web性能优化(三)反爬虫策略
[文章作者:狂奔的鹿(陆松林)本文版本:v1.0 转载请注明原文链接:http://www.cnblogs.com/dynamiclu/]
反爬虫策略,表面上看似乎跟WEB系统优化没有关系,经过分析,发现该策略是可以归到WEB性能优化的系列之中。
通过分析apache日志发现,某系统40%的带宽和服务器资源都消耗在爬虫上,如果除去10%-15%搜索引擎的爬虫,做好反爬虫策略,能节省20%-25%的资源,其实是变向优化了web系统。
一、爬虫请求与正常用户请求的区别
爬虫请求是类似httpClient的机制或curl,wget的命令,用户请求一般走浏览器。
区别:爬虫请求一般不会执行页面里的异步JavaScript操作,而用户请求则执行Jquery提供的异步JavaScript操作,具体如下:
< script type = " text/javascript " >
$(document).ready( function (){
alertFunTest();
}
function alertFunTest() {
alert(“异步”);
}
< / script >
代码alert(“异步”)一般不会被爬虫请求执行。
二、分析系统有多少爬虫行为
某系统某天的日志分析如下:
cat access20110421.log | wc - l
2156293
cat page_access20110421.log | sort | uniq - c | sort - nr | head - n20
441421 / 读帖页 20.4 %
374274 / 弹出框 17.3 %
266984 / 帖子点击数 12.3 %
213522 / 读取支持数和反支持数 9.9 %
207269 / 其它 9.6 %
203567 / 帖子列表页 9.4 %
185138 / 刷新功能 8.5 %
164884 / 帖子列表点击 7.6 %
如上所示,帖子点击数请求是不会被爬虫执行的。
(读帖页数-帖子点击数)/ 读帖页数=爬虫执行读帖页次数的比例
(441421 - 266984 )/ 441421=39.6%
结论:近40% 帖子的读取操作是爬虫行为,读帖占系统85%以上的操作,也就是说近1/3以上的网络和服务器资源在为爬虫服务。
三、请求在不同层面对应的反抓策略
(一)防火墙层面
通过netstat80端口的tcp连接量判断IP是否非法。
WEB系统都是走http协议跟WEB容器连通的,每次请求至少会产生一次客户端与服务器的tcp连接。通过netstat命令,就可以查看到当前同时连接服务器所对应的IP以及连接量。
命令 /bin/netstat -nat -n | grep 80 一般都几百或几千个。
同一个IP对应的连接数超过我们观察到的一个阀值时,就可判断为非正常的用户请求。阀值设定至关重要,大型网吧或同一个学校、公司出来的IP也可能会被误判为非法请求。
此策略我写了两个定时脚本去,一个定时封IP( tcpForbidCmd.sh ),一个定时释放IP ( tcpReleaseCmd.sh ),分别是每隔5分钟和40分钟各执行一次
tcpForbidCmd.sh参考代码如下:
# !/bin/sh
file =/ home / songlin.lu / shell / log / forbid - ips - tmp.log
myIps =/ home / songlin.lu / shell / log / noforbid_ips.log
today = `date + ' % Y % m % d'`
logForbidIp =/ home / songlin.lu / shell / log / forbid - iptables - logs - $today .log
netstatFile =/ home / songlin.lu / shell / log / forbid - netstat - nat - tmp.log
/ bin / netstat - nat - n > $netstatFile
nowDate = `date + ' % Y -% m -% d % H: % M'`
/ bin / awk -F : ' / tcp / {a[ $ (NF - 1 )] ++ } END { for (i in a) if (a[i] > 90 )print i}' $netstatFile > $file
drop_ip = `cat $file | awk '{print $2 }'`
for iptables_ip in $drop_ip
do
if [ $iptables_ip != $0 ] && [ - z " ` iptables -L -n | grep DROP | awk '{print$4}'|grep $iptables_ip`" ] && [ -z " ` cat $myIps | grep $iptables_ip ` " ];then
/sbin/iptables -A INPUT -s $iptables_ip -p tcp --dport 80 -j DROP
echo $iptables_ip >> /home/songlin.lu/shell/log/release-forbid-logs-tmp.log
echo '--------------------'$nowDate'----'$iptables_ip >> $logForbidIp
fi
done
文件/home/songlin.lu/shell/log/noforbid_ips.log为白名单列表
tcpReleaseCmd.sh参考代码如下:
# !/bin/sh
today = `date + ' % Y % m % d'`
logReleaseIpLog =/ home / songlin.lu / shell / log / release - iptables - log - $today .log
iptables =/ home / songlin.lu / shell / log / release - iptables - save - tmp.log
tmpFile =/ home / songlin.lu / shell / log / release - forbid - logs - tmp.log
/ sbin / iptables - save > $iptables
drop_ips = `cat $tmpFile `
nowDate = `date + ' % Y -% m -% d % H: % M'`
for iptables_ip1 in $drop_ips
do
if [ ! - z " `cat $iptables |awk /DROP/'{print $4}' | grep $iptables_ip1`" ]
then
/sbin/iptables -D INPUT -s $iptables_ip1 -p tcp --dport 80 -j DROP
echo '--------------------'$nowDate'----'$iptables_ip1 >> $logReleaseIpLog
fi
done
> $tmpFile
此策略相当于给我们的系统设定了门槛,类似公路交通系统内,某马路设定限高4米栏杆,高于4米的车不能在此通行。该策略能预防恶意的或新手写的请求频率不规则的爬虫。
(二)WEB服务器容器层面
a.User-Agent判断 b. connlimit模块判断
每个爬虫会声明自己的User-Agent信息,我们可以通过判断爬虫的User-Agent信息来识别,具体查看相关文档
Apache作connlimit需要mod_limitipconn来实现,一般需要手动编译。
编辑httpd.conf文件,添加如下配置
ExtendedStatus On
LoadModule limitipconn_module modules/mod_limitipconn.so
< IfModule mod_limitipconn.c >
< Location / > # 所有虚拟主机的/目录
MaxConnPerIP 20 # 每IP只允许20个并发连接
NoIPLimit image/* # 对图片不做IP限制
< /Location >
< /IfModule >
Nginx作connlimit,限制ip并发数,比较简单
添加limit_conn 这个变量可以在http, server, location使用 如:limit_conn one 10;
(三)日志层面
通过日志和网站流量分析识别爬虫
用awstats分析服务器日志,用流量统计工具,如Google Analytics来统计IP对应的流量记录,流量统计在网页里面嵌入一段js代码。把统计结果和流量统计系统记录的IP地址进行对比,排除真实用户访问IP,再排除我们希望放行的网页爬虫,比如Google,百度,youdao爬虫等。最后的分析结果就得到爬虫的IP地址。
(四)程序层面
时时反爬虫过滤机制
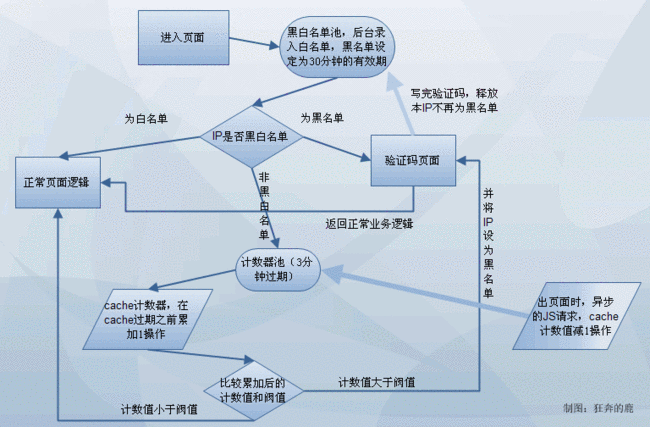
实现起来也比较简单,我们可以用memcached或本地内存来做访问计数器,在缓存过期之前的时间段内(如3分钟),每个IP访问一次,计数器加1,缓存的KEY包括IP,通过计数器得到的值,判断超过一个阀值,这个IP很可能有问题,那么就可以返回一个验证码页面,要求用户填写验证码。如果是爬虫的话,当然不可能填写验证码,就被拒掉了,保护了后端的资源。
阀值的设定也是很重要的,不同的系统不一样。
我们将这个过滤机制改进一下,将更加准确。 即我们在网页的最下面添加一个JS的异步请求,此异步请求用来减计数器的值,进页面时对IP进行加值,出页面时减值,生成一个差值。 根据我们之前的分析,爬虫不会执行异步JS减值请求。 这样可以从生成的值的大小上判断这个IP是否为爬虫。
程序逻辑如下图所示:
[文章作者:狂奔的鹿(陆松林)本文版本:v1.0 转载请注明原文链接:http://www.cnblogs.com/dynamiclu/]