机器学习实战2--蒙特卡洛方法与Q-Q图(2022/10/12)
蒙特卡洛方法与Q-Q图
文章目录
- 蒙特卡洛方法与Q-Q图
-
- 蒙特卡洛方法
-
- 蒙特卡洛的定义和基本步骤
- 一些常用的概率论相关函数
- 使用蒙特卡洛验证大数定理
- Q-Q图
-
- Q-Q图的定义及用途
import numpy as np
from numpy.linalg import inv,eig
import matplotlib.pyplot as plt
import pandas as pd
from scipy.stats import norm
蒙特卡洛方法
蒙特卡洛的定义和基本步骤
蒙特卡洛是一个赌场的名字,我对他的理解大概是这一个使用随机数暴力求解的算法。其步骤主要为以下三个:
- 构造或描述概率过程
- 实现从已知概率分布抽样
- 建立各种估计量。
一些常用的概率论相关函数
- 使用
np.random.seed()可以设置随机数种子,随机数种子有三位数的int,设置随机数种子后,每次生成的随机数均相同,不填入种子,则生成的随机数不同。 - 使用
np.random.normal(均值, 标准差, 样本个数)生成服从 N ( 均值,标准差 ) N(均值,标准差) N(均值,标准差)的确定个数的样本。 - 使用
np.random.uniform(下界, 上界, n)生成服从均匀分布 U ( a , b ) U(a,b) U(a,b)的确定个数的样本。 - 使用
np.random.binomial(n, p, n)生成服从二项分布 b ( n , p ) b(n,p) b(n,p)的确定个数的样本。 - 使用
np.random.exponential(1/lambda): 指数分布,生成服从指数分布 E X P ( 1 λ ) EXP({1\over{\lambda}}) EXP(λ1)的确定个数的样本。 - 使用
np.random.poisson(lam):生成服从参数 λ \lambda λ确定的泊松分布的确定个数的样本。
mu = 0;sigma = 1;n=10000
x = np.random.normal(mu,sigma,n)
# x =np.random.uniform(2,4,n)
plt.hist(x,bins=300)
plt.axvline(x=mu,color = "red",label="u")
plt.legend()

使用蒙特卡洛验证大数定理
- 生成一个确定的分布,我这里使用均匀分布
- 每次抽样,计算均值,
- 画均值图像(大数定理表明服从正态分布)
- 与总体均值比对
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] #中文标签
a = 2;b = 5;n = 10000 #抽样个数
e = (a+b)/2 #计算得出的总体均值
E = list() #样本均值列表
mean_e = list() # 样本均值的均值存储列表
for i in range(1000):
x = np.random.uniform(a,b,n) #抽10000个样本
E.append(np.mean(x)) #储存每一次x的均值
mean_e.append(np.mean(E)) #储存每一次均值的均值
plt.figure("样本均值的分布")
plt.hist(E,bins = 100)
plt.axvline(x=e,color = "red")
plt.title("均值的分布情况")
Text(0.5, 1.0, ‘均值的分布情况’)
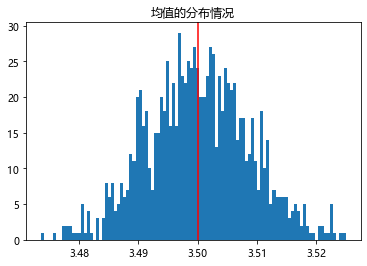
由大数定理可以得知,样本的均值是总体均值的无偏估计,即 E ( E ( X ˉ ) ) = μ E( E(\bar{X}) ) = \mu E(E(Xˉ))=μ
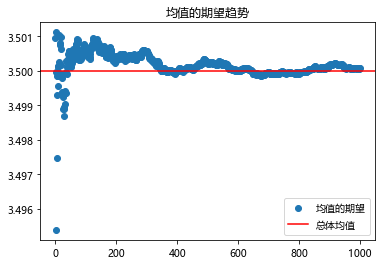
即当抽样检验的次数越多时,样本均值的数学期望(均值)会越来越接近总体均值
plt.figure(112)
plt.title("均值的期望趋势")
plt.scatter(range(1000),mean_e,label = "均值的期望")
plt.axhline(y=e,color = "red",label = "总体均值")
plt.legend()
Q-Q图
Q-Q图的定义及用途
- Q-Q图的横纵坐标均为两个分布的分位数,用于比较两个分布是否一致的情况,若一致,则两个分位数的分位点是相同的。则此时的Q-Q图应是一条直线,若分布完全相同则为 y = x y=x y=x 的直线。
- 若两个分布相同但参数不同,则呈现为一条直线,如当横轴分布为标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1) ,纵轴为正态分布 N ( μ , σ ) N(\mu,\sigma) N(μ,σ)时,直线斜率为 σ \sigma σ,截距 μ \mu μ。
- 值得注意的是:如果我们将一个某分布的样本直接根据他们的取值从小到大排列,得到的就是其分位数的函数,因为从小到大排列时,此时函数自变量为个数(即如1%个数的样本),因变量为这1%样本对应的上限值,也就是分位数
from math import sqrt
n = 10000
a = 2;b=3
x = np.random.normal(0,1,n)
y = (x+a)/b #生成(x+a)/b的分布,
y.sort() # 将这些个体从小到大排列的话,便是在横坐标函数的横坐标,即分位数。
prob = (np.arange(n)+1/2)/n #生成[0,1]间连续分布的n个的采样值(概率值)
q = norm.ppf(prob,a/b,1/b) #ppf正态分布求解分位数的函数,第一个参数是对应的概率值,所以使用[0,1]均匀分布的函数
# y 是需要我们验证的分布,因为其是由x变换求得的,q是由a/b、1/b生成的,是用来对比的
plt.scatter(x=q,y=y,color='red',label = "理想计算值分位数散点")
plt.plot(y,y,color = 'blue',label = "y=x参考线")
plt.legend()
plt.title("Q-Q图")
plt.xlabel("理想的分布")
plt.ylabel("实际的散点分布")
Text(0, 0.5, ‘实际的散点分布’)

可以看出 y = x + a b y={x+a\over{b}} y=bx+a 服从 N ( a b , 1 b ) N({a\over{b}},{1\over{b}}) N(ba,b1),
符合我们的计算 E ( y ) = E ( x b ) + E ( a b ) = 0 + a b E(y)= E({x\over{b}})+E({a\over{b}})=0+{a\over{b}} E(y)=E(bx)+E(ba)=0+ba
D ( y ) = D ( x b ) + D ( a b ) = 1 b 2 ∗ 1 + 0 = 1 b 2 = = > σ = 1 b D(y) = D({x\over{b}})+D({a\over{b}}) = {1\over{b^2}}*1 + 0 = {1\over{b^2}} ==> \sigma = {1\over{b}} D(y)=D(bx)+D(ba)=b21∗1+0=b21==>σ=b1
jupyter源文件在此处