RuleML入门(下)
使用Datalog RuleML正向推理
- 鉴于Peter Miller之前消费的事实,
- 匹配规则<if>;
- 将<Ind>Peter Miller</Ind >绑定到<Var>顾客</Var>变量上;
- 使用相同的变量再绑定到规则<then>上,进行处理
<Atom> <Ind>Peter Miller</Ind> <op><Rel>是优质的</Rel></op> </Atom>
在这个推导的例子中,规则和事实,将一起使用:
规则<If>匹配事实,将"<Ind>Peter Miller</Ind >"绑定到"<Var>顾客</Var>"变量上;
使用相同的变量再绑定到规则<then>上,一个新的<Atom>推导出"<Ind>Peter Miller</Ind>"是一个"<Rel>是优质的</ Rel>"顾客。
Datalog Rule联结
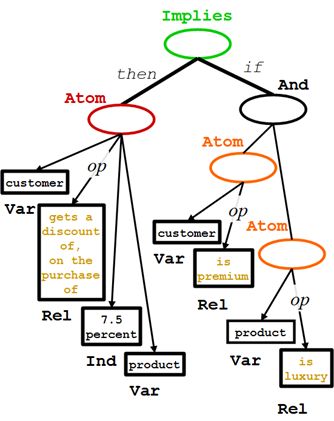
一位顾客购买产品时享受了7.5%的折扣,如果顾客是优质的,则该产品是奢侈品。
 ...
...
<if>
<And>
<Atom>
<Var>顾客</Var>
<Rel>是优质的</Rel>
</Atom>
<Atom>
<Var>产品</Var>
<Rel>是奢侈品</Rel>
</Atom>
</And>
</if>
</Implies>
除了使用单一的Atom公式中的<If>线条,一个Datalog RuleML规则也可以使用整个联结的Atom。这将允许复杂的条件通过'联结'包含各种变量。
产品分类事实
上面一章提到引入了产品,那么接下来我们将细化产品的规则
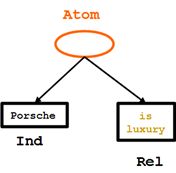 <Atom>
<Atom>
<Ind>Porsche</Ind>
<Rel>is luxury</Rel>
</Atom>
"A Porsche is a luxury product."
"保时捷是一种奢侈品"
虽然"<Rel>是优质的</ Rel>"是我们定义的第一条规则,接下来我们将定义"<Rel>是奢侈品</ Rel>":
"保时捷是一种奢侈品"
同样,这自然语言的语句也是可以用XML表示,同时可以看作成一个OrdLab Tree
反向推理Backward Chaining Derivation
- 目标:"Peter Miller买保时捷能拿到什么样的折扣?"
-
折扣规则的结果=目标绑定如下参数
- 顾客:Peter Miller
- 产品:保时捷
- 折扣:7.5%
这个新的规则和事实可以结合我们前面的例子变成一个链式推导,如下:
第一步,关系"<Rel>折扣</Rel>"的规则匹配到<if>连接到"<Rel>是优质的</Rel>"规则,接下来如前面所述,绑定"<Ind>Peter Miller</Ind>"至变量"<Var>顾客</Var>"。
第二步,仅匹配到"<Rel>是奢侈品</Rel>"事实,绑定"<Ind>保时捷</Ind>"至变量"<Var>产品</Var>"。
-
如果下面两个目标达成,则总目标达成
- 子目标:"Peter Miller是优质的客户"
- 子目标:"保时捷是一种奢侈品"
-
两个子目标都达成
- "Peter Miller是优质的客户"通过推演
- "保时捷是一种奢侈品"通过事实
所以,"<Rel>折扣</Rel>"规则达成,也证明了接下来的Atom…
反向推理结果
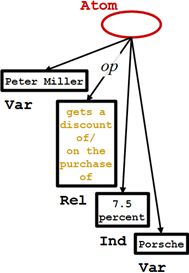 Peter Miller gets a discount of 7.5 percent on the purchase of a Porsche.
Peter Miller gets a discount of 7.5 percent on the purchase of a Porsche.
Peter Miller买保时捷时享受了7.5%的折扣。
<Atom>
<Ind>Peter Miller</Ind>
<Rel>享受…折扣,在买…的时候</Rel>(这就是一个二元关系)
<Ind>7.5%</Ind>
<Ind>保时捷</Ind>
</Atom>
这个推导出的Atom标记可以被存储以供进一步处理:
同样,这段XML也可以被看作是一个OrdLab Tree。
请注意,第一条规则我们是自下而上(正向推理)的方式进行解释,而在第二条规则是自上而下(反向推理)的方式解释。其实,每个规则都可以在两种方式下使用;默认情况下,RuleML是中性的,与方向无关。
RuleML hornlog (Horn Logic with Functional Expressions)
<Atom> <Ind>Peter Miller</Ind> <Rel>享受…折扣/在买…的时候</Rel> <Expr> <Fun>%</Fun> <Data xsi:type="xs:decimal">7.5</Data> </Expr> <Ind>保时捷</Ind> </Atom>
RuleML使用Datalog作为它的子语言家族的一部分。更神奇的子语言是RuleML hornlog(Horn logic),其中包括带有元素<Expr>和<Fun>的功能。
RuleML1.0的XML语法由XML schemas和RELAX NG schemas所定义。POSL可在线转换为RuleML/ XML。Datalog RuleML和Hornlog RuleML的语义采用Herbrand模型。Datalog和Hornlog RuleML实现是已经存在的,包括(NAF Hornlog)RuleML参考了OO jDREW的实现。
RuleML查询与变量(all non-ground sublanguages)
<Rulebase> <Query> <Atom> <Ind>Peter Miller</Ind> <Rel>享受…折扣/在买…的时候</Rel> <Var>x</Var> <Var>y</Var> </Atom> </Query> </Rulebase>
</Query>:用来包装查询内容(可选:使用<formula>标记在外面),标记在"implicit <Rulebase>"内。这样就使得说明性内容与执行程序相分离(比如使用KQML驱动,他也有类似"ask"的执行)。
<Query> <Atom> <Ind>Peter Miller</Ind> <Rel>享受…折扣/在买…的时候</Rel> <repo><Var>x</Var></repo> </Atom> </Query>
<Plex> <Ind>7.5%</Ind> <Ind>保时捷 </Ind> </Plex>
<repo>:在<Atom>, <Expr>和<Plex>标签中需要重置变量,使用该标签。需要注意的是,<Plex>是预先生成的,所以<repo>是在Datalog中唯一可以使用的标签。
RuleML Slots
<Atom> <oid><Ind>Peter Miller</Ind></oid> <Rel>is a Customer</Rel> <slot> <Ind>who has a Status of</Ind> <Ind>premium</Ind> </slot> <resl> <Var>x</Var> </resl> </Atom>
</slot>:一个用户定义的扩展槽,包括名称(第一个Ind)和过滤条件(第二个Ind)。
<resl>:在<Atom>, <Expr>和<Plex>标签中需要重置slot的变量,使用该标签。<Plex>是预先生成的,所以<resl>是在Datalog中唯一可以使用的标签。
执行,否定,量词和相等比较
<Assert> <Neg> <Exists> <Var>x</Var> <Forall> <Var>y</Var> <Equal> <Var>x</Var> <Var>y</Var> </Equal> </Forall> </Exists> </Neg> </Assert>
RuleML这个官方的入门教程,大致介绍了规则的定义以及使用方法,但是感觉很多东西没有说清楚,当然也有很多东西我也没能理解,之后我将准备看看该标准中具体提供的内容,做一个真实的例子来体验。