KDTree详解及java实现
本文内容基于An introductory tutoril on kd-trees
1.KDTree介绍
KDTree根据m维空间中的数据集D构建的二叉树,能加快常用于最近邻查找(在加快k-means算法中有应用)。
其节点具有如下属性(对应第5节中的程序实现):
非叶子节点(不存储数据):
| partitionDimention |
用于分割的维度,取值范围为1,2,…,m |
| partitionValue |
用于分割的值v,当数据点在维度partitionDimention上的值小于v时,被分到左节点,否则分到右节点 |
| left |
左节点,使用分到该节点的数据集构建 |
| right |
右节点 |
| Max(以及min,是加快最近邻查找的关键,在第3节会讲到) |
用于构建该节点的数据集(也可以说是该节点的所有叶子节点包含的数据组成的数据集)在各个维度上的最大值组成的d维向量 |
| Min |
用于构建该节点的数据集在各个维度上的最小值组成的d维向量 |
叶子节点:
| value |
存储的数据(只存储一个数据) |
private class Node{ //分割的维度 int partitionDimention; //分割的值 double partitionValue; //如果为非叶子节点,该属性为空 //否则为数据 double[] value; //是否为叶子 boolean isLeaf=false; //左树 Node left; //右树 Node right; //每个维度的最小值 double[] min; //每个维度的最大值 double[] max; }
2.KDTree构建
输入:数据集D
输出:KDTree
| a.如果D为空,返回空的KDTree |
| b.新建节点node |
| c.如果D只有一个数据或D中数据全部相同 将node标记为叶子节点 |
| d.否则将node标记为非叶子节点 取各维度上的最大最小值分别生成Max和Min 遍历m个维度,找到方差最大的维度作为partitionDimention 取数据集在partitionDimention维度上排序后的中点作为partitionValue |
| e.将数据集中在维度partitionDimention上小于partitionValue的划分为D1, 其他数据点作为D2 用数据集D1,循环a–e步,生成node的左树 用数据集D2,循环a–e步,生成node的右树 |
以数据集 (2,3),(5,4),(4,7),(8,1),(7,2),(9,2) 为例子
| a.D非空,跳到b |
| b.新建节点node |
| c.D有6个数据,且不相同,跳到d |
| d.标记node为非叶子节点 在第一个维度上(数组[2,5,4,8,7,9])计算方差得到5.8 在第二个维度上(数组[3,4,7,1,2,2])计算方差得到3.8 第一个维度上方差较大,所以partitionDimention=0 在第一个维度上排序([2,4,5,7,8, 9])取中点7作为分割点,partitionValue=7
两个维度上的最大值为[9,7]作为Max,两个维度上的最小值[2,1]作为Min |
| e.数据集D,在第一个维度上小于7的分入D1:(2,3),(5,4),(4,7) 大于等于7的分入D2:(8,1),(7,2),(9,2) 用D1构建左树,用D2构建右树
|
if(data.size()==1){ node.isLeaf=true; node.value=data.get(0); return; } //选择方差最大的维度 node.partitionDimention=-1; double var = -1; double tmpvar; for(int i=0;i<dimentions;i++){ tmpvar=UtilZ.variance(data, i); if (tmpvar>var){ var = tmpvar; node.partitionDimention = i; } } //如果方差=0,表示所有数据都相同,判定为叶子节点 if(var==0){ node.isLeaf=true; node.value=data.get(0); return; } //选择分割的值 node.partitionValue=UtilZ.median(data, node.partitionDimention); double[][] maxmin=UtilZ.maxmin(data, dimentions); node.min = maxmin[0]; node.max = maxmin[1]; int size = (int)(data.size()*0.55); ArrayList<double[]> left = new ArrayList<double[]>(size); ArrayList<double[]> right = new ArrayList<double[]>(size); for(double[] d:data){ if (d[node.partitionDimention]<node.partitionValue) { left.add(d); }else { right.add(d); } } Node leftnode = new Node(); Node rightnode = new Node(); node.left=leftnode; node.right=rightnode; buildDetail(leftnode, left, dimentions); buildDetail(rightnode, right, dimentions);
3.KDTree最近邻查找
KDTree能实现快速查找的原因:
一个节点下的所有叶子节点包含的数据所处的范围可以用一个矩形框住(数据为二维),对应到的属性就是Max和Min
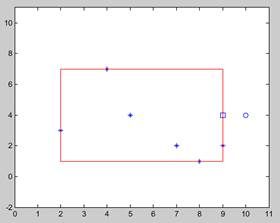
图中*为(2,3),(5,4),(4,7),(8,1),(7,2),(9,2),可以用[9,7]和[2,1]框住
此时,判断方框中是否有和点o (10,4),距离小于t的点
通过以下方法可以初步判断:
方框到o的距离最小的点,为图中的正方形表示的点(9,4)
10>9 第一个维度为9, 1<4<7 ,第二个维度为4
当找到一个相对较近的点,得到距离t后,只需要在树中找到距离比t小的点,此时如果上面的距离大于t,就可以略过这个节点,从而减少很多计算
查询步骤:
输入:查询点input
1. 从根节点出发,根据partitionDimention、partitionValue一路向下直到叶子节点
并一路将路过节点外的其他节点加入栈中(如果进入左节点,就把右节点加入栈中)
用叶子节点上的值作为一个找到的初步最近邻,记为nearest,和input的距离为distance
2. 若栈为空,返回nearest作为最近邻
3. 否则从栈中取出节点node
4. 若此节点为叶子节点,计算它和input的距离tmpdis,若tmpdis<input
更新distance=tmpdis,nearest=node.value
5. 若此节点为非叶子节点,使用Max和Min构建以下数据点h:
h[i]= Max[i],若input[i]>Max[i]
= Min[i],若input[i]<Min[i]
= input[i],若 Min[i]<input[i]< Max[i]
计算h到t的距离dis
6. 若dis>=t,回到第2步
7. 若dis<t,根据partitionDimention、partitionValue一路向下直到叶子节点
并一路将路过节点外的其他节点加入栈中(如果进入左节点,就把右节点加入栈中)
8. 计算它和input的距离tmpdis,若tmpdis<input
更新distance=tmpdis,nearest=node.value
进入第2步
double[] nearest = null; Node node = null; double tdis; while(stack.size()!=0){ node = stack.pop(); if(node.isLeaf){ tdis=UtilZ.distance(input, node.value); if(tdis<distance){ distance = tdis; nearest = node.value; } }else { /* * 得到该节点代表的超矩形中点到查找点的最小距离mindistance * 如果mindistance<distance表示有可能在这个节点的子节点上找到更近的点 * 否则不可能找到 */ double mindistance = UtilZ.mindistance(input, node.max, node.min); if (mindistance<distance) { while(!node.isLeaf){ if(input[node.partitionDimention]<node.partitionValue){ stack.add(node.right); node=node.left; }else{ stack.push(node.left); node=node.right; } } tdis=UtilZ.distance(input, node.value); if(tdis<distance){ distance = tdis; nearest = node.value; } } } } return nearest;
4.KDTree实现
可以发现当数据量是10000时,kdtree比线性查找要块134倍
datasize:10000;iteration:100000
kdtree:468
linear:63125
linear/kdtree:134.88247863247864
import java.util.ArrayList; import java.util.Stack; public class KDTree { private Node kdtree; private class Node{ //分割的维度 int partitionDimention; //分割的值 double partitionValue; //如果为非叶子节点,该属性为空 //否则为数据 double[] value; //是否为叶子 boolean isLeaf=false; //左树 Node left; //右树 Node right; //每个维度的最小值 double[] min; //每个维度的最大值 double[] max; } private static class UtilZ{ /** * 计算给定维度的方差 * @param data 数据 * @param dimention 维度 * @return 方差 */ static double variance(ArrayList<double[]> data,int dimention){ double vsum = 0; double sum = 0; for(double[] d:data){ sum+=d[dimention]; vsum+=d[dimention]*d[dimention]; } int n = data.size(); return vsum/n-Math.pow(sum/n, 2); } /** * 取排序后的中间位置数值 * @param data 数据 * @param dimention 维度 * @return */ static double median(ArrayList<double[]> data,int dimention){ double[] d =new double[data.size()]; int i=0; for(double[] k:data){ d[i++]=k[dimention]; } return findPos(d, 0, d.length-1, d.length/2); } static double[][] maxmin(ArrayList<double[]> data,int dimentions){ double[][] mm = new double[2][dimentions]; //初始化 第一行为min,第二行为max for(int i=0;i<dimentions;i++){ mm[0][i]=mm[1][i]=data.get(0)[i]; for(int j=1;j<data.size();j++){ double[] d = data.get(j); if(d[i]<mm[0][i]){ mm[0][i]=d[i]; }else if(d[i]>mm[1][i]){ mm[1][i]=d[i]; } } } return mm; } static double distance(double[] a,double[] b){ double sum = 0; for(int i=0;i<a.length;i++){ sum+=Math.pow(a[i]-b[i], 2); } return sum; } /** * 在max和min表示的超矩形中的点和点a的最小距离 * @param a 点a * @param max 超矩形各个维度的最大值 * @param min 超矩形各个维度的最小值 * @return 超矩形中的点和点a的最小距离 */ static double mindistance(double[] a,double[] max,double[] min){ double sum = 0; for(int i=0;i<a.length;i++){ if(a[i]>max[i]) sum += Math.pow(a[i]-max[i], 2); else if (a[i]<min[i]) { sum += Math.pow(min[i]-a[i], 2); } } return sum; } /** * 使用快速排序,查找排序后位置在point处的值 * 比Array.sort()后去对应位置值,大约快30% * @param data 数据 * @param low 参加排序的最低点 * @param high 参加排序的最高点 * @param point 位置 * @return */ private static double findPos(double[] data,int low,int high,int point){ int lowt=low; int hight=high; double v = data[low]; ArrayList<Integer> same = new ArrayList<Integer>((int)((high-low)*0.25)); while(low<high){ while(low<high&&data[high]>=v){ if(data[high]==v){ same.add(high); } high--; } data[low]=data[high]; while(low<high&&data[low]<v) low++; data[high]=data[low]; } data[low]=v; int upper = low+same.size(); if (low<=point&&upper>=point) { return v; } if(low>point){ return findPos(data, lowt, low-1, point); } int i=low+1; for(int j:same){ if(j<=low+same.size()) continue; while(data[i]==v) i++; data[j]=data[i]; data[i]=v; i++; } return findPos(data, low+same.size()+1, hight, point); } } private KDTree() {} /** * 构建树 * @param input 输入 * @return KDTree树 */ public static KDTree build(double[][] input){ int n = input.length; int m = input[0].length; ArrayList<double[]> data =new ArrayList<double[]>(n); for(int i=0;i<n;i++){ double[] d = new double[m]; for(int j=0;j<m;j++) d[j]=input[i][j]; data.add(d); } KDTree tree = new KDTree(); tree.kdtree = tree.new Node(); tree.buildDetail(tree.kdtree, data, m); return tree; } /** * 循环构建树 * @param node 节点 * @param data 数据 * @param dimentions 数据的维度 */ private void buildDetail(Node node,ArrayList<double[]> data,int dimentions){ if(data.size()==1){ node.isLeaf=true; node.value=data.get(0); return; } //选择方差最大的维度 node.partitionDimention=-1; double var = -1; double tmpvar; for(int i=0;i<dimentions;i++){ tmpvar=UtilZ.variance(data, i); if (tmpvar>var){ var = tmpvar; node.partitionDimention = i; } } //如果方差=0,表示所有数据都相同,判定为叶子节点 if(var==0){ node.isLeaf=true; node.value=data.get(0); return; } //选择分割的值 node.partitionValue=UtilZ.median(data, node.partitionDimention); double[][] maxmin=UtilZ.maxmin(data, dimentions); node.min = maxmin[0]; node.max = maxmin[1]; int size = (int)(data.size()*0.55); ArrayList<double[]> left = new ArrayList<double[]>(size); ArrayList<double[]> right = new ArrayList<double[]>(size); for(double[] d:data){ if (d[node.partitionDimention]<node.partitionValue) { left.add(d); }else { right.add(d); } } Node leftnode = new Node(); Node rightnode = new Node(); node.left=leftnode; node.right=rightnode; buildDetail(leftnode, left, dimentions); buildDetail(rightnode, right, dimentions); } /** * 打印树,测试时用 */ public void print(){ printRec(kdtree,0); } private void printRec(Node node,int lv){ if(!node.isLeaf){ for(int i=0;i<lv;i++) System.out.print("--"); System.out.println(node.partitionDimention+":"+node.partitionValue); printRec(node.left,lv+1); printRec(node.right,lv+1); }else { for(int i=0;i<lv;i++) System.out.print("--"); StringBuilder s = new StringBuilder(); s.append('('); for(int i=0;i<node.value.length-1;i++){ s.append(node.value[i]).append(','); } s.append(node.value[node.value.length-1]).append(')'); System.out.println(s); } } public double[] query(double[] input){ Node node = kdtree; Stack<Node> stack = new Stack<Node>(); while(!node.isLeaf){ if(input[node.partitionDimention]<node.partitionValue){ stack.add(node.right); node=node.left; }else{ stack.push(node.left); node=node.right; } } /** * 首先按树一路下来,得到一个想对较近的距离,再找比这个距离更近的点 */ double distance = UtilZ.distance(input, node.value); double[] nearest=queryRec(input, distance, stack); return nearest==null? node.value:nearest; } public double[] queryRec(double[] input,double distance,Stack<Node> stack){ double[] nearest = null; Node node = null; double tdis; while(stack.size()!=0){ node = stack.pop(); if(node.isLeaf){ tdis=UtilZ.distance(input, node.value); if(tdis<distance){ distance = tdis; nearest = node.value; } }else { /* * 得到该节点代表的超矩形中点到查找点的最小距离mindistance * 如果mindistance<distance表示有可能在这个节点的子节点上找到更近的点 * 否则不可能找到 */ double mindistance = UtilZ.mindistance(input, node.max, node.min); if (mindistance<distance) { while(!node.isLeaf){ if(input[node.partitionDimention]<node.partitionValue){ stack.add(node.right); node=node.left; }else{ stack.push(node.left); node=node.right; } } tdis=UtilZ.distance(input, node.value); if(tdis<distance){ distance = tdis; nearest = node.value; } } } } return nearest; } /** * 线性查找,用于和kdtree查询做对照 * 1.判断kdtree实现是否正确 * 2.比较性能 * @param input * @param data * @return */ public static double[] nearest(double[] input,double[][] data){ double[] nearest=null; double dis = Double.MAX_VALUE; double tdis; for(int i=0;i<data.length;i++){ tdis = UtilZ.distance(input, data[i]); if(tdis<dis){ dis=tdis; nearest = data[i]; } } return nearest; } /** * 运行100000次,看运行结果是否和线性查找相同 */ public static void correct(){ int count = 100000; while(count-->0){ int num = 100; double[][] input = new double[num][2]; for(int i=0;i<num;i++){ input[i][0]=Math.random()*10; input[i][1]=Math.random()*10; } double[] query = new double[]{Math.random()*50,Math.random()*50}; KDTree tree=KDTree.build(input); double[] result = tree.query(query); double[] result1 = nearest(query,input); if (result[0]!=result1[0]||result[1]!=result1[1]) { System.out.println("wrong"); break; } } } public static void performance(int iteration,int datasize){ int count = iteration; int num = datasize; double[][] input = new double[num][2]; for(int i=0;i<num;i++){ input[i][0]=Math.random()*num; input[i][1]=Math.random()*num; } KDTree tree=KDTree.build(input); double[][] query = new double[iteration][2]; for(int i=0;i<iteration;i++){ query[i][0]= Math.random()*num*1.5; query[i][1]= Math.random()*num*1.5; } long start = System.currentTimeMillis(); for(int i=0;i<iteration;i++){ double[] result = tree.query(query[i]); } long timekdtree = System.currentTimeMillis()-start; start = System.currentTimeMillis(); for(int i=0;i<iteration;i++){ double[] result = nearest(query[i],input); } long timelinear = System.currentTimeMillis()-start; System.out.println("datasize:"+datasize+";iteration:"+iteration); System.out.println("kdtree:"+timekdtree); System.out.println("linear:"+timelinear); System.out.println("linear/kdtree:"+(timelinear*1.0/timekdtree)); } public static void main(String[] args) { //correct(); performance(100000,10000); } }