霍夫曼编码解码以及其他
其实本人的问题不是为了撸个压缩软件啥的,只是存储的看到Windows系统编程想练手那几个API,加深下理解而已,我总不能拿个去打书上的代码打一篇,那样没有多少意义.顺便结合了下堆函数的使用,尽管没有用来实现个什么内存管理什么的,不过根据大猫说,没必要再去包装了,操作系统已经做的很好了,先说一些比较重要的东西:
- 命名习惯
- 错误处理
- 霍夫曼本身
我常常为取名字而蛋疼,也许只是我写代码次数少,量不多导致的原因,在我的胡杨树程序中严重暴露了这个问题,strcut叫saliceceae,class也叫saliceceae,inputlayout也叫这个.当然,外面有层命名空间,还有就是拼写的问题.英语对于我来说,不是难度问题,而是个心理问题.我已经被这个问题困扰了很多年了,我无力解决,我只能顺其自然(这个按此不表).由于大量的拼写错误,导致我在模板编程的时候陷入了各自拼写所带来的编译错误,这一点,vs也帮不了我,最后写了个蛋疼的BST模板,简直蛋疼.甚至搞笑的加上了迭代器支持,看样子,我写代码在一定程度上有某种强迫症的存在.我混杂了命名习惯,不过倒是也有些自己的规矩了,比如说函数参数我肯定会小写,class里面的成员基本都是m+类型+名字.但是有些时候我又会使用驼峰命名法和匈牙利命名法.我似乎是根据我所使用的API来取得名字
错误处理:我的代码基本上毫无错误处理,我厌恶这东西,更确切的说,我讨厌if,这是个很不好的情绪.不过最终的代码里塞满了各自if和数组,这是个写多了jass遗留的陋习.其实我应该尝试使用一些其他的东西,比如说map,set,stack,deque,而不是程序的除了vector就是array.我程序的数据结构真是古怪.这次霍夫曼所使用的数据结构是个比较坑爹的东西,一开始我是这样的:
struct HuffManCodeHeader
{
//const static size_t arraysize = 16;
BYTE CODE[256];
BYTE length[256];
size_t filesize;
};
这个数据结构看上去人畜无害,实际上存在着巨大的BUG,在处理小文件并没有表现出这一点,但是我尝试大一点文件却出现了不同的东西编码出了相同的字符.我重新看了下霍夫曼的编码,突然发现用BYTE来存储是大错特错的,但是最后我还是用的BYTE,只不过是用的16的大小,这意味着我是逐4bits编码解码的.
编码中出现了无数的BUG,第一个当然是数据结构的问题,第二个问题是幻数问题,由于我一开始使用的是256的大小,但代码的循环里面充满了256,不过使用Ctrl+H替换到时蛮快的.还有一个幻数问题的是,类型的大小问题,我基本上都是假定多大多大,而不是用sizeof求,还有编码解码的过程中局部变量的类型应该和数据结构的一样.没得说,C++11提供了decltype,但是由于推导出的类型是引用,结果当然是悲剧,不过懒得找了,标准库里应该有得到原来类型的东西吧,不过懒得找,懒得问.就此作罢
霍夫曼本身的问题,当源文件出现字节递增分布的时候,整个树的高度会快速增加,然后就是上面数据结构的问题,BYTE只有8bit不够,按照256种取值,最怀情况树的高度会达到255层(好吧,这个字节递增分布是我自己造的词,大概就是像这样一种情况:图1)
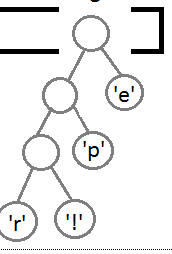 图是从http://blog.jobbole.com/20091/ 这里撸下来的,当p出现的次数= r的次数+i的次数,而e的次数 = r +i+p,整个树就会后只有一边.最后,是毫无压缩效果,具体的数学公式也懒得证了,为lee不至于把CODE类型变成一个神马int128之类恐怖的事实,我决定按4bit来解码,这样就只有16种情况,树高也完全没有那么恐怖了,尽管使用BYTE只有8bit,不能抑制树高于这个情况的存在,不过本人叫懒,就此作罢,不过实际测试还是什么蛮好的,这主要原因是ACSII码表和字符分布的原因,具体的数学我基本已经返给概念论老师了,就此不表,图1的情况其实是难出现的,不过确实是个坑
图是从http://blog.jobbole.com/20091/ 这里撸下来的,当p出现的次数= r的次数+i的次数,而e的次数 = r +i+p,整个树就会后只有一边.最后,是毫无压缩效果,具体的数学公式也懒得证了,为lee不至于把CODE类型变成一个神马int128之类恐怖的事实,我决定按4bit来解码,这样就只有16种情况,树高也完全没有那么恐怖了,尽管使用BYTE只有8bit,不能抑制树高于这个情况的存在,不过本人叫懒,就此作罢,不过实际测试还是什么蛮好的,这主要原因是ACSII码表和字符分布的原因,具体的数学我基本已经返给概念论老师了,就此不表,图1的情况其实是难出现的,不过确实是个坑
测试了下代码,压缩exe,png基本收不到压缩效果,时间的测试没有多大意义,由于是Debug模式,也看不出来速度到底如何,主要是计时器还没有写好,只能在debug下输出到vs的输出.压缩txt能收到0.75的压缩率,word文档是0.5这个倒是有意思
好了,就这样吧