分布式内存对象缓存系统Memcached-概述
全面掌握Memcached
1. 概述
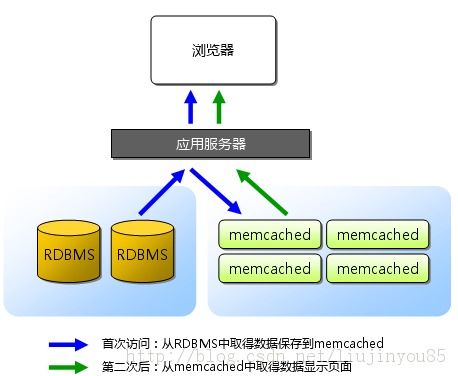
Memcached是danga.com(运营LiveJournal的技术团队)开发的一套分布式内存对象缓存系统,是为了加快网站http://www.livejournal.com/访问速度而诞生的一个项目,用于在动态系统中减少数据库负载,提升性能。许多Web应用都将数据保存到RDBMS(关系数据库管理系统)中,应用服务器从中读取数据并在浏览器中显示。但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、网站显示延迟等重大影响。有的Web应用将Session信息保存到inteinfo.exe进程、ASP.NETState Service中,这类Web应用搭建负载时,会导致Session丢失。就需要将数据缓存到内存,并支持分布式的需求。对于支持分布式缓存有:MemCached、Redis、MongoDB等。这里我将通过网络和书籍收集到的MemCached技术整理,并分享给大家。
1.1memcached是怎么工作的
MemCached是高性能的分布式内存缓存服务器。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性
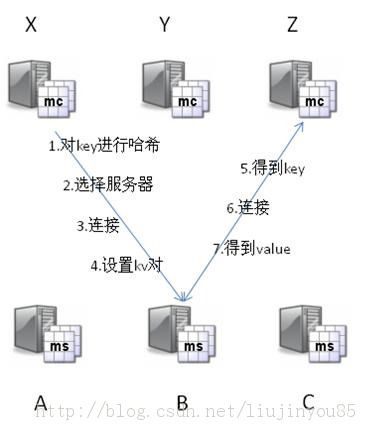
Memcached通过在内存里维护一个统一的巨大的hash表来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。它的神奇来自两阶段哈希(two-stage hash)。Memcached就像一个巨大的、存储了很多<key,value>对的哈希表。通过key,可以存储或查询任意的数据。客户端可以把数据存储在多台memcached上。当查询数据时,客户端首先参考节点列表计算出key的哈希值(阶段1哈希),进而选中一个节点;客户端将请求发送给选中的节点,然后memcached节点通过一个内部的哈希算法(阶段2哈希),查找真正的数据(item)。
举个列子,假设有3个客户端Client 1, Client 2, Client 3,3台memcached A, B, C:
Client 1想把数据"bar"以key "foo"存储。Client 1首先参考节点列表(A, B, C),计算key "foo"的哈希值,假设memcached B被选中。接着,Client 1直接connect到memcached B,通过key "foo"把数据"bar"存储进去。Client 2使用与Client 1相同的客户端库(意味着阶段1的哈希算法相同),也拥有同样的memcached列表(A, B, C)。
于是,经过相同的哈希计算(阶段1),Client 2计算出key "foo"在memcached B上,然后它直接请求memcached B,得到数据"bar"。
各种客户端在memcached中数据的存储形式是不同的(perl Storable, php serialize, java hibernate, JSON等)。一些客户端实现的哈希算法也不一样。但是,memcached服务器端的行为总是一致的。
最后,从实现的角度看,memcached是一个非阻塞的、基于事件的服务器程序。这种架构可以很好地解决C10K problem(网络服务器在处理数以万计的客户端连接时,往往出现效率低下甚至是瘫痪,被称为C10K问题) ,并具有极佳的可扩展性。
1.2 Memcached的特点
1)协议简单。Memcached的服务器客户端通信并不使用复杂的XML等格式, 而使用简单的基于文本行的协议。因此,通过telnet也能在Memcached上保存数据、取得数据。
2) 基于libevent的事件处理。libevent是一个事件触发的网络库,适用于windows、linux、bsd等多种平台,内部使用select、epoll、kqueue等系统调用管理事件机制。而且libevent在使用上可以做到跨平台,而且根据libevent官方网站上公布的数据统计,似乎也有着非凡的性能。
3)内置内存存储方式。为了提高性能,Memcached中保存的数据都存储在Memcached内置的内存存储空间中。 由于数据仅存在于内存中,因此重启Memcached、重启操作系统会导致全部数据消失。 另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。 memcached本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。
4)Memcached不互相通信的分布式。Memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。各个Memcached不会互相通信以共享信息。那么,怎样进行分布式呢?这完全取决于客户端的实现。Cache::Memcached的分布式方法简单来说,就是“根据服务器台数的余数进行分散”。 求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器。
5)Memcached的缓存是一种分布式的,可以让不同主机上的多个用户同时访问, 因此解决了共享内存只能单机应用的局限,更不会出现使用数据库做类似事情的时候,磁盘开销和阻塞的发生。
6)许多语言都实现了连接Memcached的客户端,其中以Perl、PHP为主。 仅仅Memcached网站上列出的语言就有Perl、PHP、Python、Ruby、C#、C/C++等等。
1.3 memcached最大的优势
Memcached最大的好处就是它带来了极佳的水平可扩展性,特别是在一个巨大的系统中。由于客户端自己做了一次哈希,那么我们很容易增加大量memcached到集群中。memcached之间没有相互通信,因此不会增加 memcached的负载;没有多播协议,不会网络通信量爆炸(implode)。memcached的集群很好用。内存不够了?增加几台memcached吧;CPU不够用了?再增加几台吧;有多余的内存?在增加几台吧,不要浪费了。
基于memcached的基本原则,可以相当轻松地构建出不同类型的缓存架构。
1.4 MemCached的分布式
(1)MemCached服务器端并没有“分布式”功能。分布式是完全由客户端程序库实现的。这种分布式是MemCached的最大特点。
(2)set(存数据到MemCached)时,set(‘key’,data),将’key’传给客户端程序库后,客户端实现的算法就会根据“键”来决定保存数据的MemCached服务器。服务器选定后,即命令它保存(’key’,data);
(3)get(从MemCached取数据)时,get(‘key’),此时客户端把’key’传递给函数库,函数库通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值。
(4)以上将不同的键保存到不同的服务器上,就实现了MemCached的分布式。MemCached服务器增多后,键就会分散,即使一台MemCached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
(5)Cache::MemCached的分布式算法简单来说,就是“根据服务器台数的余数进行分散”。求得键的整数哈希值[使用crc32函数,如crc32($key)],再除以服务器台数,根据其余数来选择服务器。余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大
2. Memcached基础知识说明
2.1 Memcached的cache机制
目前MemCached采用SlabAllocator的机制分配、管理内存。SlabAllocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。

(1)如上图所示,SlabAllocation将分配的内存分割成各种尺寸的块(chunk,用于缓存记录的内存空间),并把尺寸相同的块分成组(chunk的集合,每个chunk的大小相同)。默认一个slab(chunks)的大小是1MB,叫1Page。
(2)slaballocator有重复使用已分配的内存的目的。也就是说,分配到的内存不会释放,而是重复利用。
(3)MemCached根据收到的数据的大小,选择最适合数据大小的slab。MemCached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。如当来了100bytes数据,会选择最合适的112bytes的chunk(假如slabclasses中chunk的大小包含有88bytes、112bytes、144bytes……)
(4)SlabAllocator解决了当初的内存碎片问题,但由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了。
2.2 MemCached的删除机制
(1)MemCached是缓存,所以数据不会永久保存在服务器上,其实数据不会真正从memcached中消失。实际上MemCached不会释放已分配的内存,记录超时后,客户端就无法再看见该记录,其存储空间即可重复使用。
(2)LazyExpiration:MemCached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术被称为lazyexpiration(延期过期技术)。因此,MemCached不会在过期监视上耗费CPU时间。
(3)MemCached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为LeastRecently Used(LRU)机制来分配空间。顾名思义,这是删除“最近最少使用”的记录的机制。因此,当memcached的内存空间不足时(无法从slabclass获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。
Memcached主要的cache机制是LRU(最近最少用)算法+超时失效。当您存数据到memcached中,可以指定该数据在缓存中可以呆多久Which is forever, or some time in the future。如果memcached的内存不够用了,过期的slabs会优先被替换,接着就轮到最老的未被使用的slabs。
2.3 Memcached冗余机制
不实现! Memcached应该是应用的缓存层。它的设计本身就不带有任何冗余机制。如果一个memcached节点失去了所有数据,您应该可以从数据源(比如数据库)再次获取到数据。需要特别注意,应用应该可以容忍节点的失效。不要写一些糟糕的查询代码,寄希望于memcached来保证一切!如果您担心节点失效会大大加重数据库的负担,那么您可以采取一些办法。比如您可以增加更多的节点(来减少丢失一个节点的影响),热备节点(在其他节点down了的时候接管IP),等等。
2.4 Memcached的内存分配器
为什么不使用malloc/free!?要使用slabs?
实际上,这是一个编译时选项。默认会使用内部的slab分配器。您确实应该使用内建的slab分配器。最早的时候,memcached只使用malloc/free来管理内存。然而,这种方式不能与OS的内存管理协调很好地工作。反复地malloc/free造成了内存碎片,OS最终花费大量的时间去查找连续的内存块来满足malloc的请求,而不是运行memcached进程。如果您不同意,当然可以使用malloc!
slab分配器就是为了解决这个问题而生的。内存被分配并划分成chunks,一直被重复使用。因为内存被划分成大小不等的slabs,如果item的大小与被选择存放它的slab不是很合适的话,就会浪费一些内存。
2.5 Memcached命令说明
所有的被发送到memcached的单个命令是完全原子的。如果您针对同一份数据同时发送了一个set命令和一个get命令,它们不会影响对方。它们将被串行化、先后执行。即使在多线程模式,所有的命令都是原子的,除非程序有bug
命令序列不是原子的。如果您通过get命令获取了一个item,修改了它,然后想把它set回memcached,我们不保证这个item没有被其他进程(process,未必是操作系统中的进程)操作过。在并发的情况下,您也可能覆写了一个被其他进程set的item。
memcached 1.2.5以及更高版本,提供了gets和cas命令,它们可以解决上面的问题。如果您使用gets命令查询某个key的item,memcached会给您返回该item当前值的唯一标识。如果您覆写了这个item并想把它写回到memcached中,您可以通过cas命令把那个唯一标识一起发送给memcached。如果该item存放在memcached中的唯一标识与您提供的一致,您的写操作将会成功。如果另一个进程在这期间也修改了这个item,那么该item存放在memcached中的唯一标识将会改变,您的写操作就会失败。
通常,基于memcached中item的值来修改item,是一件棘手的事情。除非您很清楚自己在做什么,否则请不要做这样的事情。
3. 如何使用Memcached
3.1 Memcached如何处理容错
不处理!在memcached节点失效的情况下,集群没有必要做任何容错处理。如果发生了节点失效,应对的措施完全取决于用户。节点失效时,下面列出几种方案供您选择:
(1)忽略它! 在失效节点被恢复或替换之前,还有很多其他节点可以应对节点失效带来的影响。
(2)把失效的节点从节点列表中移除。做这个操作千万要小心!在默认情况下(余数式哈希算法),客户端添加或移除节点,会导致所有的缓存数据不可用!因为哈希参照的节点列表变化了,大部分key会因为哈希值的改变而被映射到(与原来)不同的节点上。
(3) 启动热备节点,接管失效节点所占用的IP。这样可以防止哈希紊乱(hashing chaos)。如果希望添加和移除节点,而不影响原先的哈希结果,可以使用一致性哈希算法(consistent hashing)。(一致性Hash算法的目的有两点:一是节点变动后其他节点受影响尽可能小;二是节点变动后数据重新分配尽可能均衡 Memcached客户端有各种语言的版本供大家使用,包括java,c,php,.net等等)
(4)两次哈希(reshing)。当客户端存取数据时,如果发现一个节点down了,就再做一次哈希(哈希算法与前一次不同),重新选择另一个节点(需要注意客户端并没有把down的节点从节点列表中移除,下次还是有可能先哈希到它)。如果某个节点时好时坏,两次哈希的方法就有风险了,好的节点和坏的节点上都可能存在脏数据(stale data)。
3.2 Memcached如何做身份验证
没有身份认证机制!memcached是运行在应用下层的软件(身份验证应该是应用上层的职责)。memcached的客户端和服务器端之所以是轻量级的,部分原因就是完全没有实现身份验证机制。这样,memcached可以很快地创建新连接,服务器端也无需任何配置。
如果您希望限制访问,您可以使用防火墙,建议Memcached部署在防火墙后面,或者让memcached监听unix domain socket。
3.3 Memcached多线程如何使用
线程就是定律(threads rule)!在Steven Grimm和Facebook的努力下,memcached 1.2及更高版本拥有了多线程模式。多线程模式允许memcached能够充分利用多个CPU,并在CPU之间共享所有的缓存数据。memcached使用一种简单的锁机制来保证数据更新操作的互斥。相比在同一个物理机器上运行多个memcached实例,这种方式能够更有效地处理multi gets。
如果您的系统负载并不重,也许您不需要启用多线程工作模式。如果您在运行一个拥有大规模硬件的、庞大的网站,您将会看到多线程的好处。更多信息请参见:http://code.sixapart.com/svn/memcached/trunk/server/doc/threads.txt。
总结:命令解析(memcached在这里花了大部分时间)可以运行在多线程模式下。memcached内部对数据的操作是基于很多全局锁的(因此这部分工作不是多线程的)。未来对多线程模式的改进,将移除大量的全局锁,提高memcached在负载极高的场景下的性能。
3.4 Memcached中item如何批量导入导出
您不应该这样做!Memcached是一个非阻塞的服务器。任何可能导致memcached暂停或瞬时拒绝服务的操作都应该值得深思熟虑。向memcached中批量导入数据往往不是您真正想要的!想象看,如果缓存数据在导出导入之间发生了变化,您就需要处理脏数据了;如果缓存数据在导出导入之间过期了,您又怎么处理这些数据呢?
因此,批量导出导入数据并不像您想象中的那么有用。不过在一个场景倒是很有用。如果您有大量的从不变化的数据,并且希望缓存很快热(warm)起来,批量导入缓存数据是很有帮助的。虽然这个场景并不典型,但却经常发生,因此我们会考虑在将来实现批量导出导入的功能。
但是我确实需要把memcached中的item批量导出导入,怎么办?
如果您需要批量导出导入,最可能的原因一般是重新生成缓存数据需要消耗很长的时间,或者数据库坏了让您饱受痛苦。如果一个memcached节点down了让您很痛苦,那么您还会陷入其他很多麻烦。您的系统太脆弱了。您需要做一些优化工作。比如处理"惊群"问题(比如 memcached节点都失效了,反复的查询让您的数据库不堪重负...),或者优化不好的查询。记住,Memcached 并不是您逃避优化查询的借口。
如果您的麻烦仅仅是重新生成缓存数据需要消耗很长时间(15秒到超过5分钟),您可以考虑重新使用数据库。这里给出一些提示:
(1)使用MogileFS(或者CouchDB等类似的软件)在存储item。把item计算出来并dump到磁盘上。MogileFS可以很方便地覆写item,并提供快速地访问。您甚至可以把MogileFS中的item缓存在memcached中,这样可以加快读取速度。 MogileFS+Memcached的组合可以加快缓存不命中时的响应速度,提高网站的可用性。
(2)重新使用MySQL。MySQL的InnoDB主键查询的速度非常快。如果大部分缓存数据都可以放到VARCHAR字段中,那么主键查询的性能将更好。从memcached中按key查询几乎等价于MySQL的主键查询:将key 哈希到64-bit的整数,然后将数据存储到MySQL中。您可以把原始(不做哈希)的key存储到普通的字段中,然后建立二级索引来加快查询...key被动地失效,批量删除失效的key,等等。
上面的方法都可以引入memcached,在重启memcached的时候仍然提供很好的性能。由于您不需要当心"hot"的item被memcached LRU算法突然淘汰,用户再也不用花几分钟来等待重新生成缓存数据(当缓存数据突然从内存中消失时),因此上面的方法可以全面提高性能。
关于这些方法的细节,详见博客:http://dormando.livejournal.com/495593.html 。
3.5 Memcached能接受的key的最大长度
key的最大长度是250个字符。需要注意的是,250是memcached服务器端内部的限制,如果您使用的客户端支持"key的前缀"或类似特性,那么key(前缀+原始key)的最大长度是可以超过250个字符的。我们推荐使用较短的key,因为可以节省内存和带宽。
3.6 Memcached对item的过期时间限制
过期时间最大可以达到30天。memcached把传入的过期时间(时间段)解释成时间点后,一旦到了这个时间点,memcached就把item置为失效状态。这是一个简单但obscure的机制。
3.7 Memcached最大能存储多大的单个item
1MB。如果你的数据大于1MB,可以考虑在客户端压缩或拆分到多个key中。为什么单个item的大小被限制在1M byte之内?
简单的回答:因为内存分配器的算法就是这样的。详细的回答:Memcached的内存存储引擎(引擎将来可插拔...),使用slabs来管理内存。内存被分成大小不等的slabs chunks(先分成大小相等的slabs,然后每个slab被分成大小相等chunks,不同slab的chunk大小是不相等的)。chunk的大小依次从一个最小数开始,按某个因子增长,直到达到最大的可能值。
如果最小值为400B,最大值是1MB,因子是1.20,各个slab的chunk的大小依次是:slab1 - 400B slab2 - 480B slab3 - 576B ... slab中chunk越大,它和前面的slab之间的间隙就越大。因此,最大值越大,内存利用率越低。Memcached必须为每个slab预先分配内存,因此如果设置了较小的因子和较大的最大值,会需要更多的内存。
还有其他原因使得您不要这样向memcached中存取很大的数据...不要尝试把巨大的网页放到mencached中。把这样大的数据结构load和unpack到内存中需要花费很长的时间,从而导致您的网站性能反而不好。如果您确实需要存储大于1MB的数据,你可以修改slabs.c:POWER_BLOCK的值,然后重新编译memcached;或者使用低效的malloc/free。其他的建议包括数据库、MogileFS等。
我可以在不同的memcached节点上使用大小不等的缓存空间吗?这么做之后,memcached能够更有效地使用内存吗?
Memcache客户端仅根据哈希算法来决定将某个key存储在哪个节点上,而不考虑节点的内存大小。因此,您可以在不同的节点上使用大小不等的缓存。但是一般都是这样做的:拥有较多内存的节点上可以运行多个memcached实例,每个实例使用的内存跟其他节点上的实例相同。
什么是二进制协议,我该关注吗?二进制协议尝试为端提供一个更有效的、可靠的协议,减少客户端/服务器端因处理协议而产生的CPU时间。根据Facebook的测试,解析ASCII协议是memcached中消耗CPU时间最多的环节。所以,我们为什么不改进ASCII协议呢?
4. Memcached、服务器的local cache和MySQL的query cache
4.1 Memcached和MySQL的query cache相比
把memcached引入应用中,还是需要不少工作量的。MySQL有个使用方便的query cache,可以自动地缓存SQL查询的结果,被缓存的SQL查询可以被反复地快速执行。Memcached与之相比,怎么样呢?MySQL的query cache是集中式的,连接到该query cache的MySQL服务器都会受益。
(1)当您修改表时,MySQL的query cache会立刻被刷新(flush)。存储一个memcached item只需要很少的时间,但是当写操作很频繁时,MySQL的query cache会经常让所有缓存数据都失效。
(2)在多核CPU上,MySQL的query cache会遇到扩展问题(scalability issues)。在多核CPU上,query cache会增加一个全局锁(global lock), 由于需要刷新更多的缓存数据,速度会变得更慢。
(3)在MySQL的query cache中,我们是不能存储任意的数据的(只能是SQL查询结果)。而利用memcached,我们可以搭建出各种高效的缓存。比如,可以执行多个独立的查询,构建出一个用户对象(user object),然后将用户对象缓存到memcached中。而query cache是SQL语句级别的,不可能做到这一点。在小的网站中,query cache会有所帮助,但随着网站规模的增加,query cache的弊将大于利。
(4)query cache能够利用的内存容量受到MySQL服务器空闲内存空间的限制。给数据库服务器增加更多的内存来缓存数据,固然是很好的。但是,有了memcached,只要您有空闲的内存,都可以用来增加memcached集群的规模,然后您就可以缓存更多的数据。
4.2 Memcached和服务器的local cache(比如PHP的APC、mmap文件等)相比
首先,local cache有许多与上面(query cache)相同的问题。local cache能够利用的内存容量受到(单台)服务器空闲内存空间的限制。不过,local cache有一点比memcached和query cache都要好,那就是它不但可以存储任意的数据,而且没有网络存取的延迟。
(1)local cache的数据查询更快。考虑把highly common的数据放在local cache中吧。如果每个页面都需要加载一些数量较少的数据,考虑把它们放在local cached吧。
(2)local cache缺少集体失效(group invalidation)的特性。在memcached集群中,删除或更新一个key会让所有的观察者觉察到。但是在local cache中, 我们只能通知所有的服务器刷新cache(很慢,不具扩展性),或者仅仅依赖缓存超时失效机制。
(3)local cache面临着严重的内存限制,这一点上面已经提到。
5. Memcached命令行参数说明
5.1启动Memcache 常用参数
-p <num> 设置TCP端口号(默认不设置为: 11211)
-U <num> UDP监听端口(默认: 11211, 0 时关闭)
-l <ip_addr> 绑定地址(默认:所有都允许,无论内外网或者本机更换IP,有安全隐患,若设置为127.0.0.1就只能本机访问)
-d 以daemon方式运行
-u <username> 绑定使用指定用于运行进程<username>
-m <num> 允许最大内存用量,单位M (默认: 64 MB)
-P <file> 将PID写入文件<file>,这样可以使得后边进行快速进程终止, 需要与-d 一起使用
在linux下:./usr/local/bin/memcached -d -u root -l 192.168.1.197 -m 2048 -p 12121
在window下:d:\App_Serv\memcached\memcached.exe -d RunService -l 127.0.0.1 -p 11211 -m 500
在windows下注册为服务后运行:
sc.exe create Memcached_srv binpath= “d:\App_Serv\memcached\memcached.exe -d RunService -p 11211 -m 500″start= auto
net start Memcached
5.2 连接
telnet 127.0.0.1 11211
5.3 基本命令
您将使用五种基本 memcached 命令执行最简单的操作。这些命令和操作包括:
Set、add、replace、get、delete
前三个命令是用于操作存储在 memcached 中的键值对的标准修改命令。它们都非常简单易用,且都使用如下 所示的语法:
command <key> <flags> <expiration time> <bytes>
<value>
| 参数 |
用法 |
| key |
key 用于查找缓存值 |
| flags |
可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息 |
| expiration time |
在缓存中保存键值对的时间长度(以秒为单位,0 表示永远) |
| bytes |
在缓存中存储的字节点 |
| value |
存储的值(始终位于第二行) |
set 。set 命令用于向缓存添加新的键值对。如果键已经存在,则之前的值将被替换。
如果使用 set 命令正确设定了键值对,服务器将使用单词 STORED 进行响应。本示例向缓存中添加了一个键值对,其键为userId,其值为12345。并将过期时间设置为 0,这将向 memcached 通知您希望将此值存储在缓存中直到删除它为止。
add 。仅当缓存中不存在键时,add 命令才会向缓存中添加一个键值对。如果缓存中已经存在键,则之前的值将仍然保持相同,并且您将获得响应 NOT_STORED。
replace 。仅当键已经存在时,replace 命令才会替换缓存中的键。如果缓存中不存在键,那么您将从 memcached 服务器接受到一条 NOT_STORED 响应。
Get。get 命令用于检索与之前添加的键值对相关的值。您将使用 get 执行大多数检索操作。get 命令相当简单。您使用一个键来调用 get,如果这个键存在于缓存中,则返回相应的值。如果不存在,则不返回任何内容。
Delete。最后一个基本命令是 delete。delete 命令用于删除 memcached 中的任何现有值。您将使用一个键调用delete,如果该键存在于缓存中,则删除该值。如果不存在,则返回一条NOT_FOUND 消息。可以在 memcached 中使用的两个高级命令是 gets 和 cas。gets 和cas 命令需要结合使用。您将使用这两个命令来确保不会将现有的名称/值对设置为新值(如果该值已经更新过)。
Gets。gets 命令的功能类似于基本的 get 命令。两个命令之间的差异在于,gets 返回的信息稍微多一些:64 位的整型值非常像名称/值对的 “版本” 标识符。考虑 get 和 gets 命令之间的差异。gets 命令将返回一个额外的值 — 在本例中是整型值 4,用于标识名称/值对。如果对此名称/值对执行另一个set 命令,则gets 返回的额外值将会发生更改,以表明名称/值对已经被更新。
cas 。cas(check 和 set)是一个非常便捷的 memcached 命令,用于设置名称/值对的值(如果该名称/值对在您上次执行 gets 后没有更新过)。它使用与 set 命令相类似的语法,但包括一个额外的值:gets 返回的额外值。注意,我并未使用 gets 最近返回的整型值,并且 cas 命令返回 EXISTS 值以示失败。从本质上说,同时使用gets 和cas 命令可以防止您使用自上次读取后经过更新的名称/值对。
stats 。stats 命令的功能正如其名:转储所连接的 memcached 实例的当前统计数据。在下例中,执行 stats 命令显示了关于当前 memcached 实例的信息:
STAT pid 22459 进程ID
STAT uptime 1027046 服务器运行秒数
STAT time 1273043062 服务器当前unix时间戳
STAT version 1.4.4 服务器版本
STAT pointer_size 64 操作系统字大小(这台服务器是64位的)
STAT rusage_user 0.040000 进程累计用户时间
STAT rusage_system 0.260000 进程累计系统时间
STAT curr_connections 10 当前打开连接数
STAT total_connections 82 曾打开的连接总数
STAT connection_structures 13 服务器分配的连接结构数
STAT cmd_get 54 执行get命令总数
STAT cmd_set 34 执行set命令总数
STAT cmd_flush 3 指向flush_all命令总数
STAT get_hits 9 get命中次数
STAT get_misses 45 get未命中次数
STAT delete_misses 5 delete未命中次数
STAT delete_hits 1 delete命中次数
STAT incr_misses 0 incr未命中次数
STAT incr_hits 0 incr命中次数
STAT decr_misses 0 decr未命中次数
STAT decr_hits 0 decr命中次数
STAT cas_misses 0 cas未命中次数
STAT cas_hits 0 cas命中次数
STAT cas_badval 0 使用擦拭次数
STAT auth_cmds 0
STAT auth_errors 0
STAT bytes_read 15785 读取字节总数
STAT bytes_written 15222 写入字节总数
STAT limit_maxbytes 1048576 分配的内存数(字节)
STAT accepting_conns 1 目前接受的链接数
STAT listen_disabled_num 0
STAT threads 4 线程数
STAT conn_yields 0
STAT bytes 0 存储item字节数
STAT curr_items 0 item个数
STAT total_items 34 item总数
STAT evictions 0 为获取空间删除item的总数
flush_all 。用于清理缓存中的所有名称/值对。如果您需要将缓存重置到干净的状态,则 flush_all 能提供很大的用处。
6. 参考资料
http://blog.csdn.net/liujinyou85/article/details/10023063
http://adrianset.iteye.com/blog/1976475
http://www.iteye.com/blogs/tag/memcached
http://blog.csdn.net/wanghai__/article/details/8539435
http://www.cnblogs.com/fll/archive/2008/05/17/1201540.html
http://www.360doc.com/content/13/0522/18/1542811_287328877.shtml
http://www.360doc.com/content/12/1028/22/2472295_244347968.shtml