曼巴大战变形金刚:号称超越Transformer架构的Mamba架构是什么?
曼巴大战变形金刚:号称超越Transformer架构的Mamba架构是什么?
Mamba 是一种新兴的深度学习架构,旨在解决长序列数据的建模问题。它通过将状态空间模型 (State Space Models, SSM) 与选择性机制、并行计算等方法相结合,实现了高效的长序列处理。这篇博客将深入探讨 Mamba 架构的各个组成部分,解释其背后的原理。
1. 状态空间模型(SSM)
1.1 状态空间模型的基本原理
状态空间模型是一种用来处理时间序列数据的模型,特别适合在时间维度上存在依赖关系的场景。它通过状态方程和输出方程将输入信号转换为输出,核心思想是通过一个隐藏状态来捕捉序列中重要的时间信息。
状态空间模型的数学描述如下:
-
状态方程:用于更新隐藏状态
h t + 1 = A h t + B u t \mathbf{h}_{t+1} = \mathbf{A}\mathbf{h}_t + \mathbf{B}\mathbf{u}_t ht+1=Aht+But
其中, h t \mathbf{h}_t ht 是时间 t t t 的隐藏状态, u t \mathbf{u}_t ut 是输入, A \mathbf{A} A 和 B \mathbf{B} B 分别是状态转移矩阵和输入投影矩阵。 -
输出方程:将隐藏状态映射为输出
y t = C h t + D u t \mathbf{y}_t = \mathbf{C}\mathbf{h}_t + \mathbf{D}\mathbf{u}_t yt=Cht+Dut
其中, y t \mathbf{y}_t yt 是输出, C \mathbf{C} C 和 D \mathbf{D} D 分别是输出投影矩阵和直接输入到输出的映射。
1.1.1 隐藏状态的作用
隐藏状态 h t \mathbf{h}_t ht 在SSM中扮演着至关重要的角色,它存储了从初始时刻到当前时刻 t t t 的所有重要信息。这些信息以向量的形式表示,可以视为序列的“记忆”。通过状态方程,这些记忆会被不断更新,以反映最新的输入和序列的演变。
1.1.2 噪声的考虑
在实际应用中,SSM通常还会引入噪声项来模拟真实世界中的不确定性。例如,在状态方程和输出方程中,可以分别添加噪声向量 v t \mathbf{v}_t vt 和 n t \mathbf{n}_t nt,如下所示:
-
带噪声的状态方程:
h t + 1 = A h t + B u t + v t \mathbf{h}_{t+1} = \mathbf{A}\mathbf{h}_t + \mathbf{B}\mathbf{u}_t + \mathbf{v}_t ht+1=Aht+But+vt -
带噪声的输出方程:
y t = C h t + D u t + n t \mathbf{y}_t = \mathbf{C}\mathbf{h}_t + \mathbf{D}\mathbf{u}_t + \mathbf{n}_t yt=Cht+Dut+nt
这些噪声项可以通过统计方法(如卡尔曼滤波)进行估计和消除。
1.2 状态空间模型的应用
SSM 在信号处理和时间序列预测中有广泛应用。例如,在语音信号处理中,SSM 可以通过状态方程捕捉语音信号中的连续性特征,并通过输出方程生成平滑的输出信号。
SSM 还被广泛应用于控制理论、经济学和金融学等领域。在控制系统中,SSM可以用来预测系统的未来状态,并根据预测结果调整控制策略。
2. 结构化状态空间模型(S4)
2.1 S4 的背景与原理
S4(Structured State Space for Sequence Modeling)是 Mamba 的前身模型,旨在解决长序列建模中的一些关键问题,如长距离依赖和并行计算的效率。S4 的创新点在于引入了 HiPPO 矩阵,该矩阵能够有效地保存和更新历史信息。
S4 通过将连续的状态空间模型离散化,并使用特殊的核函数进行快速计算,从而在保持模型复杂度的同时,显著提高了计算效率。
2.1.1 HiPPO 矩阵的引入
HiPPO(Highest Probability of Positivity)矩阵是S4模型的核心创新点之一。它通过特定的数学性质(如正定性)来捕捉输入信号中的重要历史信息,从而实现对长序列的有效建模。HiPPO矩阵的设计是基于对序列数据特性的深入理解,它能够在不增加计算复杂度的前提下,提高模型对长距离依赖的捕捉能力。
2.1.2 离散化与零阶保持
S4通过将连续的状态空间模型离散化,并使用零阶保持(ZOH)策略,将连续时间信号转换为离散时间信号。这种转换使得S4能够在计算机上高效运行,同时保留原始信号的关键特征。
2.2 S4 的数学描述
S4 的核心在于将 HiPPO 矩阵应用到状态方程中,通过以下公式描述:
h t + 1 = ( A + B K ) h t + B u t \mathbf{h}_{t+1} = (\mathbf{A} + \mathbf{B}\mathbf{K})\mathbf{h}_t + \mathbf{B}\mathbf{u}_t ht+1=(A+BK)ht+But
其中, K \mathbf{K} K 是 HiPPO 矩阵,能够捕捉输入信号中的重要特征,并将其转化为状态更新,它决定了模型对历史信息的保留程度和更新方式。
S4 还使用了零阶保持(Zero-Order Hold, ZOH)将连续系统转换为离散系统,简化了序列到序列的映射过程。
2.3 S4 的应用场景
S4 特别适用于需要处理长序列且对计算效率有较高要求的场景,如自然语言处理中的长文本生成、语音识别中的长语音信号处理等。
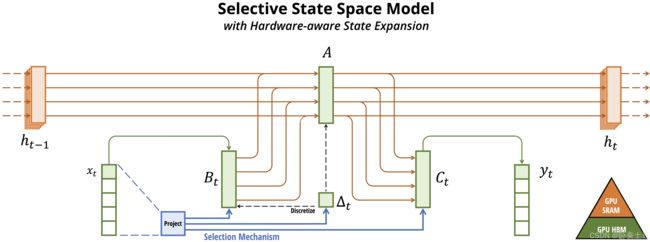
3. Mamba 的创新与选择性机制
3.1 选择性状态空间模型(S6)
Mamba 引入了选择性状态空间模型(Selective State Space Models, S6),这是在 S4 的基础上进一步改进的结果。S6 的核心思想是根据输入内容动态调整模型的权重和参数,从而更有效地处理复杂输入。
在传统的 SSM 中,所有输入信号被同等对待,但在实际应用中,不同的输入标记可能具有不同的重要性。例如,在文本处理中,一些关键字对上下文的影响更大,而一些停用词则影响较小。Mamba 的选择性机制通过动态调整参数,使得模型可以专注于更重要的内容。
3.1.1 动态权重调整
在S6中,选择性机制通过动态调整权重矩阵 W \mathbf{W} W 来实现对输入信号重要性的评估。这种调整可以是基于输入内容的某种统计特性(如词频、TF-IDF值等),也可以是通过一个额外的神经网络学习得到的。
3.1.2 激活函数的选择
激活函数 f f f 在S6中起着非线性映射的作用,它决定了隐藏状态 h t \mathbf{h}_t ht 的更新方式。常见的激活函数包括ReLU、Sigmoid和Tanh等。选择合适的激活函数对于模型的性能和稳定性至关重要。
3.2 选择性机制的数学描述
在S6中,选择性机制的具体实现可能因具体任务而异,但一般形式可以表示为:
h t + 1 = f ( A h t + B u t ) ⊙ σ ( W u t ) \mathbf{h}_{t+1} = f(\mathbf{A}\mathbf{h}_t + \mathbf{B}\mathbf{u}_t) \odot \sigma(\mathbf{W}\mathbf{u}_t) ht+1=f(Aht+But)⊙σ(Wut)
其中, ⊙ \odot ⊙ 表示逐元素乘法, f f f 是激活函数, σ \sigma σ 是选择性权重的动态调整函数。它允许模型根据输入信号的重要性动态地调整隐藏状态的更新幅度。
3.3 选择性机制的应用
选择性机制在需要处理高维复杂数据的任务中表现突出。例如,在图像处理任务中,Mamba 可以根据图像内容动态调整注意力机制,将更多的计算资源分配给重要的图像区域,从而提高模型的准确性和效率。
4. Mamba 的计算优化
4.1 并行计算与卷积核融合
Mamba 架构以其高效的计算方式著称,其核心在于并行扫描和卷积核融合技术的结合。并行扫描允许模型在训练时并行处理多个时间步的输入,显著提高了处理速度。而卷积核融合技术则通过优化卷积核的结构和计算方式,进一步加速了推理过程,同时保持了模型对长序列数据的有效特征提取能力。
4.1.1 并行扫描
想象一下你正在图书馆里工作,你的任务是扫描并整理一批书籍的条形码。如果只有你一个人,你可能需要一本接一本地拿起书,扫描条形码,然后将其分类放置。这样的过程虽然有效,但相对较慢,尤其是当书籍数量很多时。
现在,假设图书馆雇佣了多个助手来协助你。每个人负责一个扫描站,并且可以同时处理多本书籍。你和其他助手并行工作,各自扫描自己面前的书籍,并将扫描结果记录下来。最后,所有的扫描结果汇总在一起,就完成了整个批次的书籍扫描工作。
在 Mamba 架构中,并行扫描就类似于这种接力赛的模式。模型在处理输入数据时,不是按顺序一步一步地处理,而是将数据分成多个部分,同时用多个“处理器”(可以想象成多个神经元或计算单元)来处理这些部分。每个处理器处理完自己的数据后,将结果传递给下一个处理器,或者合并起来形成最终的结果。这样,Mamba 就能够同时处理多个时间步的数据,大大加快了处理速度。
4.1.2 卷积核融合
再来看一个做饭的例子。假设你要做一道菜,需要用到多种调料和食材。传统的方法是,你每放一种调料或食材,就炒一下,然后再放下一种。这样虽然可以做出美味的菜肴,但过程可能比较繁琐。
而卷积核融合就像是一种“智能烹饪”的方法。它把多种调料和食材先混合在一起(即融合多个卷积核),然后再一次性加入锅中翻炒。这样做的好处是,你不需要一次次地重复炒制的动作,而且因为调料和食材已经混合均匀,所以炒出来的菜肴味道更加均匀和美味。
在 Mamba 架构中,卷积核融合就是通过将多个卷积核合并成一个更高效的卷积核来实现计算的优化。这个新的卷积核能够同时捕捉输入数据中的多个特征,并且减少了计算量,因为不需要单独计算每个卷积核的输出后再进行合并。这样,Mamba 就能够在保持高准确率的同时,显著提高计算效率。
4.2 卷积核的数学描述与优化
卷积核融合可以形式化地描述为:
y t = ∑ i = 0 k − 1 W i u t − i \mathbf{y}_t = \sum_{i=0}^{k-1} \mathbf{W}_i \mathbf{u}_{t-i} yt=i=0∑k−1Wiut−i
其中, W i \mathbf{W}_i Wi 是卷积核的权重, k k k 是卷积核的大小, u t − i \mathbf{u}_{t-i} ut−i 是输入序列中第 t − i t-i t−i 个时间步的数据。通过精心设计和优化卷积核的结构,Mamba 能够在减少计算复杂度的同时,保持对关键特征的敏感性和准确性。
4.3 实际应用中的性能提升
这种计算优化特别适用于对实时性和准确性要求较高的应用场景,如在线语音识别、视频流分析和实时金融交易分析等。通过减少计算时间和资源消耗,Mamba 能够在这些应用中提供更快、更准确的响应。
5. Mamba 的实际应用与优势
Mamba 在处理长序列数据时展现出显著的优势,特别是在自然语言处理、计算机视觉和信号处理等领域。与传统的 Transformer 或 RNN 模型相比,Mamba 通过其独特的选择性机制和高效的计算方式,在保持高准确率的同时显著降低了计算资源的消耗。
5.1 与 Transformer 的对比
与全局注意力机制的 Transformer 相比,Mamba 更适合处理非常长的序列数据。它通过选择性机制仅关注重要内容,从而避免了 Transformer 在处理长序列时可能出现的计算瓶颈和内存限制。此外,Mamba 的卷积核融合技术也进一步提升了计算效率,使得模型在保持高性能的同时更加节能。
5.2 实际应用场景示例
- 大规模文本生成:在撰写长篇报告、学术论文或小说时,Mamba 能够快速理解和生成连贯、高质量的文本内容。
- 视频内容分析:在监控视频分析、体育赛事直播分析等领域,Mamba 能够实时处理视频流数据,提取关键信息和事件。
- 复杂信号处理:在无线通信、音频处理等领域,Mamba 能够高效处理复杂的信号数据,实现信号的识别、分类和压缩等任务。
6. 举个栗子
为了更好地理解 Mamba 架构的工作原理,我们可以将其类比为学生整理课堂笔记的过程。
- 传统方法 (RNN):就像学生只能依次记录老师讲的每一个句子,然后依靠记忆(隐藏状态)来整理笔记。随着课程内容的增加,学生可能会忘记前面的重要信息,导致笔记不完整。
- Transformer 方法:类似于学生能够同时回顾并记录所有讲过的内容,虽然全面但效率较低,因为需要处理大量的信息。
- Mamba 方法:Mamba 则像是一个聪明的学生,能够根据内容的重要性选择性地记录。当讲到重要概念时,它会详细记录并深入理解;而对于不重要的信息,则快速浏览或忽略。这样既能保证笔记的全面性,又能提高整理效率。
通过上述类比,我们可以直观地感受到 Mamba 架构在处理长序列数据时的高效性和智能性。