哈工大软件学院编译原理实验1——词法分析
这次实验被“过来人”们定位非常easy,实验内容例如以下:
-----------------------------------------------------------------------------------
对例如以下工作进行展开描写叙述
(1) 给出语言的词法规则描写叙述
· 标识符、keyword、整常数、字符常数、浮点常数
· 单界符:+,-,×,;,…
· 双界符:/*,:=,>=,<=,!=,…
· 凝视
(2) 针对这样的单词的状态转换图和程序框图
(3) 核心数据结构的设计
如符号表、keyword等
(4) 错误处理
错误的位置及类型等
-----------------------------------------------------------------------------------
这次实验我是用python写了一个简单的C语言的词法分析器,词法分析器的编写有非常多种方式,比方能够用正則表達式编写,也能够用LEX工具自己主动生成,当然,也能够用比較朴素的方式——基于有穷自己主动机(Finite Automata,FA),也即基于有穷自己主动机的状态转移来编敲代码。
说起这个有穷自己主动机(Finite Automata,FA),真心感觉是个好东西,分析问题简单清晰,并且非常直观。记得对有穷自己主动机有感性认识是在上学期考试分数并不高的《计算机网络》课上,全龙哥讲那个RDT协议的不同版本号的时候,用这个自己主动机来表明遇到不同情况时发送端和接收端要採取的行动。
自己主动机的形式化定义:
M=(Q,Σ,δ,q0,F)
„ Q→有穷状态集
„ Σ→有穷输入字母表
„ δ→从Q×Σ→2Q的映射函数(2Q是Q的幂集)
„ q0∈Q,是唯一的初态
„ F →终态集合,是Q的子集
这里说说我个人的理解。对有穷自己主动机的形式化定义的理解比較重要的是上述第三条说明的理解:δ→从Q×Σ→2Q的映射函数。也即这个δ定义了某个详细FA的状态间转移关系,或者说定义了某个FA的状态间转移的规则。所谓状态的幂集就是状态集Q的全部子集构成的集族。则这句话的字面意思是:状态集和字母表的笛卡尔乘积到状态集的幂集的映射函数。
比方:M1 = (Q,Σ,δ,q0,F),当中Q = {q,q0,q1,q2...,qn},又((q,a) , {q1,q2,q3})∈δ,也即δ((q,a)) = {q1,q2,q3}。则说明自己主动机M1有一个状态q,q在遇到字母a的时候,自己主动机状态可能跳转到q1,q2,q3三个状态。自己主动机又分为有穷自己主动机和无穷自己主动机两种,这里不再赘述。
有穷自己主动机能够用状态图直观表示,样例见下文中图。
至于词法分析的一些基本知识,简单叙述一下:
-----------------------------------------------------------------------------------
定义:
词法分析器的功能输入源程序,依照构词规则分解成一系列单词符号。单词是语言中具有独立意义的最小单位,包含keyword、标识符、运算符、界符和常量等
(1) keyword 是由程序语言定义的具有固定意义的标识符。比如,Pascal 中的begin,end,if,while都是保留字。这些字通常不用作一般标识符。
(2) 标识符 用来表示各种名字,如变量名,数组名,过程名等等。
(3) 常数 常数的类型一般有整型、实型、布尔型、文字型等。
(4) 运算符 如+、-、*、/等等。
(5) 界符 如逗号、分号、括号、等等。
输出:
词法分析器所输出单词符号经常表示成例如以下的二元式:
(单词种别,单词符号的属性值)
单词种别通经常使用整数编码。标识符一般统归为一种。常数则宜按类型(整、实、布尔等)分种。keyword可将其全体视为一种。运算符可採用一符一种的方法。界符一般用一符一种的方法。对于每一个单词符号,除了给出了种别编码之外,还应给出有关单词符号的属性信息。单词符号的属性是指单词符号的特性或特征。
演示样例:
比方例如以下的代码段:
while(i>=j) i--;经词法分析器处理后,它将被转为例如以下的单词符号序列:
<while, _> <(, _> <id, 指向i的符号表项的指针> <>=, _> <id, 指向j的符号表项的指针> <), _> <id, 指向i的符号表项的指针> <--, _> <;, _>词法分析分析器作为一个独立子程序:
词法分析是编译过程中的一个阶段,在语法分析前进行。词法分析作为一遍,能够简化设计,改进编译效率,添加�编译系统的可移植性。也能够和语法分析结合在一起作为一遍,由语法分析程序调用词法分析程序来获得当前单词供语法分析使用。
-----------------------------------------------------------------------------------
我写的这个词法分析器,不是非常健全,尤其是错误处理机制,像在字符串识别中,'ab'是C语言中不合法的char变量,可是我的词法分析器不能推断出错误,会死循环;此外,仅仅能识别出有限的keyword、有限形式的字符串(相信读者看懂我的状态机就知道哪里有限了),因为时间不够了,我不想再改了,以下贴出代码,供大家參考。
对了,贴代码之前,先说说我的词法分析器的状态机的设计。
我对“数字”的词法分析用了一个状态机,包含浮点数、整形数,状态机例如以下:

对“字符(串)”的识别用了一个状态机,包含keyword、char、以及char *,例如以下:
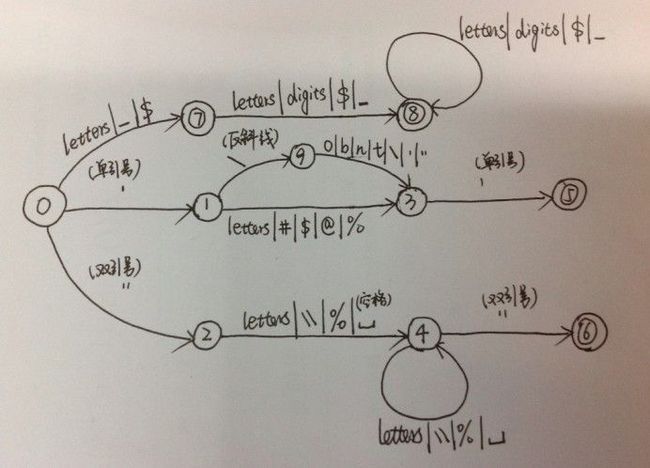
当然,对C语言的凝视的识别也用了一个状态机,必须先把源代码中的凝视cut掉才干进行分析,例如以下:

我对运算符的识别(包含双目和单目)没有採用明显的状态机,都是直接分析推断的,实际从某种意义上来讲对它们的分析也是採用了状态机的原理,仅仅是状态机结构比較简单,就没再显式用state表示,它们的状态机实际上例如以下:

以下上代码:
Scanner.py,作为主模块来运行:
'''
Created on 2012-10-18
@author: liushuai
'''
import string
import Category
import FileAccess
_currentIndex = 0
_Tokens = []
_prog = ""
_categoryNo = -1
_stateNumber = 0
_stateString = 0
_potentialNumber = ""
_potentialString = ""
def readComments(prog):
'''Read the comments of a program'''
state = 0
currentIndex, beginIndex, endIndex = (0, 0, 0)
commentsIndexs = []
for c in prog:
if state == 0:
if c == '/':
beginIndex = currentIndex
state = 1
else:
pass
elif state == 1:
if c == '*':
state = 2
else :
state = 0
elif state == 2:
if c == '*':
state = 3
else:
pass
elif state == 3:
if c == '*':
pass
elif c == '/':
endIndex = currentIndex
commentsIndexs.append([beginIndex, endIndex])
state = 0 #set 0 state
else:
state = 2
currentIndex += 1
return commentsIndexs
def cutComments(prog, commentsIndexs):
'''cut the comments of the program prog'''
num = len(commentsIndexs)
if num == 0:
return prog
else :
comments = []
for i in xrange(num):
comments.append(prog[commentsIndexs[i][0]:commentsIndexs[i][1] + 1])
for item in comments:
prog = prog.replace(item, "")
return prog
def scan(helper):
'''scan the program, and analysis it'''
global _stateNumber, _stateString, _currentIndex, _Tokens, _prog, _categoryNo, _potentialNumber, _potentialString
currentChar = _prog[_currentIndex]
######################################CHAR STRING######################################
if currentChar == '\'' or currentChar == '\"' or currentChar in string.letters + "_$\\%\@" or (currentChar in string.digits and _stateString != 0):
if _stateString == 0:
if currentChar == '\'':
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 1
_currentIndex += 1
elif currentChar == "\"":
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 2
_currentIndex += 1
elif currentChar in string.letters + "$_":
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 7
_currentIndex += 1
else:
_currentIndex += 1
_stateNumber = 10
elif _stateString == 1:
if currentChar in string.letters + "#$@%":
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 3
_currentIndex += 1
elif currentChar == '\\':
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 9
_currentIndex += 1
else:
_currentIndex += 1
_stateNumber = 10
elif _stateString == 2:
if currentChar in string.letters + "\\% ":
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 4
_currentIndex += 1
else:
_currentIndex += 1
_stateNumber = 10
elif _stateString == 3:
if currentChar == '\'':
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 5
_currentIndex += 1
else:
_currentIndex += 1
_stateNumber = 10
elif _stateString == 4:
if currentChar == '\"':
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 6
_currentIndex += 1
elif currentChar in string.letters + "\\% ":
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 4
_currentIndex += 1
else:
_currentIndex += 1
_stateNumber = 10
elif _stateString == 7:
if currentChar in string.digits + string.letters + "$_":
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 8
_currentIndex += 1
else:
_currentIndex += 1
_stateNumber = 10
elif _stateString == 8:
if currentChar in string.digits + string.letters + "$_":
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 8
_currentIndex += 1
else:
_currentIndex += 1
_stateNumber = 10
elif _stateString == 9:
if currentChar in ['b', 'n', 't', '\\', '\'', '\"']:
_potentialString = "%s%s" % (_potentialString, currentChar)
_stateString = 3
_currentIndex += 1
else:
_currentIndex += 1
_stateNumber = 10
else:
_currentIndex += 1
###################################### NUMBERS ######################################
elif currentChar in string.digits + ".":
if _stateNumber == 0:
if currentChar in "123456789":
_potentialNumber = "%s%s" % (_potentialNumber, currentChar)
_stateNumber = 6
_currentIndex += 1
elif currentChar == '0':
_potentialNumber = "%s%s" % (_potentialNumber, currentChar)
_stateNumber = 4
_currentIndex += 1
else:
_stateNumber = 8
_currentIndex += 1
elif _stateNumber == 4:
if currentChar == '.':
_potentialNumber = "%s%s" % (_potentialNumber, currentChar)
_stateNumber = 5
_currentIndex += 1
else:
_stateNumber = 8
_currentIndex += 1
elif _stateNumber == 5:
if currentChar in string.digits:
_potentialNumber = "%s%s" % (_potentialNumber, currentChar)
_stateNumber = 7
_currentIndex += 1
else:
_stateNumber = 8
_currentIndex += 1
elif _stateNumber == 6:
if currentChar in string.digits:
_potentialNumber = "%s%s" % (_potentialNumber, currentChar)
_stateNumber = 6
_currentIndex += 1
elif currentChar == '.':
_potentialNumber = "%s%s" % (_potentialNumber, currentChar)
_stateNumber = 5
_currentIndex += 1
else:
_stateNumber = 8
_currentIndex += 1
elif _stateNumber == 7:
if currentChar in string.digits:
_potentialNumber = "%s%s" % (_potentialNumber, currentChar)
_stateNumber = 7
_currentIndex += 1
else:
_stateNumber = 8
_currentIndex += 1
else:
_currentIndex += 1
######################################OTEAR OPERATERS######################################
else:
if _stateNumber == 6 or _stateNumber == 4:
helper.outPutToken(_potentialNumber, "INT", Category.IdentifierTable["INT"])
elif _stateNumber == 7:
helper.outPutToken(_potentialNumber, "FLOAT", Category.IdentifierTable["FLOAT"])
elif _stateNumber != 0:
helper.outPutToken("ERROR NUMBER", "None", "None")
_stateNumber = 0
_potentialNumber = ""
if _stateString == 7 or _stateString == 8:
if _potentialString in Category.KeyWordsTable:
helper.outPutToken(_potentialString, _potentialString.upper(), Category.IdentifierTable[_potentialString.upper()])
else:
helper.outPutToken(_potentialString, "IDN" , Category.IdentifierTable["IDN"])
helper.setSymbolTable(_potentialString, "IDN" , Category.IdentifierTable["IDN"])
elif _stateString == 5:
helper.outPutToken(_potentialString, "CHAR", Category.IdentifierTable["CHAR"])
elif _stateString == 6:
helper.outPutToken(_potentialString, "CHAR *", Category.IdentifierTable["CHAR *"])
elif _stateString != 0:
helper.outPutToken("ERROR STRING", "None", "None")
_stateString = 0
_potentialString = ""
if currentChar == " ":
_currentIndex += 1
elif currentChar == '>':
_currentIndex += 1
currentChar = _prog[_currentIndex]
if currentChar == "=":
helper.outPutToken(">=", ">=", Category.IdentifierTable[">="])
_currentIndex += 1
else :
helper.outPutToken(">", ">", Category.IdentifierTable[">"])
elif currentChar == '<':
_currentIndex += 1
currentChar = _prog[_currentIndex]
if currentChar == "=":
helper.outPutToken("<=", "<=", Category.IdentifierTable["<="])
_currentIndex += 1
else :
helper.outPutToken("<", "<", Category.IdentifierTable["<"])
elif currentChar == '+':
_currentIndex += 1
currentChar = _prog[_currentIndex]
if currentChar == '+':
helper.outPutToken("++", "++", Category.IdentifierTable["++"])
_currentIndex += 1
else :
helper.outPutToken("+", "+", Category.IdentifierTable["+"])
elif currentChar == '-':
_currentIndex += 1
currentChar = _prog[_currentIndex]
if currentChar == '-':
helper.outPutToken("--", "--", Category.IdentifierTable["--"])
else:
helper.outPutToken("-", "-", Category.IdentifierTable["-"])
elif currentChar == '=':
_currentIndex += 1
currentChar = _prog[_currentIndex]
if currentChar == '=':
helper.outPutToken("==", "==", Category.IdentifierTable["=="])
_currentIndex += 1
else :
helper.outPutToken("=", "=", Category.IdentifierTable["="])
elif currentChar == '!':
_currentIndex += 1
currentChar = _prog[_currentIndex]
if currentChar == '=':
helper.outPutToken("!=", "!=", Category.IdentifierTable["!="])
_currentIndex += 1
else :
helper.outPutToken("!", "!", Category.IdentifierTable["!"])
elif currentChar == '&':
_currentIndex += 1
currentChar = _prog[_currentIndex]
if currentChar == '&':
helper.outPutToken("&&", "&&", Category.IdentifierTable["&&"])
_currentIndex += 1
else :
helper.outPutToken("&", "&", Category.IdentifierTable["&"])
elif currentChar == '|':
_currentIndex += 1
currentChar = _prog[_currentIndex]
if currentChar == '|':
helper.outPutToken("||", "||", Category.IdentifierTable["||"])
_currentIndex += 1
else :
helper.outPutToken("|", "|", Category.IdentifierTable["||"])
elif currentChar == '*':
helper.outPutToken("*", "*", Category.IdentifierTable["*"])
_currentIndex += 1
elif currentChar == '/':
helper.outPutToken("/", "/", Category.IdentifierTable["/"])
_currentIndex += 1
elif currentChar == ';':
helper.outPutToken(";", ";", Category.IdentifierTable[";"])
_currentIndex += 1
elif currentChar == ",":
helper.outPutToken(",", ",", Category.IdentifierTable[","])
_currentIndex += 1
elif currentChar == '{':
helper.outPutToken("{", "{", Category.IdentifierTable["{"])
_currentIndex += 1
elif currentChar == '}':
helper.outPutToken("}", "}", Category.IdentifierTable["}"])
_currentIndex += 1
elif currentChar == '[':
helper.outPutToken("[", "[", Category.IdentifierTable["["])
_currentIndex += 1
elif currentChar == ']':
helper.outPutToken("]", "]", Category.IdentifierTable["]"])
_currentIndex += 1
elif currentChar == '(':
helper.outPutToken("(", "(", Category.IdentifierTable["("])
_currentIndex += 1
elif currentChar == ')':
helper.outPutToken(")", ")", Category.IdentifierTable[")"])
_currentIndex += 1
if __name__ == '__main__':
helper = FileAccess.FileHelper("H://test.c", "H://token.txt", "H://symbol_table.txt")
prog = helper.readProg()
print prog
comments = readComments(prog)
_prog = cutComments(prog, comments)
print _prog
while _currentIndex < len(_prog):
scan(helper)
helper.closeFiles()
Category.py,这个模块里面定义了一些C语言中的keyword、运算符等等,是种别码表:
'''
Created on 2012-10-18
@author: liushuai
'''
IdentifierTable = {"INT":1,"FLOAT":2,"CHAR":3,"IDN":4,"WHILE":5,"FOR":6,"DO":7,"BREAK":31,"CONTINUE":32,"CHAR *":33,"IF":37,
"*":8,"/":9,"+":10,"-":11,">":12,"<":13,"=":14,
"++":15,"--":16,"==":17,"!=":18,">=":19,"<=":20,
"&&":28,"||":29,"!":30,"&":35,"|":36,
";":21,",":34,
"{":22,"}":23,"[":24,"]":25,"(":26,")":27}
KeyWordsTable = ("int", "float", "char", "while", "for", "do","break","continue","char *","if")
'''
Created on 2012-10-23
@author: liushuai
'''
import Category
class FileHelper(object):
def __init__(self,progPath,tokenPath,symbolTablePath):
self.progPath = progPath
self.tokenPath = tokenPath
self.symbolTablePath = symbolTablePath
self.tokenFp = open(self.tokenPath,"w")
self.symbolTableFp = open(self.symbolTablePath,"w")
self.symbolTable = {}.fromkeys(Category.KeyWordsTable) #initialize symbol table
print self.symbolTable
def readProg(self):
'''read the program into the RAM'''
fp = open(self.progPath, "r+")
prog = ""
for eachLine in fp.readlines():
#print eachLine
prog = "%s%s" % (prog, eachLine.strip())
fp.close()
return prog
def outPutToken(self,tokenSelf,tokenInner,tokenNo):
'''output token into a file'''
self.tokenFp.write("(" + tokenInner + "," + tokenSelf + ")" + "\n")
print "(" + tokenInner + "," + tokenSelf + ")"
def setSymbolTable(self,tokenSelf,tokenInner,tokenNo):
'''output symbol into symbol table'''
if not self.symbolTable.has_key(tokenSelf):
self.symbolTable[tokenSelf] = None
def writeSymbolToFile(self):
for k in self.symbolTable:
self.symbolTableFp.write(k + "\n")
def closeFiles(self):
'''close token Files'''
self.writeSymbolToFile()
if self.tokenFp != None:
self.tokenFp.close()
if self.symbolTableFp != None:
self.symbolTableFp.close()
以下是我的測试C语言程序:
int main ()
{
char str[10000];
int num[30]={0};
char std[28]={"abcdefghijklmnopqrstuvwxyz"};
int i,j,temp;
float test=-0.34;
float test1=23.45;
char tom;
for (i=0;i<1000;i++) /*字符的读入*/
{
str[i]=getchar();
if (str[i]=='\n')
break;
}
for (i=0;i<10000;i++) /*字符的统计数量*/
{
if (str[i]=='\n')
break;
j=str[i] - 97; /*-97 or sth - 97?*/
num[j]++;
}
for (i=0;i<27;i++) /*字符的按出现频率排序*/
{
for (j=i+1;j<26;j++)
{
if (num[j]>num[i])
{
temp=num[j];
num[j]=num[i];
num[i]=temp;
tom=std[j];
std[j]=std[i];
std[i]=tom;
}
}
}
for (i=0;i<27;i++) /*字符的按字母表顺序排序*/
{
for (j=i+1;j<26;j++)
{
if (num[i]==num[j])
{
if (std[j]<std[i])
{
tom=std[j];
std[j]=std[i];
std[i]=tom;
}
}
}
}
for (i=0;i<29;i++)
{
if (num[i]==0)
break;
}
}
最后脚本输出例如以下:
Token.txt:
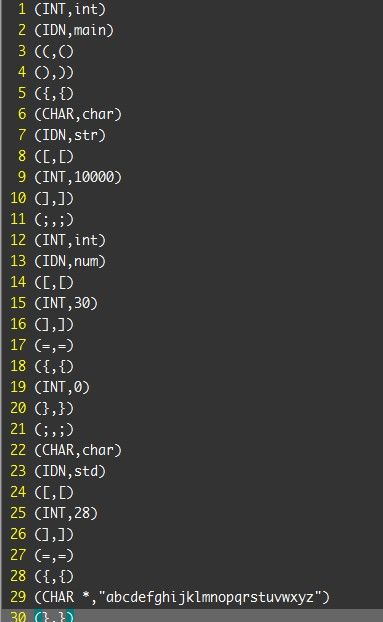
Symbol_table.txt:

这次实验就算做完了。
尽管完毕的非常水,可是正确情况下的输出还是令人惬意的,词法分析完事后,等着句法分析调用它的输出结果吧。对了,至于符号表在整个编译阶段的作用,龙书第一版2.4节和6.7节有介绍,请读者查阅。
写的非常水非常水,如有不足,欢迎指正。