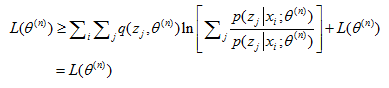从数学角度看最大期望(EM)算法 I
【转载请注明出处】http://www.cnblogs.com/mashiqi
2014/11/18
更新。发现以前的公式(2)里有错误,现已改过来。由于这几天和Can讨论了EM算法,回头看我以前写的这篇博客的时候,就发现公式里面有一个错误(多了一个连加符号),现在改正过来了。经过和Can的讨论,我又认真思考了EM算法,发现以前确实是没有弄懂这个算法的本质的。加油,以后学习知识不要只停留在表面上,要有insight!!!
2014/5/19
本文公式编辑捉鸡,请知道怎么在博客园里高效编辑公式的朋友告诉我一下,感激不尽了!
以前其实写过一个关于最大期望算法的文档,但是由于那次教研室电脑硬盘出问题,当时又没有随时备份重要文件的习惯,所以就弄没了。今天又看到EM算法,于是今天又花了40分钟重新把这个算法的思路整理了一遍,这真的是在浪费生命啊。。。所以说,这也是对以下观点的一个有力的证据之一:写文档或写学习记录真的是一件很重要的事。
本文只是从数学的角度分析EM算法,并没有对算法所反映出来的关于数据的本质问题进行刻画,所以若想通过本文学习EM算法,应该是有所欠缺的,毕竟在某些领域数学并不是全部,只是工具。然而,在翻看大部分讲解EM算法的资料时,我都被极为不好理解的公式符号所吓倒,于是打算自己写一篇关于EM算法的,有关具体公式的博文——1是用来梳理自己的思路,给自己做个笔记,免得以后忘记了EM算法又要花上一两个小时来自己推公式理解;2是用来给具有和我有同样问题的朋友们,提供帮助。或许您也在知道了"EM算法是通过琴生不等式来不断优化似然函数的下界从而求得似然解"后对此算法的理论公式表示不解,那么本文或许能给你提供一下帮助。下面进入正题。
假设我们已知数据集${x_i}$的分布$p(x)$收到参数$\theta$的影响,然后我们要做以下似然估计:
![]() (1)
(1)
这里补充一句,为了养成较好的区别"频率学派"的"贝叶斯学派"的观点,我从一些教科书上学到,一般采取这种记法:
当将$\theta$看做未知且固定的参数时,统一使用符号";":$p(x;\theta)$
当将$\theta$看做具有先验分布的参数时,统一使用符号"|":$p(x|\theta)$
回到(1)式,当这里还有一个隐变量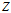 时,我们通过如下迭代方法来求解(1)式:
时,我们通过如下迭代方法来求解(1)式:
-
记$L(\theta ) = \sum\nolimits_i {\ln p({x_i};\theta )} $,于是我们有:
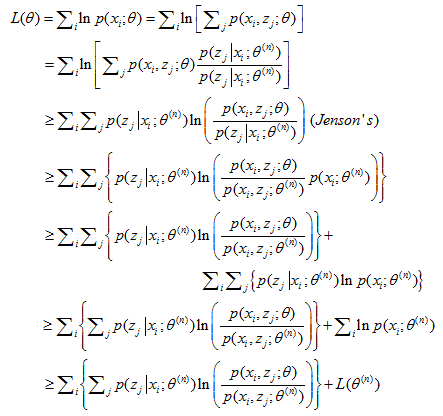 (2)
(2)
-
(E步)记,${l_n}(\theta ) = \sum\nolimits_i { \left\{ \sum\nolimits_j {p({z_j}\left| {{x_i}} \right.;{\theta ^{(n)}})\ln \left[ { {\frac{{p({x_i},{z_j};\theta )}}{{p({x_i},{z_j};{\theta ^{(n)}})}}} } \right]} \right\}} $,我们得到:
$$L(\theta ) \ge {l_n}(\theta ) + L({\theta ^{(n)}})$$ (3)
注意到${l_n}({\theta ^{(n)}}) = 0$,于是我们有:
$$L({\theta ^{(n)}}) \ge {l_n}({\theta ^{(n)}}) + L({\theta ^{(n)}}) = L({\theta ^{(n)}})$$ (4)
-
(M步)我们优化${l_n}(\theta )$:
$${\theta ^{(n + 1)}} = \arg {\max _\theta }{l_n}(\theta )$$ (5)
于是从(3)式我们得到:
$$\begin{array}{l}
L({\theta ^{(n + 1)}}) \ge {l_n}({\theta ^{(n + 1)}}) + L({\theta ^{(n)}}) \ge {l_n}({\theta ^{(n)}}) + L({\theta ^{(n)}})\\
{\kern 42pt} = L({\theta ^{(n)}})
\end{array}$$
通过上面的步骤,我们可以得到序列$\{ {\theta _n}\} $使得使得似然函数一步步变大:$L({\theta ^{(1)}}) \le \cdots \le L({\theta ^{(n)}}) \le L({\theta ^{(n + 1)}}) \le \cdots $。至于序列$ {\theta _n} $是否收敛于${\theta ^*}$,我还没有学习到 :)
在(2)式的第二行,凭空增加的$p({z_j}\left| {{x_i}} \right.;{\theta ^{(n)}})$是为了后面能配出一个$L({\theta ^{(n)}})$来。若不明白,我们可以先假设增加一项未知的$q({z_j};{\theta ^{(n)}})$,为了用到琴生不等式,我们要求$\sum\nolimits_j {q({z_j};{\theta ^{(n)}})} = 1$于是我们得到:
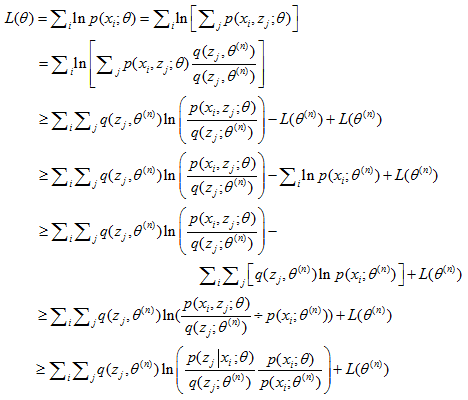
显然,若取$q({z_j};{\theta ^{(n)}}) = p({z_j}\left| {{x_i}} \right.;{\theta ^{(n)}})$,则我们能得到: