Infobright高性能数据仓库
1. 概述
Infobright是一款基于独特的专利知识网格技术的列式数据库。Infobright简单易用,快速安装部署,使用中无需复杂操作,能大幅度减少管理工作;在应对50TB甚至更多数据量进行多并发复杂查询时,更能够显示出令人惊叹的速度。相比于MySQL,其查询速度提升了数倍甚至数十倍,在同类产品中单机性能处于领先地位。为企业剧增的数据规模、增长的客户需求以及较高的用户期望提供了全面的解决方案。
2. Infobright特征
优点:
1)大数据量查询性能强劲、稳定:查询性能高,如百万、千万、亿级记录数条件下,同等的SELECT查询语句,速度比MyISAM、InnoDB等普通的MySQL存储引擎快5~60倍。高效查询主要依赖特殊设计的存储结构对查询的优化,但这里优化的效果还取决于数据库结构和查询语句的设计。
2)存储数据量大:TB级数据大小,几十亿条记录。数据量存储主要依赖自己提供的高速数据加载工具(百G/小时)和高数据压缩比(>10:1)
3)高数据压缩比:号称平均能够达到 10:1 以上的数据压缩率。甚至可以达到40:1,极大地节省了数据存储空间。高数据压缩比主要依赖列式存储和 patent-pending 的灵活压缩算法。
4)基于列存储:无需建索引,无需分区。即使数据量十分巨大,查询速度也很快。用于数据仓库,处理海量数据没一套可不行。不需要建索引,就避免了维护索引及索引随着数据膨胀的问题。把每列数据分块压缩存放,每块有知识网格节点记录块内的统计信息,代替索引,加速搜 索。
5)快速响应复杂的聚合类查询:适合复杂的分析性SQL查询,如SUM, COUNT, AVG, GROUP BY
限制:
1)不支持数据更新:社区版Infobright只能使用“LOAD DATA INFILE”的方式导入数据,不支持INSERT、UPDATE、DELETE。
这使对数据的修改变得很困难,这样就限制了它作为实时数据服务的数据仓库来使用。用户要么忍受数据的非实时或非精确,这样对最(较)新数据的分析准确性就降低了许多;要么将它作为历史库来使用,带来的问题是实时库用什么?很多用户选择数据仓库系统,不是因为存储空间不够,而是数据加载性能和查询性能无法满足要求。
2)不支持高并发:只能支持10多个并发查询
虽然单库 10 多个并发对一般的应用来说也足够了,但较低的机器利用率对投资者来说总是一件不爽的事情,特别是在并发小请求较多的情况下。
3). 没有提供主从备份和横向扩展的功能。
如果没有主从备份,想做备份的话,也可以主从同时加载数据,但只能校验最终的数据一致性,这会使得从机在数据加载时停服务的时间较长;横向扩展方面,倒不是 Infobright 的错,它本身就不是分布式的存储系统,但如果把它搞成一个分布式的系统,应该是一件比较好玩的事情。
不支持数据更新。 这个限制对于我们即要求查询性能外还要对数据库进行写入的需求, 造成了很大的不变。 这个估计是很多人试用后放弃试用ICE的第一个原因。
4). 不支持对多核的使用。 不但不支持查询的多并发,而且连导入导出也没有这样的支持。这个也是放弃ICE的一个原因。 谁也不愿意自己的强劲的硬件只能被用到1%。
与MySQL对比:
1、infobright适用于数据仓库场合:即非事务、非实时、非多并发;分析为主;存放既定的事实(基本不会再变),例如日志,或汇总的大量的 数据。所以它并不适合于应对来自网站用户的请求。实际上它取一条记录比mysql要慢很多,但它取100W条记录会比mysql快。
2、mysql的总数据文件占用空间通常会比实际数据多,因为它还有索引。infobright的压缩能力很强大,按列按不同类型的数据来压缩。
3、服务形式与接口跟mysql一致,可以用类似mysql的方式启用infobright服务,然后原来连接mysql的应用程序都可以以类似的 方式连接与查询infobright。这对熟练mysql者来说是个福音,学习成本基本为0。
infobright有两个发布版:开源的ICE及闭源商用的IEE。ICE提供了足够用的功能,但不能 INSERT,DELETE,UPDATE,只能LOAD DATA INFILE。IEE除提供更充分的功能外,据说查询速度也要更快。
3. 架构
基于MySQL的内部架构 – Infobright采取与MySQL相似的内部架构
下面是Infobright的架构图:

2)Knowledge Node里面存储着指向DP之间或者列之间关系的一些元数据集合,比如值发生的范围(MIin_Max)、列数据之间的关联。大部分的KN数据是装载数据的时候产生的,另外一些事是查询的时候产生。
Knowledge Grid构架是Infobright高性能的重要原因。
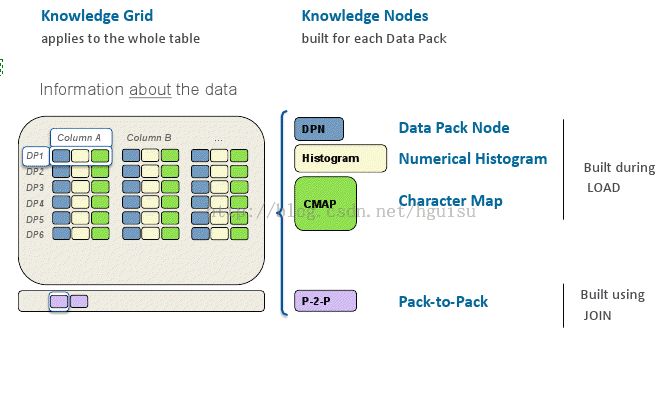
Knowledge Grid可分为四部分,DPN、Histogram、CMAP、P-2-P。
DPN如上所述。Histogram用来提高数字类型(比如date,time,decimal)的查询的性能。Histogram是装载数据的时候就产生的。DPN中有mix、max,Histogram中把Min-Max分成1024段,如果Mix_Max范围小于1024的话,每一段就是就是一个单独的值。这个时候KN就是一个数值是否在当前段的二进制表示。

Histogram的作用就是快速判断当前DP是否满足查询条件。如上图所示,比如select id from customerInfo where id>50 and id<70。那么很容易就可以得到当前DP不满足条件。所以Histogram对于那种数字限定的查询能够很有效地减少查询DP的数量。
CMAP是针对于文本类型的查询,也是装载数据的时候就产生的。CMAP是统计当前DP内,ASCII在1-64位置出现的情况。如下图所示
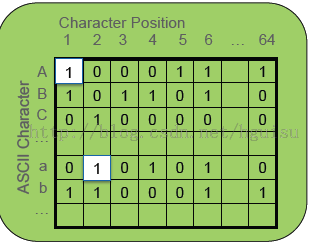
比如上面的图说明了A在文本的第二个、第三个、第四个位置从来没有出现过。0表示没有出现,1表示出现过。查询中文本的比较归根究底还是按照字节进行比较,所以根据CMAP能够很好地提高文本查询的性能。
Pack-To-Pack是Join操作的时候产生的,它是表示join的两个DP中操作的两个列之间关系的位图,也就是二进制表示的矩阵。
Knowledge Grid还是比较复杂的,里面还有很多细节的东西,可以参考官方的白皮书和Brighthouse: an analytic data warehouse for ad-hoc queries这篇论文。
4. 数据类型
5. 工作原理
粗糙集(Rough Sets)是Infobright的核心技术之一。Infobright在执行查询的时候会根据知识网络(Knowledge Grid)把DP分成三类:
相关的DP(Relevant Packs),满足查询条件限制的DP
不相关的DP(Irrelevant Packs),不满足查询条件限制的DP
可疑的DP(Suspect Packs),DP里面的数据部分满足查询条件的限制
下面是一个案例:

如图所示,每一列总共有5个DP,其中限制条件是A>6。所以A1、A2、A4就是不相关的DP,A3是相关的DP,A5是可疑的DP。那么执行查询的时候只需要计算B5中满足条件的记录的和然后加上Sum(B3),Sum(B3)是已知的。此时只需要解压缩B5这个DP。从上面的分析可以知道,Infobright能够很高效地执行一些查询,而且执行的时候where语句的区分度越高越好。where区分度高可以更精确地确认是否是相关DP或者是不相关DP亦或是可以DP,尽可能减少DP的数量、减少解压缩带来的性能损耗。在做条件判断的使用,一般会用到上一章所讲到的Histogram和CMAP,它们能够有效地提高查询性能。
多表连接的的时候原理也是相似的。先是利用Pack-To-Pack产生join的那两列的DP之间的关系。
比如:SELECT MAX(X.D) FROM T JOIN X ON T.B = X.C WHERE T.A > 6。Pack-To-Pack产生T.B和X.C的DP之间的关系矩阵M。假设T.B的第一个DP和X.C的第一个DP之间有元素交叉,那么M[1,1]=1,否则M[1,1]=0。这样就有效地减少了join操作时DP的数量。
前面降到了解压缩,顺便提一提DP的压缩。每个DP中的64K个元素被当成是一个序列,其中所有的null的位置都会被单独存储,然后其余的non-null的数据会被压缩。数据的压缩跟数据的类型有关,infobright会根据数据的类型选择压缩算法。infobright会自适应地调节算法的参数以达到最优的压缩比。
6. 压缩比例
Infobright号称数据压缩比率是10:1到40:1。前面我们已经说过了Infobright的压缩是根据DP里面的数据类型,系统自动选择压缩算法,并且自适应地调节算法的参数以达到最优的压缩比。
先看看在我的实验环境下的压缩比率,如下图所示:

相信读者可以很清楚地看到,整体的压缩比率是20.302。但是这里有一个误区,这里的压缩比率指的是数据库中的原始数据大小/压缩后的数据大小,而不是文本文件的物理数据大小/压缩后的数据大小。很明显前者会比后者大出不少。在我的实验环境下,后者是7:1左右。一般来说文本数据存入数据库之后大小会比原来的文本大不少,因为有些字段被设置了固定长度,占用了比实际更多的空间。还有就是数据库里面会有很多的统计信息数据,其中就包括索引,这些统计信息数据占据的空间绝对不小。Infobright虽然没有索引,但是它有KN数据,通常情况下KN数据大小占数据总大小的1%左右。
既然Infobright会根据具体的数据类型进行压缩,那我们就看看不同的数据类型具有什么样的压缩比率。如下表所示:
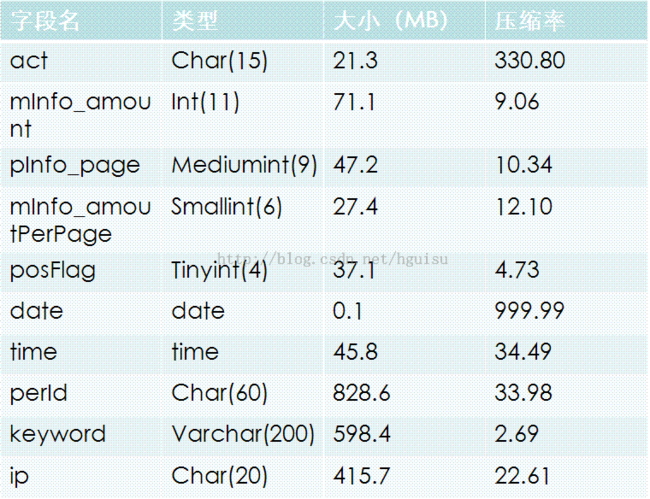
首先看看Int类型的压缩比率,结果是压缩比率上Int<mediumint<smallint。细心地读者会很容易发现tinyint的压缩比率怎么会比int还小。数据压缩比率除了和数据类型有关之外,还和数据的差异性有特别大关系,这是显而易见。posFlag只有0,1,-1三种可能,这种数据显然不可能取得很好的压缩比率。
再看看act字段,act字段使用了comment lookup,比简单的char类型具有更佳的压缩比率和查询性能。comment lookup的原理其实比较像位图索引。对于comment lookup的使用下一章节将细细讲述。
在所有的字段当中date字段的压缩比率是最高的,最后数据的大小只有0.1M。varchar的压缩比率就比较差了,所以除非必要,不然不建议使用varchar。
上面的数据很清楚地展示了Infobright强大的压缩性能。在此再次强调,数据的压缩不只是和数据类型有关,数据的差异程度起了特别大的作用。在选择字段数据类型的时候,个人觉得性能方面的考虑应该摆在第一位。比如上面表中一些字段的选择就可以优化,ip可以改为bigint类型,date甚至可以根据需要拆分成year/month/day三列。
6. comment lookup的使用
comment lookup只能显式地使用在char或者varchar上面。Comment Lookup可以减少存储空间,提高压缩率,对char和varchar字段采用comment lookup可以提高查询效率。
Comment Lookup实现机制很像位图索引,实现上利用简短的数值类型替代char字段已取得更好的查询性能和压缩比率。CommentLookup的使用除了对数据类型有要求,对数据也有一定的要求。一般要求数据类别的总数小于10000并且当前列的单元数量/类别数量大于10。Comment Lookup比较适合年龄,性别,省份这一类型的字段。
comment lookup使用很简单,在创建数据库表的时候如下定义即可:
act char(15) comment 'lookup',
part char(4) comment 'lookup',
7. 查询优化
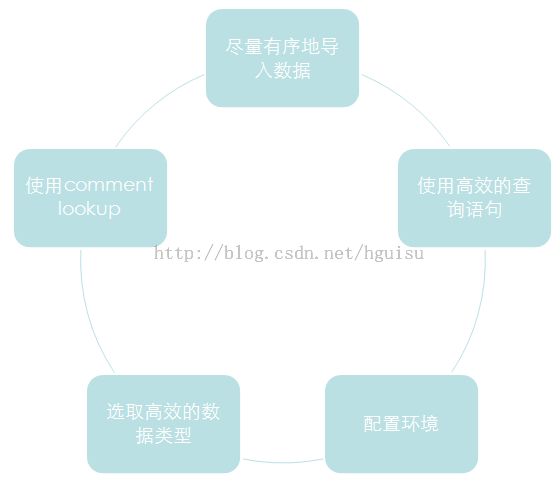
(1)配置环境
在Linux下面,Infobright环境的配置可以根据README里的要求,配置brighthouse.ini文件。
(2) 选取高效的数据类型
参见前面章节。
(3)使用comment lookup
参见前面章节。
(4)尽量有序地导入数据
前面分析过Infobright的构架,每一列分成n个DP,每个DPN列面存储着DP的一些统计信息。有序地导入数据能够使不同的DP的DPN内的数据差异化更明显。比如按时间date顺序导入数据,那么前一个DP的max(date)<=下一个DP的min(date),查询的时候就能够减少可疑DP,提高查询性能。换句话说,有序地导入数据就是使DP内部数据更加集中,而不再那么分散。
(5)使用高效的查询语句。
这里涉及的内容比较多了,总结如下:
尽量不适用or,可以采用in或者union取而代之
减少IO操作,原因是infobright里面数据是压缩的,解压缩的过程要消耗很多的时间。
查询的时候尽量条件选择差异化更明显的语句
Select中尽量使用where中出现的字段。原因是Infobright按照列处理的,每一列都是单独处理的。所以避免使用where中未出现的字段可以得到较好的性能。
限制在结果中的表的数量,也就是限制select中出现表的数量。
尽量使用独立的子查询和join操作代替非独立的子查询
尽量不在where里面使用MySQL函数和类型转换符
尽量避免会使用MySQL优化器的查询操作
使用跨越Infobright表和MySQL表的查询操作
尽量不在group by 里或者子查询里面使用数学操作,如sum(a*b)。
select里面尽量剔除不要的字段。
Infobright执行查询语句的时候,大部分的时间都是花在优化阶段。Infobright优化器虽然已经很强大,但是编写查询语句的时候很多的细节问题还是需要程序员注意。
7、IB安装
1、下载
wget http://www.infobright.org/downloads/ice/infobright-4.0.7-0-src-ice.tar.gz
2、tar zxvf infobright-4.0.7-0-src-ice.tar.gz
3、可以在目录infobright-4.0.7-0看到README文件
这么有安装说明,不过需要注意几点,用红色标注
Infobright Installation Using a Source Distribution
===================================================
* Menu:
* Source Installation Overview
* Dealing with Problems Compiling Infobright
一、需要的环境
You need the following tools to build and install MySQL and Infobright from source:
* A working gcc compiler (recomended version is 4.2.x).
* Properly installed autoconf and other gnu tools such as aclocal, autoheader, libtool(1.5.22), automake,
autoconf (2.59), autoreconf (2.59), make (3.81), m4 - macro preprocessor(1.4.5), libncurses5, libncurses5-dev, zlib,
zlib-devel, perl, bison etc.
* boost 1.42 or higher (required boost-regex*, boost-program-options*,
boost_thread*, boost_filesystem*, boost_system*). In Infobright we compile boost using the following steps
wget http://jaist.dl.sourceforge.net/project/boost/boost/1.50.0/boost_1_50_0.tar.gz
- download boost 1.50 and unpack it:tar -zxvf boost_1_50_0.tar.gz
- cd to unpacked folder: cd boost_1_42_0
- ./bootstrap.sh --prefix=/usr/local/boost_1_42_0
- ./bjam install
- export BOOST_ROOT=/usr/local/boost_1_42_0
这个一定按这个顺利执行,否则有可能出错
</pre><span style="color:#666666">二、源码安装:</span><p></p><p style="font-family:Arial; font-size:14px; line-height:26px"><span style="font-family:'Hiragino Sans GB W3','Hiragino Sans GB',Arial,Helvetica,simsun,u5b8bu4f53; font-size:16px; line-height:28px"><span style="font-family:verdana,arial,sans-serif; background-color:rgb(249,249,249)"><span style="color:rgb(102,102,102)">Source Installation Overview</span><span style="color:rgb(102,102,102)">----------------------------------</span><span style="color:rgb(102,102,102)">The basic commands that you must execute to compile and install a MySQL and Infobright source</span><span style="color:rgb(102,102,102)">distribution are:</span><span style="color:rgb(102,102,102)"> shell> groupadd mysql</span><span style="color:rgb(102,102,102)"> shell> useradd -g mysql mysql</span><span style="color:rgb(102,102,102)"> # To compile and install MySQL and Infobright server and client tools</span><span style="color:rgb(102,102,102)"> shell> cd <span style="color:rgb(102,102,102); font-family:verdana,arial,sans-serif; font-size:16px; line-height:28px; background-color:rgb(249,249,249)">infobright-4.0.7-0</span></span><span style="color:rgb(255,0,0)"> shell> make </span></span></span><span style="color:rgb(255,0,0)"><span style="background-color:rgb(240,240,240); line-height:21px; font-family:verdana,arial,sans-serif; font-size:16px">PREFIX=/usr/local/infobright </span><span style="font-size:16px; background-color:rgb(249,249,249); font-family:verdana,arial,sans-serif; line-height:28px">EDITION=community release</span><span style="font-family:'Hiragino Sans GB W3','Hiragino Sans GB',Arial,Helvetica,simsun,u5b8bu4f53; font-size:16px; line-height:28px"><span style="font-family:verdana,arial,sans-serif; background-color:rgb(249,249,249)"> shell> make </span></span><span style="background-color:rgb(240,240,240); line-height:21px; font-family:verdana,arial,sans-serif; font-size:16px">PREFIX=/usr/local/infobright </span><span style="font-size:16px; background-color:rgb(249,249,249); font-family:verdana,arial,sans-serif; line-height:28px">EDITION=community install-release</span></span><span style="color:rgb(51,51,51); font-family:'Hiragino Sans GB W3','Hiragino Sans GB',Arial,Helvetica,simsun,u5b8bu4f53; font-size:16px; line-height:28px"><span style="font-family:verdana,arial,sans-serif; background-color:rgb(249,249,249)"><span style="color:#666666"></span></span></span></p><pre name="code" class="plain" style="margin-top: 0px; margin-bottom: 10px; background-color: rgb(255, 255, 255); color: rgb(255, 102, 0); font-size: 13px; line-height: 24px;">
# make -j 8 PREFIX=/usr/local/infobright EDITION=community release # make -j 8 PREFIX=/usr/local/infobright EDITION=community install-release
make -j 8 表示使用服务器的8个核并行编译
PREFIX=/usr/local/infobright 指定安装路径
# Setting config file and brighthouse.ini file.
shell> cp src/build/pkgmt/my-ib.cnf /etc/
Note: You can customize /etc/my-ib.cnf file by changing port, socket etc.
If you are compiling on a 32 bit system, you need to rename brighthouse.ini.32bit
(can be found in package dir /usr/local/infobright/share/mysql/ etc.) to brighthouse.ini.
The existing brighthouse.ini is configured with higher memory settings suitable
for a 64 bit system.
shell> cd /usr/local/infobright
shell> bin/mysql_install_db --defaults-file=/etc/my-ib.cnf --user=mysql
如果报错:error while loading shared libraries: libboost_filesystem.so.1.42.0: cannot open shared object file: No such file or directory
执行:
shell> echo /usr/local/boost_1_42_0/lib>> /etc/ld.so.conf.d/boost_lib.conf
shell> ldconfig
shell> chown -R root .
shell> chown -R mysql var cache
shell> chgrp -R mysql .
shell> `pwd`/libexec/mysqld --defaults-file=/etc/my-ib.cnf --user=mysql
安装启动脚本:
shell> cp share/mysql/mysql.server /etc/init.d/mysqld-ib
shell> vi /etc/init.d/mysqld-ib
初始化ib实例的密码/usr/local/infobright/bin/mysqladmin -u root password "123456"
A more detailed version of the preceding description for installing
MySQL and Infobright from a source distribution follows:
1. Add a login user and group for `mysqld' to run as:
shell> groupadd mysql
shell> useradd -g mysql mysql
These commands add the `mysql' group and the `mysql' user. The
syntax for `useradd' and `groupadd' may differ slightly on
different versions of Unix, or they may have different names such
as `adduser' and `addgroup'.
You might want to call the user and group something else instead
of `mysql'. If so, substitute the appropriate name in the
following steps.
2. Pick the directory under which you want to unpack the distribution
and change location into it.
3. Unpack the distribution into the current directory:
shell> gunzip < /PATH/TO/infobright-version-src.tar.gz | tar xvf -
This command creates a directory named infobright-version-src.
4. Configure, compile and install MySQL and Infobright source code using the following commands:
shell> cd infobright-version
shell> make EDITION=community release
shell> make EDITION=community install-release
# Setting config file and brighthouse.ini file.
shell> cp vendor/mysql/support-files/my-ib.cnf /etc/
5. Change location into the installation directory:
shell> cd /usr/local/infobright
6. If you haven't installed MySQL before, you must create the MySQL
grant tables:
shell> bin/mysql_install_db --defaults-file=/etc/my-ib.cnf --user=mysql
If you run the command as `root', you should use the `--user'
option as shown. The value of the option should be the name of the
login account that you created in the first step to use for
running the server. If you run the command while logged in as that
user, you can omit the `--user' option.
After using `mysql_install_db' to create the grant tables for
MySQL, you must restart the server manually. The `mysqld_safe'
command to do this is shown in a later step.
shell> bin/mysql_install_db --defaults-file=/etc/my-ib.cnf --user=mysql
7. Change the ownership of program binaries to `root' and ownership
of the data directory to the user that you run `mysqld' as.
Assuming that you are located in the installation directory
(`/usr/local/infobright'), the commands look like this:
shell> chown -R root .
shell> chown -R mysql var cache
shell> chgrp -R mysql .
The first command changes the owner attribute of the files to the
`root' user. The second changes the owner attribute of the data
directory to the `mysql' user. The third changes the group
attribute to the `mysql' group.
8. After everything has been installed, you should test your distribution.
To start the server, use the following command:
shell> cd /usr/local/infobright
shell> `pwd`/libexec/mysqld --defaults-file=/etc/my-ib.cnf --user=mysql
9. To run the client:
shell> cd /usr/local/infobright
shell> bin/mysql --defaults-file=/etc/my-ib.cnf -uroot
If that command fails immediately and prints `mysqld ended', you can
find some information in the `HOST_NAME.err' file in the var directory.
Dealing with Problems Compiling Infobright
------------------------------------------
If you use GNU make 3.81, it might generate warning messages
"-jN forced in submake: disabling jobserver mode". Please ignore such warnings.
Make sure sytem OS and processor are supported by Infobright. Also make sure that
all the packages mentioned on top of the page are properly installed.
7. 数据导入
对于DW系统而言,庞大数据的迁移成本很高;所以导入和导出的速率及容忍性也是考量数据仓库产品的重要标准。Infobright基于MySQL所以在数据格式上有比较成型的解决办法,IB原厂对速率进行了优化。在4.0企业版中推出了DLP分布式导入选件,极大的减少了迁移时间,目前世界最大的光通信提供商JDSU也选用了IB产品,并以DLP为主要选件进行配置。
1、简介
IB提供了专用的高性能loader,不同于传统的mysql。IB loader是为了提高导入速度而设计的,所以仅支持特有的mysql loader语法,而且只支持导入格式化的变量和文本源文件.IEE版也支持mysqlloader和insert语句。infobright对txt的格式有非常严格的要求,格式不对是不能导入数据的。
2、默认Loader
1)ICE仅支持IB lorder
2)IEE默认使用的是是mysql loader,它能更多的容错,但速度稍慢。为了最快的导入,使用IB loader,做以下环境的设置
导入步骤:
1)、建表:
mysql>
create table example2 ( id int not null, textfield varchar(20) not null, number int not null )engine=birghthouse;
2)、建立txt/csv数据:
mysql> load data infile 'F:\\in2.txt' into table example2 fields terminated by ',' enclosed by '"';
Mysql>
set @bh_dataformat = ‘txt_variable’;
–使用IB loader来导入CSV格式的变量定长文本
set @bh_dataformat = ‘binary’;
–二进制文件
set @bh_dataformat = ‘mysql’;
–使用mysql loader
3,IB loader语法
IB仅支持load data infile,其他的mysql导入方式不支持
LOAD DATA INFILE ‘/full_path/file_name’
INTO TABLE tbl_name
[FIELDS
[TERMINATED BY 'char']
[ENCLOSED BY 'char']
[ESCAPED BY 'char']
];
导入前关闭
set AUTOCOMMIT=0;
完成后
COMMIT;
set AUTOCOMMIT=1;
4,区域分隔符
.区域分隔符是可选的,默认设置为
CLAUSE DEFAULT VALUE
FIELDS TERMINATED BY ‘;’ (semicolon)
FIELDS ENCLOSED BY ‘”‘ (double quote)
FIELDS ESCAPED BY ” (none)
5,导入经验
a. 当导入表格列数很多时,修改brighthouse.ini中LoaderMainHeapSize
b 使用并发导入
c 容忍性排序为txt_variables<binary<mysql
d bh_loader不支持多分隔符
e 大量数据时,DLP是必要选择
1.妥善处理字符集,在导入和迁移时,尽量将所有%character%均改为与原库相同的字符集2.选择合适分隔符,infobright自己缺省默认loader为bh_loader,仅支持单个字节分隔符,不支持如’,,’ ‘||’等
3.IEE企业版还可以使用MySQL_loader,基本上和MySQL一样,具备所有功能,使用前set @bh_dataformat=’mysql’;
4.遗留问题:
a.白发渔樵江楮上
今天在试用infobright-4.0.4版本的时候,load data 的时候出现错误“ERROR 1598 (HY000): Binary logging not possible. Message: Statement cannot be logged to the binary log in row-based nor statement-based format”,当然可用“SET SQL_LOG_BIN = 0”不记录日志,但是我岂不是用不了复制了?
b.stronghearted:infobright导入数据时,选latin1,刚才选gbk,中文总是乱码。
stronghearted:回复@W维西:导出innodb的表是gbk,如果建IB的表是gbk,导入的中文会是乱码。选latin1就正确
W维西:Hi,做了个测试,两边GBK在我这边比较正常,请看http://t.cn/akbcDH 可能还是字符集的问题,所有的变量都要改下:)
目前infobright应用越来越多了,有些场景下需要和台管理系统共用,因此需要同时存在brighthouse和myisam两种引擎。
这时候,如果需要brighthouse引擎支持utf8字符集,需要:
1. 数据库对象创建时务必使用utf8字符集,这点尤为关键,否则不可支持utf8;
2. 数据表对象创建时也使用utf8字符集;
3. 导入文件提前转换成utf8字符集;
4. 连接infobright时,执行set names utf8;
5. 导入文件,查看字符集是否正确;
另一种场景下,可能myisam表也需要支持utf8,这个相对比较麻烦:
1. 数据库对象创建时无所谓,不强制必须是utf8;
2. 数据表对象创建时务必使用utf8字符集;
3. 将导入文件全部转换成utf8字符集的INSERT语法,直接写入数据,infobright不支持LOAD DATA INFILE方式导入utf8字符集的文件;
4. 也可以将其他非字符型字段导入后,再用update进行更新
mysql数据导入到infobright中
mysql数据导入到infobright中1,在mysql中建一张表:
create table t_mis( uid mediumint not null, cid smallint not null, rating tinyint not null)engine=MyISAM;
插入数据:
insert into t_mis(uid,cid,rating) values('70000','3600','5');
2,将数据导出csv文件:
select * from t_mis into outfile 'F:\\mytable.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by '\n';
3,在infobright中建一个表:
create table t_ib( uid mediumint not null, cis smallint not null, rating tinyint not null)engine=brighthouse;
4,导入csv到表t_ib中:
load data infile 'F:\\mytable.csv' into table t_ib fields terminated by ',' optionally enclosed by '"' lines terminated by '\n';
注意:
拥有file权限才可以执行 select ..into outfile和load data infile…操作,但是不要把file, process, super权限授予管理员以外的账号,这样存在严重的安全隐患。
mysql> grant file on *.* to tet@localhost;
mysql> load data infile ‘/home/mysql/test.txt’ into table test;