flink中的分区、分组与分流
flink中的分区、分组与分流
在flink中有三个看似相似实则完全不同的概念:分区、分组与分流
下面逐个介绍三者的特点和区别。
分区
分区是将数据流划分为多个自己,这些子集可以在不同的任务实例上进行处理,以实现数据的并行处理。
数据具体去往哪个分区,是通过指定的 key 值先进行一次 hash 再进行一次 murmurHash,通过上述计算得到的值再与并行度进行相应的计算得到。
简而言之,分区==并行度。分区的个数由并行度所决定。
如图1所示,kafka中一个主题有两个分区。flink中的分区分别消费kafka中同一个topic的不同分区中的数据。

分组
分组是将具有相同键值的数据元素归类到一起,以便进行后续操作(如聚合、窗口计算等)。
key值相同的数据将进入同一个分组中。
数据如果具有相同的key将一定去往同一个分组和分区,但是同一分区中的数据不一定属于同一组。
如图2所示,即同一分区的数据在分组后在同一分区的不同组中,不同分区的数据在分组后一定不再同一分区中。

//以下代码展示了如何使用flink进行keyby操作以进行分组
package com.flink.DataStream.Aggregation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class FlinkKeyByDemo {
public static void main(String[] args) throws Exception {
//TODO 创建Flink上下文执行环境
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度为1
streamExecutionEnvironment.setParallelism(1);
//设置执行模式为批处理
streamExecutionEnvironment.setRuntimeMode(RuntimeExecutionMode.BATCH);
//TODO source 从集合中创建数据源
DataStreamSource<String> dataStreamSource = streamExecutionEnvironment.fromElements("hello word", "hello flink");
//TODO 方式一 匿名实现类
SingleOutputStreamOperator<Tuple2<String, Integer>> outputStreamOperator1 = dataStreamSource
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] s1 = s.split(" ");
for (String word : s1) {
collector.collect(word);
}
}
})
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
Tuple2<String, Integer> aa = Tuple2.of(s, 1);
return aa;
}
})
/**
* keyBy 得到的结果将不再是 DataStream,而是会将 DataStream 转换为 KeyedStream(键控流)
* KeyedStream 可以认为是“分区流”或者“键控流”,它是对 DataStream 按照 key 的一个逻辑分区
* 所以泛型有两个类型:除去当前流中的元素类型外,还需要指定 key 的类型。
* */
/**
* 分组和分区在Flink 中具有不同的含义和作用:
* 分区:分区(Partitioning)是将数据流划分为多个子集,这些子集可以在不同的任务实例上进行处理,以实现数据的并行处理。
* 数据具体去往哪个分区,是通过指定的 key 值先进行一次 hash 再进行一次 murmurHash,通过上述计算得到的值再与并行度进行相应的计算得到。
* 分组:分组(Grouping)是将具有相同键值的数据元素归类到一起,以便进行后续操作 (如聚合、窗口计算等)。
* key 值相同的数据将进入同一个分组中。
* 注意:数据如果具有相同的key将一定去往同一个分组和分区,但是同一分区中的数据不一定属于同一组。
* */
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
})
.sum(1);
//TODO 方式二 Lamda表达式实现
SingleOutputStreamOperator<Tuple2<String, Integer>> outputStreamOperator2 = dataStreamSource
.flatMap((String s, Collector<String> collector) -> {
String[] s1 = s.split(" ");
for (String word : s1) {
collector.collect(word);
}
})
.returns(Types.STRING)
.map((String word) -> {
return Tuple2.of(word, 1);
})
//Java中lamda表达式存在类型擦除
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy((Tuple2<String, Integer> s) -> {
return s.f0;
})
.sum(1);
//TODO sink
outputStreamOperator1.print("方式一");
outputStreamOperator2.print("方式二");
//TODO 执行
streamExecutionEnvironment.execute("Flink KeyBy Demo");
}
}
分流
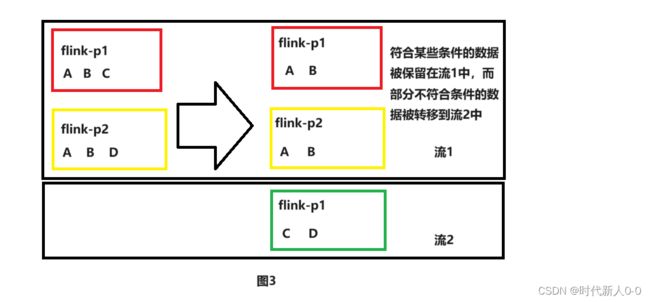
分流主要是指flink中的侧输出流操作。
所谓侧流输出(也叫旁路输出),指的是通过对读取的数据源(DataStream),根据不同的业务规则进行条件筛选,然后根据筛选后生成的不同数据分支,做不同的业务目的输出(比如写到不同的数据目的地中)。
如图3所示,当需要筛选出部分数据进行单独处理时,就可以将其分流至流2(即侧输出流)。
//侧输出流示例
package com.stream.streaming.splitflow;
import com.happy.common.model.MetricEvent;
import com.happy.common.utils.KafkaConfigUtil;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
public class SideOutput {
private static final OutputTag<MetricEvent> machineTag = new OutputTag<MetricEvent>("machine");
private static final OutputTag<MetricEvent> dockerTag = new OutputTag<MetricEvent>("docker");
private static final OutputTag<MetricEvent> applicationTag = new OutputTag<MetricEvent>("application");
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 构建数据源
DataStreamSource<MetricEvent> metricEventDataStreamSource = KafkaConfigUtil.buildSource(env);
/**
* ProcessFunction
* KeyedProcessFunction
* CoProcessFunction
* ProcessWindowFunction
* ProcessAllWindowFunction
* 这里不只是ProcessFunction可以实现该sideOutput,上面的函数同样可以实现
*/
SingleOutputStreamOperator<MetricEvent> sideOutputResult = metricEventDataStreamSource.process(new ProcessFunction<MetricEvent, MetricEvent>() {
@Override
public void processElement(MetricEvent metricEvent, Context context, Collector<MetricEvent> collector) throws Exception {
String s = metricEvent.getTags().get("type");
switch (s) {
case "machine":
context.output(machineTag, metricEvent);
case "docker":
context.output(dockerTag, metricEvent);
case "application":
context.output(applicationTag, metricEvent);
default:
collector.collect(metricEvent);
}
}
});
DataStream<MetricEvent> docker = sideOutputResult.getSideOutput(dockerTag);
DataStream<MetricEvent> application = sideOutputResult.getSideOutput(applicationTag);
DataStream<MetricEvent> machine = sideOutputResult.getSideOutput(machineTag);
docker.print();
application.print();
machine.print();
env.execute("SideOutput App start");
}
}