《菜菜的机器学习sklearn课堂》随机森林应用泛化误差调参实例
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10)
plt.plot(range(1,11), rfc_s, label = “RandomForest”)
plt.plot(range(1,11), clf_s, label = “Decision Tree”)
plt.legend()
plt.show()
另一种更加简单有趣的写法:
label = “RandomForest”
for model in [RandomForestClassifier(n_estimators=25),DecisionTreeClassifier()]:
score = cross_val_score(model,wine.data, wine.target, cv=10)
print(“{}:”.format(label)),print(score.mean())
plt.plot(range(1,11),score,label = label)
plt.legend()
label = “DecisionTree”

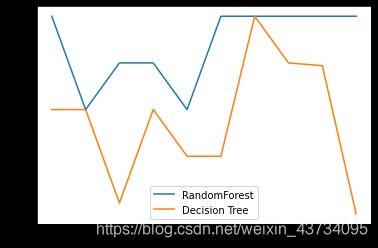
5、画出随机森林和决策树在十组交叉验证下的效果对比
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11), rfc_l, label=“Random Forest”)
plt.plot(range(1,11), clf_l, label=“Decision Tree”)
plt.legend()
plt.show()

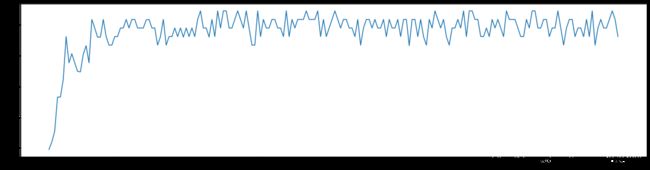
6、n_estimators的学习曲线
#####【TIME WARNING: 2mins 30 seconds】#####
superpa = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
print(max(superpa), superpa.index(max(superpa))) # 0.9888888888888889 53
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()
random_state:控制森林生成模式的随机性

思考一个问题:
我们说袋装法服从多数表决原则或对基分类器结果求平均,这即是说:我们默认森林中的每棵树应该是不同的,并且会返回不同的结果。
设想一下,如果随机森林里所有的树的判断结果都一致(全判断对或全判断错),那随机森林无论应用何种集成原则来求结果,都应该无法比单棵决策树取得更好的效果才对。但我们使用了一样的类DecisionTreeClassifier,一样的参数,一样的训练集和测试集,为什么随机森林里的众多树会有不同的判断结果?
随机森林中其实也有random_state,用法和分类树中相似:
-
在分类树中,一个random_state只控制生成一棵树
-
随机森林中的random_state控制的是生成森林的模式,而非让一个森林中只有一棵树
rfc = RandomForestClassifier(n_estimators=20, random_state=2)
rfc = rfc.fit(Xtrain, Ytrain)
#随机森林的重要属性之一: estimators, 查看森林中树的状况
rfc.estimators_[0].random_state
for i in range(len(rfc.estimators_)):
print(rfc.estimators_[i].random_state)
我们可以观察到:当random_state固定时,随机森林中生成是一组固定的树,但每棵树依然是不一致的,这是用”随机挑选特征进行分枝“的方法得到的随机性。并且我们可以证明,当这种随机性越大的时候,袋装法的效果一般会越来越好。用袋装法集成时,基分类器应当是相互独立的,是不相同的。
但这种做法的局限性是很强的,当我们需要成千上万棵树的时候,数据不一定能够提供成千上万的特征来让我们构筑尽量多尽量不同的树。因此,除了random_state。我们还需要其他的随机性。