AIGC内容分享(四十):生成式人工智能(AIGC)应用进展浅析
目录
0 引言
1 以ChatGPT为代表的AIGC发展现状
1.1 国外AIGC应用发展现状
1.2 国内AIGC应用发展现状
2 AIGC的技术架构
(1)数据层
(2)算力基础设施层
(3)算法及大模型层
(4)AIGC能力层
(5)AIGC功能层
(6)AIGC应用层
3 AIGC面临的机遇与挑战
3.1 AIGC带来的机遇
(1)AIGC为数字经济注入新引擎
(2)AIGC催生新的软件服务模式
(3)AIGC为通信行业带来新的发展机遇
3.2 AIGC带来的挑战
(1)对版权保护、社会规范、伦理道德等带来较大威胁
(2)算力资源增长与能耗的带来较大挑战
(3)构建健壮性的智算网络及调度平台面临较大挑战
4 结束语
参考文献
0 引言
生成式人工智能(AIGC, Artificial Intelligence Generated Content)是指基于生成对抗网络、大型预训练模型等人工智能的技术方法,通过已有数据的学习和识别,以适当的泛化能力生成相关内容的技术。AIGC技术的核心思想是利用人工智能算法生成具有一定创意和质量的内容。通过训练模型和大量数据的学习,AIGC可以根据输入的条件或指令,生成与之相关的内容。AIGC的发展最早可追溯到1950年艾伦•图灵(Alan Turing)在其论文《计算机器与智能(Computing Machinery and Intelligence)》中提出了著名的“图灵测试”,给出了判定机器是否具有“智能”的试验方法,即机器是否能够模仿人类的思维方式来“生成”内容,1957年莱杰伦·希勒(Lejaren Hiller)和伦纳德·艾萨克森(Leon-ard saacson)完成了人类历史上第一支由计算机创作的音乐作品就可以看作是 AIGC的开端。经过半个多世纪的快速发展,随着具有价值的有效数据大量积累、算力的大幅提升,以及深度学习算法的提出与应用,今天的人工智能技术已经普及到许多的行业,并在相应的场景中发挥着重要的作用,比如自然语言处理(NLP, Natural Language Processing)、计算机视觉、推荐系统、预测分析等,颠覆相应场景下的生产与生活等方式,为人类社会带来了极大的便捷中发挥着重要作用[1]。2022年11月30日,OpenAI公司发布了生成式预训练Transformer模型(ChatGPT, Chat Generative Pre-trained Transformer),通过大规模预训练(GPT-3.5)和自然语言生成技术实现多轮对话问答,将AIGC推向高潮,席卷全球,成为各行各业关注的焦点。ChatGPT是一种基于互联网的、可用数据来训练的、文本生成的深度学习模型,它本身属于NLP领域中的超大预训练模型(PTM,Pre-Trained Model,这类超大PTM也称为大语言模型(LLM, Large Language Model)[2~6]。文献[7~13]以ChatGPT为例详细论述了AIGC技术原理,介绍了单模态和多模态两种生成模型,对AIGC的定义、优点、在边缘云计算、Web3.0、元宇宙等中的应用、挑战以及面临的安全、隐私和知识产权等威胁等方面进行了详细论述,并给出未来的方向。文献[14~17]重点以ChatGPT为例从技术角度给出了人工智能、超大预训练模型的机遇和挑战。文献[18~22]从通信运营商的视角出发,探讨AIGC的机遇和挑战,并给出运营商AI能力建设策略和思路。
上述文献重点从技术原理和技术演进等角度出发,探讨AIGC相关技术以及面临的机遇和挑战。由于AIGC中所涉及的相应深度学习、大语言模型、算法等专业技术较多,且AIGC应用发展较为迅速。基于此,本文以AIGC工程应用的视角出发探讨国内外AIGC的发展现状与趋势,在此基础上对相应当前的AIGC国内外应用产品进行归类,并详细介绍AIGC技术架构体系,最后给出了AIGC面临的机遇与挑战。
1 以ChatGPT为代表的AIGC发展现状
随着ChatGPT的热潮持续升温,根据51GPT网站的统计,截至目前,全世界当前已有2 722个AIGC类的应用工具。这些工具的不断涌现,进一步加速推动了AIGC的商业化落地,使得产业生态链逐步走向完善。如图1所示,当前,AIGC产品主要模态包括音频生成、视频生成、文本生成、图像生成,以及图像、视频、文本间的跨模态生成等几种方式。

下面分别从国外、国内两方面来看AIGC的应用发展现状和趋势。
1.1 国外AIGC应用发展现状
结合相关文献和调研报告,将国外主要AIGC头部应用产品按照文本、图像、音频、视频进行分类,相应具有代表性的如表1所示。

从表1可知,国外AIGC应用产品主要以美国为主,绝大部分产品均具有多模态能力,这也是当前AIGC产品演进和落地的重要方向。从技术上来看,生成算法、预训练模型、多模态等AI技术的累积与融合,才催生了AIGC的大爆发,其中生成算法主要包括Transformer、基于流的生成模型(Flow-based models)、扩散模型(Diffusion Model)等深度学习算法。按照基本类型分类,预训练模型主要包括:(1)NLP预训练模型,如谷歌的LaMDA和PaLM、Open AI的GPT系列;(2)计算机视觉(CV)预训练模型,如微软的Florence;(3)多模态预训练模型,即融合文字、图片、音视频等多种内容形式。预训练模型更具通用性,成为多才多艺、多面手的 Al模型,主要得益于多模型技术(Multimodal technology)的使用,即多模态表示图像、声音、语言等融合的机器学习。多模态技术推动了AIGC的内容多样性,让AIGC具有了更通用的能力。从市场应用来看,OpenAI的ChatGPT4无疑处于绝对领先地位,从OpenAI发布会上透露信息来看,ChatGPT正式发布至今,周活跃用户数超过1亿人,目前有超过200万开发者和客户在该公司的API上进行开发,世界财富500强公司中,有92%的企业在使用其产品,即将快速创建定制ChatGPT的GPTs,实现了人人都能拥有大模型,引入性能更强的GPT-4 Turbo模型,直接支持128k上下文,知识库更新到今年4月,以及即将推出GPT Store应用商店,和新用于AI智能体的Assistants API等。
1.2 国内AIGC应用发展现状
国内方面,随着百度“文心一言”、阿里通义千问、讯飞星火大模型、智谱AI的ChatGLM等纷纷发布,美团、百川智能、云知声、美图、腾讯等纷纷加入大模型赛道,一场围绕大模型的“军备竞赛”已趋白热化。5月底,科技部新一代人工智能发展研究中心发布《中国人工智能大模型地图研究报告》,我国10亿参数规模以上的大模型已发布79个,几乎进入“百模大战”。作为通信运营商来说,面对着AIGC广泛的应用前景,为避免被管道化,迫切需要提前做好布局和卡位。基于此,国内三大运营商纷纷发布AI大模型:6月28日,中国联通在2023年上海世界移动通信大会期间发布了“鸿湖图文大模型1.0”的图文生成模型,可实现以文生图、视频剪辑、以图生图等功能;7月6日,在世界人工智能大会“算网一体·融创未来”分论坛上,中国电信正式对外发布大语言模型TeleChat,并展示了大模型赋能数据中台、智能客服和智慧政务三个方向的能力;7月8日,在2023年世界人工智能大会“大模型与深度行业智能”创新论坛上,中国移动正式发布九天·海算政务大模型和九天·客服大模型。根据当前最新AIGC应用发布情况,国内典型AIGC产品相应主要技术特征如表2所示。
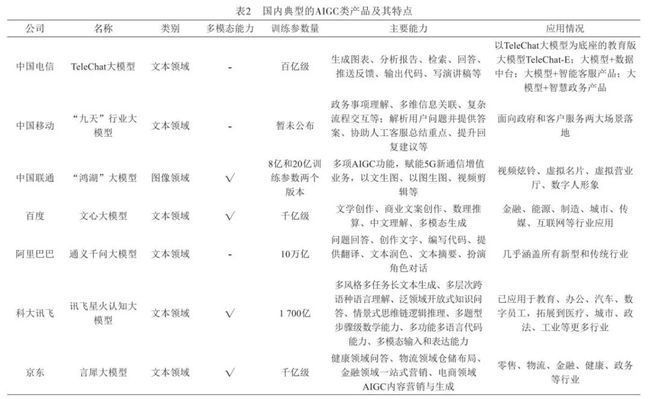
从国内AIGC产品应用情况来看,相应产品正处于加速迭代状态,与国外的AIGC产品类似,逐步向新闻媒体、智慧城市、生物科技、智慧办公、影视制作、智能教育、智慧金融、智慧医疗、智慧工厂、生活服务等行业领域渗透[23~25],且逐步具备多模态能力,但受限于算力芯片封锁、算法不公开等因素影响,国内AIGC产品在能力输出上相较于国外类似产品还存在不小差距。根据量子位智库预测,2023-2025年中国AIGC产业处于培育摸索期,预计年均复合增速为25%,2026-2030年行业将迎来快速增长阶段,中国市场规模有望在2030年达到11 491亿元。
2 AIGC的技术架构
在文献[21]中现有生成式人工智能AIGC技术架构等基础上,但该架构相对较为粗放,未能完整涵盖AIGC技术核心要素,同时并未结合AIGC技术特征和应用情况进一步进行细化分层,基于此,在此基础上提出AIGC技术架构,以期能够更清晰了解AIGC技术特征,如图2所示,AIGC从技术架构上看主要包含6层:数据层、算力基础设施层、算法及大模型层、AIGC能力层、AIGC功能层和AIGC应用层。
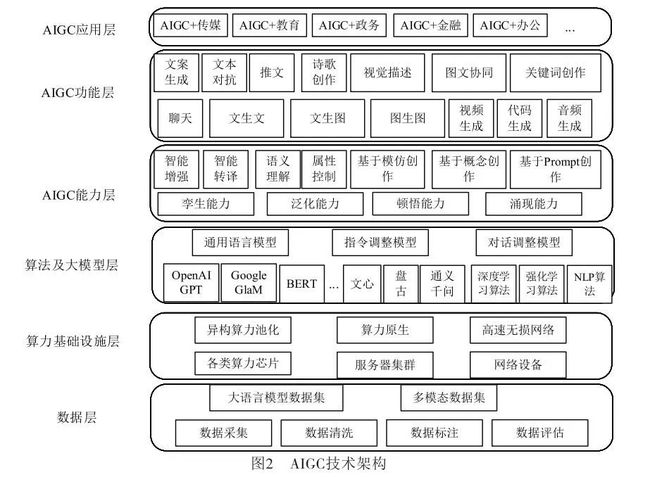
(1)数据层
数据作为AIGC三大核心要素之一,数据层数据的质量、数量、多样性决定大模型的训练效果。数据集的构建主要通过数据采集、数据清洗、数据标注、模型训练、模型测试和产品评估进行产生。根据当前AIGC应用所涉及的大语言模型和多模态模型两种类型,数据集可分为大语言模型数据集和多模态数据集,大语言模型数据集主要来源于维基百科、网络百科全书、书籍、期刊、网页数据、搜索数据、B端行业数据以及一些专业数据库等;多模态数据集主要是基于两个及以上的模态形式(文本、图像、视频、音频等)组合形成的数据集。
(2)算力基础设施层
算力基础设施层主要为大模型层提供算力底座,大模型所需的训练算力和推理算力由算力基础设施层提供。算力芯片主要包括图形处理器(GPU, Graphics Processing Unit)、张量处理器(TPU, Tensor Processing Unit)、神经网络处理器(NPU, Neural Processing Unit)以及各类智算加速芯片等。由于大模型训练所需的算力巨大且对时延要求较高,算力芯片一般都位于同一数据中心,采用高性能AI集群方式以保障算力需求,同时为降低服务器之间的延迟和带宽需求,需要采用专用InfiniBand 网络或基于融合以太网的远程直接数据存取(RoCE, Remote Direct Memory Access over Converged Ethernet)交换网络连接,形成高性能智算集群。专用InfiniBand网络架构相对封闭、运维复杂、价格昂贵,国外主要采用该技术,而国内主要以RoCE方式构建统一融合的网络架构,比如华为的超融合数据中心网络方案,使用独创的iLossLess智能无损算法,通过流量控制技术、拥塞控制技术和智能无损存储网络技术三大关键技术的相互配合,从而达到构建无损以太网络,助力实现AI场景下的数据中心网络“零丢包、低时延、高吞吐”目标。进一步地,考虑到各类算力芯片在不同行业应用的差异性,迫切需要构建异构的算力池,通过高效的调度算法、负载均衡算法等,提升算力的有效利用率,从而实现算力原生。
(3)算法及大模型层
当前,大模型采用的主要算法包括深度学习算法、强化学习算法和自然语言处理算法。深度学习算法主要包含卷积神经网络(CNN)和循环神经网络(RNN)两类,卷积神经网络(CNN)是常用于图像识别和计算机视觉任务的深度学习算法,循环神经网络(RNN)是常用于序列数据处理的深度学习算法。强化学习算法是大模型中用于决策和控制的重要算法,深度强化学习算法是结合深度学习和强化学习的优势,进一步拓展强化学习应用范围,常见的有Deep Q-Networks(DQN)、Deep Deterministic Policy Gradient(DDPG)、Proximal Policy Optimization(PPO)、Trust Region Policy Optimization(TRPO)等。自然语言处理算法主要包括文本分类算法、分词算法、命名实体识别算法、情感分析算法、机器翻译算法、问答系统算法、语音识别算法等。
大模型层主要基于算力基础设施提供的算力,面向通用、行业等构建大模型,通用大模型一般由技术实力较强的科技公司构建,而致力于构建专业或行业领域大模型的提供者,大多基于开源算法框架,以较少的通用数据结合高质量专业数据,以更低的成本训练出专业领域的大模型,相应大模型如第1节中相应的模型。一般情况下,大模型主要包含通用(或原始)语言模型、指令调整模型和对话调整模型三种类型:通用(或原始)语言模型通常使用大量的未标记文本进行训练,学习语言的统计规律,但没有特定的任务指向,模型经过训练,根据训练数据中的语言预测下一个词;指令调整模型是在通用语言模型的基础上,通过对特定任务数据的训练,使其能够对给定的指令做出适当的响应,这类模型可以理解和执行特定的语言任务,如问答、文本分类、总结、写作、关键词提取等,模型经过训练,以预测对输入中给出的指令的响应;对话调整模型是在通用语言模型的基础上,通过对对话数据的训练,使其能够进行对话。这类模型可以理解和生成对话,例如生成聊天机器人的回答,模型经过训练,以通过预测下一个响应进行对话。
(4)AIGC能力层
AIGC能力层主要表现在四个方面:孪生能力、泛化能力、顿悟能力和涌现能力。数字孪生是指利用模型和数据模拟还原出物理世界事物全生命周期的动态特征,并可双向评估,它是数字化的高级表达,数字孪生为AIGC核心能力,推动全行业降本增效,可有效与当前数字人结合为元宇宙创造有利条件。泛化能力是指AIGC大模型侧重于对知识的整合和转化,在不同内容生成任务中展现其普适性和通用性,涌现能力是指在大模型领域当模型突破某个规模时,性能显著提升,表现出让人惊艳、意想不到的能力,而顿悟能力是指经过多次的学习与训练突然爆发出的能力,一般情况下指降低原有参数规模和训练集基础上达成涌现能力。泛化能力、顿悟能力和涌现能力相互作用,能够有效提升AIGC的能力输出,通过算法调优等多重手段降低对参数量、训练数据集的要求,提升大模型在不同内容生成任务中的普适性和通用性。
(5)AIGC功能层
AIGC功能层主要基于不同的大模型能力,呈现多样性的技术场景,比如文生文、文生图、图生图、图文协同、视频生成、聊天机器人、音频生成、代码生成等多模态方式,通过构建这些技术场景以满足AIGC+行业、AIGC+通用等差异化的应用。
(6)AIGC应用层
AIGC应用层主要面向商业落地,根据各行各业的特点和需求,借助于AIGC功能层所提供的多样性技术场景进行适配,形成具有特色的AIGC应用产业,带动AIGC的发展与繁荣。一般来说,AIGC的应用主要包括基于生成式AI技术的创新应用和在现有基础上采用集成方式利用AI能力的传统应用。随着各类AIGC服务能力的逐步完善和开放,各行各业的应用开发者都可以调用AIGC服务能力开发各类领域的应用,应用生态将呈现百花齐放的局面。
3 AIGC面临的机遇与挑战
从上述分析可知,大模型需要高昂的硬件成本、开发成本投入以及模型训练成本投入等,这无疑提高其门槛。截至目前,虽然我国在AIGC方面奋起直追,但距离发达国家在该方面的投入、应用能力、技术水平等多方面还存在较大差距。此外,大模型所需的GPU等算力芯片更新迭代较快,中美贸易战导致的芯片禁售与断供也对AIGC发展带来较多不利。面对这些困难和大量人力物力投入,然而大模型相应的商业盈利模式还未见清晰,机遇与风险并存,基于此,结合AIGC的技术架构特点,分别论述AIGC所面临的机遇和挑战。
3.1 AIGC带来的机遇
AIGC所带来的机遇主要包含以下几个方面:
(1)AIGC为数字经济注入新引擎
当前,全球经济越来越呈现数字化特征,人类社会正在进入以数字化为主要标志的新阶段。数字经济,已经成为世界的主要经济形态,也成为推动我国经济社会发展的核心动力。AIGC作为一种利用人工智能模型创建数字内容的技术,它的出现让自动化生成数据成为可能,它可以把隐性的知识转变成显性的知识,这也意味着数据资产可以实现指数级的增长、极大地改变企业数据资产的生成方式与构成,进而推动IT跟业务的融合、提高工作效率、实现创新升级,AIGC将成为数字内容创新发展的新引擎。Gartner预计,到2025年,生成式人工智能将占所有生成数据的10%,而目前由人工智能生成的数据占所有数据的比例不到1%,具有较大的潜力。根据麦肯锡最近发布的一份报告预估,AIGC能每年为全球经济增加4.4万亿美元。此外,据艾媒咨询数据显示,预计2023年中国AIGC行业核心市场规模为79.3亿元,2028年将达2 767.4亿元。因此,一方面数字经济为AIGC提供了广阔的发展空间,另一方面,AIGC为数字经济提供了技术支持,AIGC的广泛应用已经成为数字经济的新趋势。随着硬件的升级和算法改进优化,AIGC的性能将越来越强大,AIGC模型体量/复杂度将极大提高,相应内容孪生、内容编辑、内容创作三大基础能力将显著增强,产品类型将逐渐丰富,应用领域将更加广泛。
(2)AIGC催生新的软件服务模式
由于大模型需要大算力、电力能源消耗、高精技术人才投入等,门槛较高,一般企业难以构建自己的大模型,因此,AIGC催生出新的软件服务模式—模型即服务MaaS(Model as a Service),MaaS模式是以机器学习和人工智能模型为基础,通过API(应用程序编程接口)提供这些模型的服务,这意味着在云端,开发者可以通过简单的API调用来使用这些模型的功能,而不需要自己构建和训练模型。这样一来,企业开发应用程序的效率大大提高,大大节省了时间和资源。于此同时,AIGC领域的发展也需要一个具有开放性和可扩展性的平台支持。MaaS模式为AIGC领域提供了更加开放和标准化的平台,使得更多的应用程序可以接入和使用这些模型服务。这一模式的出现,为行业内的企业带来了更加便捷、灵活和可扩展的服务。通过利用MaaS模式,企业可以更加专注于应用程序开发,无需过多关注模型的构建和训练。这将使企业能够更快地推出新的应用程序,提供更好的产品和服务。MaaS模式将成为未来AIGC领域的重要接口,人工智能模型的开发、部署和应用将变得更加便捷、灵活和可扩展。2023年9月8日,腾讯全球数字生态大会互联网AIGC应用专场上,腾讯云正式发布AIGC全栈解决方案,可为企业提供可信、可靠、可用的AIGC全链路内容服务,助力企业探索AGI之路,抓住AI 2.0时代发展新机遇。
(3)AIGC为通信行业带来新的发展机遇
随着AI大模型等人工智能技术的发展,对算力需求将显著增长,尤其是智算算力的需求激增,因此,相应智算网络规划、智算中心布局和数据处理能力显得尤为重要。面对当前日益严峻的国际形势和逆全球化发展趋势下,作为通信运营商来说,本身具有强大的基础设施网络和数据中心,无论是算力资源还是数据资源都较为丰富,同时具有良好的国家队基因优势和资金优势,可以站在国家利益高度角度出发,在国家的顶层规划和产业支持下,联合科研院所、产业链等的力量,逐步建立并筑牢该产业链链长,加强在人工智能大模型基础理论和应用上的投入,集中技术和资金优势共同开展关键问题攻关并实现突破,跟上或是达到世界领先水平,在数字经济中担负更大的使命。在AIGC产业中,运营商有望深度参与公共数据加工环节,一种模式是借助隐私计算技术和模式创新,提供大模型训练、推理阶段的数据产品;另一种模式是合成相应数据以满足未来大模型快速增长的参数量,构建大模型训练数据的监督体系。最后,运营商还可围绕行业智能的迭代升级需求,提供AI+泛行业解决方案,为企业创造新的增长点。
3.2 AIGC带来的挑战
AIGC所带来的挑战主要包括如下几个方面:
(1)对版权保护、社会规范、伦理道德等带来较大威胁
在版权保护方面,AIGC的飞速发展和商业化应用,除了对创作者造成冲击外,也对大量依靠版权为主要营收的企业带来较大冲击。在伦理道德方面,部分开源的AIGC项目对生成的图像、文本、视频、音频等监管程度较低,进行AI训练的数据集存在侵权等潜在风险,可利用AIGC生成虚假名人照片等违禁图片,甚至会制作出暴力、不雅等相应视频和图像,由于AI本身尚不具备价值判断能力,相关法律法规仍处于真空。此外,如何进行数据脱敏并有效利用,充分发挥数据资源的价值,都将面临较大挑战。针对上述问题,2023年7月13日,国家网信办等七部门联合发布《生成式人工智能服务管理暂行办法》,以坚持发展和安全并重、促进创新和依法治理相结合的原则,采取有效措施鼓励AIGC创新发展,成为国家首次针对于当下爆火的AIGC产业发布规范性政策,为上述问题提供了相应规范和要求,但相应具体的手段和方法仍需进一步挖掘和完善。
(2)算力资源增长与能耗的带来较大挑战
根据OpenAI研究结果,AI训练所需算力指数增长速率远超硬件的摩尔定律,在当前大模型参数量和数据集急速增长的情况下,所需的网络带宽和算力资源需求将呈指数级增长。大模型一般包含训练和推理两个部分。针对训练部分,根据OpenAI发表的论文中对训练算力计算,一般情况下,训练阶段算力需求与模型参数量、训练数据集规模等相关,且为二者乘积的6倍,以GPT为例,相应参数规模如表3所示:

根据表3所述,GPT-3参数约为1 750亿,训练语料规模(训练数据集)为45 TB,折合成训练集约为3 000亿tokens,则GPT-3训练阶段算力需求=6*1.75*1011*3*1011=3.15*1023FLOPS=3.15*108 PFLOS,折合成算力为3 646 PFLOS-day。在实际过程中,GPU算力除用于模型训练外,还需处理通信、数据存取等任务,实际所需算力远大于理论计算值。根据文献[19]给出的结论,OpenAI训练GPT-3采用英伟达1万块V100 GPU,有效算力比率为21.3%,GPT-3的实际算力需求应为1.48×109 PFLOPS(17 117 PFLOPS-day)。假设以单机搭载16片V100 GPU的英伟达DGX2服务器承载GPT-3训练,该服务器AI算力性能为2 PFLOPS,最大功率为10 kW,则训练阶段需要8 559台服务器同时工作1日,在电源使用效率PUE(Power Usage Effectiveness)为1.2时总耗电量约为2 464 992 kWh,相当于302.94吨标准煤,对应二氧化碳排放量745.25吨。从训练成本来说,OpenAI训练GPT-4的FLOPS约为2.15*e25,在大约25 000个A100上训练了90到100天,GPU利用率预估在32%到36%之间,训练的成本大约是6 300万美元。
针对推理部分,按照OpenAI提供的计算方法,推理阶段算力需求是模型参数量与训练数据集规模的2倍。根据表3所述,每轮对话最大产生2 048 tokens,则每轮对话产生的推理算力需求=2*1.75*1011*2048=7.168*1014=0.716 8 PFLOS,按照ChatGPT每日2 500万访问量,假设每账号每次发生10论对话,则每日对话产生推理算力需求=0.7168*2.5*107*10=1.792*107 PFLOS。同样地,假定推理的有效算力比率为30%,则每日对话产生推理算力需求为5.973*107 PFLOS。按照上述方法测算,ChatGPT每日对话需要338台服务器同时工作,每日耗电约为52 728 kWh。
从上述分析可知,在当前“双碳”背景下,如何突破技术和成本的双重压力满足AIGC带来的高算力需求,如何应对AIGC构建与应用过程中所带来的算力洪峰等问题都需要深入思考和解决。
(3)构建健壮性的智算网络及调度平台面临较大挑战
由于算力资源的异构特性,针对智算集群,如何通过智算网络实现高效连接、调度平台进行高效配置等将决定其有效算力比率。智算平台要求节点之间以极低时延(微秒级)、高带宽(百GB以上)传输海量的数据信息,以保证多个节点按照统一的步调分工协作完成相应任务。同时,智算中心等算力提供方所处位置区域、算力成本、能够提供的资源类型等存在差异,如何将适合的计算资源分配给需求方也显得尤为关键,同时也对算力的统一调度提出较大挑战。当前,运营商提出算力网络概念,并在相关技术上取得一系列突破,但在算力调度、算力路由、算网一体等方面还需深入研究,以更好适配和满足AIGC技术架构,提升其有效算力比率和数据流通效率等,构建面向国内的智算网络和调度平台将是未来需要深入研究的课题之一。
4 结束语
ChatGPT的出现,加速了AIGC技术和应用的发展。AIGC作为是人工智能1.0时代进入2.0时代的重要标志,已经为人类社会打开了认知智能的大门,它具有非常广泛的应用前景和市场潜力,可以为人类社会带来更多的便利和创新,同时,也要看到AIGC存在诸多挑战和面临的各类风险问题。随着深度学习、NLP等技术的不断进步和融合创新,相信AIGC技术将会在未来数字经济中扮演越来越重要的角色,成为人工智能技术应用的重要组成部分。
参考文献
[1] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[R/OL]. (2022-04-13)[2023-09-19]. https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf.
[2] Bommasani R, Hudson D A, Adeli E, et al. On the opportunities and risks of foundation models[R/OL]. (2021-08-16)[2023-09-19]. https://arxiv.org/abs/2108.07258.
[3] Chowdhery A, Narang S, Devlin J, et al. M Bosma PaLM: Scaling Language Modeling with Pathways[R/OL]. (2022-08-05)[2023-09-19]. https://arxiv.org/abs/2204.02311.
[4] Wei C, Wang Y-C, Wang B, et al. An overview on language models: Recent developments and outlook[J]. arXiv preprint arXiv:2303.05759, 2023.
[5] Devlin J, Chang M-W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]//The Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics. 2019: 4171-4186.
[6] LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015,521(7553): 436-444.
[7] Wu J, Gan W, Chen Z, et al. AI-generated content(AIGC): A survey[J]. arXiv preprint arXiv:2304.06632, 2023: 1-17.
[8] Cao Y, Li S, Liu Y, et al. A comprehensive survey of AI-generated content (AIGC): A history of generative AI from GAN to ChatGPT[J]. arXiv preprint arXiv:2303.04226, 2023: 1-44.
[9] Wang Y T, Pan Y H, Yan M, et al. A Survey on ChatGPT: AI-Generated Contents, Challenges, and Solutions[J]. IEEE Open Journal of the Computer Society( Early Access), 2023: 1-20.
[10] Barrett C, Boyd B, Burzstein E, et al. Identifying and mitigating the security risks of generative ai[J]. arXiv preprint arXiv:2308.14840, 2023.
[11] Wang Y C, Xue J T, Wei C W, et al. An Overview on Generative AI at Scale with Edge-Cloud Computing[J]. IEEE Open Journal of the Communications Society, 2023: 1-22.
[12] Ning H, Wang H, Lin Y, et al. A survey on metaverse: the state-of-the-art, technologies, applications, and challenges[J]. arXiv preprint arXiv:2111.09673, 2021.
[13] Gan W, Ye Z, Wan S, et al. Web 3.0: The future of Internet[C]//Companion Proceedings of the ACM Web Conference. 2023: 1-10.
[14] 贵重,李云翔,王光涛. GPT-4带来的变化与挑战[J]. 电信工程技术与标准化, 2023(4): 16-19.
[15] 刘禹良,李鸿亮,白翔,等. 浅析ChatGPT:历史沿革、应用现状及前景展望[J]. 中国图像图形学报, 2023(4): 893-902.
[16] 谢巍巍,薛锋章. 问答ChatGPT之后:超大预训练模型的机遇和挑战[J]. 自动化学报, 2023(4): 705-717.
[17] 贵重,李云翔,江为强. 人工智能的发展与挑战:以ChatGPT为例[J]. 电信工程技术与标准化, 2023,36(3): 24-28.
[18] 胡滨雨,郭敏杰. 新一轮AI爆发下电信运营商的挑战和机遇[J]. 中国电信业, 2023(4): 23-27.
[19] 兰祝刚,任然. ChatGPT 对运营商影响及发展建议[J]. 中国电信业, 2023(4): 28-31.
[20] 陈俊明,张洁,左罗. 运营商AI能力建设及演进探讨[J]. 邮电设计技术, 2021(12): 83-88.
[21] 张嗣宏,张健. 以ChatGPT为代表的生成式AI对通信行业的影响和应对思考[J]. 电信科学, 2023(5): 67-75.
[22] 刘亮,张琛,杨学燕. 生成式人工智能技术对通信行业的影响研究[J]. 邮电设计技术, 2023(7): 1-7.
[23] 国际数据公司(IDC)与浪潮信息. 2023-2024中国人工智能计算力发展评估报告[R]. 2023.
[24] 中国人工智能学会. 中国人工智能系列白皮书——大模型技术-2023版[R]. 2023.
[25] 华为公司. 2023年预训练大模型白皮书[R]. 2023. ★