机器学习——lightGBM(学习整理)
目录
一、认识lightGBM
1. 简单介绍
2. 主要特点
LightGBM 的缺点
3. 模型训练方式
(1)Training API
(2)Scikit-learn API
二、相关函数参数
1. Training API
2. Scikit-learn API(重复只做补充)
3. lightgbm.cv
4. lightgbm.Dataset
5. Callbacks
(1)lightgbm.record_evaluation
(2)lightgbm.early_stopping
(3)lightgbm.log_evaluation
(4)lightgbm.reset_parameter
6. Plotting
(1)lightgbm.plot_metric
(2)lightgbm.plot_importance
(3)lightgbm.plot_tree
(4)lightgbm.create_tree_digraph
三、调参
1. 基本流程(使用GridSearchCV)
(1)确定 max_depth 和 num_leaves
(2)确定 min_data_in_leaf 和 max_bin
(3)确定 feature_fraction、bagging_fraction、bagging_freq
(4)确定lambda_l1和lambda_l2
(5)确定 min_split_gain
(6)最后再次尝试调节降低学习率,增加迭代次数,验证模型。
2. 其他需求
(1)更快的训练速度
(2)更好的准确率
(3)处理过拟合
一、认识lightGBM
1. 简单介绍
LightGBM 是 微软的 一个团队 在 Github 上开发的一个 开源项目,高性能 的 LightGBM 算法具有分布式 和 可以 快速处理大量数据的 特点。LightGBM 虽然 基于 决策树和 XGBoost 而生,但它 还遵循 其他不同的 策略。
XGBoost 使用决策树 对一个 变量进行 拆分,并在 该变量上 探索不同的 切割点(按级别划分的 树生长策略),而 LightGBM 则 专注于 按叶子节点 进行拆分,以便 获得更好的 拟合(按叶划分的树生长策略)。这使得 LightGBM 能够 快速获得很好的 数据拟合,并生成 能够 替代 XGBoost 的 解决方案。从 算法上讲,XGBoost 将决策树 所进行的 分割结构 作为一个图 来计算,使用 广度优先搜索(BFS),而 LightGBM 使用的是 深度优先搜索(DFS)。

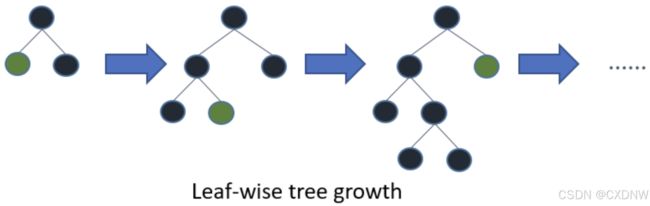
2. 主要特点
(1)比 XGBoost 准确性更高,训练时间 更短。
(2)支持 并行树增强,可以利用多核 CPU 或者 GPU 来加速训练过程,即使在大型数据集上也能提供 比 XGBoost 更好的 训练速度。
(3)通过 使用 直方图算法 将连续特征 提取为 离散特征,实现了 惊人的快速 训练速度 和 较低的内存 使用率。
(4)不需要 额外处理数据中的 缺失值,LightGBM 会自动 进行处理。
(5)通过 使用 按叶分割 而不是 按级别分割来 获得更高精度,加快 目标函数 收敛过程,并在非常复杂的 树中 捕获训练数据的 底层模式。使用 num_ leaves 和 max_depth 超参数控制过拟合。
(6)支持分类和回归任务
LightGBM 的缺点
① 容易过拟合:与其他 树模型类似,LightGBM 容易过拟合,需要进行 适当的 正则化。
② 对超参数敏感:LightGBM 的性能 受超参数的 影响较大,需要 进行 仔细调参。
③ 不适用于小样本数据:LightGBM 在小样本数据 上 可能表现不佳,需要 足够的 数据量才能 发挥其优势。
3. 模型训练方式
import lightgbm as lgb
(1)Training API
lightgbm.train(params, train_set, num_boost_round=100, valid_sets=None, valid_names=None, feval=None, init_model=None, feature_name='auto', categorical_feature='auto', keep_training_booster=False, callbacks=None)lightgbm.cv(params, train_set, num_boost_round=100, folds=None, nfold=5, stratified=True, shuffle=True, metrics=None, feval=None, init_model=None, feature_name='auto', categorical_feature='auto', fpreproc=None, seed=0, callbacks=None, eval_train_metric=False, return_cvbooster=False)(2)Scikit-learn API
class lightgbm.LGBMClassifier(boosting_type='gbdt', num_leaves=31, max_depth=-1, learning_rate=0.1, n_estimators=100, subsample_for_bin=200000, objective=None, class_weight=None, min_split_gain=0.0, min_child_weight=0.001, min_child_samples=20, subsample=1.0, subsample_freq=0, colsample_bytree=1.0, reg_alpha=0.0, reg_lambda=0.0, random_state=None, n_jobs=None, importance_type='split', **kwargs)class lightgbm.LGBMRegressor(boosting_type='gbdt', num_leaves=31, max_depth=-1, learning_rate=0.1, n_estimators=100, subsample_for_bin=200000, objective=None, class_weight=None, min_split_gain=0.0, min_child_weight=0.001, min_child_samples=20, subsample=1.0, subsample_freq=0, colsample_bytree=1.0, reg_alpha=0.0, reg_lambda=0.0, random_state=None, n_jobs=None, importance_type='split', **kwargs)二、相关函数参数
1. Training API
lightgbm.train(params, train_set, num_boost_round=100, valid_sets=None, valid_names=None, feval=None, init_model=None, feature_name='auto', categorical_feature='auto', keep_training_booster=False, callbacks=None)| lightgbm.train | 参数含义 |
|---|---|
| params(dict) | 训练参数。 通过参数传递的值优先于参数默认值。 |
| train_set (Dataset) | 训练数据。 通常通过 |
|
(int, optional) (num_iterations、n_iter、n_estimators、max_iter) |
提升迭代的次数,即训练多少棵树。 默认值为100。 |
| valid_sets (list of Dataset, optional) |
验证数据集列表。默认为None。 用于在训练过程中评估模型性能。 |
|
(list of str, optional) |
验证数据集的名字列表。默认为None。 用于在输出中标识每个验证集的性能。 |
fobj (callable, optional) |
自定义的目标函数。 |
feval (callable, optional) |
自定义的评估函数。 |
|
(str or Booster, optional) |
默认为None。 初始模型的文件路径或已训练的模型。 可以用来继续训练或作为热启动。 |
|
(str or list of str, optional) |
特征名。默认为"auto" 如果为’auto’,则使用训练集中的特征名。 |
|
(str, list of str, int, list of int, or ‘auto’, optional) |
类别特征。 可以指定为特征的索引或名称。 |
|
(bool, optional) |
如果为True,则保留训练过程中的模型,以便后续使用。默认为False。 |
evals_result (dict, optional) |
用于存储每一轮迭代结果的字典。如果提供,将覆盖evals_result参数。 |
| callbacks (list of callable, optional) |
回调函数列表,用于在训练过程中的特定事件触发时执行自定义操作。默认为None。 |
| early_stopping_rounds (early_stopping_round、 |
用于指定早停轮次,即如果验证集上的评估指标在指定的轮次内没有提升,则提前停止训练过程,以避免过拟合并节省计算资源。默认为0。
|
| eval_metric | 用于指定模型在验证集上的评估指标,以便在训练过程中监控模型的性能。 与early_stopping_rounds 结合使用设置提前停止训练过程。 |
| params | 参数含义 |
| objective(objective_type) |
指定学习任务的类型和损失函数,LightGBM 会应用不同的损失函数来优化模型。默认 regression。 ① binary(binary_logistic): 用于二分类任务,预测概率并直接输出 0 或 1。 ② multiclass(softmax): 多分类任务。适用于多个类别的分类问题,需配合 ③ cross_entropy(xentropy):交叉熵损失,常用于二分类或多分类任务,特别是在处理概率输出时。 ④ regression( ⑤ l1: Lasso回归,用于稀疏特征表示,鼓励系数为零。 ⑥ cross_entropy_lambda(xentlambda):带L2正则化的交叉熵损失,适用于需要控制模型复杂度的分类任务。 ⑦ lambdarank:排序任务,特别是用于学习排序列表的场景,如搜索引擎的排名优化。 ⑧ huber: 更鲁棒的回归损失,对于离群点影响较小。 ⑨ fair: 面向公平性的回归,减小模型对某些特定群体的偏差。 ⑩ mape: 对均绝对百分比误差(MAPE)的优化,常用于评估时间序列数据。 ⑪ quantile: 计算给定分位数的回归,如0.5(中位数)或用户自定义的分位数。 ⑫ poisson: 适用于事件计数问题,比如文档中单词数等。 |
| boosting (boosting_type、boost) |
决定了 LightGBM 在训练过程中如何结合多个弱学习器(通常是决策树)来形成一个强学习器,即构造决策树的方式。默认‘gbdt’。 ① gbdt:基于梯度提升决策树(Gradient Boosting Decision Tree)的方法。适用于回归和分类问题,速度较快且准确度较高。是大多数情况下的首选。 ② rf:随机森林(Random Forest)的方式构造决策树。虽然训练速度也较快,但相较于gbdt,其准确率可能会略低。适用于对训练速度有较高要求,且对准确率要求不是非常严格的场景。 ③ dart:Dropout 加了加性正则化的方法。训练时间较长,但能够取得较好的准确率,适合细调和调优。该方法引入了dropout机制,有助于防止过拟合。 |
| metric | 计算评估指标,以便了解模型的训练进度和性能表现。 (1)分类任务 ① binary_logloss:二元对数损失。表示模型预测的概率分布与真实标签之间的差异。 ② ③ ④ ④ multiclass_logloss:多类对数损失。是对每个类别的对数损失的平均值。 ⑤ multi_error:多分类任务的错误率。 (2)回归任务 ① l1(或mae、mean_absolute_error、regression_l1):平均绝对误差(Mean Absolute Error),衡量预测值与真实值之间差异的绝对值的平均值。 ② l2(或mse、mean_squared_error、regression_l2、regression):均方误差(Mean Squared Error),衡量预测值与真实值之间差异的平方的平均值的平方根。 ③ rmse(或root_mean_squared_error、l2_root):均方根误差(Root Mean Squared Error)。【 ④ quantile:分位数损失,用于预测具有不确定性的估计量(如预测区间)。 (3)排序任务 ① ndcg(Normalized Discounted Cumulative Gain)(或lambdarank、rank_xendcg、xendcg、xe_ndcg、xe_ndcg_mart、xendcg_mart):用于评估搜索引擎等排序任务性能的指标,考虑了排序列表中元素的顺序和相关性。 ② map(Mean Average Precision)(或mean_average_precision):在信息检索中常用的指标,特别适用于评估多个查询的平均性能。 【其他:cross_entropy、average_precision(平均精度得分)、cross_entropy_lambda、mape(MAPE损失)、huber(huber损失)、fair(fair损失)、gamma(Gamma回归的负对数似然)、gamma_deviance(Gamma回归残差)、tweedie(Tweedie回归的负对数似然)】 |
| learning_rate (list of float, optional) ( |
每一轮迭代的学习率。 默认为0.1。 |
| num_leaves( |
指定了每棵树中叶子节点的最大数量。 默认31。 |
| max_depth | 限制树模型的最大深度,有助于防止模型过拟合。默认-1。 |
| min_data_in_leaf( |
用于指定一个叶子节点上必须包含的最少样本数量,有助于防止模型过拟合。 默认20。 |
| max_bin (max_bins) |
用于指定每个特征的最大分桶数量,影响模型的训练速度和内存使用,以及可能的模型精度和泛化能力。 默认255。 较大的 |
| feature_fraction( |
用于指定在每次迭代(即每棵树)中随机选择用于训练的特征的百分比,以此进行特征子采样,有助于防止过拟合并提高训练速度。 默认1.0。 通过减少每次迭代中使用的特征数量,该参数可以增加模型的泛化能力,并可能通过减少计算量来加速训练过程。 |
bagging_fraction(sub_row、subsample、bagging) |
用于指定在每次迭代中随机选择用于训练的样本的比例,以此进行样本子采样,有助于减少模型的方差,提高模型的稳定性和泛化能力。 默认1.0。 通过降低每次迭代中使用的样本数量,该参数可以增加模型的多样性,从而在一定程度上防止过拟合,并可能通过减少计算量来加速训练过程。 |
| bagging_freq(subsample_freq) | 用于指定进行bagging的频率,即每隔多少轮迭代执行一次bagging操作。 默认0。 它通过控制 bagging 的执行频率来影响模型的训练过程,进而对模型的稳定性和泛化能力产生影响。 |
lambda_l1(reg_alpha、l1_regularization) |
这是一个正则化参数,用于控制 L1正则化 的强度,以减少模型的复杂度 和 防止过拟合。默认0。 lambda_l1 通过设置一个 阈值,使得当节点的增益(gain)小于这个阈值时,该节点不再进行分裂,从而限制树模型的复杂度。这种机制有助于提升模型的泛化能力,防止在训练集上表现过好而在测试集上表现不佳的情况。 |
lambda_l2(reg_lambda、lambda、l2_regularization) |
这是另一个正则化参数,用于控制 L2正则化 的强度,通过为节点的增益分母(即节点样本数)增加一个常数项,来减少模型的复杂度和防止过拟合。 默认0。 它作用于整个训练过程,特别是在节点样本数较小时,能显著减小增益,从而避免不必要的节点分裂。 |
| min_gain_to_split(min_split_gain) | 用于指定进行树节点分裂所需的最小增益阈值,用于控制树的生长和分裂的精细程度,有助于防止过拟合。默认0。 设置 min_gain_to_split 参数可以确保只有当分裂带来的增益大于或等于该阈值时,节点才会被分裂,从而控制树的深度和复杂度,防止模型学习到训练数据中的噪声,提高模型的泛化能力。 |
num_threads(num_thread、nthread、nthreads、n_jobs) |
用于控制OpenMP并行执行时使用的最大线程数,以优化训练过程的性能。 默认0。 在可用的系统上,通过调整 num_threads 参数,可以充分利用多核CPU的计算资源,加速LightGBM的训练过程。默认情况下,LightGBM 会遵循 OpenMP 的默认行为,即每个真实CPU内核一个线程。 |
seed(random_seed、random_state) |
用于控制训练过程中的随机性,以确保实验的可重复性。 默认为None。 它主要影响数据的初始洗牌、特征选择和分裂等过程中的随机性。通过设定相同的 seed 值,在相同的数据集和参数配置下,可以多次获得完全相同的训练结果。 |
| verbose(verbosity) | 用于控制训练过程中的信息输出量,即控制训练日志的详细程度。默认为1。 verbose=0:没有任何输出信息。 |
2. Scikit-learn API(重复只做补充)
class lightgbm.LGBMClassifier(boosting_type='gbdt', num_leaves=31, max_depth=-1, learning_rate=0.1, n_estimators=100, subsample_for_bin=200000, objective=None, class_weight=None, min_split_gain=0.0, min_child_weight=0.001, min_child_samples=20, subsample=1.0, subsample_freq=0, colsample_bytree=1.0, reg_alpha=0.0, reg_lambda=0.0, random_state=None, n_jobs=None, importance_type='split', **kwargs)class lightgbm.LGBMRegressor(boosting_type='gbdt', num_leaves=31, max_depth=-1, learning_rate=0.1, n_estimators=100, subsample_for_bin=200000, objective=None, class_weight=None, min_split_gain=0.0, min_child_weight=0.001, min_child_samples=20, subsample=1.0, subsample_freq=0, colsample_bytree=1.0, reg_alpha=0.0, reg_lambda=0.0, random_state=None, n_jobs=None, importance_type='split', **kwargs)| lightgbm.LGBMClassifier lightgbm.LGBMRegressor |
参数含义 |
|---|---|
| subsample_for_bin | 指定了用于构建直方图的样本数量。 默认为200000。 这个参数影响模型在特征选择过程中的细节,通过限制用于计算直方图的样本数,可以在保持一定精度的同时减少计算量,提高模型的训练效率。 |
| class_weight | 用于处理不平衡数据集,通过给不同类别的样本赋予不同的权重,以改善模型对少数类样本的识别能力。 默认为None。 这有助于模型在训练过程中更加关注那些数量较少的类别,从而提高整体分类性能。可以填 ’balanced‘ 自动处理,也可以以{class_label: weight} 格式手动设置。 |
| min_child_weight | 用于控制一个叶子节点上所有样本的权重之和的最小值,以防止模型过拟合。 默认为1e-3。 当某个叶子节点的样本权重和小于该参数时,该节点将不会继续拆分。 较大的min_child_weight值会使模型更加保守,倾向于生成较浅的树,有助于防止过拟合,但也可能导致模型欠拟合。 |
| min_child_samples | 用于控制每个叶子节点所需的最小样本数,以防止模型过拟合。 默认为20。 该参数设置了一个阈值,只有当叶子节点中的样本数大于或等于这个阈值时,节点才会被进一步拆分。 通过调整这个参数,可以影响模型的复杂度和泛化能力。较大的min_child_samples值会使模型更加保守,倾向于生成较浅的树,有助于防止过拟合,但也可能导致模型欠拟合。 |
3. lightgbm.cv
lightgbm.cv(params, train_set, num_boost_round=100, folds=None, nfold=5, stratified=True, shuffle=True, metrics=None, feval=None, init_model=None, feature_name='auto', categorical_feature='auto', fpreproc=None, seed=0, callbacks=None, eval_train_metric=False, return_cvbooster=False)作用:使用给定的 参数实施 交叉验证。
| lightgbm.cv | 参数含义 |
|---|---|
| train_set | 指定数据。 |
| folds | 自定义的交叉验证分割器。 如果提供了这个参数, |
| nfold | 交叉验证的折数。默认为5。 |
| stratified | 是否进行分层抽样。默认值为 在分类问题中,如果类的分布是不均匀的,分层抽样可以帮助保持每一折中类的比例与原始数据集相似。 |
| shuffle | 拆分数居前是否shuffle。默认值为 True。 |
4. lightgbm.Dataset
class lightgbm.Dataset(data, label=None, reference=None, weight=None, group=None, init_score=None, feature_name='auto', categorical_feature='auto', params=None, free_raw_data=True, position=None)| lightgbm.Dataset | 参数含义 |
|---|---|
| data | 指定训练或测试数据集。 |
| label | 指定目标变量(即标签),用于有监督学习任务。默认为None。 |
| reference | 指定一个参考数据集,用于在后续的数据集上应用相同的特征索引和分组策略。 这通常用于训练集和测试集之间的特征对齐。 |
| categorical_feature (list of str or int, or 'auto', optional) |
指定哪些特征是分类特征。LightGBM 会对这些特征进行优化处理,以提高训练效率和模型性能。默认为'auto'。 如果设置为 'auto',LightGBM 会尝试自动检测分类特征。 |
| weight (list, numpy 1-D array, pandas Series, pyarrow Array, pyarrow ChunkedArray or None, optional) |
指定每个样本的权重。默认为None。 这在处理不平衡数据集时特别有用,可以通过给少数类样本赋予更高的权重来平衡不同类别的影响。 |
| free_raw_data | 如果设置为True,则在构建内部数据结构后释放原始数据的内存,以减少内存使用。默认为True。 这对于大数据集特别有用。 |
| 方法 | 含义 |
| get_data() | 获取Dataset的原始数据。 |
| get_feature_name() | 获取Dataset中列(特征)的名称。 |
| get_label() | 获取Dataset的标签。 |
| get_params() | 获取Dataset使用的参数。 |
更多方法可以查看 lightgbm.Dataset — LightGBM 4.5.0.99 documentation
5. Callbacks
(1)lightgbm.record_evaluation
lightgbm.record_evaluation(eval_result)作用:在训练过程中 自动地记录 并输出模型 在验证集(或训练集)上的 性能指标,如准确率、AUC值 等,以 帮助用户 监控模型的 训练过程 和 性能。
(2)lightgbm.early_stopping
lightgbm.early_stopping(stopping_rounds, first_metric_only=False, verbose=True, min_delta=0.0)功能:用于 控制 早停(early stopping)行为的 功能。在 LightGBM 的训练过程 中,早停 是一种 防止过拟合的 技术,它会 在验证集上的 性能 不再提升时 提前 停止训练。
# 实例
lgb_train = lgb.Dataset(x_train, y_train)
lgb_test = lgb.Dataset(x_test, y_test, reference=lgb_train)
params = {
'boosting':'gbdt',
'objective':'binary',
"metric": ('auc')
}
eval_result = {}
lgb_model = lgb.train(
params, lgb_train, num_boost_round=200, valid_sets=lgb_test
,callbacks=(lgb.record_evaluation(eval_result), lgb.early_stopping(stopping_rounds=3))
)(3)lightgbm.log_evaluation
lightgbm.log_evaluation(period=1, show_stdv=True)功能:创建一个记录计算结果的回调。
(4)lightgbm.reset_parameter
lightgbm.reset_parameter(**kwargs)功能:创建一个回调函数,再一次迭代后重制参数。
6. Plotting
(1)lightgbm.plot_metric
lightgbm.plot_metric(booster, metric=None, dataset_names=None, ax=None, xlim=None, ylim=None, title='Metric during training', xlabel='Iterations', ylabel='@metric@', figsize=None, dpi=None, grid=True)作用:绘制训练过程中记录的评估指标。(结合 record_evaluation 使用)
| lightgbm.plot_metric | 参数含义 |
|---|---|
| booster | lightgbm.train() 返回值。 |
| metric | 要绘制的度量名称。 |
(2)lightgbm.plot_importance
lightgbm.plot_importance(booster, ax=None, height=0.2, xlim=None, ylim=None, title='Feature importance', xlabel='Feature importance', ylabel='Features', importance_type='auto', max_num_features=None, ignore_zero=True, figsize=None, dpi=None, grid=True, precision=3, **kwargs)作用:绘制特征重要性排序。
(3)lightgbm.plot_tree
lightgbm.plot_tree(booster, ax=None, tree_index=0, figsize=None, dpi=None, show_info=None, precision=3, orientation='horizontal', example_case=None, **kwargs)作用:画决策树。
(4)lightgbm.create_tree_digraph
lightgbm.create_tree_digraph(booster, tree_index=0, show_info=None, precision=3, orientation='horizontal', example_case=None, max_category_values=10, **kwargs)作用:画树图。
# 实例
print('画出训练结果...')
ax = lgb.plot_metric(evals_result, metric='auc')
plt.show()
print('画特征重要性排序...')
lgb.plot_importance(gbm, max_num_features=10)
plt.show()
print('Plot 3th tree...') # 画出决策树,其中的第三颗
lgb.plot_tree(gbm, tree_index=3, figsize=(20, 8), show_info=['split_gain'])
plt.show()
print('画出决策树的pdf图')
lgb.create_tree_digraph(gbm, tree_index=3, name='Tree3')三、调参
1. 基本流程(使用GridSearchCV)
# 初始参数
params = {
'boosting':'gbdt',
'objective':'binary',
"metric": ('auc')
}(1)确定 max_depth 和 num_leaves
params_test1={
'max_depth': range(3,8),
'num_leaves': range(25,70,5)
}(2)确定 min_data_in_leaf 和 max_bin
params_test2={
'max_bin': range(10,256,20),
'min_data_in_leaf': range(10,101,10)
}(3)确定 feature_fraction、bagging_fraction、bagging_freq
params_test3={
'feature_fraction': [0.6, 0.7, 0.8, 0.9, 1.0],
'bagging_fraction': [0.6, 0.7, 0.8, 0.9, 1.0],
'bagging_freq': range(0,81,10)
}(4)确定lambda_l1和lambda_l2
params_test4={
'lambda_l1': [1e-5, 1e-3, 1e-1, 0.0, 0.1, 0.3, 0.5, 0.7, 0.9, 1.0],
'lambda_l2': [1e-5, 1e-3, 1e-1, 0.0, 0.1, 0.3, 0.5, 0.7, 0.9, 1.0]
}(5)确定 min_split_gain
params_test5={
'min_split_gain': [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
}(6)最后再次尝试调节降低学习率,增加迭代次数,验证模型。
2. 其他需求
(1)更快的训练速度
- 通过设置
bagging_fraction和bagging_freq参数来使用 bagging 方法 - 通过设置
feature_fraction参数来使用特征的子抽样 - 使用较小的
max_bin - 使用
save_binary在未来的学习过程对数据加载进行加速 - 使用并行学习
(2)更好的准确率
- 使用较大的
max_bin(学习速度可能变慢) - 使用较小的
learning_rate和 较大的num_iterations - 使用较大的
num_leaves(可能导致过拟合) - 使用更大的训练数据
- 尝试
dart
(3)处理过拟合
- 使用较小的
max_bin - 使用较小的
num_leaves - 使用
min_data_in_leaf和min_sum_hessian_in_leaf - 通过设置
bagging_fraction和bagging_freq来使用 bagging - 通过设置
feature_fraction来使用特征子抽样 - 使用更大的训练数据
- 设置
lambda_l1、lambda_l2和min_gain_to_split来使用正则化 - 尝试
max_depth来避免生成过深的树