从可靠性的角度理解 tcp
可靠性是 tcp 最大的特点。常见的用户层协议,比如 http, ftp, ssh, telnet 均是使用的 tcp 协议。可靠性,即从用户的角度来看是可靠的,只要用户调用系统调用返回成功之后,tcp 协议栈保证将报文发送到对端。引起不可靠的表现主要有两个方面,丢包和乱序。对于 tcp 来说,即使报文在传输过程中出现了丢包或者乱序,tcp 协议也能通过重传、排序等方式解决这些问题。
(1)丢包
丢包的原因,比如链路上有一个节点(比如路由器, 交换机或服务器)的网卡接收缓冲区满,会导致丢包;再比如链路信号质量不好,导致数据传输过程中出现错误,进而导致 crc 校验失败而导致丢包,tcp 通过 ack 回应机制和重传机制来解决丢包问题,tcp 每发送一个报文,便会启动重传定时器,当超时之后没有收到接收方的响应,便会重传。
(2)乱序
乱序问题,可能由链路上的传输设备引起,也可能由一些等价路由,导致前后发送的报文走不同的路径,进而导致乱序,tcp 在接收侧可以对报文进行排序,保证用户接收到的报文的顺序和发送端发送的顺序是一致的。
本文记录 tcp 实现可靠性的一些技术点,包括面向连接,序列号,ack,重传机制。其中面向连接是基础,序列号,重传机制等都针对一个特定的连接,序列号和重传机制可以解决丢包问题,序列号和保序功能可以解决乱序问题。
1 面向连接
tcp 是面向连接的协议,通信的两端在正式收发数据之前要先建立连接,只有连接建立成功之后,双方才能收发数据,当双方通信结束之后,需要关闭连接。建立连接需要进行三次握手,关闭连接需要进行四次挥手。
下图是用 tcpdump 抓到的 tcp 报文,建立连接之后,客户端和服务端分别收发了 5 个报文,然后关闭连接。从下图可以看出,建立连接的 3 次握手和断开连接过程的 4 次挥手。
如下 tcpdump 显示的信息,Flags 后边的中括号中是 tcp 报文包含的标志,其中 S 表示 SYN,为建立连接时的标志;F 表示 FIN,是断开连接时的标志;ack 用 . 来表示,表示报文中去人序列号有效。

也可以将 tcpdump 抓到的包保存成 pcap 文件,用 wireshark 打开,进行分析:
建立连接过程:

建立连接的过程,最终的是两端知道了对端的 ip 地址和端口号,ip 地址和端口号组成的四元组可以标记一条 tcp 连接。除此之外还需要协商以下内容,协商的内容在第一次握手和第二次握手的报文中携带。
| 初始序列号 |
初始序列号不是从 0 开始,而是一个相对随机的数,可以防攻击,也可以防止两条相同的新旧连接报文重复。 |
| window |
建立连接过程中,双方会向对端通知自己的接收窗口的大小,用于流量控制。 接收窗口和选项字段 wscale 共同决定实际窗口的大小 实际窗口 = 窗口 * (1 << wscale) |
| 时间戳 |
这个可以用来计算 rtt |
| MSS |
maximum segment mss 即最大段长度。 在通信的双方正式收发数据之前,需要协商 mss,mss 一般情况下是 1460,即 1500 (以太网 mtu) - 20 (ip 头长度) - 20 (tcp 头长度). |
| SACK |
是否支持选择 ack |
关闭连接过程:

2 序号
序列号是 tcp 可靠性的基础,ack, 重传,窗口,保序这些技术点的实现均以序列号为基础。
tcp 中的序号是给每一个字节进行编号,这也符合 tcp 字节流的语义。在 tcp 首部当中有序列号,也有确认号。
序列号:是本端发送数据的第一个字节的序列号。
确认号:这个是要对端发送的报文下一个字节的序号,也就是说这个序号的字节,对端还没有发送过来。
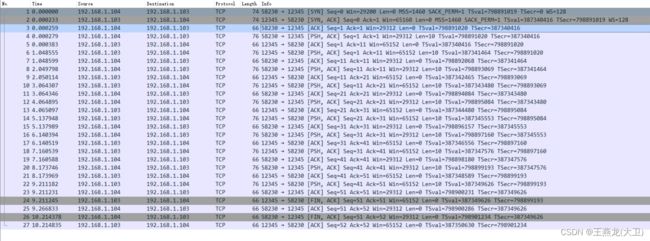
可以看下边这张截图,192.168.1.104 给 192.168.1.103 发送了 10 字节的报文,序列号是 1,也就是这次发送的 10 字节的报文序号是 1 ~ 10。192.168.1.103 收到报文之后,就会给对端回复 ack,这个 ack 序号是 11,下边一行,192.168.1.104 发送的第二个报文的序列号是 11。

2.1 初始序列号的确定
客户端和服务端,初始序列号的确定均是通过函数 secure_tcp_seq() 来进行。
从这个函数来看,计算序列号,包括三部分内容:
| 随机数 net_secret_init() |
这个函数从调用过程中的函数名字来说,是初始化一个随机数,但是使用 systemtap 打印多次建立连接的过程,这个数并没有变,所以说并不是一个随机数。 |
| tcp 四元组 源 ip, 目的 ip,源端口,目的端口 |
四元组可以标记一条 tcp 流。 |
| seq_scale() |
如果连接的四元组相同,那么计算出来的哈希值就是相同的。seq_scale() 这个函数给 ISN 增加了时间因素,这样可以避免前后两次建立的四元组相同的一条连接的初始序列号相同。 |
/* secure_tcp_seq_and_tsoff(a, b, 0, d) == secure_ipv4_port_ephemeral(a, b, d),
* but fortunately, `sport' cannot be 0 in any circumstances. If this changes,
* it would be easy enough to have the former function use siphash_4u32, passing
* the arguments as separate u32.
*/
u32 secure_tcp_seq(__be32 saddr, __be32 daddr,
__be16 sport, __be16 dport)
{
u32 hash;
net_secret_init();
hash = siphash_3u32((__force u32)saddr, (__force u32)daddr,
(__force u32)sport << 16 | (__force u32)dport,
&net_secret);
return seq_scale(hash);
}
做一个实验,为了验证初始序号的影响因素,在测试的时候,tcp 的客户端也通过 bind 绑定一个端口,这样四元组(源端口,源 ip 地址,目的端口,目的 ip 地址)是不变的,反复多次建立连接,关闭连接,查看序列号的变化规律。
序列号是一个 32 位的数,最大 42.9 亿,从下图可以看到,当一个连接的四元组不发生变化的时候,初始序号是随着时间递增的,翻转的周期大概是 275s。下图中标红的两个序列号数值相近,可以认为发生了一次翻转,时间分别是 09:59:45 和 10:04:24,相差 279s。

从 seq_scale() 的实现当中也可以看到,seq 基于系统的 ns 时钟进行递增,如果 1ns 增长一个序列号的话,那么序号的翻转周期就是 4.3s (unsigned int 最大值是 42.9 亿), 是远小于 MSL 的,为了让翻转周期大于 MSL,代码进行了 64 倍的延迟,延迟之后即为 4.3s * 64 ≈ 275s。
从这个规律可以看出,在多次建立连接的过程中,net_secret 并不是随机数。
使用 systemtap 工具,打印函数 siphash_3u32() 的入参,net_secret 保持不变, key[0] 和 key[1] 是 secret 的值。
probe kernel.function("siphash_3u32") {
printf("saddr: %d, key: %p, key[0]: %lu, key[1]: %lu\n", $first, $key, $key->key[0], $key->key[1])
}

static u32 seq_scale(u32 seq)
{
/*
* As close as possible to RFC 793, which
* suggests using a 250 kHz clock.
* Further reading shows this assumes 2 Mb/s networks.
* For 10 Mb/s Ethernet, a 1 MHz clock is appropriate.
* For 10 Gb/s Ethernet, a 1 GHz clock should be ok, but
* we also need to limit the resolution so that the u32 seq
* overlaps less than one time per MSL (2 minutes).
* Choosing a clock of 64 ns period is OK. (period of 274 s)
*/
return seq + (ktime_get_real_ns() >> 6);
}函数 secure_tcp_seq() 调用栈:
客户端:
0xffffffff9d3aeb80 : secure_tcp_seq+0x0/0xc0 [kernel]
0xffffffff9d47a0bc : tcp_v4_connect+0x47c/0x4d0 [kernel]
0xffffffff9d495331 : __inet_stream_connect+0xd1/0x370 [kernel]
0xffffffff9d495606 : inet_stream_connect+0x36/0x50 [kernel]
0xffffffff9d3980ca : __sys_connect+0x9a/0xd0 [kernel]
0xffffffff9d398116 : __x64_sys_connect+0x16/0x20 [kernel]
0xffffffff9cc042bb : do_syscall_64+0x5b/0x1a0 [kernel]
0xffffffff9d6000ad : entry_SYSCALL_64_after_hwframe+0x65/0xca [kernel]
0xffffffff9d6000ad : entry_SYSCALL_64_after_hwframe+0x65/0xca [kernel] (inexact)
服务端:
0xffffffff9d3aeb80 : secure_tcp_seq+0x0/0xc0 [kernel]
0xffffffff9d4691fc : tcp_conn_request+0x3ec/0xb80 [kernel]
0xffffffff9d46f084 : tcp_rcv_state_process+0x214/0xd62 [kernel]
0xffffffff9d47af14 : tcp_v4_do_rcv+0xb4/0x1e0 [kernel]
0xffffffff9d47d3b1 : tcp_v4_rcv+0xc11/0xc50 [kernel]
0xffffffff9d450abc : ip_protocol_deliver_rcu+0x2c/0x1d0 [kernel]
0xffffffff9d450cad : ip_local_deliver_finish+0x4d/0x60 [kernel]
0xffffffff9d450da0 : ip_local_deliver+0xe0/0xf0 [kernel]
0xffffffff9d45102b : ip_rcv+0x27b/0x36f [kernel]
0xffffffff9d3be835 : __netif_receive_skb_core+0x5c5/0xca0 [kernel]
0xffffffff9d3befad : netif_receive_skb_internal+0x3d/0xb0 [kernel]
0xffffffff9d3bfa0a : napi_gro_receive+0xba/0xe0 [kernel]
0xffffffffc032364e
0xffffffffc032364e (inexact)
0xffffffffc03220d7 (inexact)
0xffffffff9d3c026d : __napi_poll+0x2d/0x130 [kernel] (inexact)
0xffffffff9d3c0763 : net_rx_action+0x253/0x320 [kernel] (inexact)
0xffffffff9d8000d7 : __do_softirq+0xd7/0x2d6 [kernel] (inexact)
0xffffffff9ccf27a7 : irq_exit+0xf7/0x100 [kernel] (inexact)
0xffffffff9d601e7f : do_IRQ+0x7f/0xd0 [kernel] (inexact)
0xffffffff9d600a8f : ret_from_intr+0x0/0x1d [kernel] (inexact)
0xffffffff9d57cd9e : native_safe_halt+0xe/0x10 [kernel] (inexact)
0xffffffff9d57cc5a : __cpuidle_text_start+0xa/0x10 [kernel] (inexact)
0xffffffff9d57cef0 : default_idle_call+0x40/0xf0 [kernel] (inexact)
0xffffffff9cd22354 : do_idle+0x1f4/0x260 [kernel] (inexact)
0xffffffff9cd2258f : cpu_startup_entry+0x6f/0x80 [kernel] (inexact)
0xffffffff9cc5929b : start_secondary+0x19b/0x1e0 [kernel] (inexact)
0xffffffff9cc00107 : secondary_startup_64_no_verify+0xc2/0xcb [kernel] (inexact)
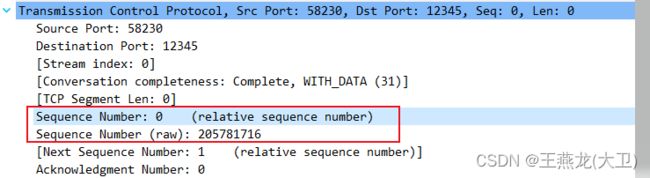
WARNING: Missing unwind data for a module, rerun with 'stap -d e1000'初始序列号是一个随机数,为什么在 wireshark 上看到的还是 0 ?
这是因为 wireshark 显示的时候进行了处理,显示的是相对值,查看详细信息,也可以看到原始的序列号。
2.2 建立连接和关闭连接过程均会消耗一个序列号
从下边这张图可以看到,建立连接过程中没有数据(len 均是 0),序列号从 0 开始,但是 ACK 都是 1,所以实际传输数据时,序列号从 1 开始,序列号 0 没有数据。
在断开连接过程中,实际传输的数据到序列号是 5,0。FIN 报文没有数据(Len 是 0),但是对 FIN 包的 ACK, 确认号却增加了 1。

2.3 序列号翻转
序列号的大小关系,无外乎 ==, >, < 这三种。在 tcp 中,判断序列号是否相等时可以直接通过 == 来判断,但是对序列号进行判断时,不是进行直接判断,而是通过 before() 这个函数来判断,在 before 的基础上封装出来一个宏 after。序列号是无符号 32 位整数,在 before() 函数里边,将无符号数的计算结果,转化成有符号数,再和 0 进行比较,来判断 seq1 和 seq2 的先后关系。
这种判断方式通过有符号数和无符号数之间的转换,对于无符号整型(unisgned int)来说,最大值是 4294967295,当两个值的差值小于一半(2147483647)的时候,那么值小的 before 值大的,否则值大的 before 值小的, 即 before(2147483649, 1) 返回 true,before(2147483648, 1) 返回 false。
tcp 使用这种方式来判断序列号的前后关系,就要求一个 tcp 包的长度小于 2147483647,即 2.1GB 左右,显然是满足的。
static inline bool before(__u32 seq1, __u32 seq2)
{
return (__s32)(seq1-seq2) < 0;
}
#define after(seq2, seq1) before(seq1, seq2)为了简单,使用一个字节的数据进行实验:
#include
#include
#include
static inline int before(unsigned char seq1, unsigned char seq2) {
return (char)(seq1 - seq2) < 0;
}
int main() {
printf("before(20, 10): %u\n", before(20, 10));
printf("before(255, 10): %u\n", before(255, 10));
printf("before(255, 127): %u\n", before(255, 127));
printf("before(255, 128): %u\n", before(255, 128));
return 0;
} 运算结果:
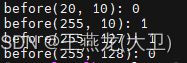
20 在 10 之前,false
255 在 10 之前,true
255 在 127 之前,true
255 在 128 之前,false
我们以 255 和 127 的比较进行分析,涉及到源码、反码、补码的概念:
对于无符号数据类型来说,没有符号位,所以最高位也可以当做数值来使用;对于有符号数据类型来说,最高位表示符号, 1 表示负数,0 表示正数。
数据在计算机中进行计算,都是通过补码来计算。
255 补码 : 1111 1111 // 无符号数,只有正数,源码,补码,反码是相等的
127 的补码:0111 1111
255 - 127 的补码是 1000 0000, 如果是无符号数的话,那么这个补码代表数值是 128, 如果是有符号数的话,那么这个数代表的就是负数,-128,所以说 255 是在 127 之前的。
当一个报文的大小大于 uint32_max 的 一半的时候,可能会导致误判,这个包的大小要大于 2G, 对于现在的网络来说,链路上不存在这么大的包。
所以 tcp 使用 before() 函数来判断序列号的前后关系,是没有问题的,这种判断方式适用于序列号发生翻转的情况。
接收到一个报文之后,在函数 tcp_v4_fill_cb() 里边完成 skb 中序列号的初始化:
static void tcp_v4_fill_cb(struct sk_buff *skb, const struct iphdr *iph,
const struct tcphdr *th)
{
/* This is tricky : We move IPCB at its correct location into TCP_SKB_CB()
* barrier() makes sure compiler wont play fool^Waliasing games.
*/
memmove(&TCP_SKB_CB(skb)->header.h4, IPCB(skb),
sizeof(struct inet_skb_parm));
barrier();
TCP_SKB_CB(skb)->seq = ntohl(th->seq);
TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin +
skb->len - th->doff * 4);
TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th);
TCP_SKB_CB(skb)->tcp_tw_isn = 0;
TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph);
TCP_SKB_CB(skb)->sacked = 0;
TCP_SKB_CB(skb)->has_rxtstamp =
skb->tstamp || skb_hwtstamps(skb)->hwtstamp;
}2.4 序列号的作用
接收侧可以基于序号判断是否乱序
2.5 序列号维护
tcp 序列号在 tcp_sock 中进行维护,最容易理解的是 rcv_nxt 和 snd_nxt。
struct tcp_sock {
u32 rcv_nxt; /* What we want to receive next */
u32 copied_seq; /* Head of yet unread data */
u32 snd_nxt; /* Next sequence we send */
u32 write_seq; /* Tail(+1) of data held in tcp send buffer */
u32 notsent_lowat; /* TCP_NOTSENT_LOWAT */
u32 pushed_seq; /* Last pushed seq, required to talk to windows */
};rcv_nxt:
rcv_nxt 是接收侧要接收的下一个字节的报文。
接收侧要根据当前接收的报文序列号和 rcv_nxt 之间的关系,来判断该报文是否是乱序报文。打个比方,如果当前 rcv_nxt 是 1000,并且收到的报文的序列号是 1000,那么就会把该报文放入接收队列并更新 rcv_nxt;如果当前收到的报文的序列号是 1100, 那么第 1001 ~ 1099 的报文还没有收到,序列号是 1100 的报文就是乱序报文,会被放入乱序队列,并且不会更新 rcv_nxt。
rcv_nxt 在函数 tcp_rcv_nxt_update() 进行更新。
/* If we update tp->rcv_nxt, also update tp->bytes_received */
static void tcp_rcv_nxt_update(struct tcp_sock *tp, u32 seq)
{
u32 delta = seq - tp->rcv_nxt;
sock_owned_by_me((struct sock *)tp);
tp->bytes_received += delta;
WRITE_ONCE(tp->rcv_nxt, seq);
}接收队列用一个双向链表来维护,在 struct sock 中管理;乱序队列用一个红黑树来维护,在 struct tcp_sock 中进行管理。
struct sock {
struct sk_buff_head sk_receive_queue;
}
struct tcp_sock {
/* OOO segments go in this rbtree. Socket lock must be held. */
struct rb_root out_of_order_queue;
}tcp 报文的入队操作在函数 tcp_data_queue() 中完成,在该函数中会判断报文是否是乱序报文。该函数的调用栈如下:
0xffffffffa9a6d930 : tcp_data_queue+0x0/0xb50 [kernel]
0xffffffffa9a6e642 : tcp_rcv_established+0x1c2/0x5c0 [kernel]
0xffffffffa9a7af8a : tcp_v4_do_rcv+0x12a/0x1e0 [kernel]
0xffffffffa9a7d2e3 : tcp_v4_rcv+0xb43/0xc50 [kernel]
0xffffffffa9a50abc : ip_protocol_deliver_rcu+0x2c/0x1d0 [kernel]
0xffffffffa9a50cad : ip_local_deliver_finish+0x4d/0x60 [kernel]
0xffffffffa9a50da0 : ip_local_deliver+0xe0/0xf0 [kernel]
0xffffffffa9a5102b : ip_rcv+0x27b/0x36f [kernel]
0xffffffffa99be835 : __netif_receive_skb_core+0x5c5/0xca0 [kernel]
0xffffffffa99befad : netif_receive_skb_internal+0x3d/0xb0 [kernel]
0xffffffffa99bfa0a : napi_gro_receive+0xba/0xe0 [kernel]
0xffffffffc011564e
0xffffffffc011564e (inexact)
0xffffffffc01140d7 (inexact)
0xffffffffa99c026d : __napi_poll+0x2d/0x130 [kernel] (inexact)
0xffffffffa99c0763 : net_rx_action+0x253/0x320 [kernel] (inexact)
0xffffffffa9e000d7 : __do_softirq+0xd7/0x2d6 [kernel] (inexact)
0xffffffffa92f27a7 : irq_exit+0xf7/0x100 [kernel] (inexact)
0xffffffffa9c01e7f : do_IRQ+0x7f/0xd0 [kernel] (inexact)
0xffffffffa9c00a8f : ret_from_intr+0x0/0x1d [kernel] (inexact)
0xffffffffa9b7cd9e : native_safe_halt+0xe/0x10 [kernel] (inexact)
0xffffffffa9b7cc5a : __cpuidle_text_start+0xa/0x10 [kernel] (inexact)
0xffffffffa9b7cef0 : default_idle_call+0x40/0xf0 [kernel] (inexact)
0xffffffffa9322354 : do_idle+0x1f4/0x260 [kernel] (inexact)
0xffffffffa932258f : cpu_startup_entry+0x6f/0x80 [kernel] (inexact)
0xffffffffa925929b : start_secondary+0x19b/0x1e0 [kernel] (inexact)
0xffffffffa9200107 : secondary_startup_64_no_verify+0xc2/0xcb [kernel] (inexact)tcp_data_queue() 中入队逻辑:
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{
// 报文有序,直接调用 tcp_queue_rcv() 进行接收
if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) {
eaten = tcp_queue_rcv(sk, skb, &fragstolen);
if (skb->len)
tcp_event_data_recv(sk, skb);
// 当前这个报文是有序的,并且乱序队列中有报文
// 当前这个报文有可能将之前乱序的空洞填充上,
// 所以尝试将乱序队列中能接上号的报文从乱序队列中出队,并放入接收队列中
if (!RB_EMPTY_ROOT(&tp->out_of_order_queue)) {
tcp_ofo_queue(sk);
return;
}
// 报文是乱序报文,将之放入乱序队列,等前边的空洞填充之后再上送
tcp_data_queue_ofo(sk, skb);
}snd_nxt:
snd_nxt 是发送侧下一个要发送的字节的序号。
每发送一个报文,就会更新,snd_nxt 的更新在 tcp_event_new_data_sent() 函数中完成。
0xffffffffa9a70320 : tcp_event_new_data_sent+0x0/0xb0 [kernel]
0xffffffffa9a73ec4 : tcp_write_xmit+0x444/0x12b0 [kernel]
0xffffffffa9a74d62 : __tcp_push_pending_frames+0x32/0xf0 [kernel]
0xffffffffa9a60c68 : tcp_sendmsg_locked+0xc38/0xda0 [kernel]
0xffffffffa9a60df7 : tcp_sendmsg+0x27/0x40 [kernel]
0xffffffffa999713e : sock_sendmsg+0x3e/0x50 [kernel]
0xffffffffa99971e7 : sock_write_iter+0x97/0x100 [kernel]
0xffffffffa952baf2 : new_sync_write+0x112/0x160 [kernel]
0xffffffffa952f1e5 : vfs_write+0xa5/0x1a0 [kernel]
0xffffffffa952f45f : ksys_write+0x4f/0xb0 [kernel]
0xffffffffa92042bb : do_syscall_64+0x5b/0x1a0 [kernel]
0xffffffffa9c000ad : entry_SYSCALL_64_after_hwframe+0x65/0xca [kernel]
0xffffffffa9c000ad : entry_SYSCALL_64_after_hwframe+0x65/0xca [kernel] (inexact)
在发送侧也有两个队列,一个是发送队列,一个是重传队列。
发送队列可以理解为发送缓冲区,用户调用 send() 时,报文并不一定真正发送出去了,而是写在发送缓冲区就返回了。
sk->sk_write_queue
sk->tcp_rtx_queue
struct sock {
union {
struct sk_buff *sk_send_head;
struct rb_root tcp_rtx_queue;
};
struct sk_buff_head sk_write_queue;
};调用函数 tcp_transmit_skb() 发送 tcp 报文,发送成功之后便会调用函数 tcp_event_new_data_sent() ,在函数 tcp_event_new_data_sent() 中主要做 3 件事。
1、更新 snd_nxt,snd_nxt 表示已经发送出去的数据
2、将 skb 从 发送队列里边移除
3、将 skb 放到重传队列中,tcp_transmit_skb() 返回成功,指标是报文从发送侧发送成功了,并不表示接收侧接收了这个报文,所以在这个时候 skb 还不能真正删除,如果这个报文被确认,那么确认的时候可以将 skb 删除,如果不能被确认,那么需要重传
static void tcp_event_new_data_sent(struct sock *sk, struct sk_buff *skb)
{
// 更新 snd_nxt
WRITE_ONCE(tp->snd_nxt, TCP_SKB_CB(skb)->end_seq);
// 将 skb 从发送队列里边移出
__skb_unlink(skb, &sk->sk_write_queue);
// 将 skb 放到重传队列中
tcp_rbtree_insert(&sk->tcp_rtx_queue, skb);
}3 ack
ack 是实现可靠性的必要条件。
ack 是接收侧在收到报文之后,给发送侧的一个回应,发送侧收到 ack 后,才会认为数据发送成功,这个时候,发送侧的数据才可以释放;如果发送侧长时间收不到 ack,那么就会重传。ack 和重传是联系紧密的两个概念,不同的 ack 也会影响发送方的重传选择。在 tcp 首部中有两个地方和 ack 有关,一个是 ack 标志,一个是 ack 序号,当 ACK 标志为 1 的时候,说明 ack 序列号是有效的,否则 ack 序列号无效。
常见的 ack 主要包括连续 ack, SACK 以及延时 ack。
3.1 连续 ack
连续 ack 是最常见的 ack, 即每收到一个报文之后便会对该报文进行 ack,如果发送的数据中间有丢包情况,如下图所示,发送方发送 报文 1 ~ 报文6,其中 报文 2 在链路上丢包,那么只要接收方收不到这个数据,后边就会一直返回 ack 为 1000 的报文。连续 ack 只能告诉发送端连续收到的报文,即使后边的报文 4 收到了,发送端根据 ack 也不能确定。发送端收到重复 ack 个数达到一定数量时(默认是 4 次,1 次正常的,3 次冗余的),便会进行快速重传,快速重传的时候除了 [1000, 1500) 这个报文,后边的报文也都会重传。

3.2 SACK
SACK 全称 selective acknowlegment,即选择性确认,SACK 是对连续 ack 补充。如上图所示,当接收方收到报文 3 之后,ack 依然是 1000,但是可以在 tcp 首部中增加选项字段,告诉发送方,报文 3 也收到了,发送方收到这个 ack 之后,只重传报文 2 就可以了。SACK 和 ACK 之间并不是相互代替的互斥关系,而是共存的关系,包含 SACK 的报文,仍然有 ACK 信息。

SACK 是 tcp 的可选项,在建立连接时,通信双方在第一次握手和第二次握手的 SYN 和 SYN + ACK 报文中携带 SACK 携带选项。SACK 允许字段是一个选项字段, 选项类型是 4,选项长度是 2。tcp 的选项字段可以有多个种类,比如常见的在建立连接过程中需要协商的内容 mss, sack 都是保存在选项字段中。每一个选项都至少包括两项内容,kind 和 length,kind 说明选项的类型,length 表示选项的长度,长度可以知道软件依次偏移解析不同的选项。
如下图所示,是用 wireshark 抓到的建立连接过程中的选项字段,其中就包括 SACK 选项。

SACK 使用了两个选项,一个是 SACK permitted,另一个是 SACK, kind 分别是 4 和 5。SACK permmited 在建立连接过程中携带,SACK 在传输数据的时候携带,是真正的 SACK 数据。SACK permitted 选项的长度是固定的,为 2;SACK 选项的长度是变化的,每一个 SACK 包括 left edge 和 right edge 两个字段,共 8 字节,另外还包括 kind 字段和 length 字段各 1 个字节,而 tcp选项字段最大长度为 40 字节,所以 SACK 选项最长为 2 + 8 * 4 = 34 字节。
其中 left edge 表示收到的不连续块的第一个序号,right edge 表示收到的不连续块的最后一个序号 + 1,即左闭右开区间。

linux 默认情况下,sack 是打开的,cat /proc/sys/net/ipv4/tcp_sack 显示为 1 则表示打开,在创建连接的过程中就会携带 SACK permitted 选项。
3.3 延时 ACK
延时 ack 是为了减小链路上纯 ack 报文的比例,提高带宽利用率,因为纯 ack 报文中并没有有效数据。当接收侧收到数据之后并不立即返回 ack,而是启动一个定时器,如果在超时时间之内本端有向对端发送的数据,那么 ack 就会和有效数据一块发向对端,否则超时之后发送 ack 报文。延时 ack 定时器的最大超时时间为 200ms (用宏 TCP_DELACK_MAX 来表示),最小超时时间和系统的 HZ 有关系,如果 HZ 大于 100,则为 40ms,最大超时时间和最小超时时间分别用宏 TCP_DELACK_MAX 和 TCP_DELACK_MIN 来表示。
#define TCP_DELACK_MAX ((unsigned)(HZ/5)) /* maximal time to delay before sending an ACK */
#if HZ >= 100
#define TCP_DELACK_MIN ((unsigned)(HZ/25)) /* minimal time to delay before sending an ACK */
#define TCP_ATO_MIN ((unsigned)(HZ/25))
#else
#define TCP_DELACK_MIN 4U
#define TCP_ATO_MIN 4U
#endif4 重传机制
重传和 ack 结合在一起来工作。简单来说就是发送侧发送一个报文之后,就启动一个定时器等接收方的回应,如果超时没有等到 ack 回应,那么发送方就会认为发生了丢包,然后会重新发送这个报文;反之,如果在超时时间内收到了对端回应的 ack, 说明接收侧已经收到了这个报文,发送侧就可以放心地把这个报文占用的资源释放了。
在两种情况下会发生重传,一个是超时重传,即上文描述的这种机制,在时间维度上触发重传;一个是快速重传,如果在重传定时器超时之前,接收方连续发送了 3 个相同的冗余 ack,那么发送方就不要再发送新的数据了,需要将 ack 指定的这个报文进行重传。
超时重传机制示意图如下,发送方发送报文序列号 1000,长度为 200,发送之后便会启动重传定时器,正常情况下,在定时器超时之前,接收方会返回 ack,如果定时器超时的时候没有收到 ack,发送方便会认为这个报文丢失,从而会重传这个报文。

快速重传示意图如下图所示,发送侧发送序号为 1000,长度为 200 的报文,这个报文如果在链路上丢了,发送侧后边发送的报文,都会收到 ack 为 1000 的回应,连续收到 4 (1 次正常 ack, 3 次冗余 ack) 次 ack 均是 1000 的报文之后,就需要对序列号是 1000 的这个报文进行重传。

4.1 超时重传
(1)什么时候启动重传定时器 ?
发包路径
// 函数 tcp_write_xmit() 中会调用 tcp_transmit_skb() 进行发包
// 如果 tcp_transmit_skb() 返回成功,则调用函数 tcp_event_new_data_sent()
// 在函数 tcp_event_new_data_sent() 中将报文放入重传队列中,同时启动重传定时器
static void tcp_event_new_data_sent(struct sock *sk, struct sk_buff *skb)
{
// packets_out 表示发送出去,但是还没有收到 ack 的报文
// 在该函数的后边会更新这个变量,把刚发送的报文加上去
// 当收到 ack 报文的时候会对这个变量做减法
unsigned int prior_packets = tp->packets_out;
// 更新 snd_nxt
WRITE_ONCE(tp->snd_nxt, TCP_SKB_CB(skb)->end_seq);
// 将 skb 从发送队列中移除,然后将 skb 放入重传队列
// 报文发向 ip 层成功之后并不能立即释放 skb, 因为报文在链路上可能会丢失
// 所以先将报文移入重传队列,如果这个报文在链路上丢了的话还可重传
// 只有收到这个报文的 ack 时,说明接收侧已经收到了这个报文
// 这个时候才可以将报文从重传队列中移除,释放 skb 资源
__skb_unlink(skb, &sk->sk_write_queue);
tcp_rbtree_insert(&sk->tcp_rtx_queue, skb);
// 更新 packets_out
tp->packets_out += tcp_skb_pcount(skb);
// prior_packets 即不带这次发送的报文,之前发送出去但是还没有确认的报文
// 如果都已经确认了,说明重传定时器这个时候没有工作,需要启动重传定时器
// 如果还有没被确认的,说明上次发包的时候还就已经启动了重传定时器,并且没有超时
// 这种情况下就不需要再次启动重传定时器了
// 具体启动重传定时器的工作在 tcp_rearm_rto() 中完成
if (!prior_packets || icsk->icsk_pending == ICSK_TIME_LOSS_PROBE)
tcp_rearm_rto(sk);
}
// 函数 tcp_rearm_rto() 中首先计算 rto,即重传定时器的超时时间
// 由此可见重传定时器的超时时间不是固定不变的,而是和链路状态有关系
// 计算 rto 之后便会通过函数 tcp_reset_xmit_timer() 启动重传定时器
void tcp_rearm_rto(struct sock *sk)
{
// 如果 packets_out 是 0,说明发送出去的报文已经全部确认,则可以停掉重传定时器
if (!tp->packets_out) {
inet_csk_clear_xmit_timer(sk, ICSK_TIME_RETRANS);
} else {
u32 rto = inet_csk(sk)->icsk_rto;
/* Offset the time elapsed after installing regular RTO */
if (icsk->icsk_pending == ICSK_TIME_REO_TIMEOUT ||
icsk->icsk_pending == ICSK_TIME_LOSS_PROBE) {
s64 delta_us = tcp_rto_delta_us(sk);
/* delta_us may not be positive if the socket is locked
* when the retrans timer fires and is rescheduled.
*/
rto = usecs_to_jiffies(max_t(int, delta_us, 1));
}
tcp_reset_xmit_timer(sk, ICSK_TIME_RETRANS, rto,
TCP_RTO_MAX);
}
}(2) 收到 ack 报文的时候如何改变重传定时器
收到 ack 报文之后,如果发现已经发送的报文都已经被确认,那么就会停掉重传定时器;否则,则会重启重传定时器。
// tcp_ack() 函数处理接收到的 ack 报文
// tcp_ack() 函数中调用 tcp_clean_rtx_queue() 来将已经 ack 的报文从重传队列中移除,
// 同时对 tp->packets_out 做减法
// tcp_clean_rtx_queue() 中会判断是不是有新的报文被确认,如果是,则返回的 flag 中包含 FLAG_SET_XMIT_TIMER 标志
// 在 tcp_ack() 中就会重置重传定时器
static int tcp_ack(struct sock *sk, const struct sk_buff *skb, int flag)
{
// 如果有新的数据被确认,则返回的 flag 中带有标志 FLAG_SET_XMIT_TIMER
flag |= tcp_clean_rtx_queue(sk, skb, prior_fack, prior_snd_una,
&sack_state, flag & FLAG_ECE);
// FLAG_SET_XMIT_TIMER 这个标志说明有数据被确认,
// 这种情况下就需要重新设置重传定时器
// tcp_set_xmit_timer() 最终会调用到 tcp_rearm_rto()
// 在 tcp_rearm_rto() 中判断,
// 如果发送出去的报文都已经确认,则停止重传定时器,否则 reset 重传定时器
if (flag & FLAG_SET_XMIT_TIMER)
tcp_set_xmit_timer(sk);
}(3) 重传定时器回调函数中如何重传 ?
重传定时器超时,最终会调用函数 tcp_retransmit_timer() 进行重传。在该函数中主要做的工作有三个:
- 从重传队列中取出第一个报文,进行重传。
- 重传之前要判断,重传次数是不是已经达到最大值,如果达到最大值,则放弃重传,设置套接字为错误状态。重传次数并不是无限的,而是有最大值限制。放弃重传的判断条件有两个,分别是时间维度和数量维度。函数 tcp_write_timeout() 中进行具体判断。
- 发生重传说明存在丢包,这种情况下进入 loss 状态。
void tcp_retransmit_timer(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct net *net = sock_net(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock *req;
struct sk_buff *skb;
// tp->packets_out 为 0,说明发送的报文都已经 ack 了
// 没有报文需要重传,直接 return
if (!tp->packets_out)
return;
// 从重传队列中取出第一个报文
skb = tcp_rtx_queue_head(sk);
if (WARN_ON_ONCE(!skb))
return;
// 判断重传是否超时,如果超时,则将套接字设置为错误状态,然后退出
// 将套接字设置为错误状态通过函数 tcp_write_err() 完成
// 重传采用退避策略,重传定时器超时时间背书增长
// 最小重传时间是 0.5s,最大是 120s,由下边两个宏来定义
// #define TCP_RTO_MAX ((unsigned)(120*HZ))
// #define TCP_RTO_MIN ((unsigned)(HZ/5))
if (tcp_write_timeout(sk))
goto out;
// 进入 loss 状态
tcp_enter_loss(sk);
// 重传报文
icsk->icsk_retransmits++;
if (tcp_retransmit_skb(sk, tcp_rtx_queue_head(sk), 1) > 0) {
/* Retransmission failed because of local congestion,
* Let senders fight for local resources conservatively.
*/
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
TCP_RESOURCE_PROBE_INTERVAL,
TCP_RTO_MAX);
goto out;
}
out_reset_timer:
// 计算下次重传超时时间并重置重传定时器
if (sk->sk_state == TCP_ESTABLISHED &&
(tp->thin_lto || net->ipv4.sysctl_tcp_thin_linear_timeouts) &&
tcp_stream_is_thin(tp) &&
icsk->icsk_retransmits <= TCP_THIN_LINEAR_RETRIES) {
icsk->icsk_backoff = 0;
icsk->icsk_rto = min(__tcp_set_rto(tp), TCP_RTO_MAX);
} else {
/* Use normal (exponential) backoff */
icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX);
}
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
tcp_clamp_rto_to_user_timeout(sk),
TCP_RTO_MAX);
out:;
}4.2 快速重传
/proc/sys/net/ipv4/tcp_reordering,这个配置默认是 3,也就是说实际收到的 ack 个数是 4(冗余个数是 3), 就会触发快速重传。
对于快速重传,关键要理解接收侧如何判断收到的 ack 是重复 ack。
tcp 收到 ack 时的处理函数是 tcp_ack()。正常情况下,tcp_ack() 中会通过函数 tcp_clean_rtx_queue() 将这次确认的报文从重传队列中移除。如果收到的 ack 是冗余 ack,那么因为前一个 ack 已经将对应的确认的报文从重传队列中移除,所以这次在函数 tcp_clean_rtx_queue() 中并没有从重传队列中移除报文。tcp_ack() 中就是根据有没有从重传队列中移除报文来判断这个 ack 是不是重复 ack。
static int tcp_ack(struct sock *sk, const struct sk_buff *skb, int flag)
{
// 收到一个 ack 报文,那么尝试将这个 ack 中确认的数据从重传队列中移除
// 如果是第一个正常的 ack,那么会把这次确认的报文从重传队列中移除
// 同时返回的 flag 中会有 FLAG_DATA_ACKED 或者 FLAG_SYN_ACKED
// 这个 flag 不会导致后边的 tcp_ack_is_dubious() 返回 true, 也就不会进入tcp_fastretrans_alert()
// 反之,如果当前这个 ack 是冗余 ack,tcp_clean_rtx_queue() 函数中返回的 flag
// 就不会包含 FLAG_DATA_ACKED 和 FLAG_SYN_ACKED,进而会导致调用 tcp_fastretrans_alert()
flag |= tcp_clean_rtx_queue(sk, skb, prior_fack, prior_snd_una,
&sack_state, flag & FLAG_ECE);
// 因为是重复 ack, 所以在函数 tcp_clean_rtx_queue() 中返回的 flag 并没有置 FLAG_DATA_ACKED 或 FLAG_SYN_ACKED
// 所以 tcp_ack_is_dubious() 返回 true,进入该分支
if (tcp_ack_is_dubious(sk, flag)) {
if (!(flag & (FLAG_SND_UNA_ADVANCED | FLAG_NOT_DUP |
FLAG_DSACKING_ACK))) {
num_dupack = 1;
/* Consider if pure acks were aggregated in tcp_add_backlog() */
if (!(flag & FLAG_DATA))
num_dupack = max_t(u16, 1,
skb_shinfo(skb)->gso_segs);
}
// tcp_fastretrans_alert()
// 调用
// tcp_time_to_recover()
// 调用
// tcp_dupack_heuristics()
// 函数 tcp_dupack_heuristics() 中会对 tp->sacked_out 加 1
// 如果这个条件成立的话 tcp_dupack_heuristics(tp) > tp->reordering
// 便会给 rexmit 赋值 *rexmit = REXMIT_LOST;
tcp_fastretrans_alert(sk, prior_snd_una, num_dupack, &flag,
&rexmit);
}
// 上边代码 tcp_fastretrans_alert() 返回的时候会给 rexmit 赋值,*rexmit = REXMIT_LOST;
// 进而导致在函数 tcp_xmit_recovery() 发生重传
tcp_xmit_recovery(sk, rexmit);
return 1;
}
// 在代码中使用的 tp->reordering,该成员初始化先关的函数如下
/* After receiving this amount of duplicate ACKs fast retransmit starts. */
#define TCP_FASTRETRANS_THRESH 3
static int __net_init tcp_sk_init(struct net *net)
{
net->ipv4.sysctl_tcp_reordering = TCP_FASTRETRANS_THRESH;
}
void tcp_init_sock(struct sock *sk)
{
tp->reordering = sock_net(sk)->ipv4.sysctl_tcp_reordering;
}