Datawhale用免费GPU线上跑AI项目实践课程任务一学习笔记。部署ChatGLM3-6B模型
前言
本篇文章为学习笔记,流程参照Datawhale用免费GPU线上跑AI项目实践课程任务,个人写此文章为记录学习历程和补充概念,并希望为后续的学习者开辟道路,没有侵权的意思。如有错误也希望大佬们批评指正。
模型介绍
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。 ChatGLM-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
从理论上来说,它是比不过ChatGpt的,毕竟它只有62亿的参数。但这也可以变成它的优势,可以部署在家用显卡中。此外,毕竟它也是开源,后续应该也有不少玩法。
配置要求

引用秋叶大佬的观点:显存6G勉强能跑,8G凑合,12G以上正常跑。对内存需求较高,推荐16G以上 。用CPU也能跑,但非常慢,需要32G内存。
如果你也像我一样,没有合适的硬件条件,也可以跟我一样在云上跑。本篇文章将分享我在云上跑的心得体会。
教程
1.注册趋动云
https://growthdata.virtaicloud.com/t/vs
2.创建项目
创建好账号之后,进入自己的空间,点击右上角的创建项目。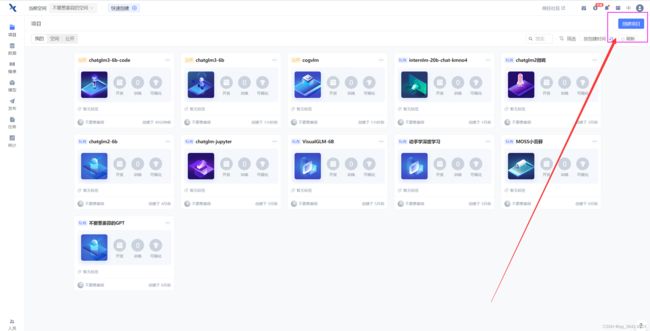
给项目起一个你喜欢的名称,选择本地代码
镜像选择pytorch2.0.1,python3.9

选择预训练模型,点击公开,选择不要葱姜蒜上传的这个ChtaGLM3-6B模型。
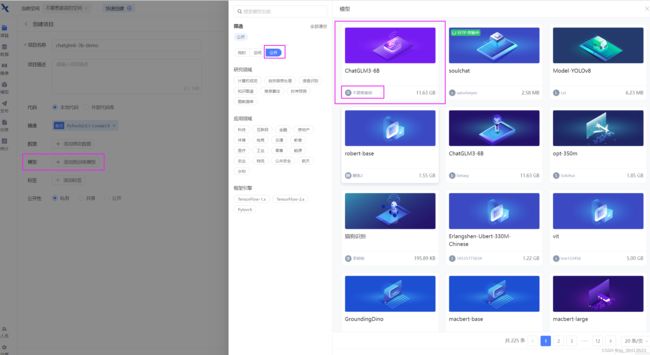
都选完之后,点击右下角的创建,代码选择暂不上传。待会直接clone代码。
点击运行代码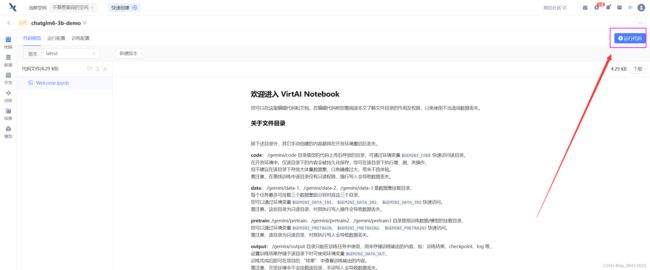
资源配置选择:B1.large, 24G的显存足够加载模型了。其他的不需要设置,然后点击右下角的开始运行。

3.配置环境+修改代码
等右边两个工具全部加载完毕之后,再点击JupyterLab进入开发环境~

进入界面之后是这样的,然后点击这个小加号。

点击terminal,进入终端。
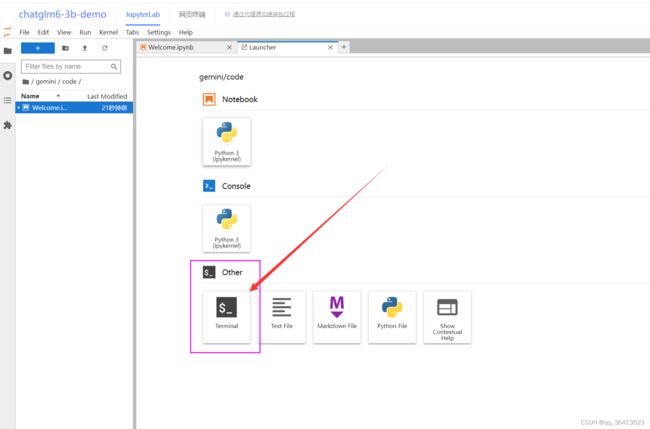
设置镜像源、克隆项目
首先在终端输入tmux,进入一个新的会话窗口。使用tmux可以保持终端的稳定性。
tmuxtmux是“Terminal MultipleXer”的简称,意味“终端复用器”。可以使你同时创建更多的命令行窗格。此外,它的脱离和附加功能可以使你离开时,你开启的窗口和窗格独立运行,它甚至可以在你注销系统后保留你的运行状态。
详细使用方法请看:比Screen更好用的神器:tmux | 《Linux就该这么学》
升级apt,安装unzip
apt-get update && apt-get install unzip即更新软件包信息库和安装解压工具
设置镜像源,升级pip
git config --global url."https://gitclone.com/".insteadOf https://
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
python3 -m pip install --upgrade pip由于国内政策原因,访问 GitHub 会被限制速度,在 clone GitHub 上的代码时很容易出现连接超时的情况,给无法的同学造成了很多困扰。
于是需要使用国内的镜像源来代替国外的,来方便我们的下载。
至于为啥要升级pip呢,我在网上找到的答案是这样的。
1.安全性:pip的旧版本可能有安全漏洞。升级pip可以保证软件的安全性,减少黑客攻击的风险。
2.性能:pip的旧版本可能存在性能问题。升级pip可以提高软件的性能,提高开发效率。
3.新功能:pip的新版本可能会添加新的功能,提高软件的功能性。
我感觉可能是一些大佬们曾经在这方面吃过亏?也许不更新会有一些意想不到的bug?
克隆项目,并进入项目目录
git clone https://github.com/THUDM/ChatGLM3.git
cd ChatGLM3克隆就是把ChatGLM3整个项目打包运送到你的云上,不需要你主动去GitHub下载再上传到你的云上了。然后用cd命令进入你的项目目录。

修改requirements
双击左侧的requirements.txt文件,把其中的torch删掉,因为我们的环境中已经有torch了,避免重复下载浪费时间。
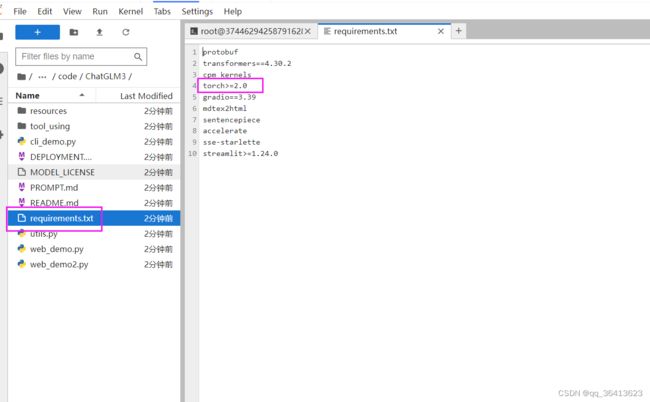
记得ctrl+s保存
点击左上选项卡,重新返回终端,安装依赖
pip install -r requirements.txt安装requirements.txt下的依赖。
修改代码
修改web_demo2.py
双击web_demo2.py,将加载模型的路径修改为:../../pretrain,如下图所示~

记得ctrl+s保存
这里应该是把模型换成了制作这个课程的大佬们预训练完的模型,应该是为了减少训练时间。
修改web_demo.py
和上面一样我们修改一下模型路径,不同的是,接下来还需要修改一段启动代码~

将下方的启动代码修改为下方代码。
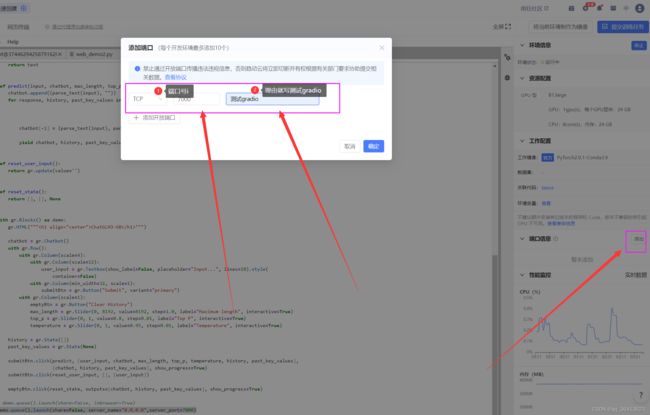
demo.queue().launch(share=False, server_name="0.0.0.0",server_port=7000) 
应该是为了固定webui的ip和端口号,避免之后找不到。
于此同时在界面的右边添加外部端口:7000
4.运行代码
运行gradio界面
python web_demo.py 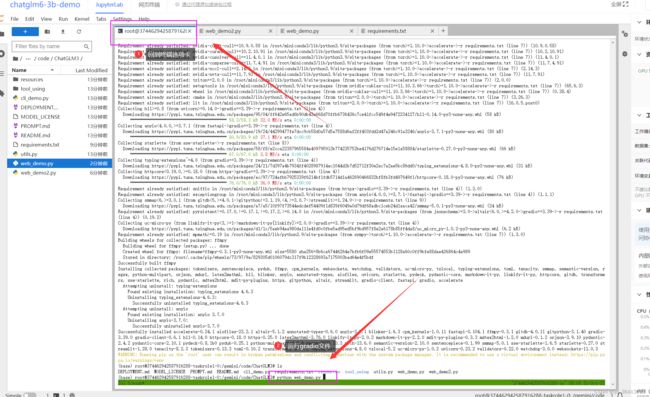
等待模型慢慢加载完毕,可能需要个五六分钟叭保持一点耐心 ~

加载完毕之后,复制外部访问的连接,到浏览器打开
这其实相当于一个内网穿透,把云端的7000口映射到公网上,让我们能透过外部链接来访问内网。
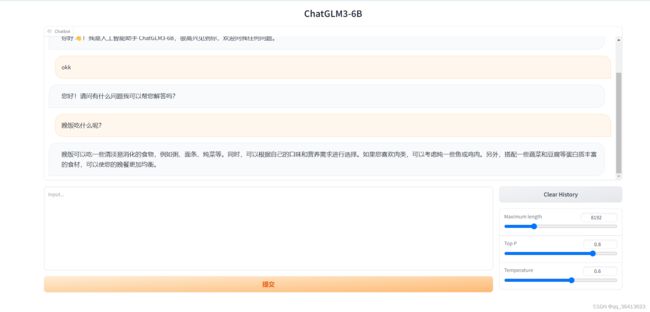
这边有个坑,你复制完外网链接后兴冲冲的粘贴到浏览器中可能会发现它无法打开。这是因为有些浏览器比如Edge浏览器会自动给你的链接前面加https://的前缀,但事实上不应该加。我这里是把它复制到谷歌浏览器里解决的,有相同问题的同学们可以试试~
运行streamlit界面
如果你运行了gradio,需要先杀掉这个进程,不然内存不够。ctrl+C 可以杀掉进程~杀掉进程之后,显存不会立刻释放,可以观察右边的GPU内存占用,查看显存释放情况。
上面咱们已经修改过web_demo2.py的代码了,所以可以直接用streamlit运行。
streamlit run web_demo2.py运行streamlit之后,终端会打印两个地址。在右边添加一个和终端上显示的一样的端口号。
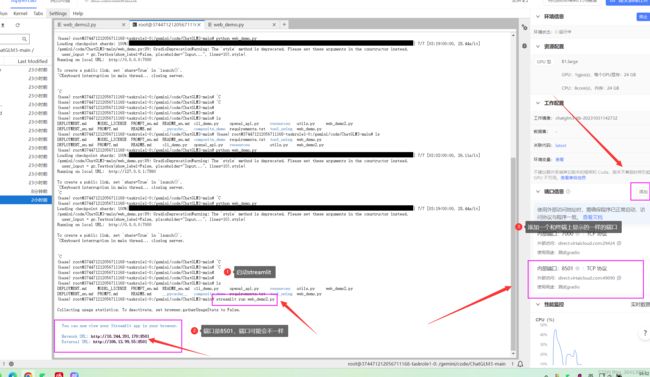
复制外部访问地址到浏览器打开,之后模型才会开始加载。等待模型记载完毕~

okk,下面就是开始体验!

至于gradio与streamlit到底是啥嘛,我也问了 ChatGLM3-6B,它的回答是这样的:
Gradio 是一个用于创建简单 AI 应用程序的 Python 框架,Streamlit 是一个用于构建 Web 应用程序的 Python 框架。
Gradio 提供了各种易于使用的组件,可以让用户构建自己的机器学习模型,包括输入层、隐藏层和输出层。这些组件可以连接到各种机器学习框架,如 TensorFlow 和 PyTorch。Gradio 还提供了各种 pre-built models,可以直接使用。
Streamlit 是一个基于 Python 的 Web 框架,用于构建交互式 Web 应用程序。它提供了一个简单易用的界面,可以让用户轻松地创建自己的 Web 应用程序,而无需编写大量的代码。Streamlit 还可以与各种 Python 库集成,如 NumPy、Pandas 和 Matplotlib。
总之,Gradio 和 Streamlit 都是非常实用的工具,可以帮助用户快速构建自己的机器学习和 Web 应用程序。
如它所言,他俩都是将数据集和机器学习模型转换为交互式Web UI。 主要区别在于Gradio更多地是为机器学习演示而设计的,而Streamlit是为创建数据仪表板而设计的。更多还请移步
https://zhuanlan.zhihu.com/p/622987790进一步了解。
来源参考
1.huggingface主页:https://huggingface.co/THUDM/chatglm-6b
2.b站up秋叶大佬的视频:【ChatGLM】本地版ChatGPT?6G显存可用!ChatGLM-6B 清华开源模型一键包发布 可更新_哔哩哔哩_bilibili
3.Datawhale课程:如何用免费GPU线上跑AI项目实践 - 飞书云文档 (feishu.cn)
4.比Screen更好用的神器:tmux | 《Linux就该这么学》
5.git clone 换源 / GitHub 国内镜像_git国内镜像源_面里多加汤的博客-CSDN博客
6.https://www.ycpai.cn/python/epeetfQ8.html
7.https://zhuanlan.zhihu.com/p/622987790