强连通分量——tarjan算法缩点
一. 什么是强连通分量?
强连通分量:在有向图G中,如果两个顶点u,v间(u->v)有一条从u到v的有向路径,同时还有一条从v到u的有向路径,则称两个顶点强连通(strongly connected)。如果有向图G的每两个顶点都强连通,称G是一个强连通图。有向图的极大强连通子图,称为强连通分量。
简单点说就是:如果一个有向图中,存在一条回路,所有的结点至少被经过一次,这样的图为强连通图。
在强连图图的基础上加入一些点和路径,使得当前的图不在强连通,称原来的强连通的部分为强连通分量。
二. 强连通分量有什么用途呢?
在图论中,我们可以利用强连通分量进行缩点,从而可以减少很多不必要的操作,降低程序的时间复杂度。
三. tarjan求强连通分量
在讲tarjan算法之前我们先来讲几个概念:
1.树枝边:x是y的父节点,那么x到y的边称为树枝边。
2.前向边:x是y的祖先节点,那么x到y的边称为前向边。
3.后向边:y是x的的祖先节点,那么y到x的边称为后向边。
4.横叉边:x是y的祖先节点,并且y能到达已经搜过的点,那么这条边被称为横叉边。
根据定义可以得知:树枝边也是一个特殊的前向边。
我们在深度优先搜索的时候是从上向下搜的,所以画图看一下(自己画的图,可能有点丑 )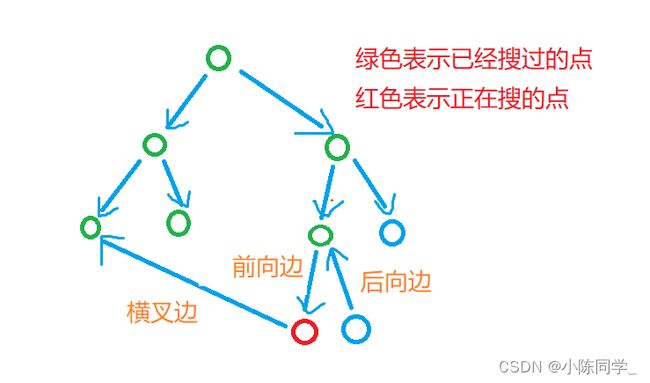
知道这些定义后,我们来看一下tarjan算法是如何求强连通分量的。
在这里,我们引入一个时间戳的概念:在深度优先搜索的时候,当前结点x是第几个被搜索到的,记为df[x]。
对于每一个结点,我们定义两个时间戳。
df[x]:x结点是第几个被搜索到的。
low[x]:从x结点开始搜索,能搜索到深度最低的结点是什么,也就是能搜索到时间戳最小的结点。
在搜索的时候我们该如何判断是一个新的强连通分量呢?
如果一个图是强连通的话,那么必然会搜完他图中的所有结点,并且从任意一个结点到达另一个结点,所以强连通分量中的点都可以遍历到时间戳更小的点。
所以我们可以发现,如果一个结点的df[]==low[]的话,那么说明这个结点是不能搜到比自己的时间戳更小的点了。说明什么呢?说明该节点就是一个强连通分量的最高点,也就是一个新的强连通分量。
下面放入一个题(受欢迎的牛):
每一头牛的愿望就是变成一头最受欢迎的牛。
现在有 N 头牛,编号从 1 到 N,给你 M 对整数 (A,B),表示牛 A 认为牛 B 受欢迎。
这种关系是具有传递性的,如果 A 认为 B 受欢迎,B 认为 C 受欢迎,那么牛 A 也认为牛 C 受欢迎。
你的任务是求出有多少头牛被除自己之外的所有牛认为是受欢迎的。
输入格式
第一行两个数 N,M;
接下来 M 行,每行两个数 A,B,意思是 A 认为 B 是受欢迎的(给出的信息有可能重复,即有可能出现多个 A,B)。
输出格式
输出被除自己之外的所有牛认为是受欢迎的牛的数量。
数据范围
1≤N≤10^4,
1≤M≤5×10^4
输入样例:
3 3
1 2
2 1
2 3
输出样例:
1
样例解释
只有第三头牛被除自己之外的所有牛认为是受欢迎的。
这题乍一看是传递闭包,第一时间会想到Floyd,但是看了数据范围之后发现传递闭包会超时,所以Floyd是不可行的。
我们用强连通分量来做。
题意:a->b且b->c,则a->c
要求的是有多少头牛被除自己之外的所有牛认为是受欢迎的(受欢迎的牛可以被其他的牛走到)。
总结:当一个强连通的出度为0,则该强连通分量中的所有点都被其他强连通分量的牛欢迎,但假如存在两及以上个出度=0的牛(强连通分量) 则必然有一头牛(强连通分量)不被所有牛欢迎。
AC代码:
#include
#include
#include
#include
using namespace std;
const int N=1e4+10,M=5*N;
int h[N],e[M],ne[M],idx; //邻接表
int id[N]; //id[x]:x结点属于第几个强连通分量
int cnt,times; //cnt:强连通分量的个数,times:时间戳
int n,m;
bool st[N]; //st[x]:x结点是否在栈中
int df[N],low[N]; //df[x]:x结点第一次被搜索到的时间戳,low[x]:x结点能遍历到最高的点
int sizes[N]; //sizes[x]:第x强连通分量中点的个数
int stack[N],top; //这里我们用数组模拟栈
int dout[N]; //dout[x]:第x个强连通分量的出度
void add(int a,int b){
e[idx]=b;
ne[idx]=h[a];
h[a]=idx++;
}
void tarjan(int u){
//当前点的时间戳
df[u]=low[u]=++times;
//把u点入栈
stack[++top]=u;
st[u]=true;
//遍历u结点能到的点
for(int i=h[u];i!=-1;i=ne[i]){
int j=e[i];
if(!df[j]){ //如果没有遍历过,那么就遍历它
tarjan(j);
low[u]=min(low[u],low[j]);
}
else if(st[j]) low[u]=min(low[u],low[j]); //如果在栈中
}
//找到一个强连通分量
if(df[u]==low[u]){
cnt++;
int t=stack[top--];
id[t]=cnt;
st[t]=false;
sizes[cnt]++;
while(t!=u){
t=stack[top--];
id[t]=cnt;
st[t]=false;
sizes[cnt]++;
}
}
}
int main(){
scanf("%d%d",&n,&m);
memset(h,-1,sizeof h);
while(m--){
int a,b;
scanf("%d%d",&a,&b);
add(a,b);
}
for(int i=1;i<=n;i++){
if(!df[i]){
tarjan(i);
}
}
for(int i=1;i<=n;i++){
for(int j=h[i];j!=-1;j=ne[j]){
int t=e[j];
int a=id[i],b=id[t]; //a:i结点所在的强连通分量,b:t结点所在的强连通分量
if(a!=b) dout[a]++; //因为是a->b,所以a的出度++
}
}
int zero=0; //出度为0点的个数
int sum=0;
for(int i=1;i<=cnt;i++){
if(!dout[i]){
sum+=sizes[i];
zero++;
}
}
if(zero>1) printf("%d",0);
else printf("%d",sum);
return 0;
}