字节跳动(社招)三面算法原题
字节跳动
昨天聊到了 字节开始卡学历了,评论区不少小伙伴感同身受。
当中有一个问题挺有意思的:什么时候投递最好,会有区别吗?
当然有区别了,而且差别巨大。
通常校招都是在一段时间内进行,但 HC(人头数)是从刚开始就确定了。
因此,当招聘市场"供不应求"的时候,越到后面要求会越宽松,毕竟完成招聘任务是第一优先级,这时候还会出现"同厂不同组抢人"的情况;但当招聘市场"供过于求"的时候,为了不让招聘过程显得突兀(距离招聘截止日期还有很久,但人已招满),这时候通常会卡住一些流程,尽量拖时间,此时越到后面要求越高,希望越少。
现在招聘市场什么情况,不用我多说了,寒气已经从头到脚了。
所以几年前学长学姐教你的"先稳稳,再拖拖"那一套现在可以扔垃圾桶里,通道开放后,第一时间投递就是最优解。
另外,最近有消息称字节跳动正在秘密筹备成立大模型研究院,并积极招揽人才。包括前零一万物技术联创黄文灏也已加入字节跳动,负责技术项目管理和规划,汇报给字节跳动大模型负责人朱文佳。
不管会不会成立独立机构,但加强大模型相关研究的长期计划是板上钉钉的。
所以,虽然目前某些字节跳动的 BU 已经开始拖流程,但在下半年,必然会有新业务大量招兵买马,抓紧准备吧各位。
...
回归主题。
来一道和「字节跳动(抖音)」相关的算法原题。
题目描述
平台:LeetCode
题号:1631
你准备参加一场远足活动。
给你一个二维 rows x columns 的地图 heights,其中 heights[row][col] 表示格子 (row, col) 的高度。
一开始你在最左上角的格子 (0, 0) ,且你希望去最右下角的格子 (rows-1, columns-1) (注意下标从 0 开始编号)。
你每次可以往「上,下,左,右」四个方向之一移动,你想要找到耗费体力最小的一条路径。
一条路径耗费的「体力值」是路径上相邻格子之间「高度差绝对值」的「最大值」决定的。
请你返回从左上角走到右下角的最小体力消耗值。
示例 1:
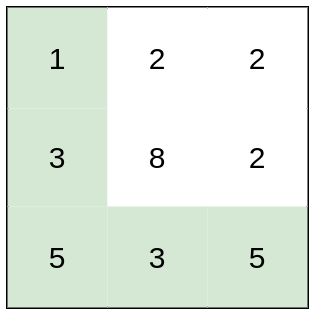
输入:heights = [[1,2,2],[3,8,2],[5,3,5]]
输出:2
解释:路径 [1,3,5,3,5] 连续格子的差值绝对值最大为 2 。
这条路径比路径 [1,2,2,2,5] 更优,因为另一条路径差值最大值为 3 。
示例 2:
输入:heights = [[1,2,3],[3,8,4],[5,3,5]]
输出:1
解释:路径 [1,2,3,4,5] 的相邻格子差值绝对值最大为 1 ,比路径 [1,3,5,3,5] 更优。
示例 3:
输入:heights = [[1,2,1,1,1],[1,2,1,2,1],[1,2,1,2,1],[1,2,1,2,1],[1,1,1,2,1]]
输出:0
解释:上图所示路径不需要消耗任何体力。
提示:
Kruskal
「当一道题我们决定往「图论」方向思考时,我们的重点应该放在「如何建图」上。」
因为解决某个特定的图论问题(最短路/最小生成树/二分图匹配),我们都是使用特定的算法。
由于使用到的算法都有固定模板,因此编码难度很低,而「如何建图」的思维难度则很高。
对于本题,我们可以按照如下分析进行建图:
因为在任意格子可以往「任意方向」移动,所以相邻的格子之间存在一条无向边。
题目要我们求的就是「从起点到终点的最短路径中,边权最大的值」。
我们可以先遍历所有的格子,将所有的边加入集合。
存储的格式为数组 ,代表编号为 a 的点和编号为 b 的点之间的权重为 w。
按照题意,w 为两者的高度差的绝对值。
对集合进行排序,按照 w 进行从小到大排序(Kruskal 部分)。
当我们有了所有排好序的候选边集合之后,我们可以对边进行从前往后处理,每次加入一条边之后,使用并查集来查询「起点」和「终点」是否连通(并查集部分)。
「当第一次判断「起点」和「终点」联通时,说明我们「最短路径」的所有边都已经应用到并查集上了,而且由于我们的边是按照「从小到大」进行排序,因此最后一条添加的边就是「最短路径」上权重最大的边。」
Java 代码:
class Solution {
int N = 10009;
int[] p = new int[N];
int row, col;
void union(int a, int b) {
p[find(a)] = p[find(b)];
}
boolean query(int a, int b) {
return p[find(a)] == p[find(b)];
}
int find(int x) {
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
public int minimumEffortPath(int[][] heights) {
row = heights.length;
col = heights[0].length;
// 初始化并查集
for (int i = 0; i < row * col; i++) p[i] = i;
// 预处理出所有的边
// edge 存的是 [a, b, w]:代表从 a 到 b 的体力值为 w
// 虽然我们可以往四个方向移动,但是只要对于每个点都添加「向右」和「向下」两条边的话,其实就已经覆盖了所有边了
List<int[]> edges = new ArrayList<>();
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
int idx = getIndex(i, j);
if (i + 1 < row) {
int a = idx, b = getIndex(i + 1, j);
int w = Math.abs(heights[i][j] - heights[i + 1][j]);
edges.add(new int[]{a, b, w});
}
if (j + 1 < col) {
int a = idx, b = getIndex(i, j + 1);
int w = Math.abs(heights[i][j] - heights[i][j + 1]);
edges.add(new int[]{a, b, w});
}
}
}
// 根据权值 w 降序
Collections.sort(edges, (a,b)->a[2]-b[2]);
// 从「小边」开始添加,当某一条边别应用之后,恰好使用得「起点」和「结点」联通
// 那么代表找到了「最短路径」中的「权重最大的边」
int start = getIndex(0, 0), end = getIndex(row - 1, col - 1);
for (int[] edge : edges) {
int a = edge[0], b = edge[1], w = edge[2];
union(a, b);
if (query(start, end)) {
return w;
}
}
return 0;
}
int getIndex(int x, int y) {
return x * col + y;
}
}
C++ 代码:
class Solution {
public:
int N = 10009;
vector<int> p;
int row, col;
void unions(int a, int b) {
p[find(a)] = find(b);
}
bool query(int a, int b) {
return find(a) == find(b);
}
int find(int x) {
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int minimumEffortPath(vector<vector<int>>& heights) {
row = heights.size();
col = heights[0].size();
p.resize(row * col);
for (int i = 0; i < row * col; ++i) p[i] = i;
vectorint, pair<int, int>>> edges;
for (int i = 0; i < row; ++i) {
for (int j = 0; j < col; ++j) {
int idx = i * col + j;
if (i + 1 < row) {
edges.emplace_back(abs(heights[i][j] - heights[i + 1][j]), make_pair(idx, (i + 1) * col + j));
}
if (j + 1 < col) {
edges.emplace_back(abs(heights[i][j] - heights[i][j + 1]), make_pair(idx, idx + 1));
}
}
}
sort(edges.begin(), edges.end());
int start = 0, end = row * col - 1;
for (const auto& edge : edges) {
int w = edge.first, a = edge.second.first, b = edge.second.second;
unions(a, b);
if (query(start, end)) {
return w;
}
}
return 0;
}
};
Python 代码:
class Solution:
def union(self, a: int, b: int) -> None:
root_a = self.find(a)
root_b = self.find(b)
if root_a != root_b:
self.p[root_b] = root_a
def query(self, a: int, b: int) -> bool:
return self.find(a) == self.find(b)
def find(self, x: int) -> int:
if self.p[x] != x:
self.p[x] = self.find(self.p[x])
return self.p[x]
def minimumEffortPath(self, heights: List[List[int]]) -> int:
self.row = len(heights)
self.col = len(heights[0])
self.N = 10009
self.p = list(range(self.row * self.col))
edges = []
for i in range(self.row):
for j in range(self.col):
idx = i * self.col + j
if i + 1 < self.row:
edges.append((abs(heights[i][j] - heights[i + 1][j]), (idx, (i + 1) * self.col + j)))
if j + 1 < self.col:
edges.append((abs(heights[i][j] - heights[i][j + 1]), (idx, idx + 1)))
edges.sort(key=lambda x: x[0])
start = 0
end = self.row * self.col - 1
for w, (a, b) in edges:
self.union(a, b)
if self.query(start, end):
return w
return 0
- 时间复杂度:令行数为 ,列数为 ,那么节点的数量为 ,无向边的数量严格为 ,数量级上为 。获取所有的边复杂度为 ,排序复杂度为 ,遍历得到最终解复杂度为 。整体复杂度为 。
- 空间复杂度:使用了并查集数组。复杂度为 。
证明
「我们之所以能够这么做,是因为「跳出循环前所遍历的最后一条边必然是最优路径上的边,而且是 w 最大的边」。」
我们可以用「反证法」来证明这个结论为什么是正确的。
我们先假设「跳出循环前所遍历的最后一条边必然是最优路径上的边,而且是 w 最大的边」不成立:
我们令循环终止前的最后一条边为 a
- 假设
a不在最优路径内:如果a并不在最优路径内,即最优路径是由a边之前的边构成,那么a边不会对左上角和右下角节点的连通性产生影响。也就是在遍历到该边之前,左上角和右下角应该是联通的,逻辑上循环会在遍历到该边前终止。与我们循环的决策逻辑冲突。 -
a在最优路径内,但不是w最大的边:我们在遍历之前就已经排好序。与排序逻辑冲突。
因此,我们的结论是正确的。a 边必然属于「最短路径」并且是权重最大的边。
最后
巨划算的 LeetCode 会员优惠通道目前仍可用 ~
使用福利优惠通道 leetcode.cn/premium/?promoChannel=acoier,年度会员 有效期额外增加两个月,季度会员 有效期额外增加两周,更有超大额专属 和实物 福利每月发放。
我是宫水三叶,每天都会分享算法知识,并和大家聊聊近期的所见所闻。
欢迎关注,明天见。
更多更全更热门的「笔试/面试」相关资料可访问排版精美的 合集新基地