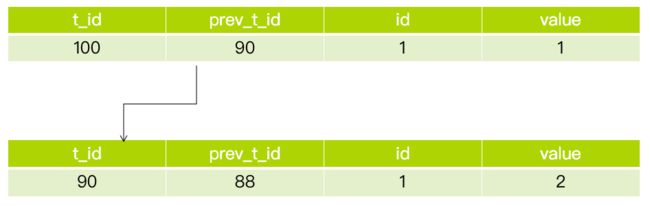
而这个指针就是我们通常诉所说的 undo log,事实上,旧版本的行记录都不是物理存在的,而是通过 undo log 实时计算出来的。
一致性视图
好了,了解了行记录事务 ID 和回滚指针的概念之后,我们来看看一致性视图。
当在一个事务 A 中查询数据时,只需要确定行记录的数据版本是否在事务 A 启动之前生成的即可,如若是,则可见;否则不可见,则需通过回滚指针找到上一个版本来继续判断属否可见,
因此,就需要在事务启动时,为该事务构造一个事务数组,用来保存该事务启动瞬间,系统中正在活跃的所有事务 ID,也就是启动了但还未提交的事务 ID。
数组中的最小值我们简记为低位,系统中的最大事务 ID 记录为高位,正是这个高位和视图数组组成了我们说的「一致性视图」。
因此,对于任何一个事务 A 来说,任何数据版本的可见行都可以通过一致性视图来得到。
-
如果数据版本小于低位,说明是已经提交的记录,则可见。
-
如果大于高位,说明是由未来的事务生成的,则不可见。
-
如果在高位和低位之间:
-
若在数组中,说民该事务还未提交,则不可见,
-
如果不在数组中,说明该事务是已经提交了的,则可见。
-
实战分析
我们针对上图的数据记录,假设有以下三个事务,我们来具体分析下,其一致性视图是怎么样的。

假设(1,1)这行记录的事务 ID 是 90;事务 A 开启前,系统里面只有一个活跃的事务,ID = 99;事务 A、B、C 的版本号分别是 100、101、102。
现在,事务 A、B、C 的视图数组和高位分别是[99,100]/101,[99,100,101]/102,[99,100,101,102]/103。
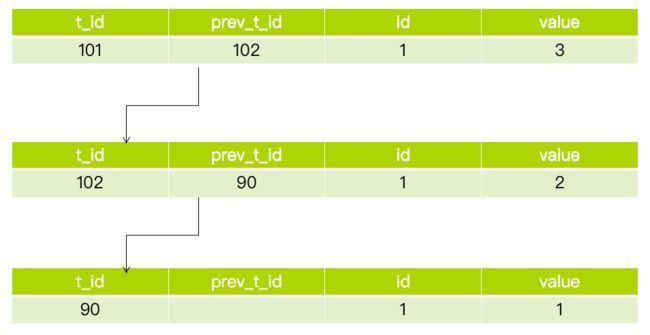
你要知道,读取数据是从当前版本往前读的,对于事务 A 来说:
-
当读取到 (1,3) 的时候,事务 ID = 101,高于高位,不可见。
-
往前读取历史版本(1,2),事务 ID = 102,高于高位,不可见。
-
继续往前读取历史版本(1,1),事务 ID = 90,低于低位,可见。
这样,我们就通过一致性视图和事务 ID 找到了可见的数据版本,不论事务 A 是什么时候查询的,看到的记录都是一致的。
读提交
上面我们分析了可重复读隔离级别下的一致性视图,那么在读取提交的隔离级别下,又是怎么样的呢?
事实上,他们最主要的区别就是一致性视图的创建时间不一样,对于可重复读隔离级别,一致性视图是在事务开启时刻生成的,之后在该事务中的查询都共用这个一个视图。而对于读提交隔离级别,每一个语句执行前都会生成一个新的视图。
因此,事务 A、B、C 的视图数组和高位分别是[99,100,101]/103,[99,101]/103,[99,102]/103。
对于事务 A 来说:
-
当读取到 (1,3) 的时候,事务 ID = 101,在数组中,不可见。
-
往前读取历史版本(1,2),事务 ID = 102,不在数组中,可见。
总结
今天我们学习了 MVCC(多版本并发控制)的底层实现方式,虽然过程略显复杂,但这保证了在不加锁的情况下,保证了可重复读,和读提交。读写不互相干扰,能极大的提高并发能力。
别看上面的分析步骤较复杂,事实上我们只需要记住以下两条规则即可。在可重复读隔离级别下,查询只能看到在事务启动前已经提交的数据。在读提交隔离级别下,查询只能看到在语句启动前已经提交的数据。
参考
极客时间 「MySQL实战45讲 08节」。