Hash functions are by definition and implementation pseudo random number generators (PRNG). From this generalization its generally accepted that the performance of hash functions and also comparisons between hash functions can be achieved by treating hash function as PRNGs. Analysis techniques such a Poisson distribution can be used to analyze the collision rates of different hash functions for different groups of data. In general there is a theoretical hash function known as the perfect hash function for any group of data. The perfect hash function by definition states that no collisions will occur meaning no repeating hash values will arise from different elements of the group. In reality its very difficult to find a perfect hash function and the practical applications of perfect hashing and its variant minimal perfect hashing are quite limited. In practice it is generally recognized that a perfect hash function is the hash function that produces the least amount of collisions for a particular set of data. The problem is that there are so many permutations of types of data, some highly random, others containing high degrees of patterning that its difficult to generalize a hash function for all data types or even for specific data types. All one can do is via trial and error find the hash function that best suites their needs. Some dimensions to analyze for choosing hash functions are:
-
Data Distribution This is the measure of how well the hash function distributes the hash values of elements within a set of data. Analysis in this measure requires knowing the number of collisions that occur with the data set meaning non-unique hash values, If chaining is used for collision resolution the average length of the chains (which would in theory be the average of each bucket's collision count) analyzed, also the amount of grouping of the hash values within ranges should be analyzed.
-
Hash Function Efficiency This is the measure of how efficiently the hash function produces hash values for elements within a set of data. When algorithms which contain hash functions are analyzed it is generally assumed that hash functions have a complexity of O(1), that is why look-ups for data in a hash-table are said to be on "average of O(1) complexity", where as look-ups of data in associative containers such as maps (typically implemented as Red-Black trees) are said to be of O(logn) complexity. A hash function should in theory be a very quick, stable and deterministic operation. A hash function may not always lend itself to being of O(1) complexity, however in general the linear traversal through a string of data to be hashed is so quick and the fact that hash functions are generally used on primary keys which by definition are supposed to be much smaller associative identifiers of larger blocks of data implies that the whole operation should be quick and to a certain degree stable.
The hash functions in this essay are known as simple hash functions. They are typically used for data hashing (string hashing). They are used to create keys which are used in associative containers such as hash-tables. These hash functions are not cryptographically safe, they can easily be reversed and many different combinations of data can be easily found to produce identical hash values for any combination of data. Hash functions are typically defined by the way they create hash values from data. There are two main methodologies for a hash algorithm to implement, they are:
-
Addative and Multiplicative Hashing This is where the hash value is constructed by traversing through the data and continually incrementing an initial value by a calculated value relative to an element within the data. The calculation done on the element value is usually in the form of a multiplication by a prime number.
-
Rotative Hashing Same as additive hashing in that every element in the data string is used to construct the hash, but unlike additive hashing the values are put through a process of bitwise shifting. Usually a combination of both left and right shifts, the shift amounts as before are prime. The result of each process is added to some form of accumulating count, the final result being the hash value is passed back as the final accumulation. 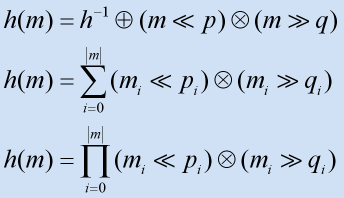
There isn't much real mathematical work which can definitely prove the relationship between prime numbers and pseudo random number generators. Nevertheless, the best results have been found to include the use of prime numbers. PRNGs are currently studied as a statistical entity, they are not study as deterministic entities hence any analysis done can only bare witness to the overall result rather than to determine how and or why the result came into being. If a more discrete analysis could be carried out, one could better understand what prime numbers work better and why they work better, and at the same time why other prime numbers don't work as well, answering these questions with stable, repeatable proofs can better equip one for designing better PRNGs and hence eventually better hash functions. The basic concepts surrounding the use of prime numbers in hash functions revolve around the concept of operating the current state value of the hash function with a prime number as opposed to another type of number. The term operate means something as simple as applying some form of mathematical operation such as multiplication or addition to the hash value. The result being a new hash value that should statistically have a higher entropic value or in other words a very low bit-bias for any of the bits in the new hash value. In simple terms when you multiply a set of random numbers by a prime number the resulting numbers when analyzed at their bit levels should show no bias towards being one state or another ie: Pr(Bi = 1) ~= 0.5. There is no concrete proof that this is the case or that it only happens with prime numbers, it just seems to be an ongoing self-proclaimed intuition that some professionals in the field seem obligied to follow. Deciding what is the right or even better yet the best possible combination of hashing methodologies and use of prime numbers is still very much a black art. No single methodology can lay claim to being the ultimate general purpose hash function. The best one can do is to evolve via trial and error and statistical analysis methods for obtaining suitable hashing algorithms that meet their needs.
Bit sequence generators, be them purely random or in some way deterministic, will generate bits with a particular probability of either being one state or another - this probability is known as the bit bias. In the case of purely random generators the bit bias of any generated bit being high or low is always 50% (Pr=0.5). However in the case of pseudo random number generators, the algorithm generating the bits will define the bit bias of the bits generated in the minimal output block of the generator. 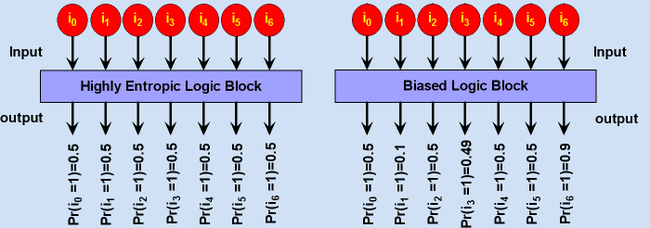 Assume a PRNG that produces 8 bit blocks as its output. For some reason the MSB is always set to high, the bit bias then for the MSB will be a probability of 100% being set high. From this one concludes that even though there are 256 possible values that can be produced with this PRNG, values less than 128 will never be generated. Assuming for simplicity the other bits being generated are purely random, then there is equal chance that any value between 128 and 255 will be generated, however at the same time, there is 0% chance that a value less than 128 will be produced. All PRNGs, be they the likes of hash functions, ciphers, msequences or anything else that produces a bit sequence will all possess a unique bit bias. Most PRNGs will attempt to converge their bit biases to an equality, stream ciphers are one example, whereas others will work best with a known yet unstable bit bias. Mixing or scrambling of a bit sequence is one way of producing a common equality in the bit bias of a stream. Though one must be careful to ensure that by mixing they do not further diverge the bit biases. A form of mixing used in cryptography is known as avalanching, this is where a block of bits are mixed together sometimes using a substitution or permutation box, with another block to produce an output that will be used to mix with yet another block. As displayed in the figure below the avalanching process begins with one or more pieces of binary data. Bits in the data are taken and operated upon (usually some form of input sensitive bit reducing bitwise logic) producing an ith-tier piece data. The process is then repeated on the ith-tier data to produce an i+1'th tier data where the number of bits in the current tier will be less than or equal to the number of bits in the previous tier. The culmination of this repeated process will result in one bit whos value is said to be dependent upon all the bits from the original piece(s) of data. It should be noted that the figure below is a mere generalisation of the avalanching process and need not necessarily be the only form of the process. 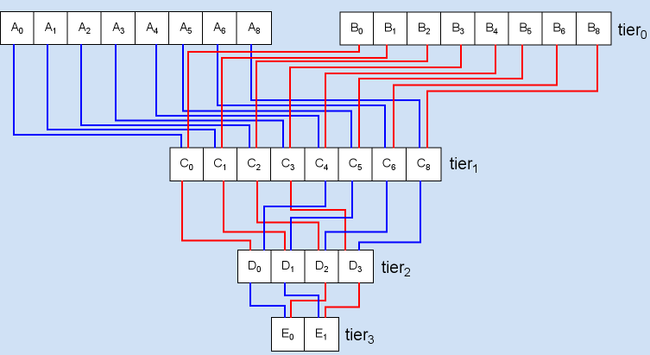 In data communications that use block code based error correcting codes, it has been seen that to overcome burst errors, that is when there is a large amount of noise for a very short period of time in the carrier channel, if one were to bit-scramble whole code blocks with each other, then have the scrambled form transmitted and then descrambled at the other end that burst errors would then most likely be distributed almost evenly over then entire sequence of blocks transmitted allowing for a much higher chance of fully detecting and correcting all errors. This type of deterministic scrambling and descrambling without the need for a common key is known as interleaving and deinterleaving.
Hashing as a tool to associate one set or bulk of data with an identifier has many different forms of application in the real-world. Below are some of the more common uses of hash functions.
-
Used in the area of data storage access. Mainly within indexing of data and as a structural back end to associative containers(ie: hash tables)
-
Used for data/user verification and authentication. A strong cryptographic hash function has the property of being very difficult to reverse the result of the hash and hence reproduce the original piece of data. Cryptographic hash functions are used to hash user's passwords and have the hash of the passwords stored on a system rather than having the password itself stored. Cryptographic hash functions are also seen as irreversible compression functions, being able to represent large quantities of data with a signal ID, they are useful in seeing whether or not the data has been tampered with, and can also be used as data one signes in order to prove authenticity of a document via other cryptographic means.
-
This form of hashing is used in the field of computer vision for the detection of classified objects in arbitrary scenes. The process involves initially selecting a region or object of interest. From there using affine invariant feature detection algorithms such as the Harris corner detector (HCD), Scale-Invariant Feature Transform (SIFT) or Speeded-Up Robust Features (SURF), a set of affine features are extracted which are deemed to represent said object or region. This set is sometimes called a macro-feature or a constellation of features. Depending on the nature of the features detected and the type of object or region being classified it may still be possible to match two constellations of features even though there may be minor disparities (such as missing or outlier features) between the two sets. The constellations are then said to be the classified set of features. A hash value is computed from the constellation of features. This is typically done by initially defining a space where the hash values are intended to reside - the hash value in this case is a multidimensional value normalized for the defined space. Coupled with the process for computing the hash value another process that determines the distance between two hash values is needed - A distance measure is required rather than a deterministic equality operator due to the issue of possible disparities of the constellations that went into calculating the hash value. Also owing to the non-linear nature of such spaces the simple Euclidean distance metric is essentially ineffective, as a result the process of automatically determining a distance metric for a particular space has become an active field of research in academia. Typical examples of geometric hashing include the classification of various kinds of automobiles, for the purpose of re-detection in arbitrary scenes. The level of detection can be varied from just detecting a vehicle, to a particular model of vehicle, to a specific vehicle.
-
A Bloom filter allows for the "state of existence" of a large set of possible values to be represented with a much smaller piece of memory than the sum size of the values. In computer science this is known as a membership query and is core concept in associative containers. The Bloom filter achieves this through the use of multiple distinct hash functions and also by allowing the result of a membership query for the existence of a particular value to have a certain probability of error. The guarantee a Bloom filter provides is that for any membership query there will never be any false negatives, however there may be false positives. The false positive probability can be controlled by varying the size of the table used for the Bloom filter and also by varying the number of hash functions. Subsequent research done in the area of hash functions and tables and bloom filters by Mitzenmacher et al. suggest that for most practical uses of such constructs, the entropy in the data being hashed contributes to the entropy of the hash functions, this further leads onto theoretical results that conclude an optimal bloom filter (one which provides the lowest false positive probability for a given table size or vice versa) providing a user defined false positive probability can be constructed with at most two distinct hash functions also known as pairwise independent hash functions, greatly increasing the efficiency of membership queries. Bloom filters are commonly found in applications such as spell-checkers, string matching algorithms, network packet analysis tools and network/internet caches.
The General Hash Functions Library has the following mix of additive and rotative general purpose string hashing algorithms. The following algorithms vary in usefulness and functionality and are mainly intended as an example for learning how hash functions operate and what they basically look like in code form.
-
A simple hash function from Robert Sedgwicks Algorithms in C book. I've added some simple optimizations to the algorithm in order to speed up its hashing process.
-
A bitwise hash function written by Justin Sobel
-
This hash algorithm is based on work by Peter J. Weinberger of AT&T Bell Labs. The book Compilers (Principles, Techniques and Tools) by Aho, Sethi and Ulman, recommends the use of hash functions that employ the hashing methodology found in this particular algorithm.
-
Similar to the PJW Hash function, but tweaked for 32-bit processors. Its the hash function widely used on most UNIX systems.
-
This hash function comes from Brian Kernighan and Dennis Ritchie's book "The C Programming Language". It is a simple hash function using a strange set of possible seeds which all constitute a pattern of 31....31...31 etc, it seems to be very similar to the DJB hash function.
-
This is the algorithm of choice which is used in the open source SDBM project. The hash function seems to have a good over-all distribution for many different data sets. It seems to work well in situations where there is a high variance in the MSBs of the elements in a data set.
-
An algorithm produced by Professor Daniel J. Bernstein and shown first to the world on the usenet newsgroup comp.lang.c. It is one of the most efficient hash functions ever published.
-
An algorithm proposed by Donald E. Knuth in The Art Of Computer Programming Volume 3, under the topic of sorting and search chapter 6.4.
-
An algorithm produced by me Arash Partow. I took ideas from all of the above hash functions making a hybrid rotative and additive hash function algorithm. There isn't any real mathematical analysis explaining why one should use this hash function instead of the others described above other than the fact that I tired to resemble the design as close as possible to a simple LFSR. An empirical result which demonstrated the distributive abilities of the hash algorithm was obtained using a hash-table with 100003 buckets, hashing The Project Gutenberg Etext of Webster's Unabridged Dictionary, the longest encountered chain length was 7, the average chain length was 2, the number of empty buckets was 4579. Below is a simple algebraic description of the AP hash function: 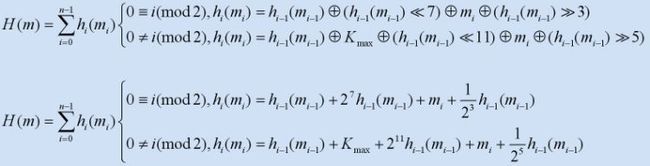
Note: For uses where high throughput is a requirement for computing hashes using the algorithms described above, one should consider unrolling the internal loops and adjusting the hash value memory foot-print to be appropriate for the targeted architecture(s).
Free use of the General Hash Functions Algorithm Library available on this site is permitted under the guidelines and in accordance with the most current version of the "Common Public License."
The General Hash Functions Algorithm Library C & C++ implementation is compatible with the following C & C++ compilers:
- GNU Compiler Collection (3.3.1-x+)
- Intel® C++ Compiler (8.x+)
- Clang/LLVM (1.x+)
- Microsoft Visual C++ Compiler (8.x+)
The General Hash Functions Algorithm Library Object Pascal and Pascal implementations are compatible with the following Object Pascal and Pascal compilers:
- Borland Delphi (1,2,3,4,5,6,7,8,2005,2006)
- Free Pascal Compiler (1.9.x)
- Borland Kylix (1,2,3)
- Borland Turbo Pascal (5,6,7)
The General Hash Functions Algorithm Library Java implementation is compatible with the following Java compilers:
- Sun Microsystems Javac (J2SE1.4+)
- GNU Java Compiler (GJC)
- IBM Java Compiler
 |