http协议
一.相关概念
互联网:是网络的网络,是所有类型网络的母集。
因特网:世界上最大的互联网网络。即因特网概念从属于互联网概念。习惯上,大家把连接在因特网上的计算机都成为主机。
万维网:WWW(world wide web)万维网并非某种特殊的计算机网络,是一个大规模的、联机式的信息贮藏库,使用链接的方法能非常方便地从因特网上的一个站点访问另一个站点(超链技术),具有提供分布式服务的特点。万维网是一个分布式的超媒体系统,是超文本系统的扩充,基于B/S架构实现。
URL:万维网使用统一资源定位符(Uniform Resource Locator)来标志万维网上的各种文档,并使每个文档在整个因特网的范围内具有唯一的标识符URL。
HTTP:为解决"用什么样的网络协议来实现整个因特网上的万维网文档”这一难题,就要使万维网客户程序(以浏览器为主,但不限于浏览器)与万维网服务器程序之间的交互遵守严格的协议,即超文本传送协议(HyperText Transfer Protocol)。HTTP是处于应用层的协议,使用TCP传输层协议进行可靠的传送。因此,需要特别提醒的是,万维网是基于因特网的一种广泛因特网应用系统,且万维网采用的是HTTP(80/TCP)和 HTTPS(443/TCP)的传输协议,但因特网还有其他的网络应用系统(如:FTP、SMTP等等)。
HTML:为了解决"怎样使不同作者创作的不同风格的万维网文档,都能在因特网上的各种主机上显示出来,同时使用户清楚地知道在什么地方存在着链接”这一问题,万维网使用超文本标记语言(HyperText Markup Language),使得万维网页面的设计者可以很方便地用链接从页面的某处链接到因特网的任何一个万维网页面,并且能够在自己的主机品目上将这些页面显示出来。HTML与txt一样,仅仅是是一种文档,不同之处在于,这种文档专供于浏览器上为浏览器用户提供统一的界面呈现的统一规约。且具备结构化的特征,这是txt所不具备的强制规定。
二.访问浏览器的过程


三.http 协议通信过程
1.简单介绍
HTTP(HyperText Transfer Protocol,超文本传输协议)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础设计HTTP最初的目的是为了提供一种远距离共享知识的方式,借助多文档进行关联实现超文本,连成相互参阅的WWW(world wide web,万维网)
HTTP的发展是由蒂姆·伯纳斯-李(Tim Berners-Lee)于1989年在欧洲核子研究组织(CERN)所发起。HTTP的标准制定由万维网协会(World Wide Web Consortium,W3C)和互联网工程任务组(Internet Engineering Task Force,IETF)进行协调,最终发布了一系列的RFC,其中最著名的是1999年6月公布的 RFC 2616,定义了HTTP协议中现今广泛使用的一个版本——HTTP 1.1版

四.http 相关技术
1.web 开发语言
http: Hyper Text Transfer Protocol 应用层协议,默认端口: 80/tcp
WEB前端开发语言:
-
html
-
css
-
javascript
html
Hyper Text Markup Language 超文本标记语言,编程语言,主要负责实现页面的结构
看:html 语言
HTML语言

欢迎
百度欢迎你
#注意:html文件编码为utf-8编码CSS
Cascading Style Sheet 层叠样式表, 定义了如何显示(装扮) HTML 元素,比如:字体大小和颜色属性等。样式通常保存在外部的 .css 文件中,用于存放一些HTML文件的公共属性,从而通过仅编辑一个简单的 CSS 文档,可以同时改变站点中所有页面的布局和外观。
品:css
#test.html 建议用Vscode创建文件,用记事本可能会出现乱码
这是 heading 1
这是一段普通的段落。请注意,该段落的文本是红色的。在 body 选择器中定义了本页面中的默认文本颜
色。
该段落定义了 class="ex"。该段落中的文本是蓝色的。
#mystyle.css
body {color:red}
h1 {color:#00ff00}
p.ex {color:rgb(0,0,255)}js
javascript,实现网页的动画效果,但实属于静态资源。
玩:JavaScript
我的第一个 JavaScript
2.MIME
MIME : Multipurpose Internet Mail Extensions 多用途互联网邮件扩展
MIME 类型通常仅包含两个部分:类型(type)和子类型(subtype),中间由斜杠 / 分割,中间没有空白字符:
类型 代表数据类型所属的大致分类,例如 video 或 text
子类型 标识了 MIME 类型所代表的指定类型的确切数据类型。以 text 类型为例,它的子类型包括:plain(纯文本)、html(HTML 源代码)、calender(iCalendar/.ics 文件)
格式: type/subtype
文件 /etc/mime.types ,来自于mailcap包


示例:
text/plain #文本文件的默认值
text/html #所有的 HTML 内容都应该使用这种类型
text/css #在网页中要被解析为 CSS 的任何 CSS 文件必须指定 MIME 为 text/css
image/jpeg jpg jpeg #图片类型
image/png #音频与视频类型
video/mp4
application/javascript3. URI
URI: Uniform Resource Identifier 统一资源标识,分为 URL 和 URN
-
URN:Uniform Resource Naming,统一资源命名,只是描述了资源的名字,并没有明确该资源在哪里
-
URL:Uniform Resorce Locator,统一资源定位符,用于描述某服务器某特定资源位置
两者区别:
-
URN 如同一个人的名称,而 URL 代表一个人的住址。换言之,URN 定义某事物的身份,而URL 提供查找该事物的方法。URN 仅用于命名,而不指定地 URL 组成。

解读:
scheme:方案,访问服务器以获取资源时要使用哪种协议
user:用户,某些方案访问资源时需要的用户名
password:密码,用户对应的密码,中间用:分隔
host:主机,资源宿主服务器的主机名或IP地址
port:端口,资源宿主服务器正在监听的端口号,很多方案有默认端口号
path:路径,服务器资源的本地名,由一个/将其与前面的URL组件分隔
params:参数,指定输入的参数,参数为名/值对,多个参数,用;分隔
query:查询,传递参数给程序,如数据库,用?分隔,多个查询用&分隔
frag:片段,一小片或一部分资源的名字,此组件在客户端使用,用#分隔
URL 示例

4.网站访问量
网站访问量统计的重要指标
-
IP(独立IP):即Internet Protocol,指独立IP数。一天内来自相同客户机IP 地址只计算一次,记录远程客户机IP地址的计算机访问网站的次数,是衡量网站流量的重要指标
-
PV(访问量): 即Page View, 页面浏览量或点击量,用户每次刷新即被计算一次,PV反映的是浏览某网站的页面数,PV与来访者的数量成正比,PV并不是页面的来访者数量,而是网站被访问的页面数量
-
UV(独立访客):即Unique Visitor,访问网站的一台电脑为一个访客。一天内相同的客户端只被计算一次。可以理解成访问某网站的电脑的数量。网站判断来访电脑的身份是通过cookies实现的。如果更换了IP后但不清除cookies,再访问相同网站,该网站的统计中UV数是不变的
5.http 工作机制
5.1 一次http事务包括:
-
http请求:http request
-
http响应:http response
5.2 Web资源:
web resource, 一个网页由多个资源(文件)构成,打开一个页面,通常会有多个资源展示出来,但是每个资源都要单独请求。因此,一个"Web 页面”通常并不是单个资源,而是一组资源的集合。
5.3 资源类型:
① 静态文件
无需服务端做出额外处理,服务器端和客户端的文件内容相同
常见文件后缀:.html, .txt, .jpg, .js, .css, .mp3, .avi
② 动态文件
服务端执行程序,返回执行的结果,服务器端和客户端的文件内容不相同
常见文件后缀:.php, .jsp ,.asp
5.4 http 连接请求
串行和并行连接

串行、持久连接和管道

提高HTTP连接性能
-
并行连接:通过多条TCP连接发起并发的HTTP请求
-
持久连接:keep-alive,重用TCP连接,以消除连接和关闭的时延,以事务个数和时间来决定是否关闭连接
-
管道化连接:通过共享TCP连接,发起并发的HTTP请求
-
复用的连接:交替传送请求和响应报文(实验阶段)
5.5 http 协议版本

http/0.9
1991,原型版本,功能简陋,只有一个命令GET。GET /index.html ,服务器只能回应HTML格式字符串,不能回应别的格式
http/1.0
1996年5月,支持cache, MIME, method
每个TCP连接只能发送一个请求,发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接引入了POST命令和HEAD命令头信息是 ASCII 码,后面数据可为任何格式。服务器回应时会告诉客户端,数据是什么格式,即Content-Type字段的作用。这些数据类型总称为MIME 多用途互联网邮件扩展,每个值包括一级类型和二级类型,预定义的类型,也可自定义类型, 常见Content-Type值:text/xml image/jpeg audio/mp3
http/1.1
1997年1月,引入了持久连接(persistent connection),即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive。对于同一个域名,大多数浏览器允许同时建立6个持久连接引入了管道机制,即在同一个TCP连接里,客户端可以同时发送多个请求,进一步改进了HTTP协议的效率新增方法:PUT、PATCH、OPTIONS、DELETE同一个TCP连接里,所有的数据通信是按次序进行的。服务器只能顺序处理回应,前面的回应慢,会有许多请求排队,造成"队头堵塞"(Head-of-line blocking)为避免上述问题,两种方法:一是减少请求数,二是同时多开持久连接。网页优化技巧,如合并脚本和样式表、将图片嵌入CSS代码、域名分片(domain sharding)等HTTP 协议不带有状态,每次请求都必须附上所有信息。请求的很多字段都是重复的,浪费带宽,影响速度
三个区别
0.9 只有get 只有下载 没有上传(put)
1.0 没有长连接 可以下载和上传
1.1 支持长连接 可以下载和上传
HTTP1.0和HTTP1.1的区别
-
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-NoneMatch等更多可供选择的缓存头来控制缓存策略
-
带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如:客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),方便了开发者自由的选择以便于充分利用带宽和连接
-
错误通知的管理,在HTTP1.1中新增24个状态响应码,如409(Conflict)表示请求的资源与资源当前状态冲突;410(Gone)表示服务器上的某个资源被永久性的删除
-
Host 头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)
-
长连接,HTTP 1.1支持持久连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,弥补了HTTP1.0每次请求都要创建连接的缺点
HTTP1.0和1.1的问题
-
HTTP1.x在传输数据时,每次都需要重新建立连接,无疑增加了大量的延迟时间,特别是在移动端更为突出
-
HTTP1.x在传输数据时,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份,无法保证数据的安全性
-
HTTP1.x在使用时,header里携带的内容过大,增加了传输的成本,并且每次请求header基本不怎么变化,尤其在移动端增加用户流量
-
虽然HTTP1.x支持了keep-alive,来弥补多次创建连接产生的延迟,但是keep-alive使用多了同样会给服务端带来大量的性能压力,并且对于单个文件被不断请求的服务(例如图片存放网站),keepalive可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间
HTTPS协议:
为解决安全问题,网景在1994年创建了HTTPS,并应用在网景导航者浏览器中。 最初,HTTP是与SSL一起使用的;在SSL逐渐演变到TLS时(其实两个是一个东西,只是名字不同而已),最新的HTTPS也由在2000年五月公布的RFC 2818正式确定下来。HTTPS就是安全版的HTTP,目前大型网站基本实现全站HTTPS。
HTTPS特点:
-
HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费
-
HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的
-
HTTP和HTTPS使用的是不同的连接方式,端口不同,前者是80,后者是443
-
HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题
-
HTTPS 实现过程降低用户访问速度,但经过合理优化和部署,HTTPS 对速度的影响还是可以接受的
HTTP2 协议
http/2.0:2015年,HTTP2.0是SPDY的升级版
-
头信息和数据体都是二进制,称为头信息帧和数据帧
-
复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,且不用按顺序一一对应,避免了"队头堵塞",此双向的实时通信称为多工(Multiplexing)
-
引入头信息压缩机制(header compression),头信息使用gzip或compress压缩后再发送;客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,不发送同样字段,只发送索引号,提高速度
-
HTTP/2 允许服务器未经请求,主动向客户端发送资源,即服务器推送(server push)
5.6 http 请求访问的完整过程
-
建立连接
-
接收请求
-
处理请求
-
访问资源
-
构建响应报文
-
发送响应报文
-
记录日志
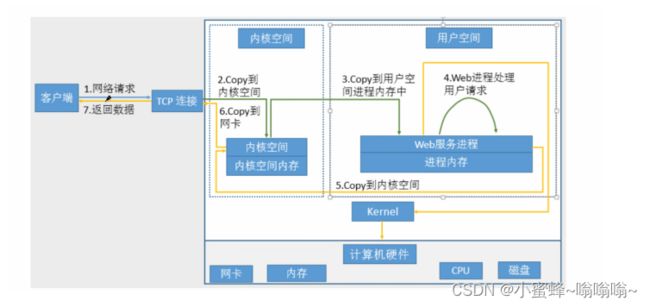
解释:
1 内核收到请求,会根据报文中的端口号信息,找到处理该请求的进程 你要找的端口号是80
2 会将请求转交给80端口上的进程(nginx) nginx进程会根据请求对照配置文件进行处理
3 nginx 进程分析完要去找资源,由于他是进程,他没有资格直接使用磁盘上的资源,所以需要内核协助获取资源(a.jpg)
4 内核去磁盘上找资源,找到以后再给 nginx 进程
5 nginx 进程拿到资源后会构建响应报文,构建完成后,再发给内核
6 内核给网卡,再把响应报文发给客户机
一次完整的 http 请求处理过程
1.建立连接
接收或拒绝连接请求
2.接受请求
接收客户端请求报文中对某资源的一次请求的过程
Web访问响应模型(Web I/O)

-
单进程I/O模型:启动一个进程处理用户请求,而且一次只处理一个,多个请求被串行响应
-
多进程I/O模型:并行启动多个进程,每个进程响应一个连接请求
-
复用I/O结构:启动一个进程,同时响应N个连接请求
-
复用的多进程I/O模型:启动M个进程,每个进程响应N个连接请求,同时接收 M*N 个请求
I/O 模型相关概念
同步/异步(消息反馈机制):关注的是消息通信机制,即调用者在等待一件事情的处理结果时,被调用者是否提供完成状态的通知。
-
同步:synchronous,被调用者并不提供事件的处理结果相关的通知消息,需要调用者主动询问事情是否处理完成
-
异步:asynchronous,被调用者通过状态、通知或回调机制主动通知调用者被调用者的运行状态

阻塞/非阻塞:关注调用者在等待结果返回之前所处的状态
-
阻塞:blocking,指IO操作需要彻底完成后才返回到用户空间,调用结果返回之前,调用者被挂起,干不了别的事情。
-
非阻塞:nonblocking,指IO操作被调用后立即返回给用户一个状态值,而无需等到IO操作彻底完成,在最终的调用结果返回之前,调用者不会被挂起,可以去做别的事情。
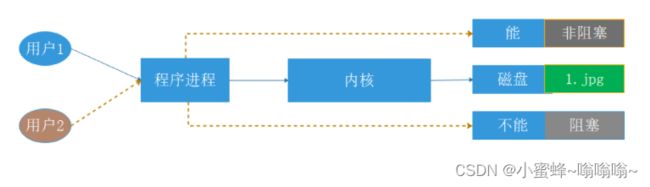

所以采用 异步非阻塞 和多路复用 一个意思
3.处理请求
服务器对请求报文进行解析,并获取请求的资源及请求方法等相关信息,根据方法,资源,首部和可选的主体部分对请求进行处理
常用请求Method: GET、POST、HEAD、PUT、DELETE、TRACE、OPTIONS
4.访问资源
服务器获取请求报文中请求的资源web服务器,即存放了web资源的服务器,负责向请求者提供对方请求的静态资源,或动态运行后生成的资源
5.构建响应报文
一旦Web服务器识别除了资源,就执行请求方法中描述的动作,并返回响应报文。响应报文中包含有响应状态码、响应首部,如果生成了响应主体的话,还包括响应主体
1)响应实体:如果事务处理产生了响应主体,就将内容放在响应报文中回送过去。响应报文中通常包括:
描述了响应主体MIME类型的Content-Type首部
描述了响应主体长度的Content-Length
实际报文的主体内容
2)URL重定向:web服务构建的响应并非客户端请求的资源,而是资源另外一个访问路径
3)MIME类型: Web服务器要负责确定响应主体的MIME类型。多种配置服务器的方法可将MIME类型与资源管理起来
-
魔法分类:Apache web服务器可以扫描每个资源的内容,并将其与一个已知模式表(被称为魔法文件)进行匹配,以决定每个文件的MIME类型。这样做可能比较慢,但很方便,尤其是文件没有标准扩展名时
-
显式分类:可以对Web服务器进行配置,使其不考虑文件的扩展名或内容,强制特定文件或目录内容拥有某个MIME类型
-
类型协商: 有些Web服务器经过配置,可以以多种文档格式来存储资源。在这种情况下,可以配置Web服务器,使其可以通过与用户的协商来决定使用哪种格式(及相关的MIME类型)"最好"
6. 发送响应报文
Web服务器通过连接发送数据时也会面临与接收数据一样的问题。服务器可能有很多条到各个客户端的连接,有些是空闲的,有些在向服务器发送数据,还有一些在向客户端回送响应数据。服务器要记录连接的状态,还要特别注意对持久连接的处理。对非持久连接而言,服务器应该在发送了整条报文之后,关闭自己这一端的连接。对持久连接来说,连接可能仍保持打开状态,在这种情况下,服务器要正确地计算Content-Length首部,不然客户端就无法知道响应什么时候结束。
7.记录日志
最后,当事务结束时,Web服务器会在日志文件中添加一个条目,来描述已执行的事务
5.7 http 协议及报文头部结构
5.7.1 http 请求报文
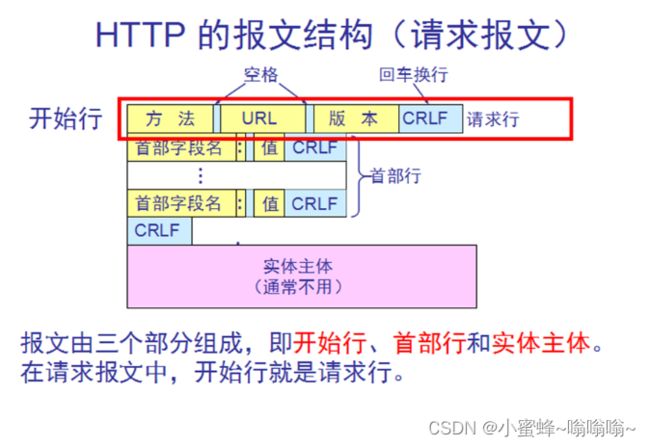
方法:
| GET | 获取资源当前网络请求中,绝大部分使用的是 GET 方法 |
| HEAD | 获取报文首部,主要用于确认 URL 的有效性以及资源更新的日期时间 |
| POST | 传输实体主体 (比如传输 用户名密码) |
| PUT | 上传文件(比如写博客) |
| PATCH | 对资源进行部分修改 |
| DELETE | 删除文件 |
| OPTIONS | 查询支持的方法(查看服务端可以支持哪些方法) |
| CONNECT | 要求在与代理服务器通信时建立隧道(类似加密) |
| TRACE | 追踪路径 |
url 指明资源的位置
-
scheme
-
http 超文本传输协议
-
https 安全的http协议
-
ftp 文件传输协议
-
-
user:帐号
-
password:密码
-
host:主机名 或 域名 或 ip地址
-
port: 服务器端口号
-
path:访问资源的路径,相当于组件路径
-
params:参数,但是这个不常用,指定一些参数,譬如指定传输方式
-
qurey:查询参数
-
frag:html资源片段,譬如html文档过大的时候,frag定位到html的一部分
首部字段:
使用首部字段是为了给浏览器和服务器提供报文主体大小、所使用的语言、认证信息等内容,HTTP 首部字段是由首部字段名和字段值构成的,中间用冒号“:” 分隔。
首部的分类:
-
通用首部:请求报文和响应报文两方都会使用的首部
-
Date: 报文的创建时间
-
Connection:连接状态,如keep-alive, close
-
Via:显示报文经过的中间节点(代理,网关)
-
Cache-Control:控制缓存,如缓存时长
-
MIME-Version:发送端使用的MIME版本
-
Warning:错误通知
-
-
请求首部:从客户端向服务器端发送请求报文时使用的首部。补充了请求的附加内容、客户端信息、请求内容相关优先级等信息
-
Accept:通知服务器自己可接受的媒体类型
-
Accept-Charset: 客户端可接受的字符集
-
Accept-Encoding:客户端可接受编码格式,如gzip
-
Accept-Language:客户端可接受的语言
-
Client-IP: 请求的客户端IP
-
Host: 请求的服务器名称和端口号
-
Referer:跳转至当前URI的前一个URL
-
User-Agent:客户端代理,浏览器版本
-
Expect:允许客户端列出某请求所要求的服务器行为(条件式请求首部)
-
If-Modified-Since:自从指定的时间之后,请求的资源是否发生过修改(条件式请求首部)
-
If-Unmodified-Since:与上面相反(条件式请求首部)
-
If-None-Match:本地缓存中存储的文档的ETag标签是否与服务器文档的Etag不匹配(条件式请求首部)
-
If-Match:与上面相反 (条件式请求首部)
-
Authorization:向服务器发送认证信息,如账号和密码(安全请求首部)
-
Cookie: 客户端向服务器发送cookie
-
Proxy-Authorization: 向代理服务器认证 ( 代理请求首部)
-
-
响应首部:从服务器端向客户端返回响应报文时使用的首部。补充了响应的附加内容,也会要求客户端附加额外的内容信息
-
协商首部:某资源有多种表示方法时使用
-
Accept-Ranges:服务器可接受的请求范围类型
-
Vary:服务器查看的其它首部列表
-
-
安全响应首部:
-
Set-Cookie:向客户端设置cookie
-
WWW-Authenticate:来自服务器对客户端的质询列表
-
-
信息性:
-
Age:从最初创建开始,响应持续时长
-
Server:服务器程序软件名称和版本
-
-
-
实体首部:针对请求报文和响应报文的实体部分使用的首部。补充了资源内容更新时间等与实体有关的的信息
-
缓存相关:
-
ETag:实体的扩展标签
-
Expires:实体的过期时间
-
Last-Modified:最后一次修改的时间
-
-
Allow: 列出对此资源实体可使用的请求方法
-
Location:告诉客户端真正的实体位于何处
-
Content-Encoding:对主体执行的编码
-
Content-Language:理解主体时最适合的语言
-
Content-Location: 实体真正所处位置
-
Content-Type:主体的对象类型,如text
-
-
扩展首部
实体:
请求时附加的数据或响应时附加的数据,例如:登录网站时的用户名和密码,博客的上传文章,论坛上的发言等。
request 报文格式
5.7.2 响应报文

response 报文格式
5.8 状态码
http 协议状态码分类:
1xx:100-101 信息提示
2xx:200-206 成功
3xx:300-307 重定向
4xx:400-415 错误类信息,客户端错误
5xx:500-505 错误类信息,服务器端错误
http 协议常用的状态码:
200: 成功,请求数据通过响应报文的entity-body部分发送;OK
301: 请求的 URL 指向的资源已经被删除;但在响应报文中通过首部 Location 指明了资源现在所处的新位置;Moved Permanently
302: 响应报文 Location 指明资源临时新位置 Moved Temporarily
304: 客户端发出了条件式请求,但服务器上的资源未曾发生改变,则通过响应此响应状态码通知客户端;Not Modified
307: 浏览器内部重定向
401: 需要输入账号和密码认证方能访问资源;Unauthorized
403: 请求被禁止;Forbidden
404: 服务器无法找到客户端请求的资源;Not Found
500: 服务器内部错误;Internal Server Error,比如:cgi程序没有执行权限
502: 代理服务器从后端服务器收到了一条伪响应,如无法连接到网关;Bad Gateway
503: 服务不可用,临时服务器维护或过载,服务器无法处理请求,比如:php服务停止,无法处理php程序
504: 网关超时
5.9 扩展网络通信,两台主机之间通信


五.httpd 安装组成
1.常见的 http 服务器程序
-
httpd apache,存在C10K(10K connections)问题
-
nginx 解决C10K问题lighttpd
-
tomcat .jsp 应用程序服务器
-
IIS .asp 应用程序服务器
-
jetty 开源的servlet容器,基于Java的web容器
-
Resin CAUCHO公司,支持servlets和jsp的引擎
-
webshpere:IBM公司
-
weblogic:BEA,Oracle
-
jboss:RedHat,IBM
-
oc4j:Oracle
2. apache 介绍和特点

20世纪90年代初,美国国家超级计算机应用中心NCSA开发,1995年开源社区发布 apache
软件基金会
-
ASF:apache software foundation
-
FSF:Free Software Foundation
apache 功能:
-
提供http协议服务
-
多个虚拟主机:IP、Port、FQDN
-
CGI:Common Gateway Interface,通用网关接口,支持动态程序 类似于协议
-
反向代理
-
负载均衡
-
路径别名
-
丰富的用户认证机制:basic,digest
-
支持第三方模块
apache特性:
-
高度模块化:core + modules
-
DSO:Dynamic Shared Object 动态加载/卸载
-
MPM:multi-processing module 多路处理模块
总结:apache 功能多,稳定,善于处理静态资源
HTTP 和 Apache 之间的关系是:HTTP定义了客户端和服务器之间的通信规则,而 Apache 是一种能够处理这些 HTTP 请求并提供网页内容的 Web 服务器软件。
3. MPM multi-processing module 工作模式
prefork
prefork : 多进程I/O模型,每个进程响应一个请求,CentOS 7 httpd默认模型一个主进程:生成和回收n个子进程,创建套接字,不响应请求多个子进程:工作 work进程,每个子进程处理一个请求;系统初始时,预先生成多个空闲进程,等待请求.

Prefork MPM预派生模式,有一个主控制进程,然后生成多个子进程,每个子进程有一个独立的线程响应用户请求,相对比较占用内存,但是比较稳定,可以设置最大和最小进程数,是最古老的一种模式,也是最稳定的模式,适用于访问量不是很大的场景
优点:稳定
缺点:慢,占用资源,不适用于高并发场景
yum 安装默认 prefork
worker
worker : 复用的多进程I/O模型,多进程多线程,IIS使用此模型
一个主进程:生成m个子进程,每个子进程负责生个n个线程,每个线程响应一个请求,并发响应请求:m*n
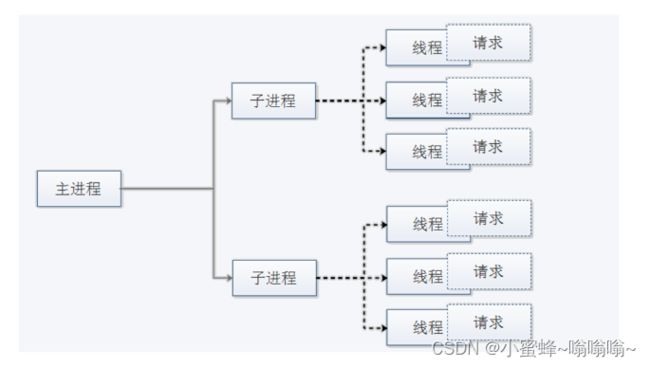
worker MPM 是一种多进程和多线程混合的模型,有一个控制进程,启动多个子进程,每个子进程里面包含固定的线程,使用线程程来处理请求,当线程不够使用的时候会再启动一个新的子进程,然后在进程里面再启动线程处理请求,由于其使用了线程处理请求,因此可以承受更高的并发。
优点:相比prefork 占用的内存较少,可以同时处理更多的请求
缺点:使用keep-alive的长连接方式,某个线程会一直被占据,即使没有传输数据,也需要一直等待到超时才会被释放。如果过多的线程,被这样占据,也会导致在高并发场景下的无服务线程可用。(该问题在prefork模式下,同样会发生)
event
event:事件驱动模型(worker模型的变种),CentOS8 默认模型
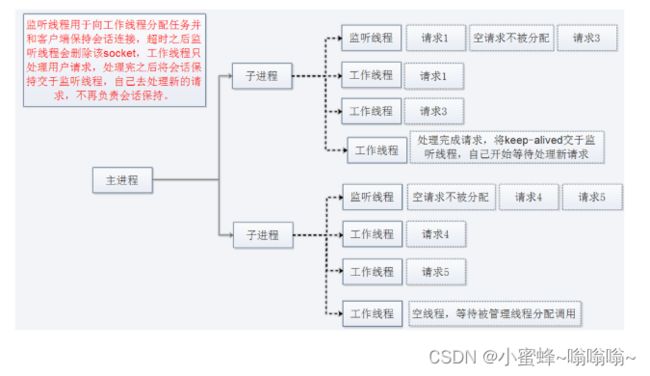 一个主进程:生成m个子进程,每个子进程负责生个n个线程,每个线程响应一个请求,并发响应请求:m*n,有专门的监控线程来管理这些keep-alive类型的线程,当有真实请求时,将请求传递给服务线程,执行完毕后,又允许释放。这样增强了高并发场景下的请求处理能力。
一个主进程:生成m个子进程,每个子进程负责生个n个线程,每个线程响应一个请求,并发响应请求:m*n,有专门的监控线程来管理这些keep-alive类型的线程,当有真实请求时,将请求传递给服务线程,执行完毕后,又允许释放。这样增强了高并发场景下的请求处理能力。
event MPM是Apache中最新的模式,2012年发布的apache 2.4.X系列正式支持event 模型. 属于事件驱动模型(epoll),每个进程响应多个请求,在现在版本里的已经是稳定可用的模式。它和worker模式很像,最大的区别在于,它解决了keep-alive场景下,长期被占用的线程的资源浪费问题(某些线程因为被keep-alive,空挂在哪里等待,中间几乎没有请求过来,甚至等到超时)。event MPM中,会有一个专门的线程来管理这些keep-alive类型的线程,当有真实请求过来的时候,将请求传递给服务线程,执行完毕后,又允许它释放。这样增强了高并发场景下的请求处理能力event只在有数据发送的时候才开始建立连接,连接请求才会触发工作线程,即使用了TCP的一个选项,叫做延迟接受连接TCP_DEFER_ACCEPT,加了这个选项后,若客户端只进行TCP连接,不发送请求,则不会触发Accept操作,也就不会触发工作线程去干活,进行了简单的防攻击(TCP连接)
优点:单线程响应多请求,占据更少的内存,高并发下表现更优秀,会有一个专门的线程来管理keep-alive类型的线程,当有真实请求过来的时候,将请求传递给服务线程,执行完毕后,又允许它释放
缺点:没有线程安全控制
修改 yum 安装的默认模式


4.httpd 相关的文件
配置文件:
-
/etc/httpd/conf/httpd.conf 主配置文件
-
/etc/httpd/conf.d/*.conf 子配置文件 (子配置文件优先级高)
-
/etc/httpd/conf.d/conf.modules.d/ 模块加载的配置文件
服务单元文件:
-
/usr/lib/systemd/system/httpd.service
站点网页文档根目录:/var/www/html

默认的是直接 index.html

但是如果在前面还有 相当于先看了 index.txt 没有才看 index.html
![]()

那么当去访问时候,如果直接是 192.168.44.20 看到的就是 index.txt 的页面,也就是192.168.44.20/index.txt
得 192.168.44.20/index.html 才能看到 index.html 页面

相当于是:
模块文件路径:
-
/etc/httpd/modules
-
/usr/lib64/httpd/modules
主服务器程序文件:/usr/sbin/httpd
httpd 命令:
检查配置语法:httpd -t

查看版本:httpd -v

5.httpd 常见的配置
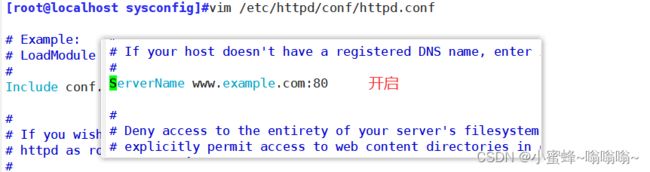
5.1 指定服务器名
[root@localhost sysconfig]#httpd -t
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using localhost.localdomain. Set the 'ServerName' directive globally to suppress this message
Syntax OK
[root@localhost sysconfig]#vim /etc/httpd/conf/httpd.conf
ServerName www.example.com:80
[root@localhost sysconfig]#httpd -t
Syntax OK

5.2 包含其它配置文件
Include file-path|directory-path|wildcard
IncludeOptional file-path|directory-path|wildcard
#
- Include和IncludeOptional功能相同,都可以包括其它配置文件
- 但是当无匹配文件时,include会报错,IncludeOptional会忽略错误include 子配置模块
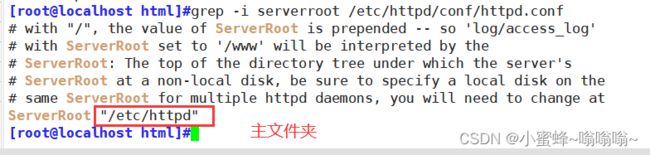
总目录:
 5.3 监听地址
5.3 监听地址
Listen [IP:]PORT
#
(1) 省略IP表示为本机所有IP
(2) Listen指令至少一个,可重复出现多次[root@localhost httpd]#grep -i listen /etc/httpd/conf/httpd.conf
# Listen: Allows you to bind Apache to specific IP addresses and/or
# Change this to Listen on specific IP addresses as shown below to
#Listen 12.34.56.78:80
#Listen 80 #监听本机所有的80端口
Listen 192.168.44.20:80
Listen 192.168.44.20:9527

也可以不写在主配置,写在子配置内
注意需要以 .conf 结尾 test.conf


没重启服务之前访问不了
![]()


5.4 隐藏服务器版本信息

进入编辑
servertokens prod
#语法
ServerTokens Major|Minor|Min[imal]|Prod[uctOnly]|OS|Full
#相关指令
ServerTokens Prod[uctOnly] :Server: Apache
ServerTokens Major: Server: Apache/2
ServerTokens Minor: Server: Apache/2.0
ServerTokens Min[imal]: Server: Apache/2.0.41
ServerTokens OS: Server: Apache/2.0.41 (Unix)
ServerTokens Full (or not specified): Server: Apache/2.0.41 (Unix) PHP/4.2.2 MyMod/1.2 此为默认值

效果:看不到版本号了

也可以在子配置文件添加
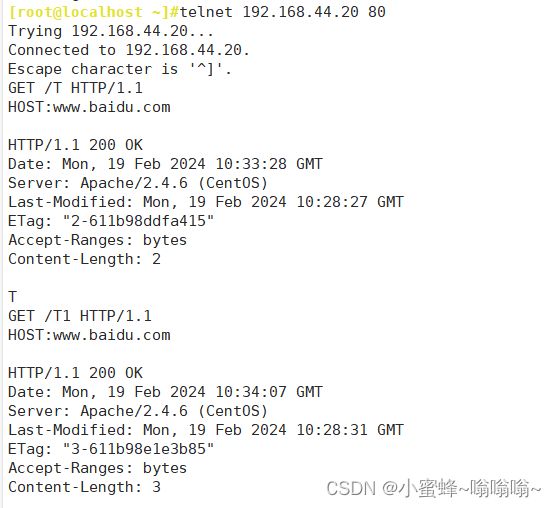
 5.5 持久连接
5.5 持久连接
Persistent Connection:连接建立,每个资源获取完成后不会断开连接,而是继续等待其它的请求完成,默认开启持久连接。
断开条件:
-
时间限制:以秒为单位, 默认5s,httpd-2.4 支持毫秒级
-
请求数量: 请求数达到指定值,也会断开
副作用:对并发访问量大的服务器,持久连接会使有些请求得不到响应
折衷:使用较短的持久连接时间
持久连接相关指令:
KeepAlive On|Off
KeepAliveTimeout 300 #连接持续300s,可以以ms为单位,默认值为5s
MaxKeepAliveRequests 2 #持久连接最大接收的请求数,默认值100
测试:

telnet 模拟长连接

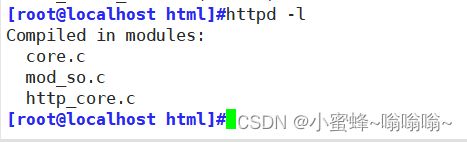
5.6 DSO (Dynamic Shared Object)
Dynamic Shared Object,加载动态模块配置,不需重启即生效动态模块所在路径:
查看静态编译的模块 :httpd -l
查看静态编译及动态装载的模块: httpd -M



5.7 MPM (Multi-Processing Module)多路处理模块
httpd 支持三种MPM工作模式:prefork, worker, event
只能使用一种,不能一起使用
 5.8 prefork 模式相关配置
5.8 prefork 模式相关配置
StartServers 100
MinSpareServers 50
MaxSpareServers 80
ServerLimit 2560 #最多进程数,最大值 20000
MaxRequestWorkers 2560 #最大的并发连接数,默认256
MaxConnectionsPerChild 4000 #子进程最多能处理的请求数量。在处理MaxRequestsPerChild 个
请求之后,子进程将会被父进程终止,这时候子进程占用的内存就会释放(为0时永远不释放)
MaxRequestsPerChild 4000 #从 httpd.2.3.9开始被MaxConnectionsPerChild代替5.9 worker 和 event 模式相关的配置
ServerLimit 16 #最多worker进程数 Upper limit on configurable number of
processes
StartServers 10 #Number of child server processes created at startup
MaxRequestWorkers 150 #Maximum number of connections that will be processed
simultaneously
MinSpareThreads 25
MaxSpareThreads 75
ThreadsPerChild 25 #Number of threads created by each child process
修改之前是5个

修改之后变成10个

3.10 定义Main server的文档页面路径
DocumentRoot "/path”
Require all granted
说明:
DocumentRoot指向的路径为URL路径的起始位置
/path 必须显式授权后才可以访问
默认站点路径


并建好指定目录

并在 index.html 里面添加内容

测试:

此时的站点位置在

注意:一定要授权
别名alias


 3.11 定义站点默认主页面文件
3.11 定义站点默认主页面文件
DirectoryIndex index.txt index.html
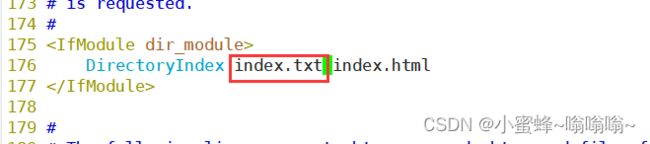
谁在前面就默认访问谁的,这里是 index.txt 的
针对目录和URL实现访问控制
Options 指令
后跟1个或多个以空白字符分隔的选项列表,在选项前的+,-表示增加或删除指定选项
常见选项:



FollowSymLinks 允许访问符号链接文件所指向的源文件



下载的:
3.12 虚拟主机
httpd 支持在一台物理主机上实现多个网站,即多虚拟主机
网站的唯一标识:
-
IP相同,但端口不同
-
IP不同,但端口均为默认端口
-
FQDN不同, IP和端口都相同
多虚拟主机有三种实现方案:
-
基于ip:为每个虚拟主机准备至少一个ip地址
-
基于port:为每个虚拟主机使用至少一个独立的port
-
基于FQDN:为每个虚拟主机使用至少一个FQDN,请求报文中首部
理解:
基于ip地址
192.168.44.20 ---------> jd
192.168.44.100 ---------> taobao
基于端口
192.168.44.20:80 ---------> jd
192.168.44.100:80 --------> taobao
基于域名
www.lucky.com --------> lucky
www.cloud.com ---------> cloud
① 基于ip地址
AllowOverride None
# Allow open access:
Require all granted
options Indexes FollowSymLinks
ServerAdmin [email protected]
DocumentRoot "/opt/html/20"
ServerName www.accp.com
ErrorLog "logs/20_error_log"
CustomLog "logs/20_access_log" common
ServerAdmin [email protected]
DocumentRoot "/opt/html/100"
ServerName www.accp.com
ErrorLog "logs/100_error_log"
CustomLog "logs/100_access_log" common

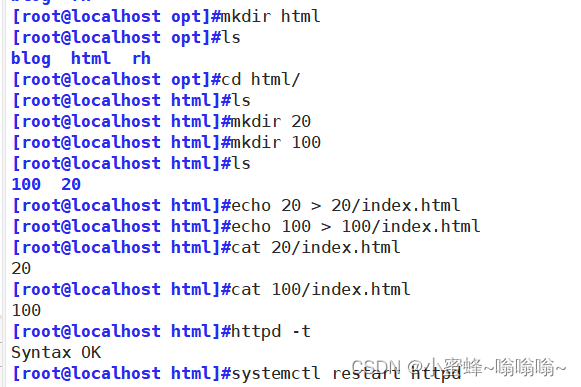
测试:

② 基于端口
AllowOverride None
# Allow open access:
Require all granted
options Indexes FollowSymLinks
ServerAdmin [email protected]
DocumentRoot "/opt/html/20"
ServerName www.accp.com
ServerAdmin [email protected]
DocumentRoot "/opt/html/100"
ServerName www.accp.com
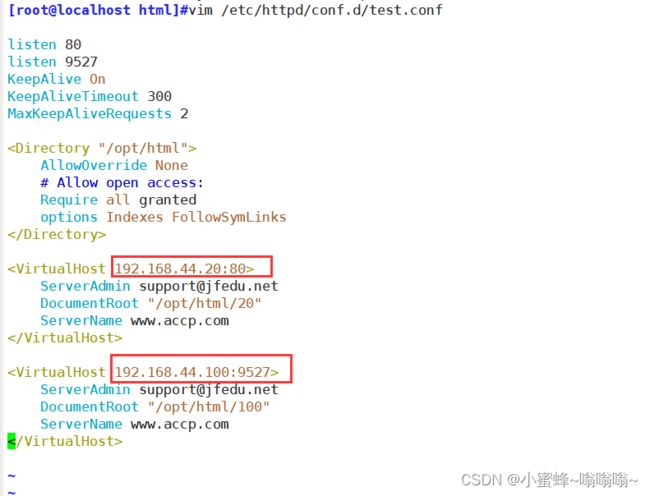
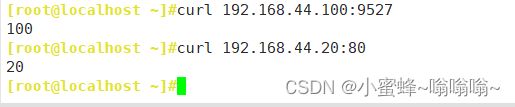
③ 基于域名
AllowOverride None
# Allow open access:
Require all granted
options Indexes FollowSymLinks
ServerAdmin [email protected]
DocumentRoot "/opt/html/20"
ServerName www.lucky.com
ServerAdmin [email protected]
DocumentRoot "/opt/html/100"
ServerName www.cloud.com

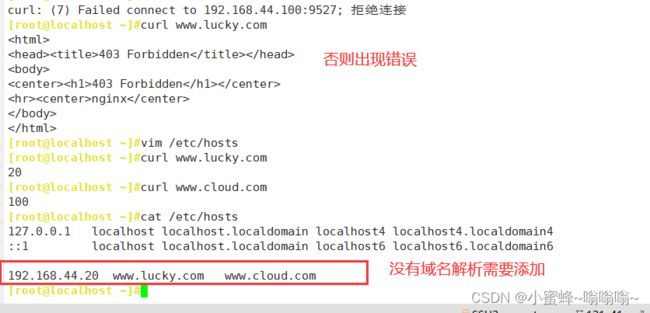 3.13 基于客户端 IP 地址实现访问控制
3.13 基于客户端 IP 地址实现访问控制
黑名单,不能有失效,至少有一个成功匹配才成功,即失败优先
Require all granted
Require not ip 172.16.1.1 #拒绝特定ip
白名单,多个语句有一个成功,则成功,即成功优先
Require all denied
Require ip 172.16.1.1 #允许特定IP
测试:
Require all granted #默认允许所有
Require not ip 192.168.44.1 #除了真机不可以访问
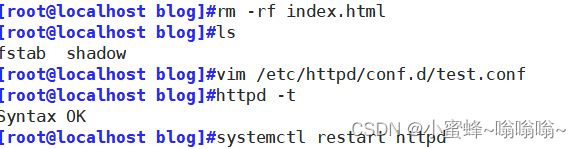
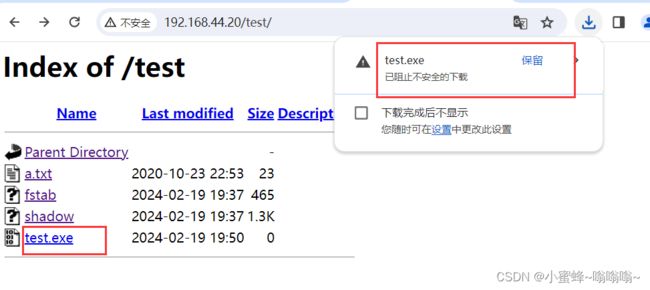
alias /test /mnt/html


正常可以访问:

真机不可以访问:

3.14 日志


六.Cookie和session
1.介绍
无状态协议是指协议对事物处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它应答就很快。
HTTP是超本文传输协议,顾名思义,这个协议支持超文本的传输。什么是超文本?说白了就是使用HTML编写的页面。通常,我们使用客户端浏览器访问服务器的资源,最常见的URL也是以 html为后缀的文件,因此可以说超文本是网络上最主要的资源。
既然HTTP协议的目的是在于支持超文本的传输,也就是资源的传输,那么客户端浏览器向HTTP服务器发送请求,继而HTTP服务器将相信资源发回给客户端这样一个过程中,无论对于客户端还是服务器,都没有必要记录这个过程,因为每一次请求和响应都是相对独立的,一般而言,一个URL对应着一个唯一的超文本,正是因为这样的唯一性,使得记录用户的行为状态变得毫无意义,所以,HTTP协议被设计为无状态的连接协议符合它本身的需求。
HTTP协议这种特性有优点也有缺点,优点在于解放了服务器,每一次请求"点到为止",不会造成不必要的连接占用,缺点在于如果为了保留状态,每次请求都会传输大量的重复信息内容。
可是随着 Web 的不断发展,很多业务都需要对通信状态进行保存.如果是一次性会话的过程: 打开浏览器 -> 访问一些服务器内容 -> 关闭浏览器但目前有很多WEB访问场景,并不是一次性会话,而是多次相关的会话,比如:
-
登录场景:
打开浏览器 -> 浏览到登陆页面 -> 输入用户名和密码 -> 访问到用户主页(显示用户名) -> 修改密码(输入原密码)-> 修改收货地址.......
问题:在此处登录会话过程中产生的数据(用户会话数据)如何保存下来呢?
-
购物场景:
打开浏览器 -> 浏览商品列表 -> 加入购物车(把商品信息保存下来) -> 关闭浏览器打开浏览器-> 直接进入购物车 -> 查看到上次加入购物车的商品 -> 下订单 -> 支付
问题: 在购物会话过程中,如何保存商品信息?
以上场景都需要保留会话数据,需要会话管理机制。
会话管理: 管理浏览器客户端和服务器端之间会话过程中产生的会话数据。
为了会话管理,HTTP就需要传输大量重复信息内容的问题,造成大量的网络带宽消耗。于是 Cookie 和 Session 技术闪亮登场了,它们可以为用户进行会话管理,实现保存状态。
2.Cookie
介绍
Cookie 又称为"小甜饼”。类型为"小型文本文件”,指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。由网景公司的前雇员卢·蒙特利在1993年3月发明
因为HTTP协议是无状态的,即服务器不知道用户上一次做了什么,这严重阻碍了交互式Web应用程序的实现。在典型的网上购物场景中,用户浏览了几个页面,买了一盒饼干和两瓶饮料。最后结帐时,由于HTTP的无状态性,不通过额外的手段,服务器并不知道用户到底买了什么,所以Cookie就是用来绕开HTTP的无状态性的"额外手段”之一。服务器可以设置或读取Cookies中包含信息,借此维护用户跟服务器会话中的状态。
在上面的购物场景中,当用户选购了第一项商品,服务器在向用户发送网页的同时,还发送了一段Cookie,记录着那项商品的信息。当用户访问另一个页面,浏览器会把Cookie发送给服务器,于是服务器知道他之前选购了什么。用户继续选购饮料,服务器就在原来那段Cookie里追加新的商品信息。结帐时,服务器读取发送来的Cookie就行了。
Cookie 基于 HTTP 协议,也叫 Web Cookie 或浏览器 Cookie,是服务器发送到用户浏览器并保存在客户端本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie 使基于无状态的HTTP协议记录稳定的状态信息成为了可能。

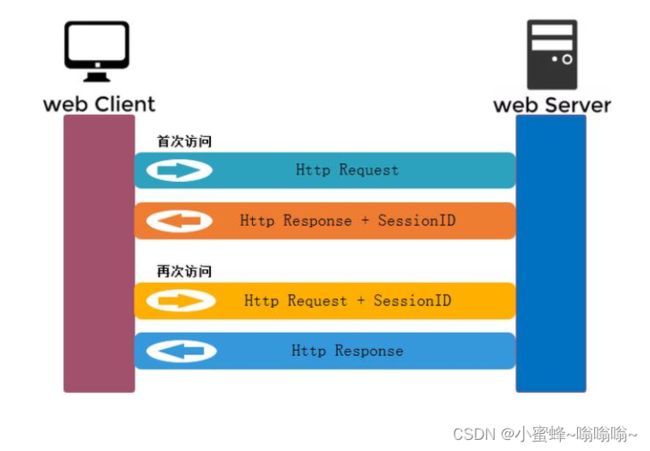
过程:
第一次请求过程
浏览器第一次发送请求时,不会携带任何cookie信息,
服务器接收到请求之后,发现请求中没有任何cookie信息,
服务器生成和设置一个 cookie.并将此 cookie 设置通过 set_cookie 的首部字段保存在响应报文中返回给浏览器,浏览器接收到这个响应报文之后,发现里面有 cookie 信息,浏览器会将 cookie 信息保存起来。
第二次及其之后的过程
当浏览器第二次及其之后的请求报文中自动 cookie 的首部字段携带第一次响应报文中获取的 cookie信息,
服务器再次接收到请求之后,会发现请求中携带的 cookie 信息,这样的话就认识是谁发的请求了
之后的响应报文中不会再添加 set_cookie 首部字段。
应用:
Cookie主要用于以下三个方面:
-
会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
-
个性化设置(如用户自定义设置、主题等)
-
浏览器行为跟踪(如跟踪分析用户行为等)
3.session
4.cookie和session的相同和不同

-
cookie 通常是在服务器生成,但也可以在客户端生成,session 是在服务器端生成的
-
session 将数据信息保存在服务器端,可以是内存,文件,数据库等多种形式,cookie 将数据保存在客户端的内存或文件中
-
单个 cookie 保存的数据不能超过4K,每个站点 cookie 个数有限制,比如 IE8为50个、Firefox为50个、Opera为30个;session 存储在服务器,没有容量限制
-
cookie 存放在用户本地,可以被轻松访问和修改,安全性不高;session 存储于服务器,比较安全
-
cookie 有会话cookie和持久cookie,生命周期为浏览器会话期的 会话cookie 保存在缓存,关闭浏览器窗口就消失,持久cookie 被保存在硬盘,知道超过设定的过期时间;随着服务端session 存储压力增大,会根据需要定期清理 session 数据
-
session 中有众多数据,只将 sessionID 这一项可以通过 cookie 发送至客户端进行保留,客户端下次访问时,在请求报文中的 cookie 会自动携带 sessionID,从而和服务器上的的 session进行关联
5.cookie 和 seeion 的缺点
cookie缺点:
1、使用 cookie 来传递信息,随着 cookie 个数的增多和访问量的增加,它占用的网络带宽也很大,试想假如 cookie 占用200字节,如果一天的PV有几个亿,那么它要占用多少带宽?
2、cookie 并不安全,因为 cookie 是存放在客户端的,所以这些 cookie 可以被访问到,设置可以通过插件添加、修改 cookie。所以从这个角度来说,我们要使用 sesssion,session 是将数据保存在服务端的,只是通过 cookie 传递一个 sessionId 而已,所以 session 更适合存储用户隐私和重要的数据。
session 缺点:
1、不容易在多台服务器之间共享,可以使用 session绑定,session复制,session共享解决
2、session 存放在服务器中,所以 session 如果太多会非常消耗服务器的性能 cookie 和 session各有优缺点,在大型互联网系统中,单独使用 cookie 和 session 都是不可行的。
七.web 相关工具
1.wget
非交互式的网络文件下载工具
格式:
wget [OPTION]... [URL]...常用选项:
| -q | 静默模式 |
| -c | 断点续传 |
| -P /path | 保存在指定目录 |
| -O filename | 保存为指定文件名, filename 为 - 时,发送至标准输出 |
| --limit-rate= | 指定传输速率,单位K,M等 |
示例:
[root@centos7 ~]#wget --limit-rate 1M -P /data https://mirrors.aliyun.com/centos/8/isos/x86_64/CentOS-8-x86_64-1905-dvd1.iso[root@localhost ~]#wget -h
GNU Wget 1.14,非交互式的网络文件下载工具。
用法: wget [选项]... [URL]...
长选项所必须的参数在使用短选项时也是必须的。
启动:
-V, --version 显示 Wget 的版本信息并退出。
-h, --help 打印此帮助。
-b, --background 启动后转入后台。
-e, --execute=COMMAND 运行一个“.wgetrc”风格的命令。
日志和输入文件:
-o, --output-file=FILE 将日志信息写入 FILE。
-a, --append-output=FILE 将信息添加至 FILE。
-d, --debug 打印大量调试信息。
-q, --quiet 安静模式 (无信息输出)。
-v, --verbose 详尽的输出 (此为默认值)。
-nv, --no-verbose 关闭详尽输出,但不进入安静模式。
--report-speed=TYPE Output bandwidth as TYPE. TYPE can be bits.
-i, --input-file=FILE 下载本地或外部 FILE 中的 URLs。
-F, --force-html 把输入文件当成 HTML 文件。
-B, --base=URL 解析与 URL 相关的
HTML 输入文件 (由 -i -F 选项指定)。
--config=FILE Specify config file to use.
下载:
-t, --tries=NUMBER 设置重试次数为 NUMBER (0 代表无限制)。
--retry-connrefused 即使拒绝连接也是重试。
-O, --output-document=FILE 将文档写入 FILE。
-nc, --no-clobber skip downloads that would download to
existing files (overwriting them).
-c, --continue 断点续传下载文件。
--progress=TYPE 选择进度条类型。
-N, --timestamping 只获取比本地文件新的文件。
--no-use-server-timestamps 不用服务器上的时间戳来设置本地文件。
-S, --server-response 打印服务器响应。
--spider 不下载任何文件。
-T, --timeout=SECONDS 将所有超时设为 SECONDS 秒。
--dns-timeout=SECS 设置 DNS 查寻超时为 SECS 秒。
--connect-timeout=SECS 设置连接超时为 SECS 秒。
--read-timeout=SECS 设置读取超时为 SECS 秒。
-w, --wait=SECONDS 等待间隔为 SECONDS 秒。
--waitretry=SECONDS 在获取文件的重试期间等待 1..SECONDS 秒。
--random-wait 获取多个文件时,每次随机等待间隔
0.5*WAIT...1.5*WAIT 秒。
--no-proxy 禁止使用代理。
-Q, --quota=NUMBER 设置获取配额为 NUMBER 字节。
--bind-address=ADDRESS 绑定至本地主机上的 ADDRESS (主机名或是 IP)。
--limit-rate=RATE 限制下载速率为 RATE。
--no-dns-cache 关闭 DNS 查寻缓存。
--restrict-file-names=OS 限定文件名中的字符为 OS 允许的字符。
--ignore-case 匹配文件/目录时忽略大小写。
-4, --inet4-only 仅连接至 IPv4 地址。
-6, --inet6-only 仅连接至 IPv6 地址。
--prefer-family=FAMILY 首先连接至指定协议的地址
FAMILY 为 IPv6,IPv4 或是 none。
--user=USER 将 ftp 和 http 的用户名均设置为 USER。
--password=PASS 将 ftp 和 http 的密码均设置为 PASS。
--ask-password 提示输入密码。
--no-iri 关闭 IRI 支持。
--local-encoding=ENC IRI (国际化资源标识符) 使用 ENC 作为本地编码。
--remote-encoding=ENC 使用 ENC 作为默认远程编码。
--unlink remove file before clobber.
目录:
-nd, --no-directories 不创建目录。
-x, --force-directories 强制创建目录。
-nH, --no-host-directories 不要创建主目录。
--protocol-directories 在目录中使用协议名称。
-P, --directory-prefix=PREFIX 以 PREFIX/... 保存文件
--cut-dirs=NUMBER 忽略远程目录中 NUMBER 个目录层。
HTTP 选项:
--http-user=USER 设置 http 用户名为 USER。
--http-password=PASS 设置 http 密码为 PASS。
--no-cache 不在服务器上缓存数据。
--default-page=NAME 改变默认页
(默认页通常是“index.html”)。
-E, --adjust-extension 以合适的扩展名保存 HTML/CSS 文档。
--ignore-length 忽略头部的‘Content-Length’区域。
--header=STRING 在头部插入 STRING。
--max-redirect 每页所允许的最大重定向。
--proxy-user=USER 使用 USER 作为代理用户名。
--proxy-password=PASS 使用 PASS 作为代理密码。
--referer=URL 在 HTTP 请求头包含‘Referer: URL’。
--save-headers 将 HTTP 头保存至文件。
-U, --user-agent=AGENT 标识为 AGENT 而不是 Wget/VERSION。
--no-http-keep-alive 禁用 HTTP keep-alive (永久连接)。
--no-cookies 不使用 cookies。
--load-cookies=FILE 会话开始前从 FILE 中载入 cookies。
--save-cookies=FILE 会话结束后保存 cookies 至 FILE。
--keep-session-cookies 载入并保存会话 (非永久) cookies。
--post-data=STRING 使用 POST 方式;把 STRING 作为数据发送。
--post-file=FILE 使用 POST 方式;发送 FILE 内容。
--content-disposition 当选中本地文件名时
允许 Content-Disposition 头部 (尚在实验)。
--content-on-error output the received content on server errors.
--auth-no-challenge 发送不含服务器询问的首次等待
的基本 HTTP 验证信息。
HTTPS (SSL/TLS) 选项:
--secure-protocol=PR choose secure protocol, one of auto, SSLv2,
SSLv3, TLSv1, TLSv1_1 and TLSv1_2.
--no-check-certificate 不要验证服务器的证书。
--certificate=FILE 客户端证书文件。
--certificate-type=TYPE 客户端证书类型,PEM 或 DER。
--private-key=FILE 私钥文件。
--private-key-type=TYPE 私钥文件类型,PEM 或 DER。
--ca-certificate=FILE 带有一组 CA 认证的文件。
--ca-directory=DIR 保存 CA 认证的哈希列表的目录。
--random-file=FILE 带有生成 SSL PRNG 的随机数据的文件。
--egd-file=FILE 用于命名带有随机数据的 EGD 套接字的文件。
FTP 选项:
--ftp-user=USER 设置 ftp 用户名为 USER。
--ftp-password=PASS 设置 ftp 密码为 PASS。
--no-remove-listing 不要删除‘.listing’文件。
--no-glob 不在 FTP 文件名中使用通配符展开。
--no-passive-ftp 禁用“passive”传输模式。
--preserve-permissions 保留远程文件的权限。
--retr-symlinks 递归目录时,获取链接的文件 (而非目录)。
WARC options:
--warc-file=FILENAME save request/response data to a .warc.gz file.
--warc-header=STRING insert STRING into the warcinfo record.
--warc-max-size=NUMBER set maximum size of WARC files to NUMBER.
--warc-cdx write CDX index files.
--warc-dedup=FILENAME do not store records listed in this CDX file.
--no-warc-compression do not compress WARC files with GZIP.
--no-warc-digests do not calculate SHA1 digests.
--no-warc-keep-log do not store the log file in a WARC record.
--warc-tempdir=DIRECTORY location for temporary files created by the
WARC writer.
递归下载:
-r, --recursive 指定递归下载。
-l, --level=NUMBER 最大递归深度 (inf 或 0 代表无限制,即全部下载)。
--delete-after 下载完成后删除本地文件。
-k, --convert-links 让下载得到的 HTML 或 CSS 中的链接指向本地文件。
--backups=N before writing file X, rotate up to N backup files.
-K, --backup-converted 在转换文件 X 前先将它备份为 X.orig。
-m, --mirror -N -r -l inf --no-remove-listing 的缩写形式。
-p, --page-requisites 下载所有用于显示 HTML 页面的图片之类的元素。
--strict-comments 用严格方式 (SGML) 处理 HTML 注释。
递归接受/拒绝:
-A, --accept=LIST 逗号分隔的可接受的扩展名列表。
-R, --reject=LIST 逗号分隔的要拒绝的扩展名列表。
--accept-regex=REGEX regex matching accepted URLs.
--reject-regex=REGEX regex matching rejected URLs.
--regex-type=TYPE regex type (posix|pcre).
-D, --domains=LIST 逗号分隔的可接受的域列表。
--exclude-domains=LIST 逗号分隔的要拒绝的域列表。
--follow-ftp 跟踪 HTML 文档中的 FTP 链接。
--follow-tags=LIST 逗号分隔的跟踪的 HTML 标识列表。
--ignore-tags=LIST 逗号分隔的忽略的 HTML 标识列表。
-H, --span-hosts 递归时转向外部主机。
-L, --relative 只跟踪有关系的链接。
-I, --include-directories=LIST 允许目录的列表。
--trust-server-names use the name specified by the redirection
url last component.
-X, --exclude-directories=LIST 排除目录的列表。
-np, --no-parent 不追溯至父目录。2.curl
curl 是基于URL语法在命令行方式下工作的文件传输工具,它支持FTP, FTPS, HTTP, HTTPS, GOPHER, TELNET, DICT, FILE及LDAP等协议。curl支持HTTPS认证,并且支持HTTP的POST、PUT等方法, FTP上传, kerberos认证,HTTP上传,代理服务器,cookies,用户名/密码认证, 下载文件断点续传,上载文件断点续传, http代理服务器管道( proxy tunneling),还支持IPv6,socks5代理服务器,通过http代理服务器上传文件到FTP服务器等,功能十分强大。
格式:
curl [options] [URL...]选项:
-A/--user-agent 设置用户代理发送给服务器
-v/--verbose 更详细
-I/--head 只显示响应报文首部信息
-s --silent Silent mode
-m, --max-time 案例:
① 这个网页不让你访问,我们可以冒充浏览器去访问

[root@localhost ~]#curl www.163.com -vA chrome
#冒充浏览器去访问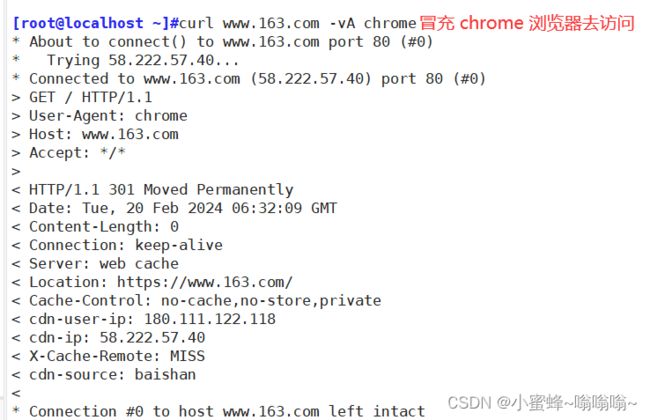
② 提取状态码
curl -s -I -m10 -o /dev/null -w %{http_code} http://www.baidu.com/
③ 远程计算机ip
curl -s -I -m10 -o /dev/null -w %{remote_ip} http://www.baidu.com/
④ 本机ip地址
curl -s -I -m10 -o /dev/null -w %{local_ip} http://www.baidu.com/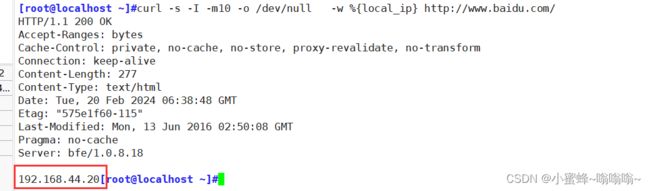
⑤ 本地端口
curl -s -I -m10 -o /dev/null -w %{local_port} http://www.baidu.com/
⑥ 远程端口
curl -s -I -m10 -o /dev/null -w %{remote_port} http://www.baidu.com/
3.压力测试工具
httpd的压力测试工具:
-
ab, webbench, http_load, seige
-
Jmeter 开源
-
Loadrunner 商业,有相关认证
-
tcpcopy:网易,复制生产环境中的真实请求,并将之保存
ab 来自httpd-tools包
命令格式:
ab [OPTIONS] URL选项:
| -n | 总请求数 |
| -c | 模拟的并发数 |
| -k | 以持久连接模式测试 |