Transformer总结(二):架构介绍(从seq2seq谈到Transformer架构)
文章目录
- 一、seq2seq应用介绍
- 二、编码器解码器架构
-
- 2.1 流程介绍
- 2.2 原理说明
- 三、Transformer整体结构和处理流程
-
- 3.1 Attention机制在seq2seq中的引入
- 3.2 比较RNN与自注意力
- 3.3 Transformer架构介绍
- 3.4 处理流程
-
- 3.4.1 编码器中处理流程
- 3.4.2 解码器在训练阶段和预测阶段的差异(重要)
- 3.4.3 预测阶段解码器中处理流程
在Transformer总结(一)中介绍了基础的注意力机制,接下来将结合具体的任务场景,介绍Transformer的整体架构,并简单探讨一下相应原理。其中涉及到的组件将在Transformer总结(三)中详细说明。
一、seq2seq应用介绍
Seq2Seq(Sequence to Sequence)模型,主要用于处理序列到序列的映射问题,常见的应用场景如下:
- 机器翻译:将一种语言的序列映射为另一种语言的序列。
- 文本摘要:将长文本压缩为简洁的摘要。
- 语音识别:将语音信号转换为文本序列。
- 对话系统:根据用户的输入生成响应。(可以通用处理很多场景)
二、编码器解码器架构
2.1 流程介绍
Encoder-Decoder是一个更为通用的框架,而Seq2Seq是这个框架下的一种特定实现,专门用于处理序列转换问题。Seq2Seq模型依赖于Encoder-Decoder架构,但具体实现时会有所不同。
一般的Encoder-Decoder架构如下:
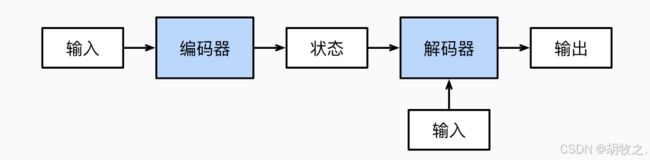
编码器(Encoder)的作用:
- 信息压缩:将输入序列(如句子、音频等)转换为固定长度的向量,这个向量旨在捕捉输入序列中的关键信息。
- 特征提取:在压缩信息的过程中,编码器提取输入序列的特征,这些特征有助于后续的解码过程。
- 表示学习:编码器学习如何表示输入数据,以便这些表示可以用于其他任务,如分类、预测等。
解码器(Decoder)的作用:
- 序列生成:基于编码器生成的上下文向量,解码器逐步生成输出序列。在每一步,它可能会考虑之前的输出,以及上下文向量。
- 信息解码:解码器将编码器压缩的信息“解码”成目标序列,如翻译后的句子或语音识别的文本。
- 概率模型:解码器通常是一个概率模型,它预测在给定当前输出序列和上下文向量的情况下,下一个输出元素的概率分布。
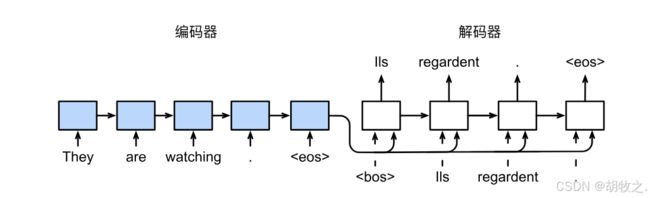
对应到具体的seq2seq场景,可以参照下列图片展示的流程:
感谢李沐老师的教材,下列图片展示了一个机器翻译任务:
- 编码器先对句子中的单词进行编码学习,得到单词的特征表示和相应阶段的隐藏状态。
- 解码器借助由编码器得到的上下文变量,再结合每次的输入内容,从而预测输出,然后将此时的输出作为下一次的输入;以‘
’作为初始输入,依次进行,直到输出为‘ ’标识,表示句子结尾,结束输出。
2.2 原理说明
编码器(Encoder)的处理:
考虑由一个序列组成的样本(批量大小是 1 1 1)。
- 假设输入序列是 x 1 , … , x T x_1, \ldots, x_T x1,…,xT,其中 x t x_t xt是输入文本序列中的第 t t t个词元。
- 在时间步 t t t,词元 x t x_t xt的输入特征向量 x t \mathbf{x}_t xt和 h t − 1 \mathbf{h} _{t-1} ht−1(即上一时间步的隐状态)转换为 h t \mathbf{h}_t ht(即当前步的隐状态)。
函数 f f f描述了这种变换:
h t = f ( x t , h t − 1 ) . \mathbf{h}_t = f(\mathbf{x}_t, \mathbf{h}_{t-1}). ht=f(xt,ht−1).
总之,编码器通过选定的函数 q q q,将所有时间步的隐状态转换为上下文变量:
c = q ( h 1 , … , h T ) . \mathbf{c} = q(\mathbf{h}_1, \ldots, \mathbf{h}_T). c=q(h1,…,hT).
解码器(Decoder)的处理:
- 直接使用编码器最后一个时间步的隐状态来初始化解码器的隐状态。
- 解码器每个时间步 t ′ t' t′输出 y t ′ y_{t'} yt′的概率取决于上一次的输出 y t ′ − 1 y_{t'-1} yt′−1、隐状态 s t \mathbf{s}_{t} st、上下文变量 c \mathbf{c} c
- 使用函数 g g g来表示解码器的隐藏层的变换:
s t ′ = g ( y t ′ − 1 , c , s t ′ − 1 ) . \mathbf{s}_{t^\prime} = g(y_{t^\prime-1}, \mathbf{c}, \mathbf{s}_{t^\prime-1}). st′=g(yt′−1,c,st′−1).
- 将 y t ′ − 1 y_{t'-1} yt′−1与 c \mathbf{c} c拼接得到新参数,再与隐状态 s t \mathbf{s}_{t} st一起传入计算得到 y t ′ y_{t'} yt′
三、Transformer整体结构和处理流程
3.1 Attention机制在seq2seq中的引入
在上述展示的内容中,解码器如何使用上下文变量 c \mathbf{c} c是值得探讨的,解码器仅在其初始化阶段使用解码器最终得到的隐藏状态,每次计算使用的上下文 c \mathbf{c} c是一个固定值,但很明显这种方法不能高效地利用解码器中的信息,因为它忽略了输入词元与解码器中词元的关系,所以可以往其中简单引入注意力机制,Bahdanau Attention正是对上述架构的加强:
Bahdanau Attention:
- 在解码器的处理过程中, c t ′ = ∑ t = 1 T α ( s t ′ − 1 , h t ) h t , \mathbf{c}_{t'} = \sum_{t=1}^T \alpha(\mathbf{s}_{t' - 1}, \mathbf{h}_t) \mathbf{h}_t, ct′=∑t=1Tα(st′−1,ht)ht,,每个时间步的上下文变量都是重新计算出来的,这里使用的是加型注意力机制计算注意力权重
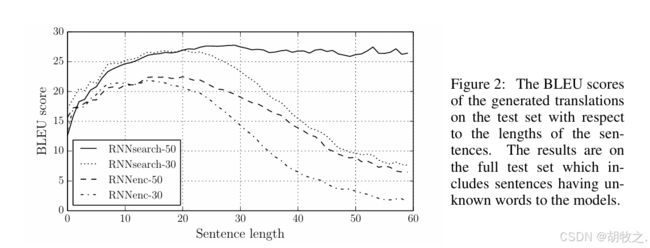
- 30和50表示的是训练阶段使用句子的单词数目上限;search表示引入了注意力机制,enc表示传统机制;根据结果可以看到,在长句子中,引入注意力机制的模型不仅鲁棒性更强,而且效果也更好
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE原文
3.2 比较RNN与自注意力
Bahdanau Attention基于RNN,观察上述的实现,可以发现RNN存在一些局限:
- 顺序处理:必须按时间步依次处理序列元素,限制了并行处理的能力,也导致计算效率的低下
- 长距离依赖受限:RNN在反向传播过程中存在梯度消失或梯度爆炸的问题,这限制了RNN捕捉长距离依赖的能力
针对上述两点,自注意力可以做出提升:
- 支持并行:自注意力不依赖于时间步,且其中的矩阵运算很适合并行,可以在GPU上高效执行
- 直接关系建模:直接计算序列中任意两个位置之间的关联,有效地提升了模型捕捉长距离依赖的能力
3.3 Transformer架构介绍
Attention Is All You Need原文
Transformer架构完全基于注意力,它摒弃了传统的循环神经网络(RNN)结构,转而采用自注意力机制来处理序列数据。这种机制允许模型并行计算序列中所有位置的表示,从而有效捕捉长距离依赖关系。
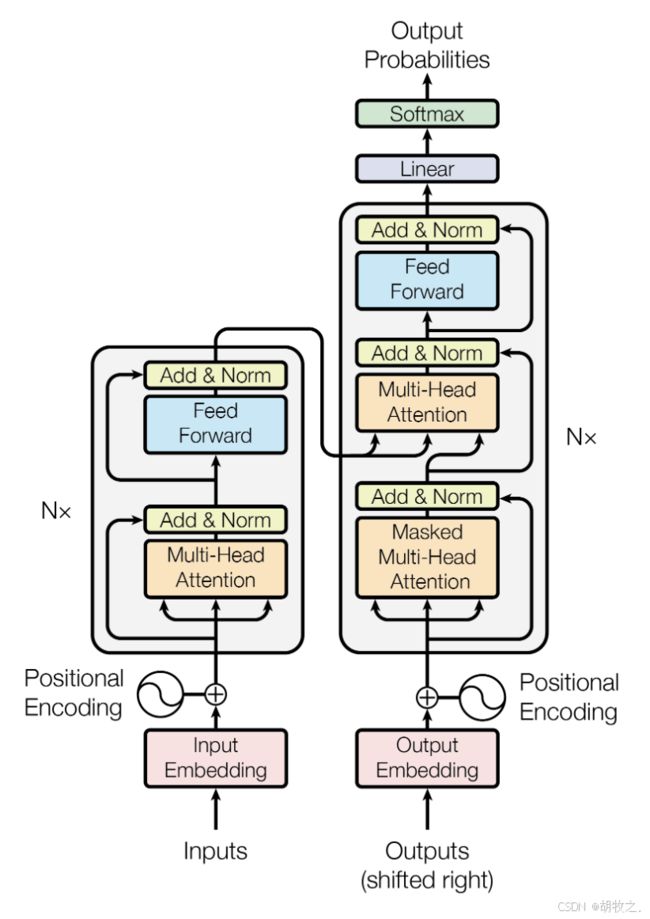
编码器架构
编码器由几个完全一样的块组成,而每个块则由两个子层组成,分别为:
- multi-head self-attention mechanism
- positionwise fully connected feed-forward network
对于每个子层,再使用residual connection和layer normalization。子层的输出为:
L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x + Sublayer(x)) LayerNorm(x+Sublayer(x))
为了方便进行残差连接,所以需要统一子层输入输出的维度,此时涉及到了两个超参数,分别为:块数、子层的输入输出维度;而论文中超参数设定块数为6,维度为512。
解码器架构
解码器同样使用6个完全一样的块组成,但与编码器不同的是,此时每个块由三个子层组成,分别为:
- masked multi-head self-attention mechanism
- multi-head self-attention mechanism
- positionwise fully connected feed-forward network
对于每个子层,同样使用residual connection和layer normalization。
整体架构见下图
3.4 处理流程
接下来将以上述的机器翻译任务为例,简单说明一下如何实现结果的预测,关于一些操作的具体实现会在后文中详细说明,在Transformer总结(一)也稍有提及。
若动图无法加载,可见动图来源
3.4.1 编码器中处理流程
- 最初的输入序列由词元所组成,通过 嵌入层(embedding layer) 来获得输入序列中每个词元的特征向量,经过这一步,数据的结构将变为 (batch_size, num_steps, embed_size)
- 位置编码(Positional Encoding) 会给序列中的每个词元(分配一个相同大小的向量。这个向量的维度与词元的嵌入向量维度相同,确保了它们可以相加在一起,并且不改变数据结构。
- 多头注意力(Multi-Head Attention) ,先对此时的输入序列进行线性变换,得到多组query、Key、Value,每组单独计算得到的结果进行拼接,再次经过线性变换得到结果,此时输出的结构依然为 (batch_size, num_steps, embed_size),也就是最终结构没有发生变化。
- 残差连接(Residual Connection) ,将子层的输出与输入相加,由于维度未发生变化,所以直接相加,结构依然无变化。
- 层归一化(Layer Normalization),对每个词元的特征向量进行归一化操作,也就是每个词元都会有各自的均值和方差,但结构依然无变化。
- 前馈神经网络(Feed-Forward Neural Network) 是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下:
m a x ( 0 , X W 1 + b 1 ) W 2 + b 2 max(0,XW_1+b_1)W_2+b_2 max(0,XW1+b1)W2+b2此时结构将变为 (batch_size, num_steps, ffn_num_outputs),但此时结构依然没有发生变化,后续的残差操作也可作为佐证。
3.4.2 解码器在训练阶段和预测阶段的差异(重要)
需要重点说明的是,解码器是一个自回归模型,使用上一次预测的结果作为下一次的输入,所以它在预测阶段是串行的,但是在训练阶段可以使用 强制教学(Teacher Forcing) 从而并行计算。
teacher-forcing ,在训练网络过程中,每次不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入。
这也就意味着训练阶段不必依赖于之前的输出生成输入,而是直接得到每个时间步的输入,也就是可以并行计算。
由强制教学出发,此时便可以说明masked multi-head self-attention mechanism中掩码的作用。掩码通过控制注意力权重,从而在计算多头注意力时query不会关注当前时间步之后的信息,等会将详细说明。预测阶段,也就不需要使用这里的Sequence Mask机制了。
3.4.3 预测阶段解码器中处理流程
具体细节可见知乎讲解,此处仅以动图进行演示。
其中值得说明的是整体右移一位(Shifted Right),解码器每次处理都需要输入,但在最开始的时候还没有上一个阶段的预测输出,此时就要以起始符作为初始的输入,而这个起始符将导致输入句子在原始的基础上右移一位。