多模态推荐系统综述
推荐系统(RS)已经成为在线服务不可或缺的工具。它们集成了各种深度学习技术,可以根据标识符和属性信息对用户偏好进行建模。随着短视频、新闻等多媒体服务的出现,在推荐的同时了解这些内容变得至关重要。此外,多模态特征也有助于缓解RS中的数据稀疏问题。因此,多模态推荐系统(multimodal recommendations System, MRS)近年来受到了学术界和业界的广泛关注。在本文中,我们将主要从技术角度对MRS模型进行全面的综述。本文首先总结了MRS模型的一般流程和面临的主要挑战,然后分别从特征交互、特征增强和模型优化三个方面介绍了现有的MRS模型。为了方便那些想要研究这个领域的人,我们还总结了数据集和代码资源。最后,我们讨论了一些有希望的发展方向,并对本文进行了总结。
1,引言
随着互联网的发展,出现了许多多媒体在线服务,如时尚推荐[9]、音乐推荐[11]等。近年来,得益于多模态研究[1]的发展,多模态推荐系统(multi - modal recommender systems, MRS)被设计和应用。一方面,MRS可以处理不同模态的信息,这是多媒体业务固有的特性;另一方面,MRS还可以利用项目丰富的多模态信息来缓解推荐系统中广泛存在的数据稀疏和冷启动问题。
一般来说,推荐系统利用协同信息或辅助信息,即项目的标识符(缩写为id)和列表特征。相比之下,多模态特征,如图像、音频和文本,在MRS中起着至关重要的作用。为简单起见,我们将MRS定义为:具有多模态特征的项目推荐系统。
越来越多的研究关注于MRS,因此迫切需要对其进行综述和分类。虽然现有的综述[10]已经迈出了很好的一步,但它们按照实际应用中的不同模态组织研究。与那篇综述不同的是,我们从MRS. s中使用的技术的角度组织了本篇综述。此外,我们试图收集所有最近的论文,以帮助读者了解该领域的最新进展。然后,我们将在本节的其余部分介绍一般过程和分类,以使综述更具可读性。
1.1 多模态推荐系统的流程
根据MRS的输入项,我们总结出MRS的统一流程,如图1所示。该方法分为三个步骤:原始特征提取、特征交互和推荐。我们以电影推荐为例,说明如下:

原始特征提取。每部电影都有两类特征,即表格特征和多模态特征,包括海报图像和文本介绍。嵌入层用于处理表格式特征,这类似于常见的基于内容的RS[19]。多模态特征被送入不同的模态编码器。模态编码器提取表示,是用于其他领域的通用架构,如用于图像的ViT[13]和Bert[12]文本。然后,我们可以得到每个物品的表格特征和多模态特征(即图像和文本)的表示,记为v,v和v。
特征交互。我们得到了每个项目的不同模态的表示,但它们处于不同的语义空间。此外,不同用户对模态的偏好也存在差异。因此,在这个过程中,MRS试图融合和交互多模态表示v,v和v,以获得项目和用户表示,这对推荐模型很重要。
推荐。在第二个过程之后,我们得到用户和物品的表示,分别表示为v和v。一般的推荐模型吸收了这两种表示并给出推荐概率,例如MF[22]。然而,数据稀疏性问题往往会降低推荐性能。因此,许多研究提出通过融合多模态信息来增强表示。
1.2 分类学
根据上述流程,我们总结出以下三个挑战:
挑战1。如何融合不同语义空间中的模态特征,得到对每种模态的偏好。
挑战2。如何在数据稀疏条件下获得推荐模型的综合表示。
挑战3。如何优化轻量级推荐模型和参数化模态编码器。
最近的工作旨在提出有效的技术来解决这3个挑战,因此将它们分为3个相应的分类:特征交互、特征增强和模型优化。第一类关注挑战1,主要通过GNN和注意力技术融合和捕获各种模态特征。如图1所示,这些工作都是针对MRS. 2中的第二个过程。关于特征增强的研究提出使用对比学习和解缠学习来增强有限数据下物品和用户的表示,即挑战2。值得注意的是,这些工作总是与MRS. s中的推荐过程密切相关。为了应对挑战3,模型优化工作设计了高效的方法来训练模型,包括轻量级的推荐模型和参数化的模态编码器。这些工作都涉及到MRS的整个过程,我们知道,我们是第一个以这样的技术方式组织MRS的工作。我们根据表1中的类别对现有工作进行了总结。

2,特征交互
多模态数据是指描述信息的多种模态。由于它们是稀疏的,并且在不同的语义空间中,将它们与推荐任务连接起来是至关重要的。特征交互可以实现特征空间到公共空间的非线性转换,最终提升推荐模型的性能和泛化能力。如图2所示,我们将交互分为三种类型:桥接、融合和过滤。这三种技术从不同的角度实现交互,因此它们可以同时应用于一个MRS模型。

2.1 桥接
这里的桥梁指的是多通道信息传递通道的构建。它关注于捕获用户和物品之间的相互关系,同时考虑了多模态信息。多媒体推荐与传统推荐的区别在于推荐项目包含丰富的多媒体信息。大多数早期工作只是简单地使用多模态内容来增强物品的表达,但往往忽略了用户与物品之间的交互。图神经网络的消息传递机制可以通过用户与项目之间的信息交换增强用户表征,进一步捕获用户对不同模态信息的偏好。图2(a)给出了一个例子:许多作品通过聚合每个模态的交互项目来获得用户1的偏好。此外,电影1的模态表示可以从潜在的项目-项目图中推导出来。在这一小节中,我们将介绍如何在MRS中建立桥梁的方法。
2.1.1 用户物品图
利用用户和物品之间的信息交换,可以捕获用户对不同模态的偏好。因此,有些工作利用了用户-物品图。MMGCN[51]为每个模态建立一个用户-物品二部图。对于每个节点,可以利用相邻节点的拓扑结构和项目的模态信息来更新节点的特征表达。GRCN[55]在MMGCN的基础上提高了性能通过在模型训练期间自适应地修改图的结构来删除不正确的交互数据(用户点击了无趣的视频)。尽管这些方法在性能上取得了巨大的成功,但这些方法仍然局限于采用统一的方式融合不同模态的用户偏好,忽略了用户对不同模态偏好程度的差异。换句话说,给每个模态均等的权重可能会导致模型的性能次优。针对这一问题,DualGNN[47]在二分图和用户共现图的基础上,利用用户之间的相关性来学习用户偏好。同时,MMGCL[54]设计了一种新的多模态图对比学习方法来解决该问题。MMGCL使用模态边缘损失和模态掩蔽来生成用户-项目图,并引入一种新的负采样技术来学习模态之间的相关性。MGAT[44]引入了基于MMGCN的注意力机制,有利于自适应捕捉用户对不同模态的偏好。此外,MGAT采用门控注意力机制判断用户对不同模态的偏好,能够捕获隐藏在用户行为中相对复杂的交互模式。
2.1.2 物品物品图
上述工作集中于使用多模态特征对用户-物品交互进行建模,而忽略了潜在的语义物品-物品结构。合理利用项目-项目结构有利于更好地学习项目表示,提升模型性能。例如,LATTICE[58]基于用户-项目二部图为每个模态构造一个项目-项目图。将它们聚合起来得到潜在项图。MICRO[59]还为每个模态构建一个项目-项目图。与LATTICE不同的是,MICRO在进行图卷积后采用了一种新的比较方法来融合特征。然而,这些工作没有考虑到不同特定用户群体之间的偏好差异。此外,HCGCN[38]提出了一种聚类图卷积网络,该网络首先对物品-物品和用户-物品图进行分组,然后通过动态图聚类学习用户偏好。此外,受最近预训练模型成功的启发,PMGT[33]提出了一种参考Bert结构的预训练图transformer,并以多模态形式提供了项目关系及其相关辅助信息的统一视图。BGCN[3]模型将用户-物品交互、用户-物品交互和物品-物品从属关系统一到一个异构图中,利用图卷积提取精细化的未来。Cross-CBR[37]构建用户-包图、用户-物品图和物品-包图,使用对比学习从包视图和物品视图中对齐它们。
2.1.3 知识图
知识图谱(KG)因能够为推荐系统提供辅助信息而被广泛应用。为了将KG和MRS结合起来,许多研究者将物品的每一种模态引入KG作为一个实体。MKGAT[43]是第一个将知识图谱引入多模态推荐的模型。MKGAT提出一种多模态图注意力技术,分别从实体信息聚合和实体关系推理两个方面对多模态知识图谱进行建模。此外,采用一种新颖的图注意力网络在考虑知识图谱中关系的同时对邻近实体进行聚合。SI-MKR[50]提出了一种基于交替训练的增强多模态推荐方法和基于MKR[45]的知识图谱表示。此外,大多数多模态推荐系统忽略了数据类型多样性问题。SI-MKR通过从知识图谱中添加用户和项目属性信息来解决该问题。通过对比,MMKGV[29]采用图注意力网络,结合多模态信息,利用知识图谱的三元组推理关系,在知识图谱上进行信息传播和信息聚合。CMCKG[2]将来自描述属性和结构连接的信息视为两种模态,通过最大化这两种视图之间的一致性来学习节点表示。
2.2 融合
在多模态推荐场景中,用户和项目的多模态信息的种类和数量都非常大。因此,需要融合不同的多模态信息来生成推荐任务的特征向量。与bridge相比,fusion更关注项目之间的多模态内部关系。具体来说,它旨在结合各种对模态的偏好。由于内部和内部关系对学习全面表示至关重要,许多MRS模型[39,44]甚至同时采用融合和桥接。注意力机制是应用最广泛的特征融合方法,能够灵活地融合具有不同权重和侧重点的多模态信息。在这一小节中,如图2(b)所示,我们首先按融合粒度划分注意力机制,然后介绍MRS中存在的一些其他融合方法。
2.2.1 粗粒度注意力机制
一些模型应用注意力机制在粗粒度上融合来自多个模态的信息。例如,UVCAN[32]将多模态信息分为用户端和物品端,包括各自的id信息和边信息。利用用户端的多模态数据,通过自注意力机制为物品端生成融合权重。MCPTR[34]在UVCAN的基础上,提出了项目信息和用户信息的并行合并算法。除了用户和项目方面,一些模型还融合了不同模态方面的信息。CMBF[7]引入交叉注意力机制,分别对图像和文本模态的语义信息进行共同学习,然后将两者连接起来。此外,在一些模型中各种模态所占比例也有所不同。MML[40]基于id信息设计了一个注意力层,并辅以视觉和文本信息。在MCPTR[34]中,每个模态占据相同的位置,自注意力机制决定融合权重。相比之下,HCGCN[38]更注重项目本身的视觉和文本信息。
2.2.2 细粒度注意力机制
多模态数据既包含全局特征,也包含细粒度特征,如音频录音的音调或一件衣服上的图案。由于粗粒度融合往往是侵入性的、不可逆的[27],它会破坏原始模态的信息,降低推荐性能。因此,一些工作考虑细粒度融合,选择性地融合不同模态之间的细粒度特征信息。
细粒度融合在时尚推荐场景中具有重要意义。POG[5]是一个基于transformer架构的大型在线服装RS系统。在编码器中,通过多层注意力挖掘服装图像中属于搭配方案的深层特征,不断实现细粒度融合;相比之下,POG和[25]都应用了编码器-解码器transformer架构,其中包含细粒度的自注意力结构。根据搭配信息生成相应的方案描述。此外,为了增加可解释性,EFRM[18]还设计了语义提取网络(Semantic Extraction Network, SEN)来提取局部特征,最后将细粒度注意力偏好的两种特征进行融合。VECF[6]进行图像分割,将每个块的图像特征与其他模态融合。UVCAN[26]分别对VECF等视频截图进行图像分割,并通过注意力机制将图像块与id信息和文本信息进行融合。MM-Rec[52]首先通过目标检测算法Mask-RCNN从新闻图像中提取感兴趣区域,然后使用co-attention将兴趣点与新闻内容进行融合。
一些模型设计了独特的内部结构,以更好地进行细粒度融合。MKGformer[8]通过共享一些QKV参数和相关的感知融合模块来实现细粒度融合。MGAT[44]使用门控注意力机制专注于用户的局部偏好。MARIO[21]通过考虑每种模态对每次交互的个体影响来预测用户偏好。因此,该模型设计了一种模态感知注意力机制来识别不同模态对每次交互的影响,并对不同模态进行点乘。
2.2.3 组合的注意力
在细粒度融合的基础上,一些模型设计组合式融合结构,希望细粒度特征的融合也能保留全局信息的聚合。NOVA[27]引入辅助信息进行顺序推荐。指出直接使用vanilla attention融合不同模态特征通常效果不佳,甚至会降低性能。因此,提出了一种具有两个分支的非侵入式注意力机制,将id嵌入到一个分离的分支中,以保留融合过程中的交互信息。NRPA[30]提供了一种个性化注意力网络,该网络考虑了以用户评论为代表的用户偏好。利用个性化的单词级注意力为每个用户/物品在评论中选择更重要的单词,并依次通过细粒度和粗粒度融合对评论信息注意力层进行传递。VLSNR[14]是序列推荐的另一个应用——新闻推荐。通过多头注意力和GRU网络对用户临时兴趣和长期兴趣进行建模,实现细粒度和粗粒度的融合。MARank[57]设计了一个多阶注意力层,将注意力和Resnet结合成一个统一的结构来融合信息。
2.2.4 其它的融合方法
除了通过注意力权重融合多模态信息外,一些工作应用了一些简单的方法,包括平均池化、concat操作[60]和门控机制[27]。然而,它们很少单独出现,经常与图和注意力机制结合出现,如上所述。现有工作[27]表明,简单的交互,如果使用得当,不会破坏推荐效果,并且可以降低模型的复杂度。此外,一些早期的模型采用RNN[14]和LSTM[16]等结构,试图通过多模态信息对用户时间偏好进行建模。然而,随着注意力机制和CNN等深度学习技术的发展,近年来它们的应用越来越少。一些模型通过线性和非线性层融合多模态特征。Lv出版社。[35]在位置设置一个线性层来融合文本和视觉特征。在MMT-Net[23]中,人为标记餐厅数据的3个上下文不变量,通过3层MLP网络进行交互。
2.3 过滤
由于多模态数据不同于用户交互数据,它包含了许多与用户偏好无关的信息。例如,如图2(c)所示,电影3和用户1之间的交互是有噪声的,应该被去除。在多模态推荐任务中,过滤掉噪声数据通常可以提高推荐性能。它值得注意到噪声可能存在于交互图中,也可能存在于多模态特征本身,因此过滤可以分别嵌入到桥接和融合中。
一些模型使用图像处理来去噪。例如,VECF[6]和UVCAN[26]通过对图像进行分割来去除图像中的噪声,从而更好地对用户的个性化兴趣建模。MM-Rec[52]采用目标检测算法选取图像的显著边缘。
此外,许多基于图神经网络的结构也被用于去噪。由于用户-项目交互的稀疏性和项目特征的噪声,通过图聚合学习到的用户和项目表示内在地包含噪声。FREEDOM[63]设计了一种度敏感的边修剪方法来对用户-项目交互图进行去噪。GRCN[55]检测用户是否不小心与噪声项交互。与传统的GCN模型不同,GRCN可以在训练过程中自适应地调整交互图的结构,以识别和剪枝错误的交互信息。PMGCRN[20]也考虑了用户对不感兴趣物品的交互,但与GRCN不同的是,它通过主动注意力机制来处理不匹配的交互,以纠正用户的错误偏好。此外,MEGCF[31]重点解决了多模态特征提取与用户兴趣建模之间的不匹配问题。首先构建多模态用户-项目图,然后利用评论数据中的情感信息对GCN模块中的细粒度权重近邻聚合进行信息过滤。
3,多模态特征增强
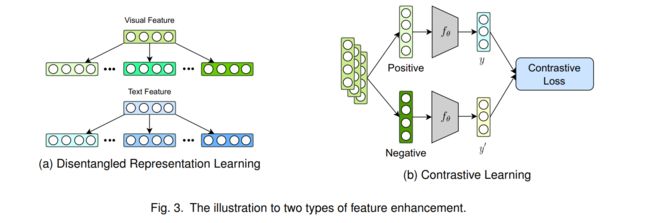
同一物体的不同模态表示具有独特而共同的语义信息。因此,如果能够区分独特特征和共同特征,MRS的推荐性能和泛化能力将得到显著提升。近年来,为了解决这一问题,一些模型配备了解缠表示学习(disentanglement Representation Learning, DRL)和对比学习(contrast Learning, CL)来进行基于交互的特征增强,如图3所示。
3.1 解离化表示学习
在RS中,不同模态的特征对用户对目标项目某一特定因素的偏好具有不同的重要性。然而,每种模态中不同因素的表示往往是纠缠在一起的,因此许多研究人员引入分解学习技术来挖掘用户偏好中细致的因素,如DICER [61], MacridVAE [36], CDR[4]。此外,多模态推荐是从高度纠缠的多模态数据中发现各种隐藏因素形成的有用信息。MDR[49]提出了一种多模态解纠缠推荐,可以从不同模态学习到携带互补和标准信息的解纠缠良好的表示。DMRL[28]考虑了不同模态特征对每个解缠因子的不同贡献,以捕获用户偏好。PAMD[15]设计了一个解缠编码器,在自动提取其模态公共特征的同时,保留其模态特定特征。此外,对比学习保证了分离模态表示之间的一致性和差距。与MacridVAE相比,SEM-MacridVAE[48]在从用户行为中学习解纠缠表示时考虑了项目语义信息。
3.2 对比学习
与深度强化学习不同,对比学习方法通过数据增强来增强表示,这也有助于处理稀疏问题。许多MRS工作引入了CL损失函数,主要用于模态对齐和增强正负样本之间的深度特征信息。
MCPTR[34]提出了一种新的CL损失,使同一项的不同模态表示具有语义相似性。此外,GHMFC[46]基于来自图神经网络的实体嵌入表示构建了两个对比学习模块。两个CL损失函数在两个方向上,即文本到图像和图像到文本。Cross-CBR[37]提出一个CL损失来对齐来自捆绑视图和项目视图的图表示。MICRO[59]侧重于共享模态信息和特定模态信息。在CMCKG[2]中,通过知识图谱同时从描述性属性和结构链接信息中获取实体嵌入,以进行对比损失。在HCGCN[38]中,为了将视觉和文本项特征映射到相同的语义空间中,参考CLIP[41],采用对比学习,最大化批处理中正确的视觉-文本对的相似度。此外,为不同的CL损失函数设置权重。
由于对比学习的核心是挖掘正负样本之间的关系,许多模型在推荐场景中采用数据增强方法来构建正样本。MGMC[62]设计了图增强来增加样本,并引入元学习来提高模型泛化能力。MML[40]是一种序列推荐模型,通过构建用户历史购买项目序列的子集来扩展训练数据。LHBPMR[38]从图卷积中选择具有相似偏好的项目来构建正样本。MMGCL[54]通过模态边缘损失和模态掩蔽来构造正样本。Victor[24]首先通过中文语义构造样本;Combo-Fashion[64]是一种捆绑的时尚推荐模型,因此它构造了正向和负向的时尚匹配方案。现有模型大多考虑在多模态数据中删除不属于用户偏好的信息。相比之下,QRec[56]从相反的角度出发,将多模态信息作为正样本添加均匀噪声,以提高模型的泛化能力。此外,UMPR[53]虽然没有显式的CL损失函数,但它也构建了一个描述视觉正负样本差异的损失函数。
4,模型的优化
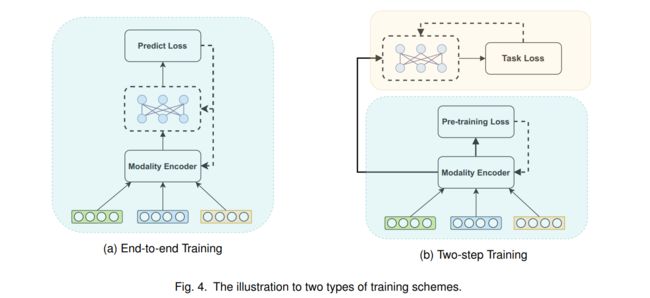
与传统推荐任务不同,由于多模态信息的存在,当多模态编码器和推荐模型一起训练时,模型训练的计算需求大大增加。因此,多模态推荐模型在训练过程中可以分为端到端训练和两步训练两类。如图4(a)所示,端到端训练可以用反向传播得到的每一个梯度来更新模型中所有层的参数。两步训练包括预训练多模态编码器的第一阶段和面向任务的优化的第二阶段,如图4(b)所示。
4.1 端到端训练
由于多模态推荐系统使用图片、文本、音频等多媒体信息,在处理这些多模态数据时,往往采用一些其他领域常用的编码器,如Vit[13]、Resnet[17]、Bert[12]。这些预训练模型的参数通常非常大。例如,Vit-Base[13]的参数数量达到8600万,这对计算资源是一个很大的挑战。为了解决这个问题,大多数MRS直接采用预训练编码器,并且仅以端到端的模式训练推荐模型。NOVA[27]和VLSNR[14]使用预训练编码器对图像和文本特征进行编码,然后通过模型嵌入得到的多模态特征向量,并为用户进行推荐。他们表明,在不更新编码器参数的情况下引入多模态数据也可以提高推荐性能。MCPTR[34]通过推荐和对比损失,仅用100次迭代对编码器参数进行微调。
一些端到端的方法也旨在减少计算量的同时提高推荐性能。它们通常会减少训练时需要更新的参数数量。例如,MKGformer[8]是一个多层transformer结构,其中许多注意力层参数被共享以减少计算。FREEDOM[63]旨在冻结图结构的一些参数,大幅降低内存成本,并实现去噪效果以提高推荐性能。
4.2两阶段训练
与端到端模式相比,两阶段训练模式能更好地定位下游任务,但对计算资源的要求较高。因此,很少有MRS采用两步训练。PMGT[33]提出了一种参考Bert结构的预训练图transformer。它学习项目表示有两个目标:图结构重建和掩码节点特征重建。在POG[5]中,训练一个预训练transformer来学习服装搭配知识,然后通过布料生成模型为用户进行服装推荐。此外,在序列推荐任务中,通常难以以端到端方案训练模型。例如,在预训练阶段,MML[40]首先通过元学习训练元学习器以增加模型泛化能力,然后训练项嵌入生成器在第二阶段。此外,TESM[39]和Victor[24]分别预训练了一个设计良好的图神经网络和一个视频transformer。
5,应用以及资源
在本节中,我们将列举典型的MRS应用,并提供每个应用场景的数据集。此外,在第二小节中介绍了几个开源的多模态推荐框架。
5.1 应用及相关数据集
目前,用户在浏览网络购物平台时,会接收到大量的多模态商品信息,这些信息会在潜移默化中影响用户的购物行为。例如,在时尚推荐场景中,用户往往会因为布料的形象而诱惑购买他们不需要的东西。在电影推荐场景中,用户只有被电影海报和标题吸引时才会点击内容。充分利用这些多模态数据可以提高模型的推荐效果。此外,多模态数据的质量直接影响推荐效果。因此,如表2所示,我们根据应用场景总结了MRS的几个常用数据集。这将指导研究人员方便地获得这些MRS数据集。任何想使用这些数据集的人都可以参考相应的引用和网站以了解更多细节。
5.2 开源框架
MMRec1: MMRec是一个基于PyTorch的多模态推荐工具箱。它集成了MMGCN、[51]等十余种优秀的多模态推荐系统模型。
Cornac2 [42]: Cornac是一个用于多模态推荐系统的比较框架。从数据、模型、度量和实验4个方面给出了MRS的完整实验流程。此外,cornac与TensorFlow和PyTorch等主流深度学习框架高度兼容。
6,挑战
为了激励想要投身于该领域的研究人员,本文列出了一些有希望的研究面临的现有挑战:
一个通用的解决方案。值得注意的是,虽然针对模型的不同阶段提出了一些方法,但目前还没有提供将这些技术结合起来的通用解决方案。
模型可解释性:多模态模型的复杂性会使系统生成的建议难以理解和解释,这可能会限制系统的信任和透明度。虽然很少有先驱者[6,18]提到它,但仍然需要探索。
计算复杂性:MRS需要大量的数据和计算资源,使其具有挑战性,以扩展到大型数据集和人群。多模态数据和模型的复杂性会增加推荐生成的计算成本和时间,使其对实时应用具有挑战性。
通用MRS数据集。目前,MRS的数据集仍然有限,覆盖的模态不够广泛。此外,不同模态的数据质量和可用性可能不同,这可能会影响建议的准确性和可靠性
7,总结
多模态推荐系统凭借其在不同模态上的聚集优势,正成为推荐系统的前沿研究方向之一。文中针对多模态推荐模型在不同建模阶段面临的挑战,将其分为特征交互、特征增强和模型优化3类。总结了数据集和开源代码,以促进研究人员的工作。总之,我们相信通过总结这些分类法、技术和资源,我们的调查将通过提高对不同方法的认识和呈现新主题来指导和刺激进一步的研究。
REFERENCES
[1] Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. 2018. Multimodal machine learning: A survey and taxonomy. TPAMI (2018).
[2] Xianshuai Cao, Yuliang Shi, Jihu Wang, Han Yu, Xinjun Wang, and Zhongmin Yan. 2022. Cross-modal Knowledge Graph Contrastive Learning for
Machine Learning Method Recommendation. In Proc. of ACM MM.
[3] Jianxin Chang, Chen Gao, Xiangnan He, Depeng Jin, and Yong Li. 2020. Bundle recommendation with graph convolutional networks. In Proc. of
SIGIR.
[4] Hong Chen, Yudong Chen, Xin Wang, Ruobing Xie, Rui Wang, Feng Xia, and Wenwu Zhu. 2021. Curriculum Disentangled Recommendation with
Noisy Multi-feedback. Proc. of NeurIPS (2021).
[5] Wen Chen, Pipei Huang, Jiaming Xu, Xin Guo, Cheng Guo, Fei Sun, Chao Li, Andreas Pfadler, Huan Zhao, and Binqiang Zhao. 2019. POG:
personalized outfit generation for fashion recommendation at Alibaba iFashion. In Proc. of KDD.
[6] Xu Chen, Hanxiong Chen, Hongteng Xu, Yongfeng Zhang, Yixin Cao, Zheng Qin, and Hongyuan Zha. 2019. Personalized fashion recommendation
with visual explanations based on multimodal attention network: Towards visually explainable recommendation. In Proc. of SIGIR.
[7] Xi Chen, Yangsiyi Lu, Yuehai Wang, and Jianyi Yang. 2021. CMBF: Cross-Modal-Based Fusion Recommendation Algorithm. Sensors (2021).
[8] Xiang Chen, Ningyu Zhang, Lei Li, Shumin Deng, Chuanqi Tan, Changliang Xu, Fei Huang, Luo Si, and Huajun Chen. 2022. Hybrid Transformer
with Multi-level Fusion for Multimodal Knowledge Graph Completion. arXiv preprint arXiv:2205.02357 (2022).
[9] Yashar Deldjoo, Fatemeh Nazary, Arnau Ramisa, Julian Mcauley, Giovanni Pellegrini, Alejandro Bellogin, and Tommaso Di Noia. 2022. A review of
modern fashion recommender systems. arXiv preprint arXiv:2202.02757 (2022).
[10] Yashar Deldjoo, Markus Schedl, Paolo Cremonesi, and Gabriella Pasi. 2020. Recommender systems leveraging multimedia content. ACM Computing
Surveys (CSUR) (2020).
[11] Yashar Deldjoo, Markus Schedl, and Peter Knees. 2021. Content-driven music recommendation: Evolution, state of the art, and challenges. arXiv
preprint arXiv:2107.11803 (2021).
[12] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language
understanding. arXiv preprint arXiv:1810.04805 (2018).
[13] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias
Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint
arXiv:2010.11929 (2020).
[14] Songhao Han, Wei Huang, and Xiaotian Luan. 2022. VLSNR: Vision-Linguistics Coordination Time Sequence-aware News Recommendation. arXiv
preprint arXiv:2210.02946 (2022).
[15] Tengyue Han, Pengfei Wang, Shaozhang Niu, and Chenliang Li. 2022. Modality Matches Modality: Pretraining Modality-Disentangled Item
Representations for Recommendation. In Proceedings of the ACM Web Conference 2022.
[16] Casper Hansen, Christian Hansen, Lucas Maystre, Rishabh Mehrotra, Brian Brost, Federico Tomasi, and Mounia Lalmas. 2020. Contextual and
sequential user embeddings for large-scale music recommendation. In Proc. of RecSys.
[17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proc. of CVPR.
[18] Min Hou, Le Wu, Enhong Chen, Zhi Li, Vincent W Zheng, and Qi Liu. 2019. Explainable fashion recommendation: A semantic attribute region
guided approach. arXiv preprint arXiv:1905.12862 (2019).
[19] Umair Javed, Kamran Shaukat, Ibrahim A Hameed, Farhat Iqbal, Talha Mahboob Alam, and Suhuai Luo. 2021. A review of content-based and
context-based recommendation systems. International Journal of Emerging Technologies in Learning (iJET) (2021).
[20] Xiangen Jia, Yihong Dong, Feng Zhu, Yu Xin, and Jiangbo Qian. 2022. Preference-corrected multimodal graph convolutional recommendation
network. Applied Intelligence (2022).
[21] Taeri Kim, Yeon-Chang Lee, Kijung Shin, and Sang-Wook Kim. 2022. MARIO: Modality-Aware Attention and Modality-Preserving Decoders for
Multimedia Recommendation. In Proc. of CIKM.
[22] Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization techniques for recommender systems. Computer (2009).
[23] Adit Krishnan, Mahashweta Das, Mangesh Bendre, Hao Yang, and Hari Sundaram. 2020. Transfer learning via contextual invariants for one-to-many
cross-domain recommendation. In Proc. of SIGIR.
[24] Chenyi Lei, Shixian Luo, Yong Liu, Wanggui He, Jiamang Wang, Guoxin Wang, Haihong Tang, Chunyan Miao, and Houqiang Li. 2021. Understanding
chinese video and language via contrastive multimodal pre-training. In Proc. of ACM MM.
[25] Yujie Lin, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Jun Ma, and Maarten De Rijke. 2019. Explainable outfit recommendation with joint outfit
matching and comment generation. IEEE Transactions on Knowledge and Data Engineering (2019).
[26] Bo Liu. 2022. Implicit semantic-based personalized micro-videos recommendation. arXiv preprint arXiv:2205.03297 (2022).
[27] Chang Liu, Xiaoguang Li, Guohao Cai, Zhenhua Dong, Hong Zhu, and Lifeng Shang. 2021. Noninvasive self-attention for side information fusion in
sequential recommendation. In Proc. of AAAI.
[28] Fan Liu, Zhiyong Cheng, Huilin Chen, Anan Liu, Liqiang Nie, and Mohan Kankanhalli. 2022. Disentangled Multimodal Representation Learning for
Recommendation. arXiv preprint arXiv:2203.05406 (2022).
[29] Huizhi Liu, Chen Li, and Lihua Tian. 2022. Multi-modal Graph Attention Network for Video Recommendation. In Proc. of CCET.
[30] Hongtao Liu, Fangzhao Wu, Wenjun Wang, Xianchen Wang, Pengfei Jiao, Chuhan Wu, and Xing Xie. 2019. NRPA: neural recommendation with
personalized attention. In Proc. of SIGIR.
[31] Kang Liu, Feng Xue, Dan Guo, Le Wu, Shujie Li, and Richang Hong. 2022. MEGCF: Multimodal entity graph collaborative filtering for personalized
recommendation. TOIS (2022).
[32] Shang Liu, Zhenzhong Chen, Hongyi Liu, and Xinghai Hu. 2019. User-video co-attention network for personalized micro-video recommendation. In
Proc. of WWW.
[33] Yong Liu, Susen Yang, Chenyi Lei, Guoxin Wang, Haihong Tang, Juyong Zhang, Aixin Sun, and Chunyan Miao. 2021. Pre-training graph transformer
with multimodal side information for recommendation. In Proc. of ACM MM.
[34] Zhuang Liu, Yunpu Ma, Matthias Schubert, Yuanxin Ouyang, and Zhang Xiong. 2022. Multi-Modal Contrastive Pre-training for Recommendation. In
Proceedings of the 2022 International Conference on Multimedia Retrieval.
[35] Junmei Lv, Bin Song, Jie Guo, Xiaojiang Du, and Mohsen Guizani. 2019. Interest-related item similarity model based on multimodal data for top-N
recommendation. IEEE Access (2019).
[36] Jianxin Ma, Chang Zhou, Peng Cui, Hongxia Yang, and Wenwu Zhu. 2019. Learning disentangled representations for recommendation. Proc. of
NeurIPS (2019).
[37] Yunshan Ma, Yingzhi He, An Zhang, Xiang Wang, and Tat-Seng Chua. 2022. CrossCBR: Cross-view Contrastive Learning for Bundle Recommendation.
arXiv preprint arXiv:2206.00242 (2022).
[38] Zongshen Mu, Yueting Zhuang, Jie Tan, Jun Xiao, and Siliang Tang. 2022. Learning Hybrid Behavior Patterns for Multimedia Recommendation. In
Proc. of ACM MM.
[39] Juan Ni, Zhenhua Huang, Yang Hu, and Chen Lin. 2022. A two-stage embedding model for recommendation with multimodal auxiliary information.
Information Sciences (2022).
[40] Xingyu Pan, Yushuo Chen, Changxin Tian, Zihan Lin, Jinpeng Wang, He Hu, and Wayne Xin Zhao. 2022. Multimodal Meta-Learning for Cold-Start
Sequential Recommendation. In Proc. of CIKM.
[41] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack
Clark, et al. 2021. Learning transferable visual models from natural language supervision. In Proc. of ICML.
[42] Aghiles Salah, Quoc-Tuan Truong, and Hady W Lauw. 2020. Cornac: A Comparative Framework for Multimodal Recommender Systems. Journal of
Machine Learning Research (2020).
[43] Rui Sun, Xuezhi Cao, Yan Zhao, Junchen Wan, Kun Zhou, Fuzheng Zhang, Zhongyuan Wang, and Kai Zheng. 2020. Multi-modal knowledge graphs
for recommender systems. In Proc. of CIKM.
[44] Zhulin Tao, Yinwei Wei, Xiang Wang, Xiangnan He, Xianglin Huang, and Tat-Seng Chua. 2020. MGAT: multimodal graph attention network for
recommendation. Information Processing & Management (2020).
[45] Hongwei Wang, Fuzheng Zhang, Miao Zhao, Wenjie Li, Xing Xie, and Minyi Guo. 2019. Multi-task feature learning for knowledge graph enhanced
recommendation. In Proc. of WWW.
[46] Peng Wang, Jiangheng Wu, and Xiaohang Chen. 2022. Multimodal Entity Linking with Gated Hierarchical Fusion and Contrastive Training. In Proc.
of SIGIR.
[47] Qifan Wang, Yinwei Wei, Jianhua Yin, Jianlong Wu, Xuemeng Song, and Liqiang Nie. 2021. Dualgnn: Dual graph neural network for multimedia
recommendation. IEEE Transactions on Multimedia (2021).
[48] Xin Wang, Hong Chen, Yuwei Zhou, Jianxin Ma, and Wenwu Zhu. 2023. Disentangled Representation Learning for Recommendation. IEEE
Transactions on Pattern Analysis and Machine Intelligence (2023).
[49] Xin Wang, Hong Chen, and Wenwu Zhu. 2021. Multimodal disentangled representation for recommendation. In Proc. of ICME.
[50] Yuequn Wang, Liyan Dong, Hao Zhang, Xintao Ma, Yongli Li, and Minghui Sun. 2020. An enhanced multi-modal recommendation based on alternate
training with knowledge graph representation. Ieee Access (2020).
[51] Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng Chua. 2019. MMGCN: Multi-modal graph convolution network
for personalized recommendation of micro-video. In Proc. of ACM MM.
[52] Chuhan Wu, Fangzhao Wu, Tao Qi, and Yongfeng Huang. 2021. Mm-rec: multimodal news recommendation. arXiv preprint arXiv:2104.07407
(2021).
[53] Cai Xu, Ziyu Guan, Wei Zhao, Quanzhou Wu, Meng Yan, Long Chen, and Qiguang Miao. 2020. Recommendation by users’ multimodal preferences
for smart city applications. IEEE Transactions on Industrial Informatics (2020).
[54] Zixuan Yi, Xi Wang, Iadh Ounis, and Craig Macdonald. 2022. Multi-modal graph contrastive learning for micro-video recommendation. In Proc. of
SIGIR.
[55] Wei Yinwei, Wang Xiang, Nie Liqiang, He Xiangnan, and Chua Tat-Seng. 2021. GRCN: Graph-Refined Convolutional Network for Multimedia
Recommendation with Implicit Feedback. arXiv preprint arXiv:2111.02036 (2021).
[56] Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are graph augmentations necessary? simple graph
contrastive learning for recommendation. In Proc. of SIGIR.
[57] Lu Yu, Chuxu Zhang, Shangsong Liang, and Xiangliang Zhang. 2019. Multi-order attentive ranking model for sequential recommendation. In Proc. of
AAAI.
[58] Jinghao Zhang, Yanqiao Zhu, Qiang Liu, Shu Wu, Shuhui Wang, and Liang Wang. 2021. Mining latent structures for multimedia recommendation. In
Proc. of ACM MM.
[59] Jinghao Zhang, Yanqiao Zhu, Qiang Liu, Mengqi Zhang, Shu Wu, and Liang Wang. 2022. Latent Structure Mining with Contrastive Modality Fusion
for Multimedia Recommendation. IEEE Transactions on Knowledge and Data Engineering (2022).
[60] Xiaoyan Zhang, Haihua Luo, Bowei Chen, and Guibing Guo. 2020. Multi-view visual Bayesian personalized ranking for restaurant recommendation.
Applied Intelligence (2020).
[61] Yin Zhang, Ziwei Zhu, Yun He, and James Caverlee. 2020. Content-collaborative disentanglement representation learning for enhanced recommendation. In Fourteenth ACM Conference on Recommender Systems.
[62] Feng Zhao and Donglin Wang. 2021. Multimodal graph meta contrastive learning. In Proc. of CIKM.
[63] Xin Zhou. 2022. A Tale of Two Graphs: Freezing and Denoising Graph Structures for Multimodal Recommendation. arXiv preprint arXiv:2211.06924
(2022).
[64] Chenxu Zhu, Peng Du, Weinan Zhang, Yong Yu, and Yang Cao. 2022. Combo-Fashion: Fashion Clothes Matching CTR Prediction with Item History.
In Proc. of KDD.