基于强化学习的制造调度智能优化决策

获取更多资讯,赶快关注上面的公众号吧!
文章目录
- 调度状态和动作设计
-
- 调度状态的设计
- 调度动作的设计
- 基于RL的调度算法
-
- 基于值函数的RL调度算法
-
- SARSA
- Q-learning
- DQN
- 基于策略的RL调度算法
- 基于RL的调度应用
-
- 基于RL的单机调度
- 基于RL的并行机调度
- 基于RL的流水车间调度
- 基于RL的作业车间调度
- 基于RL的其他调度
- RL与元启发式算法在调度中的集成应用
- 讨论
-
- 问题领域
- 算法领域
- 应用领域
- 参考文献
生产调度作为制造系统的关键组成部分,其目的是通过合理确定加工路径、机器分配、执行时间等主要因素,实现利润、效率、能耗等目标的优化。由于生产调度问题的大规模、强耦合约束以及特定场景下的实时求解要求,使得生产调度问题的求解面临着巨大的挑战。随着机器学习的发展,强化学习(RL)在各种决策问题上取得了突破性进展。针对制造调度问题,本文总结了状态和动作的设计,梳理了基于强化学习的调度算法,整理了强化学习在不同类型调度问题中的应用,并讨论了强化学习与元启发式算法的融合模式,旨在为强化学习研究者或生产调度实践者提供一些参考。
调度状态和动作设计
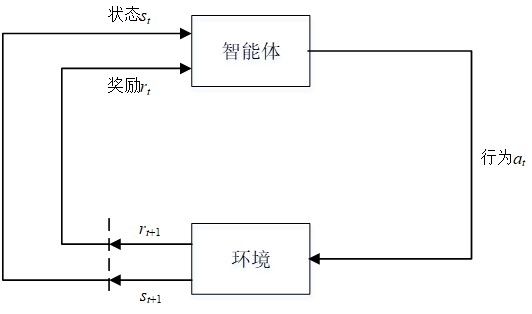
与监督学习不同,RL允许代理或智能体通过与环境的试错交互来学习最佳行为,而无需标签数据,以最大化奖励。图1说明了在RL的框架中代理和环境之间的交互。具体地说,在时间t,代理从环境感知状态信号 s t s_t st并且在时间 t t t执行动作 a t a_t at,从而获得奖励信号 r t + 1 r_{t+1} rt+1,此时环境转移至新的状态 s t + 1 s_{t+1} st+1。然后,代理根据 r t + 1 r_{t+1} rt+1更新策略,并在状态 s t + 1 s_{t+1} st+1下的动作 a t + 1 a_{t+1} at+1,以获得奖励信号 r t + 2 r_{t+2} rt+2。通过与环境的交互,Agent在试错过程中学习决策策略。最后,智能体可以根据状态s下的策略选择适当的动作,以最大化累积奖励。
调度状态的设计
调度问题的状态设计一般可以分为3种:
- (1)将生产信息或相关统计信息作为状态,包括加工信息、加工环境信息、订单信息等,该方法可以有效地减少信息的丢失。然而,生产信息通常是连续的数据,如工序的松弛率、机床的利用率等都是连续数值,问题规模的增加会带来维数灾难,因此通常使用神经网络来近似值函数和策略函数。
主要研究成果如下:
| 文献 | 场景 | 状态 |
|---|---|---|
| Wang and Pan[1] | 置换流水车间调度 | 工件在每台机器上的加工时间 |
| Wang et al.[2] | 动态作业车间调度 | 工序加工时间、工件加工状态、 机器选择 |
| Qu et al.[3] | 流水车间调度 | 缓冲区大小、工站运行状况 、员工状况 |
| Luo et al.[4] | 动态多目标柔性作业车间调度 | 机器数量、机器平均利用率、交货期松弛等 |
- (2)根据生产信息之间的数量关系或生产信息的统计定义状态。这样可以避免问题规模增大带来的更大状态空间的挑战,但会导致问题信息的丢失。
主要研究成果如下:
| 文献 | 场景 | 状态 |
|---|---|---|
| Wang and Usher[5] | 动态单机调度 | 根据缓冲区中工件数量的情况和总延迟的估计来定义状态 |
| Wang et al.[6] | 考虑退化的单机调度 | 根据平均正常加工时间与剩余工件平均延迟估计之间的定量关系划分状态空间 |
| Zhao et al.[7] | 作业车间调度 | 通过比较估计的平均松弛时间和估计的平均剩余时间来定义六种状态 |
- (3)将调度问题转化为图,根据图中节点和边的情况定义状态。该方法很好地考虑了问题的结构特征,高效地表示了生产环境。同时,通常采用图神经网络(GNN)、卷积神经网络(CNN)、图卷积网络(GCN)等网络来有效地提取问题特征。
主要研究成果如下:
| 文献 | 场景 | 状态 |
|---|---|---|
| Zhang et al.[8] | 作业车间调度 | 析取图模型 |
| Han and Yang[9] | 自适应作业车间调度 | 多通道图像 |
| Hu et al.[10] | 柔性制造系统动态调度 | Petri网 |
| Chen et al.[74] | 作业车间调度 | 析取图嵌入 |
| Song et al.[73] | 柔性作业车间调度 | 析取图+图神经网络 |
总之,状态设计的方式有很多种。优秀的状态设计需要平衡信息损失和状态空间的大小。同时,还应考虑调度问题的特点和优化目标。
调度动作的设计
调度问题的动作设计也可以分为3类:
- (1)选择启发式作为动作。通过这种方式,可以协同使用启发式,并且动作的数量是恒定的,与问题的大小无关。然而,该算法的性能取决于所选择的启发式的效率和质量。
主要研究成果如下:
| 文献 | 场景 | 动作 |
|---|---|---|
| Lin et al.[11] | 智能制造工厂 | MOR、FIFO、LPT等 |
| Yang et al.[12] | 置换流水车间动态调度 | SPTLPT等 |
| Luo[13] | 考虑工件插入的柔性作业车间动态调度 | 6种复合规则 |
- (2)以作业顺序等调度解作为动作。该方法主要用于解决端到端的静态调度问题。通过这种方式,代理可以快速构建调度解。
主要研究成果如下:
| 文献 | 场景 | 动作 |
|---|---|---|
| Wang and Pan[1] | 置换流水车间调度 | 使用加工信息直接输出调度序列 |
| Kintsakis et al.[14] | 工作流管理系统 | 通过序列到序列直接生成调度解 |
- (3)根据问题特征定义调度算子作为动作。代理学习选择合适的算子,例如决定机器分配、调整作业顺序等,以生成新的解。这种方法应该对问题有很好的理解,以避免产生不可行解。
| 文献 | 场景 | 动作 |
|---|---|---|
| Li et al.[15] | 单机在线调度 | 选择未加工的工件 |
| Williem and Setiawan[16] | 作业车间调度问题 | 重分派和任务移动 |
| Arviv et al.[17] | 考虑机器人搬运的流水车间调度 | 工件搬运 |
| Park et al.[18] | 半导体制造 | 选择未加工的工件 |
可见,动作设计的方法多种多样,一般需要考虑问题的属性,以生成合适的动作形式和数量。
基于RL的调度算法
根据环境模型的使用,RL可以分为两类,即无模型强化学习和基于模型的强化学习。基于模型的强化学习依赖于环境模型,其中包含状态转换和奖励预测。虽然基于模型的强化学习的代理可以直接获得新的状态和奖励,但很难获得生产调度问题的状态转移信息。与基于模型的强化学习不同,无模型强化学习依赖于代理与环境之间的实时交互,而不需要状态转换信息。现有的基于RL的生产调度优化算法大多是无模型RL算法,又可分为基于值函数的RL和基于策略的RL。
基于值函数的RL调度算法
基于值函数的强化学习通过选择具有最大状态-动作值的动作来构造最优策略。显然,价值函数的构造和计算是基于值函数的强化学习的核心。这种强化学习具有较高的样本利用率,但容易过拟合,泛化能力差。基于值函数的强化学习在生产调度优化中的代表性算法包括SARSA、Q学习和DQN。
SARSA
SARSA是一种在策略的时间差分(TD)算法。在迭代学习过程中,代理采用ε-贪婪方法在状态 s t s_t st下选择 a t a_t at,获得奖励 r t + 1 r_{t+1} rt+1。然后,环境转移至新状态 s t + 1 s_{t+1} st+1 。对于新状态,代理通过使用ε-贪婪方法继续选择 a t + 1 a_{t+1} at+1,并根据下式更新值函数 q ( s t , a t ) q(s_t,a_t) q(st,at):
q ( s t , a t ) = q ( s t , a t ) + α × ( r t + 1 + γ × q ( s t + 1 , a t + 1 ) − q ( s t , a t ) ) (1) q\left(s_t, a_t\right)=q\left(s_t, a_t\right)+\alpha \times\left(r_{t+1}+\gamma \times q\left(s_{t+1}, a_{t+1}\right)-q\left(s_t, a_t\right)\right)\tag{1} q(st,at)=q(st,at)+α×(rt+1+γ×q(st+1,at+1)−q(st,at))(1)
其中 α \alpha α为学习率, γ \gamma γ为折扣因子。
使用该算法的主要成果如下:
| 文献 | 场景 | 算法 |
|---|---|---|
| Palombarini et al.[19] | 油漆制造厂 | SARSA |
| Chen et al.[20] | 柔性作业车间调度 | GA+SARSA+Q-learning |
| Orhean et al.[21] | 异构分布式系统 | SARSA |
| Aissani et al.[22] | 动态多产地调度问题 | SARSA |
Q-learning
与SARSA不同,Q学习是一种离策略的TD算法。其值函数q(s_t,a_t)更新如下:
q ( s t , a t ) = q ( s t , a t ) + α × ( r t + 1 + γ × max a q ( s t + 1 , a ) − q ( s t , a t ) ) (2) q\left(s_t, a_t\right)=q\left(s_t, a_t\right)+\alpha \times\left(r_{t+1}+\gamma \times \max _a q\left(s_{t+1}, a\right)-q\left(s_t, a_t\right)\right)\tag{2} q(st,at)=q(st,at)+α×(rt+1+γ×amaxq(st+1,a)−q(st,at))(2)
使用该算法的主要成果如下:
| 文献 | 场景 | 算法 |
|---|---|---|
| Bouazza et al.[23] | 柔性作业车间调度 | Q-learning |
| Wang[24] | 动态作业车间调度 | weighted Q-learning |
| Stricker et al.[25] | 半导体制造 | Q-learning |
| Wang and Yan[26] | 知识化制造 | Q-learning |
| Wang et al.[27] | 航空发动机装配调度 | double-layer Q-learning |
DQN
SARSA和Q-learning都采用一个表来记录状态-动作值,但当状态空间或动作空间的规模过大时,该表不再适用。因此,通过集成Q-learning和深度神经网络来逼近值函数,提出了深度Q学习网络DQN。DQN采用经验重放和目标网络来克服算法的不稳定性。
使用该算法的主要成果如下:
| 文献 | 场景 | 算法 |
|---|---|---|
| Waschneck et al.[28] | 半导体制造 | DQN |
| Hu et al.[29] | 柔性作业车间 | DQN |
| Palombarini and Martínez[30] | 闭环重调度 | DQN |
在三种基于值的强化学习算法中,Q-learning算法具有贪婪性,容易陷入局部最优。SARSA算法相对保守,但ε-贪婪算法需要控制搜索速率以保证收敛性。DQN适合于求解大规模问题,但DQN的采样效率低,且对参数设置有很强的依赖性。
基于策略的RL调度算法
与基于值函数的强化学习不同,基于策略的强化学习不考虑值函数,而是直接搜索最佳策略。此外,基于策略的强化学习通常采用神经网络来拟合策略函数。这类算法都有自己的探索机制,但样本利用率低,容易产生方差较大的局部最优解。典型的算法包括REINFORCE、PPO、TRPO、Actor-Critic等。
基于策略RL的调度成果如下:
| 文献 | 场景 | 算法 |
|---|---|---|
| Wang and Pan[1] | 置换流水车间调度 | pointer network+REINFORCE |
| Rummukainen and Nurminen[31] | 随机经济批调度 | PPO |
| Zhang et al.[8] | 作业车间调度 | GNN+PPO |
| Kuhnle et al.[32] | 半导体制造 | TRPO |
| Liu et al.[33] | 作业车间调度 | DDPG |
| Hubbs et al.[34] | 化工生产调度 | advantage actor-critic |
| Chen and Tian[35] | 在线作业调度 | actor-critic |
基于RL的调度应用
关于强化学习在不同类型的调度问题中的应用,主要集中在车间作业、流水车间、并行机、单机调度问题。
基于RL的单机调度
单机调度的约束条件相对简单,只需要确定工件的加工顺序。目前,强化学习主要用于解决随机、动态或在线条件下的单机调度问题。主要成果如下:
| 文献 | 场景 | 算法 |
|---|---|---|
| Wang et al.[36] | 面向库存的单机生产系统 | two RL-based methods |
| Xie et al.[37] | 在线单机调度 | Q-learning |
| Wang et al.[38] | 动态单机调度 | Q-learning |
| Yang et al.[39] | 带退化过程的多状态单机生产调度 | heuristic RL |
| Yang et al.[40] | 多状态生产系统中的生产调度和预防性维护 | model-free RL |
| Wang and Usher[41] | 单机调度 | Q-learning |
基于RL的并行机调度
与单机调度相比,并行机调度需要考虑机器分配问题。代理的状态和动作的设计也更加复杂。基于RL的并行机调度优化算法主要是针对动态调度问题而设计的。主要成果如下:
| 文献 | 场景 | 算法 |
|---|---|---|
| Zhang et al.[42] | 考虑机器作业条件和顺序相关准备时间的动态并行机调度 | Q-learning |
| Zhou et al.[43] | 智慧制造动态调度 | deep RL |
| Zhang et al.[44] | 工件动态到达的并行机调度 | R-learning |
| Zhang et al.[45] | 非等效并行机调度 | on-line R-learning with function approximation |
基于RL的流水车间调度
流水车间调度需要考虑多个阶段的加工。为了实现柔性制造,在某些阶段存在多台并行机,即混合或柔性流水车间调度。显然,它比并行机调度要复杂得多。主要成果如下:
| 文献 | 场景 | 算法 |
|---|---|---|
| Zhang and Ye[15] | 置换流水车间调度 | Q-learning |
| Xiao et al.[46] | 非置换流水车间调度 | deep temporal difference RL |
| Zhang et al.[47] | 非置换流水车间调度 | on-line TD (λ) |
| Han et al.[48] | 混合流水车间调度 | Q-learning |
| Fonseca-Reyna and Martínez-Jiménez[49] | 具有顺序相关准备时间的流水作业调度 | improved Q-learning |
| Zhao et al.[50] | 分布式装配无空闲流水车间调度 | a cooperative water wave algorithm with RL |
基于RL的作业车间调度
与上述三种调度问题相比,作业车间调度需要考虑工件的不同机器加工路线。对于柔性作业车间调度,还应考虑机器分配。因此,调度算法的设计更为复杂。主要成果如下:
| 文献 | 场景 | 算法 |
|---|---|---|
| Gabel and Riedmilier[51] | 反应式作业车间调度 | Q-learning |
| Martínez et al.[52] | 柔性作业车间调度 | Q-learning |
| Kardos et al.[53] | 动态柔性作业车间调度 | Q-learning |
| Luo et al.[54] | 工件随机到达的作业车间调度 | double loop deep Q-network |
| Zhao et al.[7] | 作业车间调度 | improved Q-learning |
| Luo[13] | 带有新工件插入的柔性车间调度 | deep Q-network |
| Shahrabi et al.[55] | 工件随机到达和机器故障的动态车间调度 | RL-based variable neighborhood search |
| Csáji et al.[56] | 考虑机器故障、新机器到达、作业取消和新作业到达的分布式生产系统 | triple-level learning mechanism |
| Wang et al.[57] | 不确定装配作业车间调度 | dual Q-learning |
基于RL的其他调度
强化学习也被应用于一些其他类型的调度问题,如分布式调度,能源效率调度和多目标调度。此外,RL在几个真实的生产场景中取得了进展,例如边缘计算任务调度和农业灌溉调度。主要成果如下:
| 文献 | 场景 | 算法 |
|---|---|---|
| Aissani et al.[22] | 多产地调度 | multi-agent method based on RL |
| Zhou et al.[58] | 分布式系统 | online RL |
| Wang et al.[59] | 能量效率调度 | deep RL |
| model | ||
| He et al.[60] | 机械加工车间 | improved Q-learning |
| Hong and Prabhu[61] | 具有准时制约束的动态多目标作业车间调度 | Q-learning |
| Kuhnle et al.[32] | 多目标半导体调度 | Q-learning |
| Zhou et al.[62] | 不确定多目标调度 | DQN |
| Yuan et al.[63] | 异构云环境下的多目标调度 | Q-learning |
| Zhan et al.[64] | 车辆边缘计算中的卸载调度 | PPO |
| Yang et al.[65] | 灌溉调度 | deep RL |
| Mortazavi et al.[66] | 供应链订购管理系统 | Q-learning |
RL与元启发式算法在调度中的集成应用
强化学习在调度中的应用是非常有前途的,仍然需要讨论和研究。近几十年来,计算智能作为人工智能的一个重要分支,特别是元启发式算法,在生产调度方面取得了很大的进展。然而,单一搜索模式的元启发式算法难以有效和高效地处理复杂的调度问题,如分布式调度和绿色调度。有必要引入学习机制等多种机制来辅助元启发式算法提高搜索效率。因此,RL和元启发式的集成是一个很有前途的方式来提高算法的性能。RL和元启发式的集成模式主要有3种:
- (1)RL和元启发式算法被视为两个阶段的算法。这是一个简单而容易的方法,联合RL和元启发式的优点,以提高解的质量。对于流水车间调度问题,Wang和Pan[1]提出了一种新的网络来建模问题,并通过RL进行训练。在网络输出解后,采用迭代贪婪算法对结果进行改进。
- (2)RL用于指导元启发式算法的参数选择。通过与环境的交互,RL可以学习参数设置的知识。元启发式算法可以利用训练好的代理的引导实现自适应调整。
| 文献 | 场景 | 算法 |
|---|---|---|
| Shahrabi et al.[55] | 动态作业车间调度 | Q-learning+VNS |
| Xing and Liu[67] | 连续函数 | Q-learning+PSO |
- (3)采用强化学习来指导元启发式算法的搜索。这样,RL和超启发式的优点,可以用来实现搜索策略的自适应选择和搜索方向的自适应调整。
| 文献 | 场景 | 算法 |
|---|---|---|
| Wang and Wang[68] | 分布式混合流水车间调度 | memetic algorithm+RL |
| Li et al.[69] | 任务调度 | GA+Q-learning |
| Alicastro et al.[70] | 增材制造调度 | local search+RL |
| Zhao et al.[50] | 流水车间调度 | water wave algorithm+Q-learning |
| Gu et al.[71] | 动态作业车间调度 | salp swarm algorithm+DQN |
| Karimi-Mamaghan et al.[72] | 置换流水车间调度 | iterated greedy algorithm+Q-learning |
综上所述,已有的研究表明,强化学习和元启发式的结合可以有效地提高算法的性能。
讨论
生产调度是制造系统的核心问题,鉴于大规模和实时性的要求,现有的调度算法面临着巨大的挑战。随着人工智能的发展,强化学习在许多组合优化问题上取得了突破性进展,为调度优化提供了新的途径。本文对强化学习在生产调度中的应用进行了综述,为强化学习智能优化生产调度提供了指导。从已有的基于RL的调度研究来看,RL算法在求解车间调度问题,特别是动态调度问题时具有方便、快速等独特的优势。然而,相关研究仍处于起步阶段,在问题、算法和应用领域仍有待进一步探索。
问题领域
现有的工作主要集中在RL来解决单目标调度问题。同时,关于多目标优化问题的研究很少,主要考虑经济性和时间性指标。
另外,目前关于强化学习在生产调度问题中的应用大多是简化的、传统的。同时,许多现实生活中的约束,如无空闲,无等待,顺序相关的准备时间,和机器退化的影响,都应考虑。研究RL算法在求解具有复杂工艺约束的生产调度问题中具有重要的实用价值。
算法领域
目前,已有的强化学习算法缺乏对调度问题的理论分析和支持。此外,缺乏系统的方法来指导状态和动作的设计,也不利于RL在解决生产调度问题中的推广和应用。
目前,基于策略的强化学习算法很少用于生产调度问题,它能够以端到端的方式搜索最优策略并生成调度,能够有效克服实时场景的挑战。因此,研究基于策略的强化学习算法,如PPO、TRPO等,以端到端的方式解决生产调度问题,实现调度规则的自适应生成具有重要意义。
考虑到与元启发式算法的协同性,对协作强化学习的研究相对较少。探索强化学习与元启发式算法的有效融合机制是一个很有前途的研究方向。通过充分发挥强化学习的优势,确定搜索方向和搜索步长,自适应地调整搜索操作和参数设置,以期发现关联知识,提高搜索效率。
应用领域
目前,强化学习在调度问题上的研究大多停留在学术层面。相关理论和方法只是通过仿真进行测试和分析,缺乏实际问题的应用。因此,有必要加强对实际问题的理解和提炼,强调问题建模、算法设计,推动RL算法在求解车间调度中的应用。
总之,基于强化学习的生产调度优化研究是一个很有前途的研究方向,但仍有许多地方需要改进和探索。随着强化学习技术的发展,其理论、方法和应用研究必将得到全面的发展和提高。
参考文献
[1] L. Wang and Z. X. Pan, Scheduling optimization for flowshop based on deep reinforcement learning and iterative greedy method, (in Chinese), Control and Decision, vol. 36, no. 11, pp. 2609–2617, 2021.
[2] L. B. Wang, X. Hu, Y. Wang, S. J. Xu, S. J. Ma, K. X. Yang, Z. J. Liu, and W. D. Wang, Dynamic job-shop scheduling in smart manufacturing using deep reinforcement learning, Comput. Netw., vol. 190, p. 107969, 2021.
[3] S. H. Qu, J. Wang, S. Govil, and J. O. Leckie, Optimized adaptive scheduling of a manufacturing process system with multi-skill workforce and multiple machine types: An ontology-based, multi-agent reinforcement learning approach, Procedia Cirp, vol. 57, pp. 55–60, 2016.
[4] S. Luo, L. X. Zhang, and Y. S. Fan, Dynamic multiobjective scheduling for flexible job shop by deep reinforcement learning, Comput. Ind. Eng., vol. 159, p. 107489, 2021.
[5] Y. C. Wang and J. M. Usher, Application of reinforcement learning for agent-based production scheduling, Eng. Appl. Artif. Intell., vol. 18, no. 1, pp. 73–82, 2005.
[6] H. F. Wang, Q. Yan, and S. Z. Zhang, Integrated scheduling and flexible maintenance in deteriorating multi-state single machine system using a reinforcement learning approach, Adv. Eng. Inform., vol. 49, p. 101339, 2021.
[7] Y. J. Zhao, Y. H. Wang, J. Zhang, and H. X. Yu, Application of improved Q learning algorithm in job shop scheduling problem, (in Chinese), Journal of System Simulation, https://kns.cnki.net/kcms/detail/11.3092.V. 20210423.1823.002.html, 2021.
[8] C. Zhang, W. Song, Z. G. Cao, J. Zhang, P. S. Tan, and C. Xu, Learning to dispatch for job shop scheduling via deep reinforcement learning, arXiv preprint arXiv: 2010.12367, 2020.
[9] B. A. Han and J. J. Yang, Research on adaptive job shop scheduling problems based on dueling double DQN, IEEE Access, vol. 8, pp. 186474–186495, 2020.
[10] L. Hu, Z. Y. Liu, W. F. Hu, Y. Y. Wang, J. R. Tan, and F. Wu, Petri-net-based dynamic scheduling of flexible manufacturing system via deep reinforcement learning with graph convolutional network, J. Manuf. Syst., vol. 55, pp. 1–14, 2020.
[11] C. C. Lin, D. J. Deng, Y. L. Chih, and H. T. Chiu, Smart manufacturing scheduling with edge computing using multiclass deep Q network, IEEE Trans. Ind. Inform., vol. 15, no. 7, pp. 4276–4284, 2019.
[12] S. L. Yang, Z. G. Xu, and J. Y. Wang, Intelligent decisionmaking of scheduling for dynamic permutation flowshop via deep reinforcement learning, Sensors, vol. 21, no. 3, p. 1019, 2021.
[13] S. Luo, Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning, Appl.Soft Comput., vol. 91, p. 106208, 2020.
[14] A. M. Kintsakis, F. E. Psomopoulos, and P. A. Mitkas, Reinforcement learning based scheduling in a workflow management system, Eng. Appl. Artif. Intell., vol. 81,pp. 94–106, 2019.
[15] Y. Y. Li, E. Fadda, D. Manerba, R. Tadei, and O. Terzo, Reinforcement learning algorithms for online singlemachine scheduling, in Proc. 2020 Federated Conf. Computer Science and Information Systems, Sofia, Bulgaria, 2020, pp. 277–283.
[16] R. S. Williem and K. Setiawan, Reinforcement learning combined with radial basis function neural network to solve Job-Shop scheduling problem, in Proc. 2011 IEEE Int. Summer Conference of Asia Pacific Business Innovation and Technology Management, Dalian, China, 2011, pp. 29–32.
[17] K. Arviv, H. Stern, and Y. Edan, Collaborative reinforcement learning for a two-robot job transfer flowshop scheduling problem, Int. J. Prod. Res., vol. 54, no. 4, pp. 1196–1209, 2016.
[18] I. B. Park, J. Huh, J. Kim, and J. Park, A reinforcement learning approach to robust scheduling of semiconductor manufacturing facilities, IEEE Trans. Automat. Sci. Eng., vol. 17, no. 3, pp. 1420–1431, 2020.
[19] J. Palombarini, J. C. Barsce, and E. Martinez, Generating rescheduling knowledge using reinforcement learning in a cognitive architecture, arXiv preprint arXiv: 1805.04752,2018.
[20] R. H. Chen, B. Yang, S. Li, and S. L. Wang, A self learning genetic algorithm based on reinforcement learning for flexible job-shop scheduling problem, Comput. Ind. Eng., vol. 149, p. 106778, 2020.
[21] A. I. Orhean, F. Pop, and I. Raicu, New scheduling approach using reinforcement learning for heterogeneous distributed systems, J. Parallel Distrib. Comput., vol. 117, pp. 292–302, 2018.
[22] N. Aissani, A. Bekrar, D. Trentesaux, and B. Beldjilali, Dynamic scheduling for multi-site companies: A decisional approach based on reinforcement multi-agent learning, J. Intell. Manuf., vol. 23, no. 6, pp. 2513–2529, 2012.
[23] W. Bouazza, Y. Sallez, and B. Beldjilali, A distributed approach solving partially flexible job-shop scheduling problem with a Q-learning effect, IFAC-Papers OnLine, vol. 50, no. 1, pp. 15890–15895, 2017.
[24] Y. F. Wang, Adaptive job shop scheduling strategy based on weighted Q-learning algorithm, J. Intell. Manuf., vol. 31, no. 2, pp. 417–432, 2020.
[25] N. Stricker, A. Kuhnle, R. Sturm, and S. Friess, Reinforcement learning for adaptive order dispatching in the semiconductor industry, CIRP Annals, vol. 67, no. 1,pp. 511–514, 2018.
[26] H. X. Wang and H. S. Yan, An interoperable adaptive scheduling strategy for knowledgeable manufacturing based on SMGWQ-learning, J. Intell. Manuf., vol. 27, no. 5, pp. 1085–1095, 2016.
[27] H. X. Wang, H. S. Yan, and Z. Wang, Adaptive assembly scheduling of aero-engine based on double-layer Qlearning in knowledge manufacturing, (in Chinese), Computer Integrated Manufacturing Systems, vol. 20, no. 12, pp. 3000–3010, 2014.
[28] B. Waschneck, A. Reichstaller, L. Belzner, T. Altenmüller, T. Bauernhansl, A. Knapp, and A. Kyek, Optimization of global production scheduling with deep reinforcement learning, Procedia CIRP, vol. 72, pp. 1264–1269, 2018.
[29] H. Hu, X. L. Jia, Q. X. He, S. F. Fu, and K. Liu, Deep reinforcement learning based AGVs real-time scheduling with mixed rule for flexible shop floor in industry 4.0, Comput. Ind. Eng., vol. 149, p. 106749, 2020.
[30] J. A. Palombarini and E. C. Martínez, Closed-loop rescheduling using deep reinforcement learning, IFACPapersOnLine, vol. 52, no. 1, pp. 231–236, 2019.
[31] H. Rummukainen and J. K. Nurminen, Practical reinforcement learning-experiences in lot scheduling application, IFAC-PapersOnLine, vol. 52, no. 13, pp. 1415–1420, 2019.
[32] A. Kuhnle, N. Röhrig, and G. Lanza, Autonomous order dispatching in the semiconductor industry using reinforcement learning, Procedia CIRP, vol. 79, pp. 391–396, 2019.
[33] C. L. Liu, C. C. Chang, and C. J. Tseng, Actor-critic deep reinforcement learning for solving job shop scheduling problems, IEEE Access, vol. 8, pp. 71752–71762, 2020.
[34] C. D. Hubbs, C. Li, N. V. Sahinidis, I. E. Grossmann, and J. M. Wassick, A deep reinforcement learning approach for chemical production scheduling, Comput. Chem. Eng., vol. 141, p. 106982, 2020.
[35] X. Y. Chen and Y. D. Tian, Learning to perform local rewriting for combinatorial optimization, arXiv preprint arXiv: 1810.00337, 2019.
[36] J. Wang, X. P. Li, and X. Y. Zhu, Intelligent dynamic control of stochastic economic lot scheduling by agent-based reinforcement learning, Int. J. Prod. Res., vol. 50, no. 16, pp. 4381–4395, 2012.
[37] S. F. Xie, T. Zhang, and O. Rose, Online single machine scheduling based on simulation and reinforcement learning, in Proc. of the Simulation in Producktion and Logistik, Wissenschaftliche Scripten, Auerbach, Germany, 2019, pp. 59–68.
[38] S. J. Wang, S. Sun, B. H. Zhou, and L. F. Xi, Q-learning based dynamic single machine scheduling, (in Chinese), Journal of Shanghai Jiaotong University, vol. 41, no. 8, pp. 1227–1232 & 1243, 2007.
[39] H. B. Yang, W. C. Li, and B. Wang, Joint optimization of preventive maintenance and production scheduling for multi-state production systems based on reinforcement learning, Reliab. Eng. Syst. Saf., vol. 214, p. 107713, 2021.
[40] H. B. Yang, L. Shen, M. Cheng, and L. F. Tao, Integrated optimization of scheduling and maintenance in multi-state production systems with deterioration effects, (in Chinese), Computer Integrated Manufacturing Systems, vol. 24, no. 1, pp. 80–88, 2018.
[41] Y. C. Wang and J. M. Usher, Learning policies for single machine job dispatching, Robot. Comput. -Integr. Manuf., vol. 20, no. 6, pp. 553–562, 2004.
[42] Z. C. Zhang, L. Zheng, and M. X. Weng, Dynamic parallel machine scheduling with mean weighted tardiness objective by Q-Learning, Int. J. Adv. Manuf. Technol., vol. 34, no. 9, pp. 968–980, 2007.
[43] L. F. Zhou, L. Zhang, and B. K. P. Horn, Deep reinforcement learning-based dynamic scheduling in smart manufacturing, Procedia CIRP, vol. 93, pp. 383–388, 2020.
[44] Z. C. Zhang, L. Zheng, and X. H. Weng, Parallel machines scheduling with reinforcement learning, (in Chinese), Computer Integrated Manufacturing Systems, vol. 13, no. 1, pp. 110–116, 2007.
[45] Z. C. Zhang, L. Zheng, N. Li, W. P. Wang, S. Y. Zhong, and K. S. Hu, Minimizing mean weighted tardiness in unrelated parallel machine scheduling with reinforcement learning, Comput. Operat. Res., vol. 39, no. 7, pp. 1315–1324, 2012.
[46] P. F. Xiao, C. Y. Zhang, L. L. Meng, H. Hong, and W. Dai, Non-permutation flow shop scheduling problem based on deep reinforcement learning, (in Chinese), Computer Integrated Manufacturing Systems, vol. 27, no. 1, pp. 192–205, 2021.
[47] Z. C. Zhang, W. P. Wang, S. Y. Zhong, and K. S. Hu, Flow shop scheduling with reinforcement learning, AsiaPac. J. Operat. Res., vol. 30, no. 5, p. 1350014, 2013.
[48] W. Han, F. Guo, and X. C. Su, A reinforcement learning method for a hybrid flow-Shop scheduling problem, Algorithms, vol. 12, no. 11, p. 222, 2019.
[49] Y. C. Fonseca-Reyna and Y. Martínez-Jiménez, Adapting a reinforcement learning approach for the flow shop environment with sequence-dependent setup time, Revista Cubana de Ciencias Informáticas, vol. 11, no. 1, pp. 41–57, 2017.
[50] F. Q. Zhao, L. X. Zhang, J. Cao, and J. X. Tang, A cooperative water wave optimization algorithm with reinforcement learning for the distributed assembly no-idle flowshop scheduling problem, Comput. Ind. Eng., vol. 153, p. 107082, 2021.
[51] T. Gabel and M. Riedmiller, Scaling adaptive agent-based reactive job-shop scheduling to large-scale problems, in Proc. of 2007 IEEE Symp. Computational Intelligence in Scheduling, Honolulu, HI, USA, 2007, pp. 259–266.
[52] Y. Martínez, A. Nowé, J. Suárez, and R. Bello, A reinforcement learning approach for the flexible job shop scheduling problem, in Proc. of the 5th Int. Conf. Learning and Intelligent Optimization, Rome, Italy, 2011, pp. 253–262.
[53] C. Kardos, C. Laflamme, V. Gallina, and W. Sihn, Dynamic scheduling in a job-shop production system with reinforcement learning, Procedia CIRP, vol. 97, pp. 104–109, 2021.
[54] B. Luo, S. B. Wang, B. Yang, and L. L. Yi, An improved deep reinforcement learning approach for the dynamic job shop scheduling problem with random job arrivals, J. Phys.: Conf. Ser., vol. 1848, no. 1, p. 012029, 2021.
[55] J. Shahrabi, M. A. Adibi, and M Mahootchi, A reinforcement learning approach to parameter estimation in dynamic job shop scheduling, Comput. Ind. Eng., vol. 110, pp. 75–82, 2017.
[56] B. C. Csáji, L. Monostori, and B. Kádár, Reinforcement learning in a distributed market-based production control system, Adv. Eng. Inform., vol. 20, no. 3, pp. 279–288, 2006.
[57] H. X. Wang, B. R. Sarker, J. Li, and J. Li, Adaptive scheduling for assembly job shop with uncertain assembly times based on dual Q-learning, Int. J. Prod. Res., vol. 59, no. 19, pp. 5867–5883, 2021.
[58] T. Zhou, D. B. Tang, H. H. Zhu, and Z. Q. Zhang, Multiagent reinforcement learning for online scheduling in smart factories, Robot. Comput. -Integr. Manuf., vol. 72, p. 102202, 2021.
[59] B. Wang, F. G. Liu, and W. W. Lin, Energy-efficient VM scheduling based on deep reinforcement learning, Future Generation Computer Systems, vol. 125, pp. 616–628, 2021.
[60] Y. He, L. X. Wang, Y. F. Li, and Y. L. Wang, A scheduling method for reducing energy consumption of machining job shops considering the flexible process plan, (in Chinese), Journal of Mechanical Engineering, vol. 52, no. 19, pp. 168–179, 2016.
[61] J. Hong and V. V. Parbhu, Distributed reinforcement learning control for batch sequencing and sizing in Just-InTime manufacturing systems, Appl. Intell., vol. 20, no. 1, pp. 71–87, 2004.
[62] T. Zhou, D. B. Tang, H. H. Zhu, and L. P. Wang, Reinforcement learning with composite rewards for production scheduling in a smart factory, IEEE Access, vol. 9, pp. 752–766, 2020.
[63] J. L. Yuan, M. C. Chen, T. Jiang, and C. Li, Multiobjective reinforcement learning job scheduling method using AHP fixed weight in heterogeneous cloud environment, (in Chinese), Control and Decision, doi:10.13195/j.kzyjc.2020.0911.
[64] W. H. Zhan, C. B. Luo, J. Wang, C. Wang, G. Y. Min, H. C. Duan, and Q. X. Zhu, Deep reinforcement learning based offloading scheduling for vehicular edge computing, IEEE Internet Things J., vol. 7, no. 6, pp. 5449–5465, 2020.
[65] Y. X. Yang, J. Hu, D. Porter, T. Marek, K. Heflin, and H. X. Kong, Deep reinforcement learning-based irrigation scheduling, Trans. ASABE, vol. 63, no. 3, pp. 549–556, 2020.
[66] A. Mortazavi, A. A. Khamseh, and P. Azimi, Designing of an intelligent self-adaptive model for supply chain ordering management system, Eng. Appl. Artif. Intell., vol. 37, pp. 207–220, 2015.
[67] C. M. Xing and F. A. Liu, An adaptive particle swarm optimization based on reinforcement learning, (in Chinese), Control and Decision, vol. 26, no. 1, pp. 54–58, 2011.
[68] J. J. Wang and L. Wang, A cooperative memetic algorithm with learning-based agent for energy-aware distributed hybrid flow-Shop scheduling, IEEE Trans. Evol. Comput., doi: 10.1109/TEVC.2021.3106168.
[69] Z. P. Li, X. M. Wei, X. S. Jiang, and Y. W. Pang, A kind of reinforcement learning to improve genetic algorithm for multiagent task scheduling, Mathematical Problems in Engineering, vol. 2021, p. 1796296, 2021.
[70] M. Alicastro, D. Ferone, P. Festa, S. Fugaro, and T. Pastore, A reinforcement learning iterated local search for makespan minimization in additive manufacturing machine scheduling problems, Comput. Operat. Res., vol. 131, p. 105272, 2021.
[71] Gu Y M, Chen M, Wang L. A self-learning discrete salp swarm algorithm based on deep reinforcement learning for dynamic job shop scheduling problem[J]. Applied Intelligence, 2023.
[72] Karimi-Mamaghan M, Mohammadi M, Pasdeloup B, et al. Learning to select operators in meta-heuristics: An integration of Q-learning into the iterated greedy algorithm for the permutation flowshop scheduling problem[J]. European Journal of Operational Research, 2023, 304(3): 1296-1330.
[73] Song W, Chen X Y, Li Q Q, et al. Flexible Job-Shop Scheduling via Graph Neural Network and Deep Reinforcement Learning[J]. Ieee Transactions on Industrial Informatics, 2023, 19(2): 1600-1610.
[74] Chen R, Li W, Yang H. A Deep Reinforcement Learning Framework Based on an Attention Mechanism and Disjunctive Graph Embedding for the Job-Shop Scheduling Problem[J]. Ieee Transactions on Industrial Informatics, 2023, 19(2): 1322-1331.