HDFS副本存放读取
HDFS作为Hadoop中 的一个分布式文件系统,而且是专门为它的MapReduce设计,所以HDFS除了必须满足自己作为分布式文件系统的高可靠性外,还必须为 MapReduce提供高效的读写性能,那么HDFS是如何做到这些的呢?首先,HDFS将每一个文件的数据进行分块存储,同时每一个数据块又保存有多个 副本,这些数据块副本分布在不同的机器节点上,这种数据分块存储+副本的策略是HDFS保证可靠性和性能的关键,这是因为:一.文件分块存储之后按照数据 块来读,提高了文件随机读的效率和并发读的效率;二.保存数据块若干副本到不同的机器节点实现可靠性的同时也提高了同一数据块的并发读效率;三.数据分块 是非常切合MapReduce中任务切分的思想。在这里,副本的存放策略又是HDFS实现高可靠性和搞性能的关键。
HDFS采用一种称为机架感知的策略来改进数据的可靠性、可用性和网络带宽的利用率。通过一个机架感知的过程,NameNode可以确定每一个 DataNode所属的机架id(这也是NameNode采用NetworkTopology数据结构来存储数据节点的原因,也是我在前面详细介绍NetworkTopology类 的原因)。一个简单但没有优化的策略就是将副本存放在不同的机架上,这样可以防止当整个机架失效时数据的丢失,并且允许读数据的时候充分利用多个机架的带 宽。这种策略设置可以将副本均匀分布在集群中,有利于当组件失效的情况下的均匀负载,但是,因为这种策略的一个写操作需要传输到多个机架,这增加了写的代 价。
在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架节点上,一个副本存放在同一个机架的另一个节点上,最后一个副本放在不同机 架的节点上。这种策略减少了机架间的数据传输,提高了写操作的效率。机架的错误远远比节点的错误少,所以这种策略不会影响到数据的可靠性和可用性。与此同 时,因为数据块只存放在两个不同的机架上,所以此策略减少了读取数据时需要的网络传输总带宽。在这种策略下,副本并不是均匀的分布在不同的机架上:三分之 一的副本在一个节点上,三分之二的副本在一个机架上,其它副本均匀分布在剩下的机架中,这种策略在不损害数据可靠性和读取性能的情况下改进了写的性能。下 面就来看看HDFS是如何来具体实现这一策略的。
NameNode是通过类来为每一分数据块选择副本的存放位置的,这个ReplicationTargetChooser的一般处理过程如下:
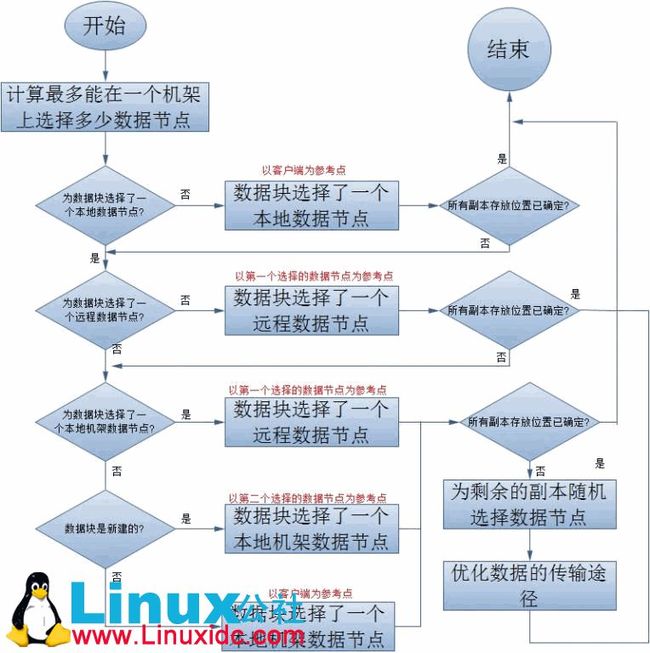
上面的流程图详细的描述了Hadoop-0.2.0版本中副本的存放位置的选择策略,当然,这当中还有一些细节问题,如:如何选择一个本地数据节点,如何选择一个本地机架数据节点等,所以下面我还将继续展开讨论。
1.选择一个本地节点
这里所说的本地节点是相对于客户端来说的,也就是说某一个用户正在用一个客户端来向HDFS中写数据,如果该客户端上有数据节点,那么就应该最优先考虑把正在写入的数据的一个副本保存在这个客户端的数据节点上,它即被看做是本地节点,但是如果这个客户端上的数据节点空间不足或者是当前负载过重,则应该从该数据节点所在的机架中选择一个合适的数据节点作为此时这个数据块的本地节点。另外,如果客户端上没有一个数据节点的话,则从整个集群中随机选择一个合适的数据节点作为此时这个数据块的本地节点。那么,如何判定一个数据节点合不合适呢,它是通过isGoodTarget方法来确定的:
- private boolean isGoodTarget(DatanodeDescriptor node, long blockSize, int maxTargetPerLoc, boolean considerLoad, List<DatanodeDescriptor> results) {
- Log logr = FSNamesystem.LOG;
- // 节点不可用了
- if (node.isDecommissionInProgress() || node.isDecommissioned()) {
- logr.debug("Node "+NodeBase.getPath(node)+ " is not chosen because the node is (being) decommissioned");
- return false;
- }
- long remaining = node.getRemaining() - (node.getBlocksScheduled() * blockSize);
- // 节点剩余的容量够不够
- if (blockSize* FSConstants.MIN_BLOCKS_FOR_WRITE>remaining) {
- logr.debug("Node "+NodeBase.getPath(node)+ " is not chosen because the node does not have enough space");
- return false;
- }
- // 节点当前的负载情况
- if (considerLoad) {
- double avgLoad = 0;
- int size = clusterMap.getNumOfLeaves();
- if (size != 0) {
- avgLoad = (double)fs.getTotalLoad()/size;
- }
- if (node.getXceiverCount() > (2.0 * avgLoad)) {
- logr.debug("Node "+NodeBase.getPath(node)+ " is not chosen because the node is too busy");
- return false;
- }
- }
- // 该节点坐在的机架被选择存放当前数据块副本的数据节点过多
- String rackname = node.getNetworkLocation();
- int counter=1;
- for(Iterator<DatanodeDescriptor> iter = results.iterator(); iter.hasNext();) {
- Node result = iter.next();
- if (rackname.equals(result.getNetworkLocation())) {
- counter++;
- }
- }
- if (counter>maxTargetPerLoc) {
- logr.debug("Node "+NodeBase.getPath(node)+ " is not chosen because the rack has too many chosen nodes");
- return false;
- }
- return true;
- }
2.选择一个本地机架节点
实际上,选择本地节假节点和远程机架节点都需要以一个节点为参考,这样才是有意义,所以在上面的流程图中,我用红色字体标出了参考点。那么,ReplicationTargetChooser是如何根据一个节点选择它的一个本地机架节点呢?
这个过程很简单,如果参考点为空,则从整个集群中随机选择一个合适的数据节点作为此时的本地机架节点;否则就从参考节点所在的机架中随机选择一个合适的数据节点作为此时的本地机架节点,若这个集群中没有合适的数据节点的话,则从已选择的数据节点中找出一个作为新的参考点,如果找到了一个新的参考点,则从这个新的参考点在的机架中随机选择一个合适的数据节点作为此时的本地机架节点;否则从整个集群中随机选择一个合适的数据节点作为此时的本地机架节点。如果新的参考点所在的机架中仍然没有合适的数据节点,则只能从整个集群中随机选择一个合适的数据节点作为此时的本地机架节点了。
- <font xmlns="http://www.w3.org/1999/xhtml">private DatanodeDescriptor chooseLocalRack(DatanodeDescriptor localMachine, List<Node> excludedNodes, long blocksize, int maxNodesPerRack, List<DatanodeDescriptor> results)throws NotEnoughReplicasException {
- // 如果参考点为空,则从整个集群中随机选择一个合适的数据节点作为此时的本地机架节点
- if (localMachine == null) {
- return chooseRandom(NodeBase.ROOT, excludedNodes, blocksize, maxNodesPerRack, results);
- }
- //从参考节点所在的机架中随机选择一个合适的数据节点作为此时的本地机架节点
- try {
- return chooseRandom(localMachine.getNetworkLocation(), excludedNodes, blocksize, maxNodesPerRack, results);
- } catch (NotEnoughReplicasException e1) {
- //若这个集群中没有合适的数据节点的话,则从已选择的数据节点中找出一个作为新的参考点
- DatanodeDescriptor newLocal=null;
- for(Iterator<DatanodeDescriptor> iter=results.iterator(); iter.hasNext();) {
- DatanodeDescriptor nextNode = iter.next();
- if (nextNode != localMachine) {
- newLocal = nextNode;
- break;
- }
- }
- if (newLocal != null) {//找到了一个新的参考点
- try {
- //从这个新的参考点在的机架中随机选择一个合适的数据节点作为此时的本地机架节点
- return chooseRandom(newLocal.getNetworkLocation(), excludedNodes, blocksize, maxNodesPerRack, results);
- } catch(NotEnoughReplicasException e2) {
- //新的参考点所在的机架中仍然没有合适的数据节点,从整个集群中随机选择一个合适的数据节点作为此时的本地机架节点
- return chooseRandom(NodeBase.ROOT, excludedNodes, blocksize, maxNodesPerRack, results);
- }
- } else {
- //从整个集群中随机选择一个合适的数据节点作为此时的本地机架节点
- return chooseRandom(NodeBase.ROOT, excludedNodes, blocksize, maxNodesPerRack, results);
- }
- }
- }</font>
3.选择一个远程机架节点
选择一个远程机架节点就是随机的选择一个合适的不在参考点坐在的机架中的数据节点,如果没有找到这个合适的数据节点的话,就只能从参考点所在的机架中选择一个合适的数据节点作为此时的远程机架节点了。
4.随机选择若干数据节点
这里的随机随机选择若干个数据节点实际上指的是从某一个范围内随机的选择若干个节点,它的实现需要利用前面提到过的NetworkTopology数据结构。随机选择所使用的范围本质上指的是一个路径,这个路径表示的是NetworkTopology所表示的树状网络拓扑图中的一个非叶子节点,随机选择针对的就是这个节点的所有叶子子节点,因为所有的数据节点都被表示成了这个树状网络拓扑图中的叶子节点。
5.优化数据传输的路径
以前说过,HDFS对于Block的副本copy采用的是流水线作业的方式:client把数据Block只传给一个DataNode,这个DataNode收到Block之后,传给下一个DataNode,依次类推,...,最后一个DataNode就不需要下传数据Block了。所以,在为一个数据块确定了所有的副本存放的位置之后,就需要确定这种数据节点之间流水复制的顺序,这种顺序应该使得数据传输时花费的网络延时最小。ReplicationTargetChooser用了非常简单的方法来考量的,大家一看便知:
- private DatanodeDescriptor[] getPipeline( DatanodeDescriptor writer, DatanodeDescriptor[] nodes) {
- if (nodes.length==0) return nodes;
- synchronized(clusterMap) {
- int index=0;
- if (writer == null || !clusterMap.contains(writer)) {
- writer = nodes[0];
- }
- for(;index<nodes.length; index++) {
- DatanodeDescriptor shortestNode = nodes[index];
- int shortestDistance = clusterMap.getDistance(writer, shortestNode);
- int shortestIndex = index;
- for(int i=index+1; i<nodes.length; i++) {
- DatanodeDescriptor currentNode = nodes[i];
- int currentDistance = clusterMap.getDistance(writer, currentNode);
- if (shortestDistance>currentDistance) {
- shortestDistance = currentDistance;
- shortestNode = currentNode;
- shortestIndex = i;
- }
- }
- //switch position index & shortestIndex
- if (index != shortestIndex) {
- nodes[shortestIndex] = nodes[index];
- nodes[index] = shortestNode;
- }
- writer = shortestNode;
- }
- }
- return nodes;
- }
可 惜的是,HDFS目前并没有把副本存放策略的实现开放给用户,也就是用户无法根据自己的实际需求来指定文件的数据块存放的具体位置。例如:我们可以将有关 系的两个文件放到相同的数据节点上,这样在进行map-reduce的时候,其工作效率会大大的提高。但是,又考虑到副本存放策略是与集群负载均衡休戚相 关的,所以要是真的把负载存放策略交给用户来实现的话,对用户来说是相当负载的
读取
HDFS对文件的存储是分块来存储的,即HDFS对于客户端写入的数据先按照固 定大小对这些数据进行分块,然后把每一个数据块的多个副本存储在不同的DataNode节点上,同时不同的数据块也可能存储在不同的DataNode节点 上。那么,当客户端要从HDFS上读取某个文件时,它又是如何处理的呢?很明显,客户端也是按照分块来读取文件的数据的,关于客户端如何分块读取文件的详 细原理与过程我已经在前面的博文中详细的阐述了,在这里就不多赘述了。但是,一个数据块有多个副本,客户端到底优先读取那个DataNode节点上的该数 据块的副本呢?这将是本要所要讨论的重点了,即HDFS读取副本的选择策略,而这个工作具体是由NameNode来完成的。
当客户端读到一个文件的某个数据块时,它就需要向NameNode节点询问这个数据块存储在那些DataNode节点上,这个过程如下图:
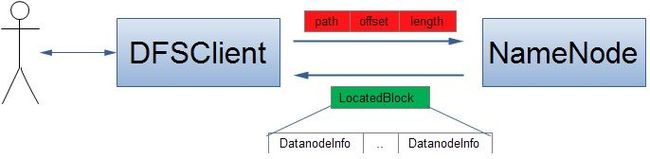
当然,客户端至少需要向NameNode传输三个参数:文件路径、读取文件的起始位 置、读取文件的长度,而NameNode会向该客户端返回它所要读取文件内容所在的位置——LocatedBlock对象,该对象包含对应的数据块所有副 本所在的DataNode节点的位置信息,客户端接着就会依次从这些DataNode节点上读取该数据块,直到成功读取为止。这里就设计到了一个优化问题 了:客户端应该总是选择从距离它最近的可用DataNode节点上读取需要的数据块,所以此时的关键就是如何来计算客户端与DataNode节点之间的距离。这个计算距离的问题本质上涉及到我前面介绍过的一种数据结构——NetworkTopology,这种数据结构被NameNode节点用来形象的表示HDFS集群中所有DataNode节点的物理位置,自然这个优化工作就交由NameNode来处理了。
NameNode对文件的读优化的实现很简单,基本原理就是按照客户端与DataNode节点之间的距离进行排序,距客户端越近的DataNode节点越被放在LocatedBlock的前面,该算法的基本思路如下:
1.如果该Block的一个副本存在于客户端,则客户端优先从本地读取该数据块;
2.如果该Block的一个副本与客户端在同一个机架上,且没有一个副本存放在客户端,则客户端优先读取这个同机架上的副本;否则客户端优先读取同机器的副本,失败的情况下然后再优先考虑这个同机架上的副本;
3.如果该Block既没有一个副本存在客户端,又没有一个副本与客户端在同一个机架上,则随机选择一个DataNode节点作为优先节点。
其详细实现如下:
- /**
- * @param reader 客户端
- * @param nodes 某个Block所在的DataNode节点
- */
- public void pseudoSortByDistance( Node reader, Node[] nodes ) {
- int tempIndex = 0;
- if (reader != null ) {
- int localRackNode = -1;
- //scan the array to find the local node & local rack node
- for(int i=0; i<nodes.length; i++) {
- if(tempIndex == 0 && reader == nodes[i]) { //local node
- //swap the local node and the node at position 0
- if( i != 0 ) {
- swap(nodes, tempIndex, i);
- }
- tempIndex=1;
- if(localRackNode != -1 ) {
- if(localRackNode == 0) {
- localRackNode = i;
- }
- break;
- }
- } else if(localRackNode == -1 && isOnSameRack(reader, nodes[i])) {
- //local rack
- localRackNode = i;
- if(tempIndex != 0 ) break;
- }
- }
- // swap the local rack node and the node at position tempIndex
- if(localRackNode != -1 && localRackNode != tempIndex ) {
- swap(nodes, tempIndex, localRackNode);
- tempIndex++;
- }
- }
- // put a random node at position 0 if it is not a local/local-rack node
- if(tempIndex == 0 && nodes.length != 0) {
- swap(nodes, 0, r.nextInt(nodes.length));
- }
- }
从上面的具体实现可以看,这种优化策略存在一个很大的缺陷:完全没有考虑到DataNode上的负载情况,从而致使HDFS的读性能急速下降。这一点也正好反映了HDFS好友很大的优化空间,但遗憾的是,HDFS对这种读Block时的副本选择策略并没有开放给开发者,以至于大大的增加了优化的难度。