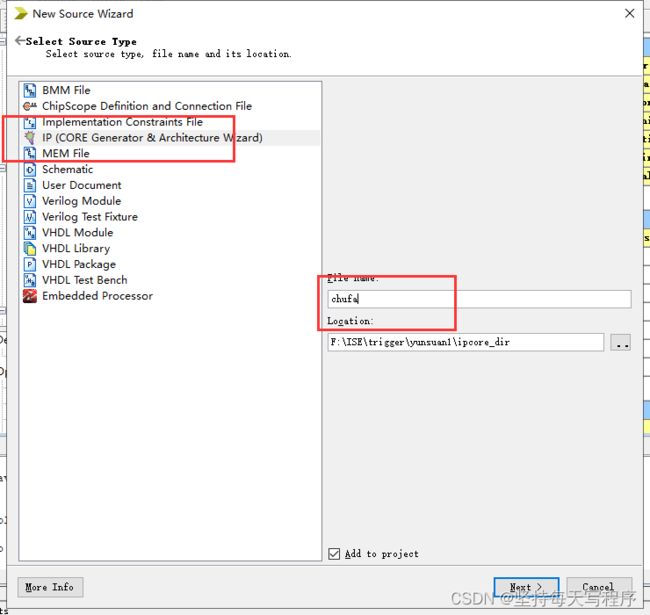
xilinx FPGA 乘法器 除法器 开方 IP核的使用(VHDL&ISE)
目录
一、乘法器ip核
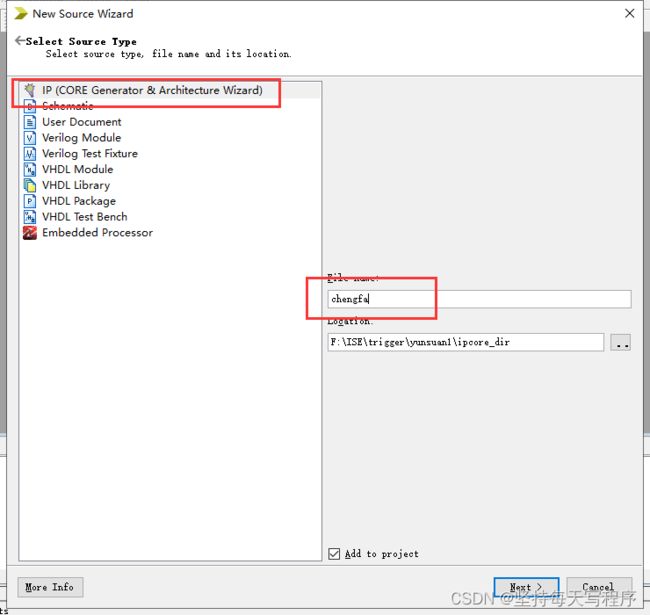
1.新建工程之后 建一个ip核文件:
2.配置ip核:
3.编写顶层文件或者激励文件:
第一种情况:这个是加了ce的
第二种情况:这个是加了ce和sclr的
第三种情况:这个是不加使能的
乘法器的正确使用:
第二天的新进展:最高位是1结果之所以出问题,是因为设置的时候我忘了改了,那个输入的类型默认是signed,即有符号位,大家一定要看清楚哟,按照自己需求,看是否设置最高位为有符号位
二、除法器:
第一种情况:
第二种情况
除法ip核的延时分析
第一种,选用Radix-2 模式
第二种,选用High Radix 模式
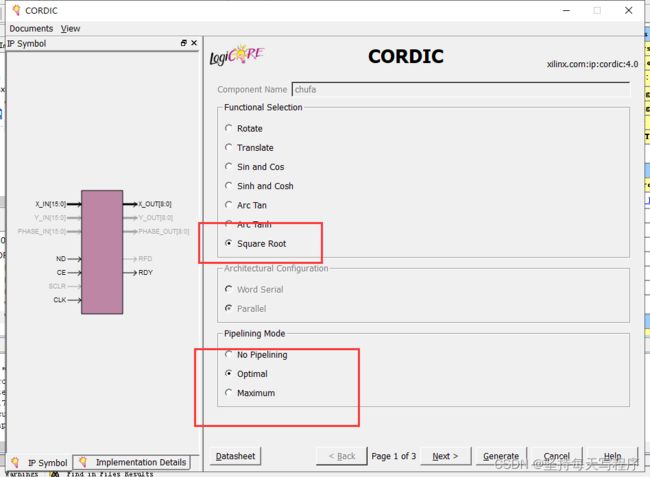
三、开方ip核
建立ip核文件,并进行配置
建立测试文件
开方ip核的时延问题
第一种情况,选择最优模式,正无穷模式
第二种情况,我将模式选择成了截断
总结:对于fpga里面的计算时延,既然存在就是不可避免的,那么再进行级联计算的时候,
四、新建vhdl文件,将三种ip核联合起来使用,进行例化核程序编写: (由于位宽不同,我还建了一个除法器)
1.4个计算ip核的例化
2.ip核之间的使能
3.顶层例化
4.测试文件
5.rtl图:
6.仿真图:
7.这是在写状态机时遇到的问题
一、乘法器ip核
1.新建工程之后 建一个ip核文件:
2.配置ip核:

根据自身需求,完成端口位宽设置
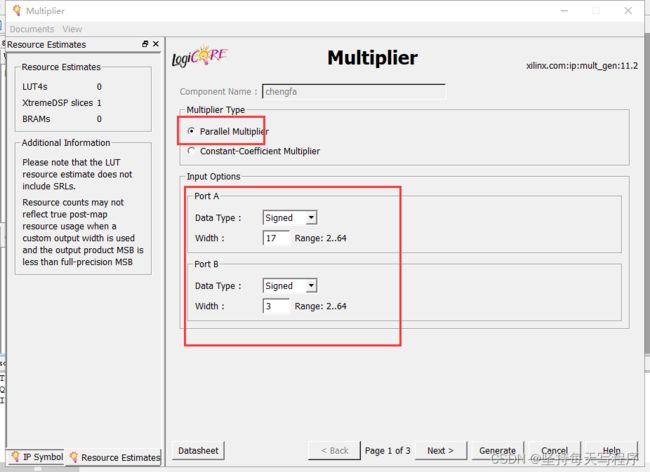
好像选用mult就是使用dsp的乘法器资源(maybe是这样吧 笔者能力有限)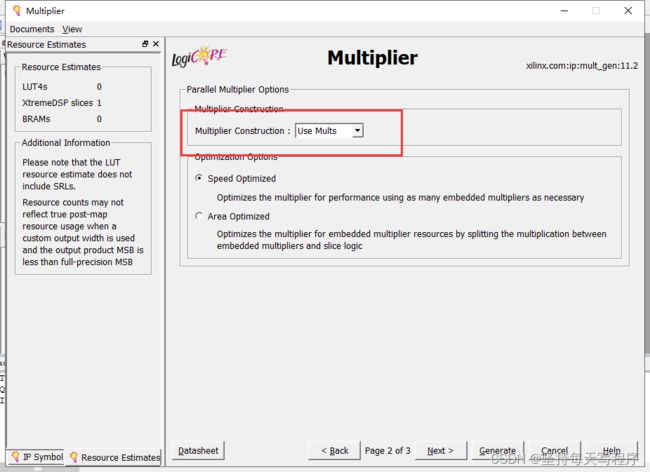
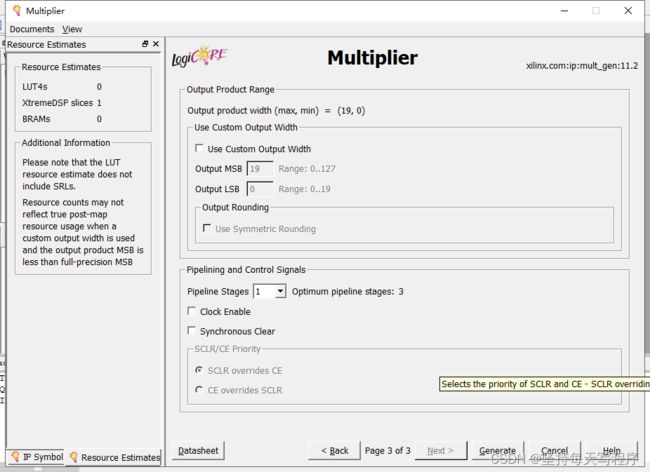
这里按照默认 自动匹配输出位宽,也可以自己选择是否开启时钟使能和异步复位(我后面的程序是打开了ce的,就是要勾上clock enable)
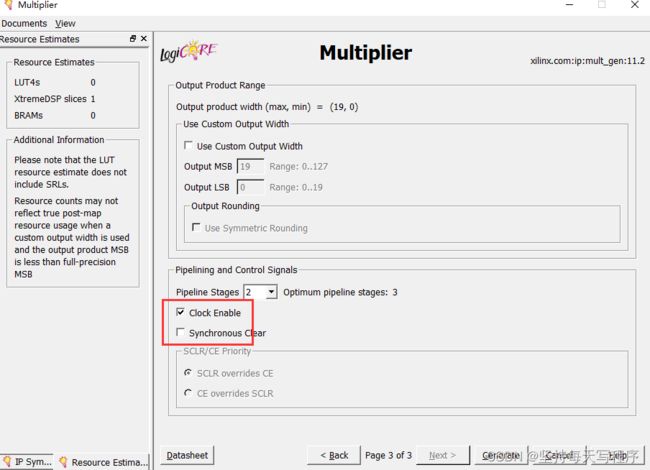
乘法器生成完
3.编写顶层文件或者激励文件:
(一定一定点击下面这个例化模板 去对ip核进行例化)


我是直接写的tb文件进行仿真(以下是我对乘法器配置是否选用ce和sclr的测试,但结果有点问题 不知道哪里出错了)
注:因为我调用乘法ip核,第一次出现结果不正确,以前测试的时候就是随便写个5什么的数据去计算,都是对的,但是这一次就是小一点的数相乘结果正确,但是当数大一点,但是在位宽范围内,相乘的结果却是错误的,所以不知道问题在哪里,我就想尝试从是否添加使能和复位有关,以下就是测试结果,但原因是其他,在下文有详细描述。
第一种情况:这个是加了ce的
两个数相乘结果错误,是小一点的值对的 大一点计算就错了 但是我都输出范围也没超啊 不知道哪里的错
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
ENTITY chengfa_tb IS
END chengfa_tb;
ARCHITECTURE behavior OF chengfa_tb IS
COMPONENT chengfa
PORT(
clk : IN std_logic;
a : IN std_logic_vector(16 downto 0);
b : IN std_logic_vector(2 downto 0);
ce : IN std_logic;
p : OUT std_logic_vector(19 downto 0)
);
END COMPONENT;
--Inputs
signal clk : std_logic := '0';
signal a : std_logic_vector(16 downto 0) := (others => '0');
signal b : std_logic_vector(2 downto 0) := (others => '0');
signal ce : std_logic := '0';
--Outputs
signal p : std_logic_vector(19 downto 0):= (others => '0');
-- Clock period definitions
constant clk_period : time := 10 ns;
BEGIN
-- Instantiate the Unit Under Test (UUT)
uut: chengfa PORT MAP (
clk => clk,
a => a,
b => b,
ce => ce,
p => p
);
-- Clock process definitions
clk_process :process
begin
clk <= '0';
wait for clk_period/2;
clk <= '1';
wait for clk_period/2;
end process;
-- Stimulus process
stim_proc: process
begin
-- hold reset state for 100 ns.
ce <= '0';
wait for 100 ns;
ce <= '1';
a <= '1'&X"86D4"; --100052
b <= "101"; --5
wait for clk_period*10;
wait;
end process;
END;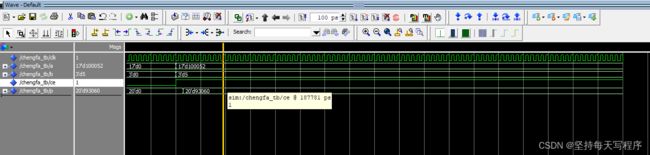
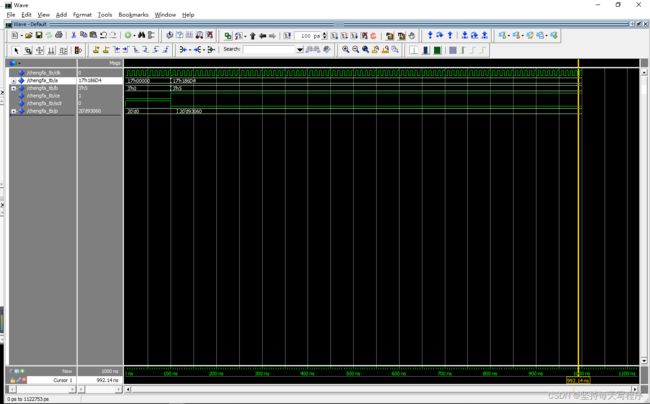
第二种情况:这个是加了ce和sclr的
两个数相乘结果错误,是小一点的值对的 大一点计算就错了 但是我都输出范围也没超啊 不知道哪里的错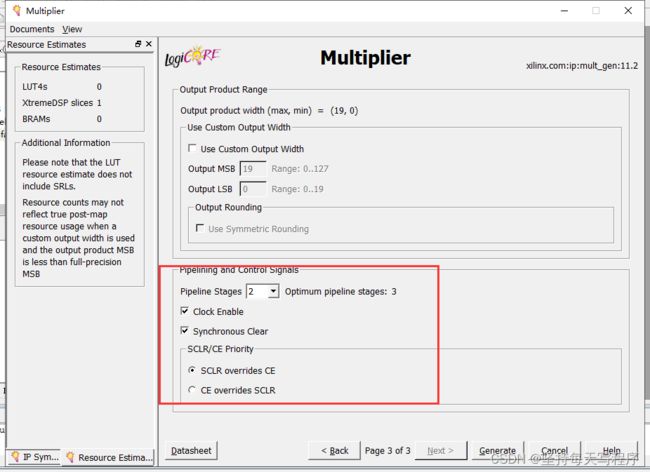
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
ENTITY chengfa_tb IS
END chengfa_tb;
ARCHITECTURE behavior OF chengfa_tb IS
-- Component Declaration for the Unit Under Test (UUT)
COMPONENT chengfa
PORT(
clk : IN std_logic;
a : IN std_logic_vector(16 downto 0);
b : IN std_logic_vector(2 downto 0);
ce : IN std_logic;
sclr : IN STD_LOGIC;
p : OUT std_logic_vector(19 downto 0)
);
END COMPONENT;
--Inputs
signal clk : std_logic := '0';
signal a : std_logic_vector(16 downto 0) := (others => '0');
signal b : std_logic_vector(2 downto 0) := (others => '0');
signal ce : std_logic := '0';
signal sclr : std_logic := '0';
--Outputs
signal p : std_logic_vector(19 downto 0):= (others => '0');
-- Clock period definitions
constant clk_period : time := 10 ns;
BEGIN
-- Instantiate the Unit Under Test (UUT)
uut: chengfa PORT MAP (
clk => clk,
a => a,
b => b,
ce => ce,
sclr => sclr,
p => p
);
-- Clock process definitions
clk_process :process
begin
clk <= '0';
wait for clk_period/2;
clk <= '1';
wait for clk_period/2;
end process;
-- Stimulus process
stim_proc: process
begin
-- hold reset state for 100 ns.
ce <= '0';
sclr<= '1';
wait for 100 ns;
ce <= '1';
sclr<= '0';
a <= '1'&X"86D4"; --100052
b <= "101"; --5
wait for 100 ns;
wait for clk_period*10;
-- insert stimulus here
wait;
end process;
END;
第三种情况:这个是不加使能的
两个数相乘结果错误,是小一点的值对的 大一点计算就错了 但是我都输出范围也没超啊 不知道哪里的错
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
ENTITY chengfa_tb IS
END chengfa_tb;
ARCHITECTURE behavior OF chengfa_tb IS
-- Component Declaration for the Unit Under Test (UUT)
COMPONENT chengfa
PORT(
clk : IN std_logic;
a : IN std_logic_vector(16 downto 0);
b : IN std_logic_vector(2 downto 0);
p : OUT std_logic_vector(19 downto 0)
);
END COMPONENT;
--Inputs
signal clk : std_logic := '0';
signal a : std_logic_vector(16 downto 0) := (others => '0');
signal b : std_logic_vector(2 downto 0) := (others => '0');
--Outputs
signal p : std_logic_vector(19 downto 0):= (others => '0');
-- Clock period definitions
constant clk_period : time := 10 ns;
BEGIN
-- Instantiate the Unit Under Test (UUT)
uut: chengfa PORT MAP (
clk => clk,
a => a,
b => b,
p => p
);
-- Clock process definitions
clk_process :process
begin
clk <= '0';
wait for clk_period/2;
clk <= '1';
wait for clk_period/2;
end process;
-- Stimulus process
stim_proc: process
begin
-- hold reset state for 100 ns.
a <= '1'&X"86D4"; --100052
b <= "101"; --5
wait for 100 ns;
wait for clk_period*10;
-- insert stimulus here
wait;
end process;
END;
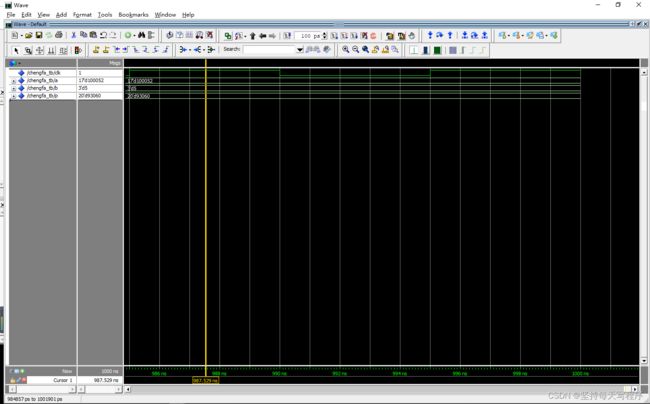
乘法器的正确使用:
通过测试发现,如果输出结果的位宽按照默认设置,当两个乘数有一个的最高位是1,那么结果会发生错误。因为我有一个乘数如果是16位的话,最高位就是1,那么按照16的位宽就会犯错,我将乘数的位宽改成17,结果正确。
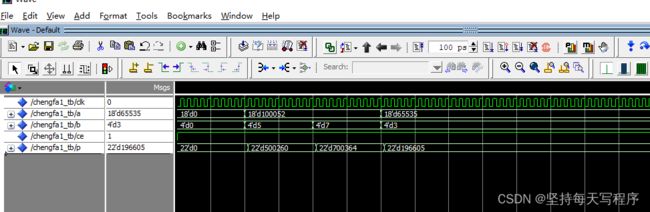
大家可以对比以下两张图,当乘数当中有一个最高位是1,那么结果会出错,而输出结果的位宽不会影响,只是如果范围大于位宽,将会溢出。(所以最后我在我原本需要的乘数位宽上加一,结果就没有问题,但考虑到资源问题,输出结果的位宽就可以根据实际需求来定。以上就是我对vhdl当中乘法器相乘结果不对的分析。)
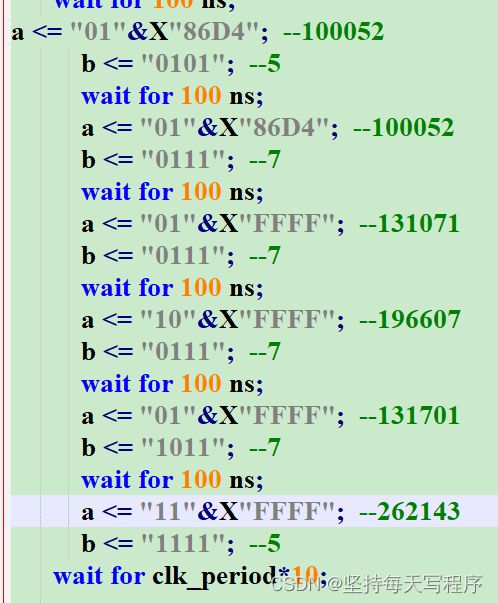
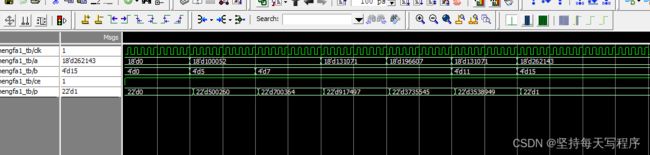
第二天的新进展:最高位是1结果之所以出问题,是因为设置的时候我忘了改了,那个输入的类型默认是signed,即有符号位,大家一定要看清楚哟,按照自己需求,看是否设置最高位为有符号位
心得:有的时候百思不得其解的问题,到最后发现只是一个小小的环节出了一点问题,当然最后发现原因之后,也会豁然开朗,虽然发现问题的时间很长,但终归是要慢慢积累,有人说过一句话,我们遇到的问题,以前一定有人遇到过,我们只需要去发现别人事是怎么解决问题的。最近对这句话真的深有感触,我通过写csdn的方式去记录自己的学习过程,虽然刚开始时一些很简单的问题,但有很多文章,我并不是一下写完的,就像这篇一下,当我发现问题,不知道怎么解决或者压根不知道为什么错,甚至觉得自己的逻辑无懈可击,但过两天会发现,oh原来问题在这里,希望这次出现的一些bug,能够帮助下一个遇到相同问题的人叭。

大家可以看到,乘法器是没有时延的,在数据输入的那个周期,就会产生结果。
后面发现不是说乘法器没有延时,乘法器的输入是在ce为1时输入的,他算出来的结果是在ce的那个周期里面算出来的,但是要等到时钟上升沿来的时候才输出,比如下面第一组和第三组的数据,可以看到输入数据是在时钟上升沿的时候送进来的,那么刷出结果就是在下一个时钟的上升沿输出。但是第二组数据,是在时钟下降沿送进来的,那么算出的结果就会在紧接着的时钟上升沿输出的。所以可以看做本身乘法器的运算是没有延时的,但是由于数据输出必须在时钟上升沿输出,所以在进行ip核级联运算时,最好将乘法器的输出,延迟一个时钟再去进行下一步的运算。

二、除法器:
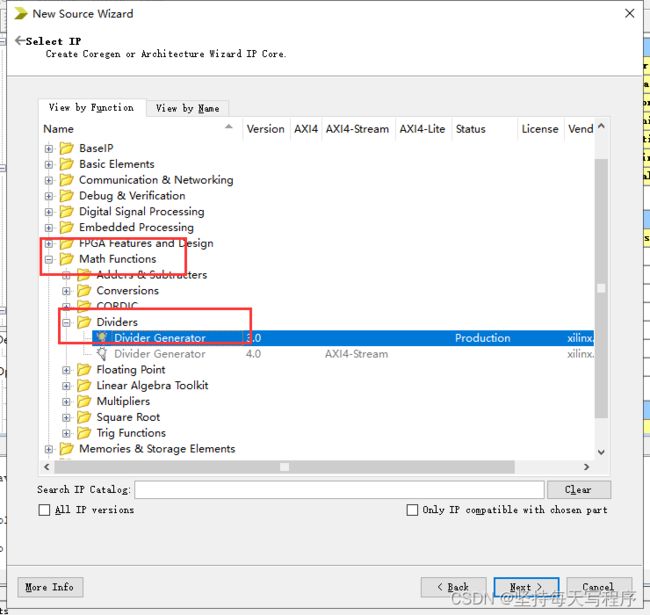
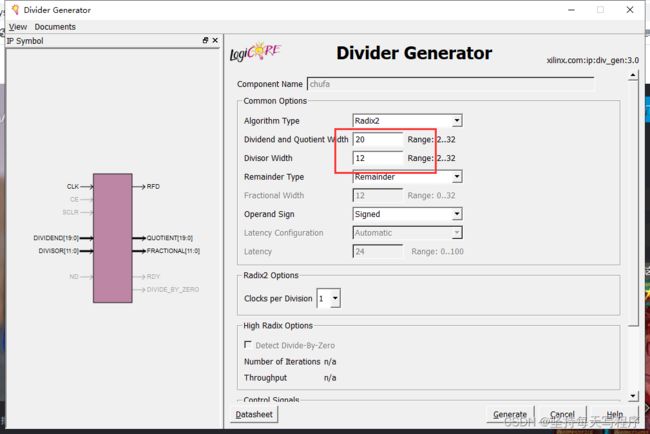
第一种情况:
当将除法器配置如下时,我们来看一下仿真结果
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
USE ieee.numeric_std.ALL;
ENTITY testbench IS
END testbench;
ARCHITECTURE behavior OF testbench IS
-- Component Declaration
component chufa
port (
clk: in std_logic;
ce: in std_logic;
rfd: out std_logic;
dividend: in std_logic_vector(19 downto 0);
divisor: in std_logic_vector(11 downto 0);
quotient: out std_logic_vector(19 downto 0);
fractional: out std_logic_vector(11 downto 0));
end component;
SIGNAL clk: std_logic:= '0';
SIGNAL ce: std_logic:= '0';
SIGNAL rfd: std_logic:= '0';
SIGNAL dividend: std_logic_vector(19 downto 0):= (others => '0');
SIGNAL divisor: std_logic_vector(11 downto 0):= (others => '0');
SIGNAL quotient: std_logic_vector(19 downto 0):= (others => '0');
SIGNAL fractional: std_logic_vector(11 downto 0):= (others => '0');
constant clk_period : time := 10 ns;
BEGIN
-- Component Instantiation
chuf : chufa
port map (
clk => clk,
ce => ce,
rfd => rfd,
dividend => dividend,
divisor => divisor,
quotient => quotient,
fractional => fractional);
clk_process :process
begin
clk <= '0';
wait for clk_period/2;
clk <= '1';
wait for clk_period/2;
end process;
-- Test Bench Statements
tb : PROCESS
BEGIN
ce<= '0';
wait for 100 ns; -- wait until global set/reset completes
ce<= '1';
dividend<= X"7A224";
divisor<= X"9C4";
-- Add user defined stimulus here
wait for 100 ns; -- wait until global set/reset completes
dividend<= X"7A1DE";
divisor<= X"9C4";
wait for 100 ns; -- wait until global set/reset completes
dividend<= X"FA1DE";
divisor<= X"9C4";
wait for 100 ns; -- wait until global set/reset completes
dividend<= X"7A1DE";
divisor<= X"FC4";
wait; -- will wait forever
END PROCESS tb;
-- End Test Bench
END;
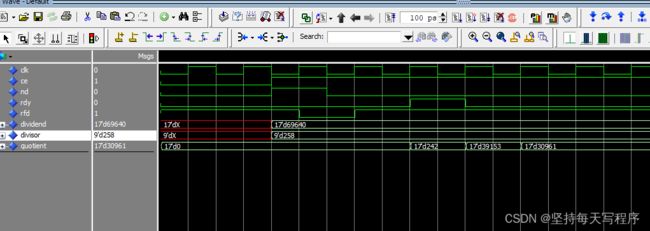
我们可以看到除数的结果只显示能过除尽的部分,然后就是余数,比如第一个结果余数是260,下一个余数是190。当然我测试了乘法器里面的那个故障,当我把除数或者被除数的最高位置一时,结果没有发生错误。
第二种情况
我将分数的位宽减小时:
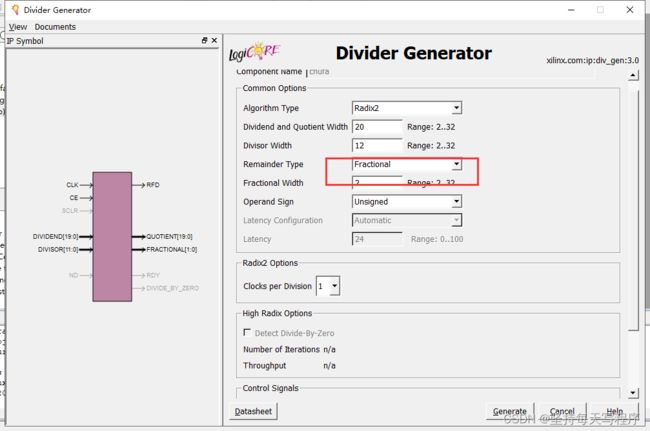
结果是一样的,只是余数不一样了,然后计算的时延也没有变化。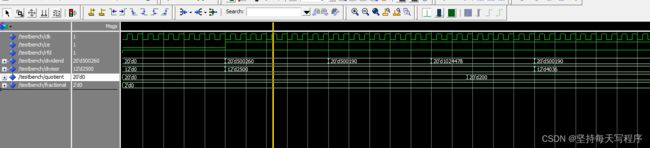
除法ip核的延时分析
在进行除法运算时,因为后一级运算也需要用到除法运算的结果,但不知道怎么判断除法运算是否完成,一下是对不同除法运算的时延的分析:
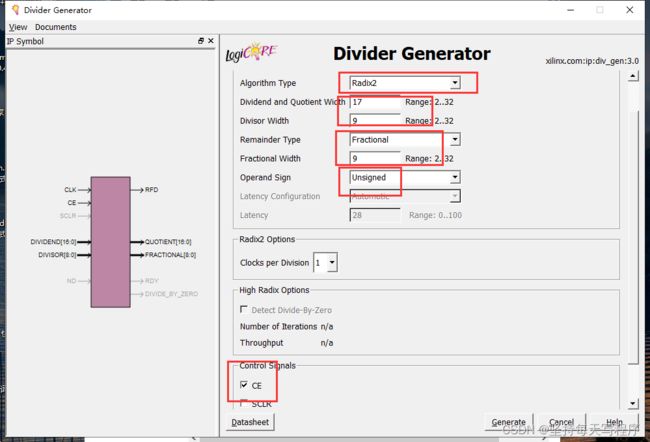
第一种,选用Radix-2 模式

这是该模式下的输入输出,分别是
同步清除(SCLR)。可选的输入引脚。当(高)时,所有ip核触发器都被同步初始化(与时钟同步)。ip核一直保持在这种状态下,直到SCLR被取消高电平。当SCLR和CE都存在时,GUI中的SCLR/CE优先级设置将确定SCLR是否被CE限定或SCLR是否覆盖CE(即,即使CE被取消断言,SCLR也会清除时钟边缘的模块)。
时钟启用(CE)。可选的输入引脚。取消断言(低)时,所有同步输入被忽略,ip核保持其当前状态。(即高有效)
dividend :被除数 divisor:除数
基数-2非恢复算法使用加减法求解每个周期的一点商。该设计是完全流水线的,可以实现每个时钟周期一分的吞吐量。如果所需的吞吐量较小,则每个时钟参数的分法允许降低吞吐量和资源使用。该算法自然会生成一个余数,对于需要整数余数或模数结果的应用程序的选择也是如此。
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
USE ieee.numeric_std.ALL;
ENTITY testbench IS
END testbench;
ARCHITECTURE behavior OF testbench IS
-- Component Declaration
component chufa1
port (
clk: in std_logic;
ce: in std_logic;
rfd: out std_logic;
dividend: in std_logic_vector(16 downto 0);
divisor: in std_logic_vector(8 downto 0);
quotient: out std_logic_vector(16 downto 0);
fractional: out std_logic_vector(8 downto 0));
end component;
signal clk: std_logic;
signal ce: std_logic;
signal rfd: std_logic;
signal dividend: std_logic_vector(16 downto 0);
signal divisor: std_logic_vector(8 downto 0);
signal quotient: std_logic_vector(16 downto 0);
signal fractional: std_logic_vector(8 downto 0);
constant clk_period : time := 10 ns;
BEGIN
-- Component Instantiation
u0 : chufa1
port map (
clk => clk,
ce => ce,
rfd => rfd,
dividend => dividend,
divisor => divisor,
quotient => quotient,
fractional => fractional);
-- Test Bench Statements
clk_process :process
begin
clk <= '0';
wait for clk_period/2;
clk <= '1';
wait for clk_period/2;
end process;
tb : PROCESS
BEGIN
ce <= '0';
wait for 20 ns;
ce <= '1';
dividend <= '1'&X"1008";
divisor <= '1'&X"02";
wait for 10 ns; -- wait until global set/reset completes
dividend <= '0'&X"1008";
divisor <= '0'&X"32";
wait for 10 ns;
-- Add user defined stimulus here
dividend <= '1'&X"1508";
divisor <= '1'&X"12";
wait for 10 ns;
wait; -- will wait forever
END PROCESS tb;
-- End Test Bench
END;
结果都是对的,但好像只有第一次计算的时候,才有时延,后面好像又没有
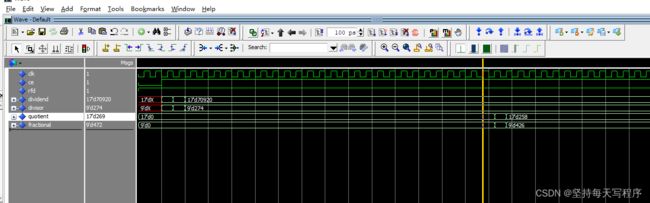
我把那个模式选成余数试试:
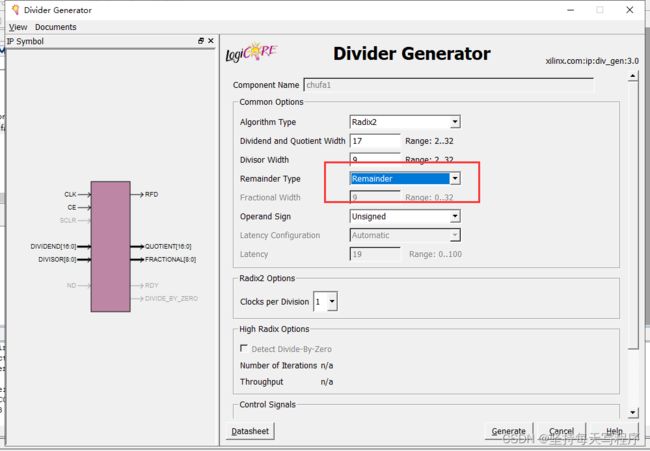

结论就是在这种模式下,余数的时延大概是19个时钟,分数模式大概28个时延(指针对本次测试数据)
在该模式下的延迟:
总延迟(在ip核生成第一个有效输出之前所需的时钟数)是被除数的位宽度的函数。如果需要分数输出,则延迟也是分数位宽度的函数。如果选择了时钟启用(ce),则延迟是根据已启用的时钟周期。
当每个划分的时钟被设置为2、4或8时,RFD(准备好的数据)输出指示输入数据被采样的周期(如下图),因此,从测量延迟时开始。如果在外部使用,RFD应该通过时钟启用。

一般来说:对于整数余数除法器,延迟的顺序是M(被除数的位宽),对于分数剩余除法器,延迟的顺序是M+F(F是分数部分的位宽)
大家可以看一下下表,基于除法器参数的基数2的延迟,可以看到他跟我们选择是否有符号位和分数有关,我们上面的设计即是1.无符号位余数每一次一个时钟,所以延迟是M+2=19个时钟
2.无符号位分数每一次一个时钟,所以延迟M+F+2=28。
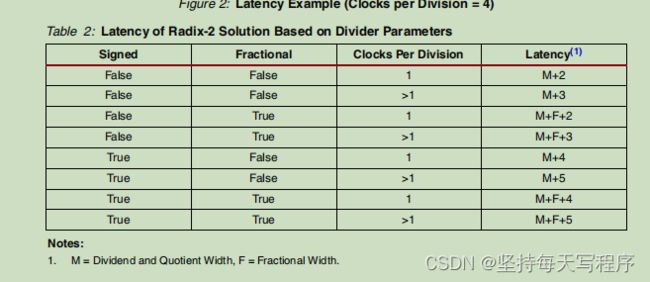
总结:如果选择无符号位,那么慢时延会减小,如果选择余数输出,时延也会减小,Clocks Per Division增大,时延也会减小,当然数据的位宽减小,时延也会减小。大家在进行除法配置的时候,可以尽量减小位宽(根据需求)
第二种,选用High Radix 模式
具有预标定算法的高基数算法一次解析商的多个位。它是通过重用商估计块来实现的,因此吞吐量是所需迭代次数的函数。操作数必须为迭代操作做准备。这种开销使得该算法不太适合用于较小的操作数。尽管迭代计算比Radiz-2更复杂,需要更多的循环,但每次迭代解析的商位数和XtremeDSP切片的使用使得它成为更大操作数宽度的首选选择。
在使用加速的高基数划分算法之前,高基数实现通过预缩放操作数来执行划分。该设计是完全流水线的最大时钟频率。首先,将除数归一化,然后得到其倒数的估计。两个操作数都乘以这个估计,使除数更接近1。前标度的精度和精度决定了在每次后续迭代中可以解析多少商位。预调整的除数接近于1这一事实使得新商位的估计只是前一次迭代中剩下的残差的顶部位。迭代操作本身是在携带保存符号中执行的,因此没有长携带链限制性能。因为只使用残差的顶部位被用作估计,并且除数不是1,每次迭代的内部结果都会出现错误;因此,每次迭代中解析的商位与之前解析的位略有重叠,以便在后续迭代中纠正错误。
因为迭代计算由携带保存的乘法和减法组成,所以它非常适合XtremeDSP(乘加)片,提供了一个高效的、低延迟的迭代。
所提供的三个握手信号分别为ND、RFD和RDY。所有这些信号都受CE的影响,所以当CE真正输入到核心时,ND必须成立。同样地,RFD和RDY只会在CE为真的时钟周期中发生改变。ND是对新数据输入的请求,但只有在RFD为true时才会被接受,否则该输入将被忽略。如果ND和RFD都为真,那么核心将接受输入,在一段延迟后RDY将出现一个结果。这个延迟是通过GUI指定的,用从输入到输出的时钟启用时钟周期数表示。
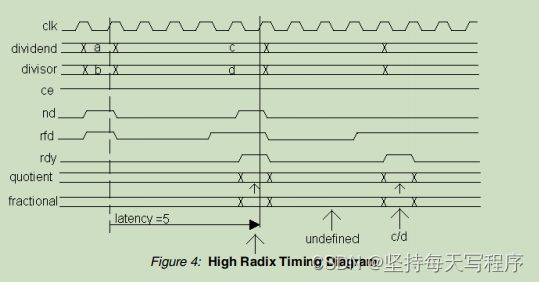
下图为该模式下的引脚分配图:

DIVIDE_BY_ZERO:检测到除以零
新数据(ND)。用于向核心发出信号,表明在ip核的输入上存在新的操作数。
已准备好获取数据(RFD)。有信号表明ip核能够接受新的操作数。
RDY : 准备好的表示在ip核的输出中有一个结果可用的信号。
其时序图如下:当启用时,DIVIDE_BY_ZERO输出与商输出和分数输出在相同的周期上提供。
所以在使用该模式时,要根据下面的时序去产生nd,也就是两个nd之间要相隔一个延时周期,比如,它的延时周期是5,所以当nd=1一个周期后,后面四个周期=0,然后再拉高,就不会产生数据错位,还有就是商的时间,要在ndy为1 时,商才是正确的。
该模式下最小延迟

该模式下最大延迟
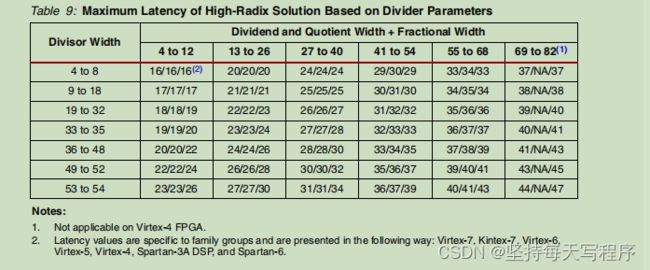
而在配置ip核时,有延迟配置界面,延迟配置:自动(完全流水线化)或手动(由以下字段确定)。基数-2解决方案的延迟配置始终是自动的。延迟:当“延迟配置”设置为“自动”时,此字段将根据启用时钟的时钟周期提供从输入到输出的延迟。当手动操作时,此字段用于指定所需的延迟。
也就是说用第二种模式时,计算的延迟,可以在High Radix Options中进行配置
Radix-2 Options:每除时钟:确定输入(和输出)新数据之间的时钟间隔
例如一下配置时,仿真波形如图:
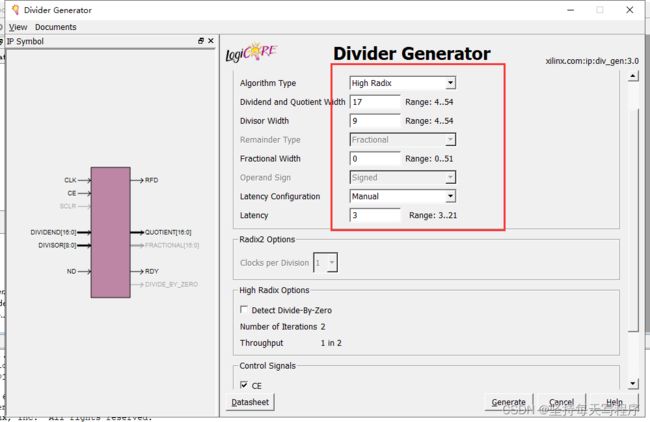
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
USE ieee.numeric_std.ALL;
ENTITY testbench IS
END testbench;
ARCHITECTURE behavior OF testbench IS
-- Component Declaration
component chufa2
port (
clk: in std_logic;
ce: in std_logic;
nd: in std_logic;
rdy: out std_logic;
rfd: out std_logic;
dividend: in std_logic_vector(16 downto 0);
divisor: in std_logic_vector(8 downto 0);
quotient: out std_logic_vector(16 downto 0));
end component;
signal clk: std_logic;
signal ce: std_logic;
signal nd: std_logic;
signal rdy: std_logic;
signal rfd: std_logic;
signal dividend: std_logic_vector(16 downto 0);
signal divisor: std_logic_vector(8 downto 0);
signal quotient: std_logic_vector(16 downto 0);
--signal fractional: std_logic_vector(8 downto 0);
constant clk_period : time := 10 ns;
BEGIN
-- Component Instantiation
u0 : chufa2
port map (
clk => clk,
ce => ce,
nd => nd,
rdy => rdy,
rfd => rfd,
dividend => dividend,
divisor => divisor,
quotient => quotient);
-- Test Bench Statements
clk_process :process
begin
clk <= '0';
wait for clk_period/2;
clk <= '1';
wait for clk_period/2;
end process;
tb : PROCESS
BEGIN
ce <= '0';
nd <= '0';
wait for 20 ns;
ce <= '1';
nd <= '1';
dividend <= '1'&X"1008";
divisor <= '1'&X"02";
wait for 10 ns; -- wait until global set/reset completes
nd <= '0';
wait; -- will wait forever
END PROCESS tb;
-- End Test Bench
END;
可以看到确实延迟了3个时钟,但是已经将nd清零了,后面还会输出商
不知道大家有没有发现,它的计算结果是错误的,后来发现,在这种模式下,被除数和除数都是有符号类型的数,所以大家要注意,如果计算的都是正数,那么就可以扩大一位位宽。
总结,fpga使用除法时,肯定会产生时延,我们要尽可能的去缩小时延,还有就是因为有延迟,所以要严格按照时序,去使能一些管脚,以免造成数据错位。
三、开方ip核
建立ip核文件,并进行配置
这个是cordic ip核的引脚分配图
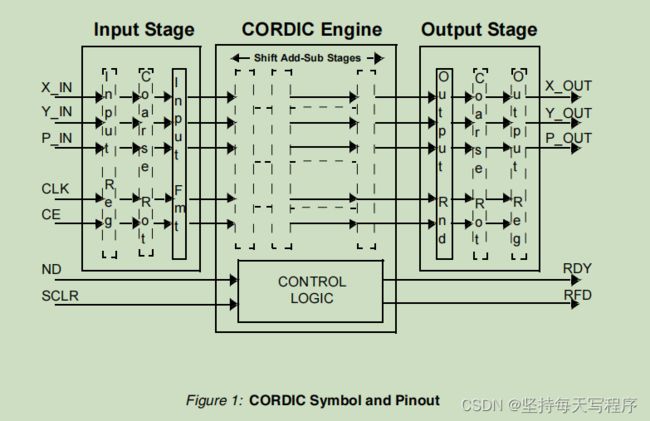
ND:在输入端口上的新数据。高有效。
RDY:新的输出数据已准备就绪。高有效。

当选择平方根函数配置时,使用简化的CORDIC算法来计算输入的正平方根。输入X_IN和输出X_OUT总是正的,并且都表示为无符号分数或无符号整数。当数据格式设置为无符号分数时,X_IN被限制为范围:0<=X_IN<+2。当数据格式设置为无符号整数时,X_IN的限制范围为:0<=X_IN<2**输入宽度,输出宽度根据输入宽度自动确定。
下图是开方时,输入输出位宽情况:

当选用开方模块时,cordic会自动选择Parallel Architectural Configuration模式
CORDIC算法需要每位精度大约一个移位加子操作。具有并行体系结构配置的CORDIC核心使用移加子阶段数组并行实现这些移加子操作。一个具有N位输出宽度的并行CORDIC核有N个周期的延迟,每个周期产生一个新的输出。并行CORDIC核心的实现大小与内部精度乘以迭代次数成正比。
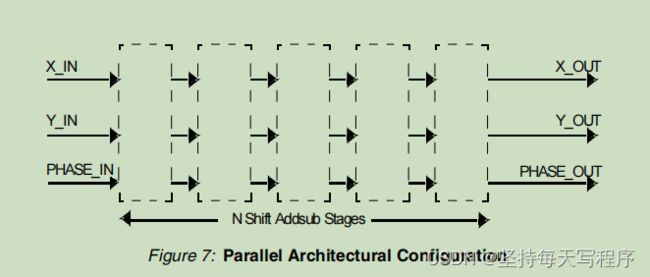
Pipelining Mode流水线模式:CORDICip核提供了三种流水线模式:无流水线模式、最优流水线模式和最大流水线模式。流水线模式的选择是基于功能配置和体系结构配置的选择。不可用的流水线模式在GUI中是灰色的。
•无:CORDIC核心的实现没有流水线。
•最优:CORDIC核心实现了尽可能多的管道阶段,而不使用任何额外的lut。
•最大值:CORDIC核心在每个转移添加子阶段后通过一个管道实现。

数据格式:
无符号分数:X和Y的输入和输出表示为无符号的整数。仅可用于平方根功能配置。示例:“11100000”表示值+1.75。
•无符号整数:X和Y的输入和输出表示无符号整数。仅可用于平方根功能配置。示例:“11100000”表示值+224。
输入/输出选项:CORDIC核心提供了四个输入/输出通用配置选项。
•输入宽度:输入宽度控制输入端口的宽度,X_IN、Y_IN和PHASE_IN。输入宽度可以配置在8到48位的范围内。
•寄存器输入:如果输入信号X_IN、Y_IN、PHASE_IN是寄存器输入,就选上。
•输出宽度:输出宽度控制输出端口的宽度,X_OUT、Y_OUT、PHASE_OUT。输出宽度可以配置在8到48位的范围内。
•寄存器输出:如果输出信号、X_OUT、Y_OUT、PHASE_OUT是寄存器输出,就选上。
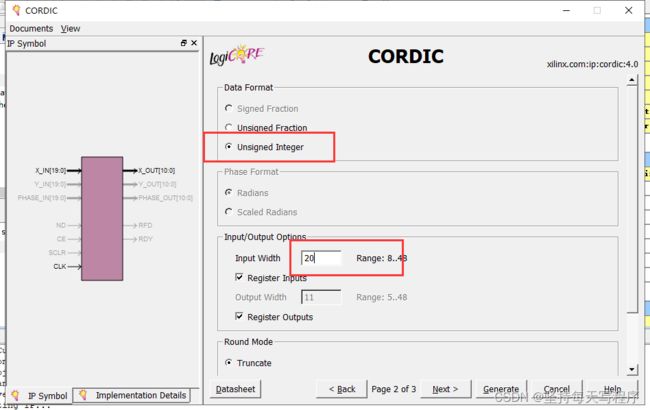

可选择控制信号:ND、RDY、SCLR和CE控制信号可选。CLK和RFD控制信号的存在是基于选定的体系结构配置、管道模式、寄存器输入和寄存器输出来确定的。
•输出信号:X_OUT、Y_OUT和PHASE_OUT都是可选的。
这些信号的默认状态是根据所选的功能配置来确定的,但可以由用户手动覆盖。

建立测试文件
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
ENTITY kaifang_tb IS
END kaifang_tb;
ARCHITECTURE behavior OF kaifang_tb IS
-- Component Declaration for the Unit Under Test (UUT)
COMPONENT kaifang
PORT(
x_in : IN std_logic_vector(19 downto 0);
x_out : OUT std_logic_vector(10 downto 0);
clk : IN std_logic;
ce : IN std_logic
);
END COMPONENT;
--Inputs
signal x_in : std_logic_vector(19 downto 0) := (others => '0');
signal clk : std_logic := '0';
signal ce : std_logic := '0';
--Outputs
signal x_out : std_logic_vector(10 downto 0);
-- Clock period definitions
constant clk_period : time := 10 ns;
BEGIN
-- Instantiate the Unit Under Test (UUT)
uut: kaifang PORT MAP (
x_in => x_in,
x_out => x_out,
clk => clk,
ce => ce
);
-- Clock process definitions
clk_process :process
begin
clk <= '0';
wait for clk_period/2;
clk <= '1';
wait for clk_period/2;
end process;
-- Stimulus process
stim_proc: process
begin
-- hold reset state for 100 ns.
ce <= '0';
wait for 100 ns;
ce <= '1';
x_in <= X"000C8";
wait for 100 ns;
x_in <= X"100C8";
wait for clk_period*10;
-- insert stimulus here
wait;
end process;
END;

开方ip核的时延问题
但是可以看到开方也是有时延存在的,所以我们需要用到它的nd和rdy
相关的时序信息如下:
控制信号和定时以下部分描述了CORDIC ip核所使用的控制信号。所有的控制信号都与CLK的上升边缘同步。具有并行架构配置的CORDIC核心的时序图如下图所示。(在选择开方的时候,ip核会自动默认为并行架构)
可以看到在第一个输入数据(Di0)和第一个输出数据(Do0)之间是有时间延迟的(但没有具体告诉时延怎么计算)
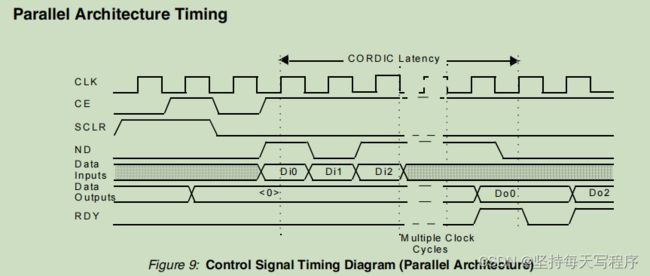
当ND(新数据)输入高时,输入数据在同一上升时钟边缘采样。如果CE低或RFD较低,则忽略ND。当选择了Word串行体系结构时,ND是必需的。否则,ND是可选的。(如果想要控制输入数据,在开方时,可以选择此端口)
RFD(准备好了数据)表示核心已经准备好采样新的输入数据。RFD信号在启动或复位时被设置为高信号。当选择了Word Serial架构时,RFD是必需的。否则,RFD将不存在。(此处没有这个端口)
RDY RDY(就绪)输出信号表明数据输出端口上存在新的有效数据样本。RDY在输出端有效数据的第一个时钟周期上被高脉冲。RDY信号在启动或复位时设置为低。当选择了Word Serial架构时,RDY是必需的。否则,RDY是可选的。
第一种情况,选择最优模式,正无穷模式


LIBRARY ieee;
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.numeric_std.all;
use IEEE.std_logic_unsigned.all;
use ieee.std_logic_arith.all;
LIBRARY XilinxCoreLib;
ENTITY chufa_tb IS
END chufa_tb;
ARCHITECTURE behavior OF chufa_tb IS
-- Component Declaration for the Unit Under Test (UUT)
COMPONENT chufa
PORT (
x_in : IN STD_LOGIC_VECTOR(15 DOWNTO 0);
nd : IN STD_LOGIC;
x_out : OUT STD_LOGIC_VECTOR(8 DOWNTO 0);
rdy : OUT STD_LOGIC;
clk : IN STD_LOGIC;
ce : IN STD_LOGIC
);
END COMPONENT;
signal x_in : STD_LOGIC_VECTOR(15 DOWNTO 0);
signal nd : STD_LOGIC;
signal x_out : STD_LOGIC_VECTOR(8 DOWNTO 0);
signal rdy : STD_LOGIC;
signal clk : STD_LOGIC;
signal ce : STD_LOGIC;
constant clk_period : time := 10 ns;
BEGIN
-- Instantiate the Unit Under Test (UUT)
uut: chufa
PORT MAP (
x_in => x_in,
nd => nd,
x_out => x_out,
rdy => rdy,
clk => clk,
ce => ce
);
-- Clock process definitions
clk_process :process
begin
clk <= '0';
wait for clk_period/2;
clk <= '1';
wait for clk_period/2;
end process;
-- Stimulus process
stim_proc: process
begin
nd <= '0';
ce <= '0';
wait for 100 ns;
x_in <= X"0004";
nd <= '1';
ce <= '1';
-- x2 <= X"0009";
wait for 60 ns;
x_in <= X"1004";
wait for 60 ns;
x_in <= X"0104";
wait for clk_period*10;
-- insert stimulus here
wait;
end process;
END;
可以看到延迟了6个时钟(该测试数据之下)
第二种情况,我将模式选择成了截断
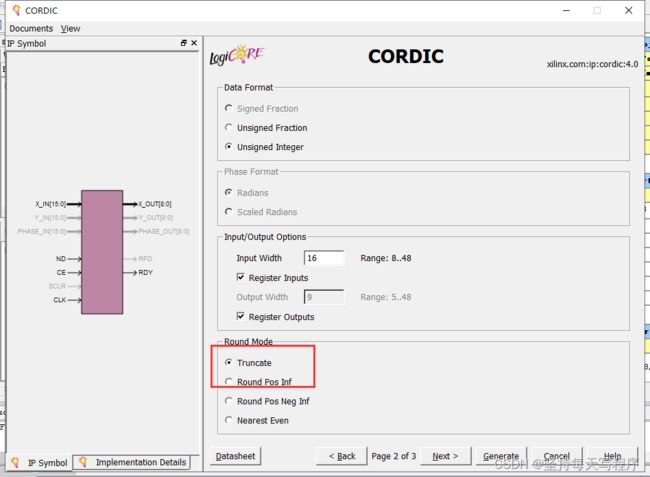
结果没有变化,延时也没有变化,还有延迟了大约6个周期(会不会跟输入的位宽有关系?)
我把输入位宽改成了32,现在的延时大约是10个周期

我改了一下测试文件里面的nd
stim_proc: process
begin
nd <= '0';
ce <= '0';
wait for 100 ns;
x_in <= X"00200004";
nd <= '1';
ce <= '1';
-- x2 <= X"0009";
wait for 90 ns;
nd <= '0';
wait for 10 ns;
nd <= '1';
x_in <= X"10031004";
wait for 90 ns;
nd <= '0';
wait for 10 ns;
x_in <= X"01600104";
nd <= '1';
wait for clk_period*10;

总结:对于fpga里面的计算时延,既然存在就是不可避免的,那么再进行级联计算的时候,
为了使一组数据在同一次计算中,我们可以使用一些使能信号和标志位,就像除法器和开方的ip核中,会有一个nd和rdy,那么我们只需要一开始给nd高信号,然后当计算完成,拉高rdy,然后判断rdy为高时,再去拉高前面一级运算的使能信号。之前一直没想到如果去改变初始的nd信号,今天老师提了一句状态机,好像有点灵感了,就是在第一个状态时,给nd使能,然后后面的rdy反馈回来时,就进入到第二个状态,也就是说在第一个状态里面初始化使能就好了,然后在后面几个状态里进行反馈循环。然后就是数据输入的问题,如果一组数据的话,就可以不考虑,但是如果是多组数据的话,我考虑的是两种办法,第一种是将数据寄存在寄存器里面,然后根据后面的计算延时,去看前面要寄存多少个时钟,也就是移位多少次。第二种就是,先判断出后面计算的延时有多少,可能前面处理完的数据,更新速度小于计算时延。
四、新建vhdl文件,将三种ip核联合起来使用,进行例化核程序编写: (由于位宽不同,我还建了一个除法器)

1.4个计算ip核的例化
vhdl代码如下:
----------------------------------------------------------------------------------
-- Create Date: 12:35:28 08/28/2022
-- Module Name: yunsuan2 - Behavioral
----------------------------------------------------------------------------------
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use ieee.std_logic_unsigned.all;
use ieee.std_logic_arith.all;
entity yunsuan2 is
PORT(
clk : IN std_logic; --clock
rst_n : IN std_logic; --reset
Nbkg : IN std_logic_vector(16 downto 0);
Tobs : IN std_logic_vector(2 downto 0);
ce : IN std_logic; --除法器 开方ip的时钟使能
nd1 : IN std_logic; --乘法器的使能
nd2 : IN std_logic; --第一个除法器的使能
Nobs: in std_logic_vector(11 downto 0);
Tbkg: in std_logic_vector(12 downto 0);
rdy_chuf1: OUT std_logic; --计算完成使能
Nobs_reg : OUT std_logic_vector(11 downto 0);
p : OUT std_logic
);
end yunsuan2;
architecture Behavioral of yunsuan2 is
--乘法器例化
COMPONENT chengfa1
PORT(
clk : IN std_logic;
a : IN std_logic_vector(16 downto 0);
b : IN std_logic_vector(2 downto 0);
ce : IN std_logic;
p : OUT std_logic_vector(19 downto 0)
);
END COMPONENT;
--除法器例化
component chufa
port (
clk: in std_logic;
ce: in std_logic;
nd: in std_logic;
rdy: out std_logic;
rfd: out std_logic;
dividend: in std_logic_vector(19 downto 0);
divisor: in std_logic_vector(12 downto 0);
quotient: out std_logic_vector(19 downto 0));
end component;
--开方例化
COMPONENT kaifang
PORT (
x_in : IN STD_LOGIC_VECTOR(19 DOWNTO 0);
nd : IN STD_LOGIC;
x_out : OUT STD_LOGIC_VECTOR(10 DOWNTO 0);
rdy : OUT STD_LOGIC;
clk : IN STD_LOGIC;
ce : IN STD_LOGIC
);
END COMPONENT;
--除法器例化
component chufa1
port (
clk: in std_logic;
ce: in std_logic;
nd: in std_logic;
rdy: out std_logic;
rfd: out std_logic;
dividend: in std_logic_vector(19 downto 0);
divisor: in std_logic_vector(10 downto 0);
quotient: out std_logic_vector(19 downto 0));
end component;
type yunsuan_state is (s0,s1,s2,s3,s4) ; --状态机状态
signal curr_state,next_state : yunsuan_state;
signal Nbkg_Tobs :std_logic_vector(19 downto 0):= (others => '0'); --Nbkg X Tobs的结果
signal Nbkg_Tobs_Tbkg: std_logic_vector(19 downto 0):= (others => '0'); --(Nbkg X Tobs)/ Tbkg的结果
signal rdy_chuf : std_logic:= '0'; --第一个除法器计算完的标志,连接下一个开方的使能
signal rdy_chuf1_reg: std_logic:= '0'; --寄存除法标志位,用于判断触发
signal Nobs_reg1 : std_logic_vector(19 downto 0):= (others => '0'); -- (X"00"&Nobs) - Nbkg_Tobs_Tbkg的结果;
signal xishu : std_logic_vector(19 downto 0):= (others => '0'); --最后除法运算完的结果,即系数
signal Nbkg_Tobs_Tbkg_kf : STD_LOGIC_VECTOR(10 DOWNTO 0):= (others => '0'); --开方完的结果
signal rdy_kaif : std_logic:= '0'; --开方计算完的标志,连接下一个除法器的使能
signal rfd1: std_logic:= '0';
signal rfd2: std_logic:= '0';
begin
chengf: chengfa1 PORT MAP (
clk => clk,
a => Nbkg,
b => Tobs,
ce => nd1,
p => Nbkg_Tobs
);
chuf : chufa port map (
clk => clk,
ce => ce,
nd => nd2,
rdy => rdy_chuf,
rfd => rfd1,
dividend => Nbkg_Tobs,
divisor => Tbkg,
quotient => Nbkg_Tobs_Tbkg);
kaif: kaifang PORT MAP (
x_in => Nbkg_Tobs_Tbkg,
nd => rdy_chuf,
x_out => Nbkg_Tobs_Tbkg_kf,
rdy => rdy_kaif,
clk => clk,
ce => ce
);
chuf1 : chufa1 port map (
clk => clk,
ce => ce,
nd => rdy_kaif,
rdy => rdy_chuf1_reg,
rfd => rfd2,
dividend => Nobs_reg1,
divisor => Nbkg_Tobs_Tbkg_kf,
quotient => xishu);
--计算分子的减法
rdy_chuf1 <= rdy_chuf1_reg;
process (clk,rst_n,rdy_chuf1_reg)
begin
if (rst_n = '1') then
Nobs_reg1 <= (others=> '0');
elsif (rising_edge(clk)) then
if (rdy_chuf = '1') then
if ((X"00"&Nobs) > Nbkg_Tobs_Tbkg) then
Nobs_reg1 <= (X"00"&Nobs) - Nbkg_Tobs_Tbkg;
else
Nobs_reg1 <=(others=> '0');
end if;
end if;
end if;
end process;
--根据最后的系数,判断是否触发使能
process (clk,rst_n,xishu)
begin
if (rst_n = '1') then
p <= '0';
Nobs_reg <= (others=> '0');
elsif (rising_edge(clk)) then
if (rdy_chuf1_reg = '1' and xishu > X"00004") then
p <= '1';
Nobs_reg <= Nobs;
else
Nobs_reg <= (others=> '0');
p <= '0';
end if;
end if;
end process;
end Behavioral;
2.ip核之间的使能
----------------------------------------------------------------------------------
-- Create Date: 10:38:15 08/31/2022
-- Module Name: enable - Behavioral
----------------------------------------------------------------------------------
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
entity enable is
PORT(
clk : IN std_logic;
rst_n : IN std_logic;
yunsuan_flag : IN std_logic; --开始计算使能
nd1 : OUT std_logic; --输出乘法器使能
nd2 : OUT std_logic; --输出除法器使能
rdy_chuf1: IN std_logic --上一次运算完成标志
);
end enable;
architecture Behavioral of enable is
type type_state is (s1,s2,s3,s4,s5);
signal state: type_state;
begin
comb : process(clk,rst_n,state)
begin
if(rst_n = '1') then
state <= s1;
nd1 <= '0';
nd2 <= '0';
elsif (rising_edge(clk)) then
case state is
when s1 =>
if (yunsuan_flag = '1') then --开始计算标志
nd1 <= '1';
state <= s2;
else
state <= s1;
end if;
when s2 =>
nd1 <= '0';
state <= s3;
when s3 =>
nd2 <= '1';
state <= s4;
when s4 =>
nd2 <= '0';
state <= s5;
when s5 =>
if (rdy_chuf1 = '1') then --计算完成标志
state <= s1;
else
state <= s5;
end if;
when others =>
nd1 <= '0';
nd2 <= '0';
state <= s1;
end case;
end if;
end process;
end Behavioral;
3.顶层例化
----------------------------------------------------------------------------------
-- Create Date: 10:50:27 08/31/2022
-- Design Name: 顶层例化
-- Module Name: yunsuan2_enable - Behavioral
----------------------------------------------------------------------------------
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
entity yunsuan2_enable is
PORT(
clk : IN std_logic;
rst_n : IN std_logic;
Nbkg : IN std_logic_vector(16 downto 0);
Tobs : IN std_logic_vector(2 downto 0);
ce : IN std_logic;
yunsuan_flag : IN std_logic;
Nobs: in std_logic_vector(11 downto 0);
Tbkg: in std_logic_vector(12 downto 0);
Nobs_reg : OUT std_logic_vector(11 downto 0);
p : OUT std_logic
);
end yunsuan2_enable;
architecture Behavioral of yunsuan2_enable is
COMPONENT yunsuan2
PORT(
clk : IN std_logic;
rst_n : IN std_logic;
Nbkg : IN std_logic_vector(16 downto 0);
Tobs : IN std_logic_vector(2 downto 0);
ce : IN std_logic;
nd1 : IN std_logic;
nd2 : IN std_logic;
Nobs : IN std_logic_vector(11 downto 0);
Tbkg : IN std_logic_vector(12 downto 0);
rdy_chuf1 : OUT std_logic;
Nobs_reg : OUT std_logic_vector(11 downto 0);
p : OUT std_logic
);
END COMPONENT;
COMPONENT enable
PORT(
clk : IN std_logic;
rst_n : IN std_logic;
yunsuan_flag : IN std_logic;
rdy_chuf1 : IN std_logic;
nd1 : OUT std_logic;
nd2 : OUT std_logic
);
END COMPONENT;
signal nd1_reg: std_logic;
signal nd2_reg: std_logic;
signal rdy_chuf1_reg: std_logic;
begin
u0: yunsuan2 PORT MAP(
clk => clk,
rst_n => rst_n,
Nbkg => Nbkg,
Tobs => Tobs,
ce => ce,
nd1 => nd1_reg,
nd2 => nd2_reg,
Nobs_reg => Nobs_reg,
Nobs => Nobs,
Tbkg => Tbkg,
rdy_chuf1 => rdy_chuf1_reg,
p => p
);
u1: enable PORT MAP(
clk => clk,
rst_n => rst_n,
yunsuan_flag => yunsuan_flag,
nd1 => nd1_reg,
nd2 => nd2_reg,
rdy_chuf1 => rdy_chuf1_reg
);
end Behavioral;
4.测试文件
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
ENTITY yunsuan2_enable_tb IS
END yunsuan2_enable_tb;
ARCHITECTURE behavior OF yunsuan2_enable_tb IS
-- Component Declaration for the Unit Under Test (UUT)
COMPONENT yunsuan2_enable
PORT(
clk : IN std_logic;
rst_n : IN std_logic;
Nbkg : IN std_logic_vector(16 downto 0);
Tobs : IN std_logic_vector(2 downto 0);
ce : IN std_logic;
yunsuan_flag : IN std_logic;
Nobs : IN std_logic_vector(11 downto 0);
Nobs_reg : OUT std_logic_vector(11 downto 0);
Tbkg : IN std_logic_vector(12 downto 0);
p : OUT std_logic
);
END COMPONENT;
--Inputs
signal clk : std_logic := '0';
signal rst_n : std_logic := '0';
signal Nbkg : std_logic_vector(16 downto 0) := (others => '0');
signal Tobs : std_logic_vector(2 downto 0) := (others => '0');
signal ce : std_logic := '0';
signal yunsuan_flag : std_logic := '0';
signal Nobs : std_logic_vector(11 downto 0) := (others => '0');
signal Nobs_reg : std_logic_vector(11 downto 0) := (others => '0');
signal Tbkg : std_logic_vector(12 downto 0) := (others => '0');
--Outputs
signal p : std_logic;
-- Clock period definitions
constant clk_period : time := 10 ns;
BEGIN
-- Instantiate the Unit Under Test (UUT)
uut: yunsuan2_enable PORT MAP (
clk => clk,
rst_n => rst_n,
Nbkg => Nbkg,
Tobs => Tobs,
ce => ce,
yunsuan_flag => yunsuan_flag,
Nobs => Nobs,
Nobs_reg => Nobs_reg,
Tbkg => Tbkg,
p => p
);
-- Clock process definitions
clk_process :process
begin
clk <= '0';
wait for clk_period/2;
clk <= '1';
wait for clk_period/2;
end process;
-- Stimulus process
stim_proc: process
begin
ce <= '0';
rst_n <= '1';
wait for 15 ns;
ce <= '1';
rst_n <= '0';
yunsuan_flag <= '1';
Tbkg <= '0'&X"9C4";--2500
Tobs <= "101"; --5
Nbkg <= '1'&X"86C6"; --100038
Nobs <= X"3D8"; --984
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nobs <= X"0D4"; --212
Nbkg <= '1'&X"86D4";--100052
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"86E6"; --100070
Nobs <= X"0D4"; --212
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"86CE"; --100046
Nobs <= X"0C1"; --193
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"86C6"; --100038
Nobs <= X"3D8"; --984
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"86DC"; --100060
Nobs <= X"0DE"; --222
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"870F"; --100111
Nobs <= X"0C4"; --196
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"86C6"; --100103
Nobs <= X"309"; --777
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"8707"; --100125
Nobs <= X"0E2"; --226
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"874A"; --100170
Nobs <= X"0C9"; --201
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"875D"; --100189
Nobs <= X"4B5"; --1205
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
yunsuan_flag <= '1';
Nbkg <= '1'&X"8762"; --100194
Nobs <= X"0BC"; --188
wait for 10 ns;
yunsuan_flag <= '0';
wait for 200 ns;
wait;
end process;
END;
5.rtl图:
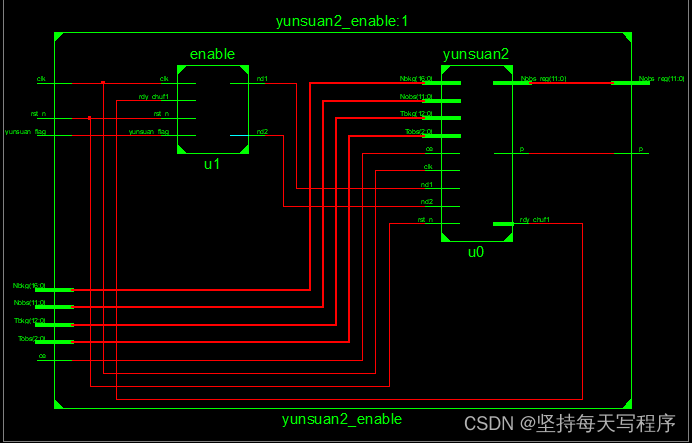
6.仿真图:

7.这是在写状态机时遇到的问题
在网上看有一个分析是这样的,我本来时用的两段式状态机去写ip核之间的使能的,但是一直只能进行一次循环,然后就卡在那了,然后问了老师,就说改成一段式试一下,然后就可以了,但是逻辑什么的,真的一点没变,我也不是很懂之间的区别,下图时网上看到的一个分析
