一文读懂CEPH RGW基本原理
一文读懂CEPH RGW基本原理
一、RGW简介
二、RGW的组成结构
三、Rgw用户信息
四、BUCKET与对象索引信息
五、RGW对象与RADOS对象的关系
六、上传对象的处理流程
七、RGW的双活机制
八、RGW版本管理机制与CLS机制
九、结语
本文从RGW的基本原理出发,从整体上描述RGW的框架结构,突出关键结构之间的关联关系,从基础代码分析关键环节的实现细节,以达到清晰说明RGW模块“骨架”的效果。
一、RGW简介
RGW是CEPH系统的一种应用,用于对外提供对象存储服务。随着技术的发展,网络中的非结构化数据越来越多,而且数据量特别大,这些数据在技术上表现为大块的顺序读写,并且单次写入、多次读取,数据内容上传后几乎不会修改,这就提出了使用分布式技术存储这些对象数据的迫切需求。RGW是其中基于CEPH技术的一种需求实现。互联网中常见的云存储也是这类需求的具体应用。
RGW以S3协议和SWIFT协议对外提供对象存储服务,两个协议有较多的相似之处。S3协议全称为Amazon Simple Storage,源于亚马逊早期推出的云计算服务。SWIFT是OpenStack云平台的一个云存储子系统,两者的对象访问方式均以HTTP方式访问,上传对象为PUT,下载对象为GET,删除对象的接口为DELETE;但两者在用户管理、对象集合方面有些差异,S3协议采用Bucket组织对象,SWIFT采用Container组织对象。基于此,RGW在上层针对两个协议分别实现,屏蔽两者的差异,在中间层以后则采用一致的设计实现。为支持HTTP协议,RGW模块内部还集成了WEB服务器civetweb。本文重点以S3协议为例进行阐述。
S3协议与SWIFT协议主要接口对比表
| 项目 | S3协议 | SWIFT协议 |
|---|---|---|
| 查询用户的存储桶 | List Buckets | List Containers |
| 查询存储桶内的对象 | List Bucket | List Container |
| 上传对象 | Put Object | Put Object |
| 下载对象 | Get Object | Get Object |
| 删除对象 | Delete Object | Delete Object |
对内而言,用户的对象经由RGW处理后,会最终存放在后端RADOS系统内。RGW所负责的就是用户对象到后端RADOS对象的转换。用户对象就是用户的文件,比如文本文件、图片文件、音视频文件或者打包的压缩文件,其大小可能很小,只有几个字节,也可能很大,数G或者数T,经由RGW处理后,这些文件都将以RADOS对象的方式存储。单个RADOS对象理论上也可以存放大量数据,但是综合考虑I/O效率、数据迁移和各节点均衡分布等因素,在实际使用时一般都会限制单个RADOS对象的大小。对于RGW应用场景而言,默认限制单个RADOS对象的大小最大为4M。在这种情形下,RGW就需要处理RGW对象怎么分解为多个RADOS对象、这些RADOS对象怎么组织、RGW元数据如何存放等问题,这也是本文分析的重点。
RADOS对象与RGW对象主要特性对比表
| 项目 | RADOS对象 | RGW对象 |
|---|---|---|
| 服务协议 | HTTP | LIBRADOS |
| 对象大小 | 一般限制在4M | S3协议默认限制在5T |
| 覆盖写支持 | 支持 | 不支持 |
| 索引支持 | 不支持 | 支持 |
| 版本控制 | 不支持 | 支持 |
二、RGW的组成结构
RGW 是RADOS Gateway 的缩写。RGW 是运行于RADOS集群之上的一个RADOS Client 实例,是CEPH集群对外提供对象存储服务的一个网关,它允许用户通过Restful API 的方式访问CEPH集群。其提供的Restful API具体为S3 API 和Swift API,即符合S3 协议和Swift 协议。
向下RGW通过LibRADOS接口库访问RADOS集群。RGW的所有数据,包括集群内RGW服务单元zone的配置信息、用户信息等元数据和实际内容数据均存放在RADOS集群内,RGW自身不持久化存储数据。RGW与RADOS集群的通讯方式为网络通信,基于TCP协议与RADOS集群内的Monitor节点和OSD节点进行高速的数据访问与处理。
RGW的组成结构如下图。

图中Frontend WEB服务器用于监听并接收HTTP服务请求。默认情况下RGW内嵌入了WEB服务器Civetweb(N版本后换成了beast),相关请求在RGW进程内直接处理;此外,RGW支持Apache、Nginx等第三方WEB服务器。与第三方WEB服务器集成时,RGW与WEB服务器是独立的进程,WEB服务器通过RGW注册的监听端口转发请求给RGW。本文以内嵌入的Civetweb为例进行说明,在此情形下Civetweb以线程池的模式运行在RGW进程内,以便于多任务的并发处理;默认线程数为512个,并受配置参数rgw_thread_pool_size控制。
REST API处理层负责处理S3协议与SWIFT协议的协议API特性逻辑。S3X协议接口采用WEB API形式,由GET、PUT、DELETE等简单的WEB接口组成,分别对应上传、下载、删除等操作。用户的操作请求到达WEB服务器后,操作请求会先交由该层处理。该层依据具体的S3协议或SWIFT协议将操作请求进一步整理,去除协议特性,按照RGW对象标准操作格式提交给下一层处理。
Execution层按照RGW对象的标准格式处理各类操作请求,各类操作请求在该层中都有相对应的程序实现。在这一层中会根据操作请求处理RGW对象的元数据和内容数据,并操纵RGW-RADOS适配层进行I/O操作。
RGW-RADOS适配层会将对RGW对象的操作转化为对RADOS对象的操作。操作RADOS对象主要通过LIBRADOS接口实现,因此LIBRADOS接口对该层而言是完全可见的。RGW对象的所有数据均以RADOS对象作为支撑,在处理用户操作请求的过程中,需要使用RGW对象多种关联信息,因此RGW-RADOS适配层会在这一过程中被反复多次调用。
LIBRADOS是RADOS系统的对外窗口,在RGW应用环境中它运行在RGW进程内,并通过网络协议访问RADOS系统内的OSD(数据存储节点)、MONITOR(监控管理节点)。RGW、RBD(CEPH的块存储应用)等均要通过LIBRADOS接口库访问RADOS系统,它是规范使用CEPH的重要接口。该库除实现公开的标准接口外,还实现了CRUSH对象寻址算法,这意味着应用RGW可更具CRUSH算法的运算结果直接发起对最终OSD数据存储节点的访问,能做到更高的I/O效率。
GC资源回收模块属于辅助模块,是针对磁盘空间等资源的回收。RGW使用专门的线程负责此项工作。在客户端执行删除对象操作后,对象所占用的磁盘空间会由后台GC线程处理;此外在执行对象上传操作时,上传过程中会产生一些临时数据,这些临时数据也会由GC线程负责回收。可使用命令“radosgw-admin gc list --cluster clustername”查看资源回收处理情况。
QUOTA配额管理模块也属于辅助模块,其用于管理存储桶和用户的配额。存储桶配额可限制存储桶内的所有对象大小、对象数量,用户配额可限制用户所有对象的大小和对象数量。配额信息的访问和更新都比较频繁,因此RGW将配额信息缓存在缓存中,同时设置了数个配置项控制缓存配额信息与落盘配额信息的同步周期、同步时机,在RGW进程内还有相应的“rgw_buck_st_syn”“rgw_user_st_syn”线程处理这些工作。可通过“radosgw-admin”命令配置相关配置项,也可配置为不开启配额功能。
AUTH权限管理模块也是一个辅助模块,其涉及到基于S3协议的用户身份认证和基于swift协议的用户身份认证,以及用户对资源的操作权限管理。S3协议的身份认证基于密钥进行,swift协议的用户身份认证基于令牌认证。操作权限方面RGW将划分为读、写、删除等不同类别,这些功能均在AUTH权限管理模块中实现。
三、Rgw用户信息
Rgw用户信息存放在多个rados对象内。根据S3协议规定,用户访问RGW时会首先发送acess key和一段密文信息,并不会直接发送用户名。因此对RGW用户相关信息的描述是从access key开始。基于access key可检索出用户名,基于用户名可查找到该用户的id、别名以及email等关联信息;同时在知道用户名的情况下,可直接到RADOS对象“{username}.bucket”内查询出用户的所有bucket。下图以图示的方式说明各部分之间的关联关系。
 图中,用户的access key作为一个RADOS对象单独存在,该对象的名字就是{access key},如“AccessKeyDemo”,内容是access key对应的用户名{username},如“UserNameDemo”。这意味着access key在RADOS内是以明文、并作为RADOS对象名存在的,也意味着不同RGW用户的access key不能相同,在创建RGW用户时也会检查access key是否冲突,冲突时会提示“user id mismatch”。
图中,用户的access key作为一个RADOS对象单独存在,该对象的名字就是{access key},如“AccessKeyDemo”,内容是access key对应的用户名{username},如“UserNameDemo”。这意味着access key在RADOS内是以明文、并作为RADOS对象名存在的,也意味着不同RGW用户的access key不能相同,在创建RGW用户时也会检查access key是否冲突,冲突时会提示“user id mismatch”。
对于username,会在RADOS内的POOL“{zone}.rgw.meta”中直接创建一个以具体username命名的RADOS对象,该对象通过内容数据存放用户的基本信息,基本信息对应数据结构RGWUserInfo,其内包含user_id、display neme、access key等信息。POOL是RADOS对外提供的、用以管理并划分RADOS对象的一个逻辑结构,一个RGW的zone会有多个RADOS POOL来支撑。
针对用户与其所持有的bucket,会在RADOS内创建一个以具体username+“.bucket”为名称的RADOS对象。在该对象的OMAP属性内记录了RGW用户所持有的bucket的基本信息。OMAP属性是KV结构,OMAP属性的名为具体的bucket名称,属性值为cls_user_bucket_entry结构数据,其内记录了bucket名称、大小size、创建时间creation_time等基本信息。
对于每个bucket,系统会以具体的bucket名称创建对应的RADOS对象,其内以XATTR属性的方式存放了bucket拥有者的基本信息,这些信息与前述username对象相同。此外对于每个bucket,系统还会创建其他多个RADOS对象,用于存放bucket自身的一个基础元数据信息,包括bucket的ACL策略、bucket内的对象列表等。下一节再详细说明。
上述这些RADOS对象均存放在POOL“{zone}.rgw.meta”内。为了更好地区分这些不同类别的RADOS对象,RGW利用了RADOS的命名空间机制。比如username对象在users.uid命名空间、acess key对象在users.keys命名空间等。命名空间是RADOS对象标识的基本结构组成之一,它作为一个因素参与到CRUSH运算之中,在后端存储落盘时它也是最终数据文件的标识因素之一,因此不同命名空间的RADOS对象可以重名。在rados ls 命令中使用参数—all可以列出特定pool下所有命名空间中的对象,如下例所示:
# rados ls -p ZoneTest.rgw.meta --all
此外从图中还可看出,用户基本信息以及用户与bucket之间的关联等由单独的RADOS对象存放,RADOS对象内会以内容数据、XATTR属性数据或OMAP属性数据等形式存放数据,XATTR数据数据读取速度最快,但其数据大小具有严格的限制;OMAP数据的读写速度次之,在后台它在专门的KV数据库内存放,其数据条目可根据应用需求增加;RADOS对象的内容数据则没有太多限制,只要不超过设定的限制即可,默认限制是100G。各RADOS对象间通过RADOS对象名称进行关联,这些关联关系在RGW程序逻辑中直接确定。比如在已知用户名“UserNameDemo”的情况下,可以到RADOS对象“UserNameDemo.bucket”内直接查询到该用户所拥有的bucket;在已知bucket名称“BucketNameDemo”的情况下,可以在RADOS对象“BucketNameDemo”中直接查询到bucket拥有者的基本信息。
四、BUCKET与对象索引信息
与描述用户相类似,Bucket自身以及对象索引等元数据信息也存放在数个RADOS对象内。相关主要RADOS对象及其关联关系如下图所示。
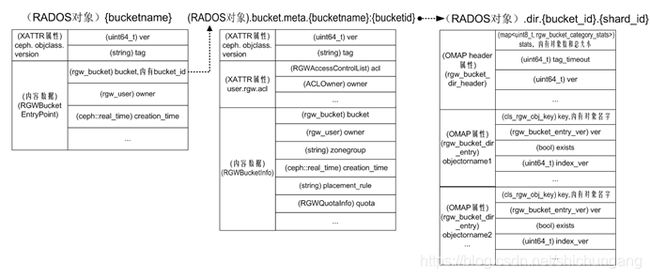 Bucket自身最基本的元数据信息存放在{bucketname}RADOS对象内,这个RADOS对象的名字就是bucket的名字,存放在{zone}.rgw.meta POOL中,命名空间为root,在其内容数据中存放了bucket的bucket_id、bucket拥有者、创建时间等基本信息。
Bucket自身最基本的元数据信息存放在{bucketname}RADOS对象内,这个RADOS对象的名字就是bucket的名字,存放在{zone}.rgw.meta POOL中,命名空间为root,在其内容数据中存放了bucket的bucket_id、bucket拥有者、创建时间等基本信息。
Bucket更为丰富的元数据信息保存在.bucket.meta.{bucketname}:{bucketid} RADOS对象内,这个RADOS对象的XATTR属性中存放了bucket的访问控制策略,XATTR属性名为user.rgw.acl,属性值对应数据结构RGWAccessControlPolicy。这个RADOS对象的内容数据部分存放了bucket的主要元数据信息,包括bucket拥有者、所属zonegroup、空间配额quota等,对应数据结构RGWBucketInfo。该RADOS对象同样存放在{zone}.rgw.meta POOL中,命名空间也为root。这个RADOS对象的名字较长,可用rados命令列出该RADOS对象以及Bucket基本元数据的RADOS对象。
# rados ls -p ZoneTest.rgw.meta --namespace=root
BuckertNameTest
.bucket.meta.BuckertNameTest:ab46ccc9-4eb5-432d-8d9e-63d79720582e.2674103.1
bucket内的对象索引信息会分片存放在多个RADOS对象内。因为CEPH定位于大规模分布式对象存储,因此一个Bucket内的对象可能会非常多,将索引信息分片存放有利于提高对象检索的速度。这些RADOS对象命名规则为.dir.{bucket_id}.{shard_id},存放在{zone}.rgw.buckets.index POOL内,未设定命名空间。这些RADOS对象有多个OMAP属性,每个属性对应一个对象,属性名为对象名,属性值为对应的基本元数据信息,包括对象名字、版本、存在状态等,对应数据结构rgw_bucket_dir_entry。在生产环境中,OMAP属性数据常存放在SSD等快速存储介质上,以OMAP方式存放对象索引信息有利于提高索引信息的读写速度。
此外这些RADOS对象的OMAPHeader属性中存放了Bucket的整体统计信息,包括Bucket内对象总数和总大小,对应数据结构rgw_bucket_dir_header。OMAPHeader属性是OMAP属性的一种,与常规OMAP属性相比,它不需要指定属性名,直接存放属性值;在RADOS后端实现时,以“{对象ID}-”作为key名进行数据读写。
五、RGW对象与RADOS对象的关系
RGW对象最终是由RADOS对象承载的。根据RGW对象的大小,RGW对象与RADOS对象的对应关系分为三种情况。当RGW对象的内容数据小于默认设定值4M时,一个RGW对象对应一个RADOS对象;当RGW对象超过4M、小于S3客户端设定值(s3cmd默认设定15M)时,RGW对象由一个首部RADOS对象和多个分片RADOS对象组成;对于更大的RGW对象(s3cmd默认是超过15M),RGW对象由一个首部RADOS对象和多个分段对象组成,每个分段对象又由multipart RADOS对象和分片RADOS对象组成。当使用java等应用编程接口时,按段分割界限可由应用指定,但最大不超过5G,当RGW对象超过5G时必须分段上传。
对于小于4M的对象,其与RADOS对象的关系如下图。此处以只有12字节“Hello world!”RGW对象hw为例进行说明。此时在{zone}.rgw.buckets.data POOL下只建立一个RADOS对象,RADOS对象名字为{bucketid}{RGW对象名字}。该对象的数据内容就是RGW对象要存储的内容,该对象的user.rgw.manifest XATTR属性存放了RGW对象的数据布局信息,包括RGW对象的实际大小、首部对象的实际大小、首部对象允许的最大大小、存在其他RADOS对象时的对象命名前缀等关键信息。此外该首部对象还有user.rgw.acl、user.rgw.content_type、user.rgw.source_zone等多个XATTR属性信息。
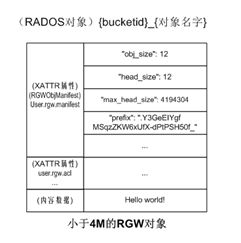
对于大于4M、小于默认值15M的RGW对象,系统在RADOS首部对象后面增加其他RADOS对象存放数据,这种方式称为数据分片。新增加的RADOS对象只存放内容数据,没有XATTR或OMAP属性数据,并以{bucketid}shadow{prefix}{stripid1}命名,其中前缀prefix来自于首部对象的user.rgw.manifest XATTR属性值,在新建RGW对象时随机产生。

对于大于默认值15M的RGW对象,S3协议客户端s3cmd将会分段上传,每段内容数据不超过15M,在RADOS中存放数据时也以15M为分段界限进行存放。按段分割界限是由S3协议规定的,最大不超过5G,实际使用时每段不宜太大。因为S3协议使用的是HTTP传输协议,HTTP协议更适合在一个协议会话中传输短报文,在一个协议会话中传输太大的文件容易影响系统稳定性。HTTP协议服务端更喜欢能尽快地完成并结束一个协议话。此外S3协议的这个规定,也有利于按段进行断点续传。当分段存放时RGW对象的组织方式如下。
 此时,首部对象不再存放内容数据,只以XATTR属性的形式user.rgw.manifest等元数据信息。在每段的首部会有一个multipart对象,其自身会存放不超过4M的内容数据,以及user.rgw.acl等XATTR属性数据。在multipart对象后面会有一些strip分片对象,专门用于存放内容数据,每个内容数据大小同样不超过4M。因为每段最多15M,每个multipart对象自身可存放4M内容数据,因此其后面的分片对象不超过3个。
此时,首部对象不再存放内容数据,只以XATTR属性的形式user.rgw.manifest等元数据信息。在每段的首部会有一个multipart对象,其自身会存放不超过4M的内容数据,以及user.rgw.acl等XATTR属性数据。在multipart对象后面会有一些strip分片对象,专门用于存放内容数据,每个内容数据大小同样不超过4M。因为每段最多15M,每个multipart对象自身可存放4M内容数据,因此其后面的分片对象不超过3个。
从上述RGW对象的数据组织方式也可看出,RGW对象存储的数据访问特征是大块的顺序读写,并且单次写入、多次读取,数据内容上传后几乎不会修改。如果数据经常需要随机改写和追加,使用RGW存放会比较困难。
六、上传对象的处理流程
下面以上传12个字节的RGW对象hw为例说明对象的上传过程。Hw对象的内容为“Hello world!”,对象以S3接口方式上传。使用s3cmd命令“s3cmd put ./hw s3://BucketNameDemo”上传对象hw,上传操作与RGW之间的会话基于HTTP协议,它们间的第一个会话交互如下。
//操作请求提交的内容
GET /BucketNameDemo/?location HTTP/1.1
Host: 10.21.170.218:7480
Accept-Encoding: identity
Content-Length: 0
x-amz-content-sha256: e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
Authorization: AWS4-HMAC-SHA256 Credential=KeyDemo/20210510/us-east-1/s3/aws4_request,SignedHeaders=host;x-amz-content-sha256;x-amz-date,Signature=1c74ee51a2a83272cb0389a69160287fee5b8564bc2fc650bdee7ad14c66ee94
x-amz-date: 20210510T093939Z
//RGW返回的内容
HTTP/1.1 200 OK
x-amz-request-id: tx00000000000000000001c-006098ff5b-3a5a5d-default
Content-Length: 127
Date: Mon, 10 May 2021 09:39:39 GMT
该次交互的目的是查询目标BUCKET是否存在。这通过S3接口“GET / BucketNameDemo/”实现。RGW收到请求后会进行用户身份的鉴别。身份鉴别通过后,查询目标bucket是否存在,当目标bucket存在时,RGW返回HTTP 200;当目标bucket不存在时,RGW会返回HTTP 404错误。
第一次交互对RGW而言也是一个操作请求。该次交互完成后,进行第二次交互,第二次交互过程如下。
//操作请求提交的内容
<?xml version="1.0" encoding="UTF-8"?><LocationConstraint xmlns="http://s3.amazonaws.com/doc/2006-03-01/"></LocationConstraint>
PUT /BucketNameDemo/hw HTTP/1.1
Host: 10.21.170.218:7480
Accept-Encoding: identity
Authorization: AWS4-HMAC-SHA256
Credential= KeyDemo/20210510/us-east-1/s3/aws4_request,
SignedHeaders=content-length;content-type;host;x-amz-content-sha256;x-amz-date;x-amz-meta-s3cmd-attrs;x-amz-storage-class,Signature=16a3b9cf0aa937353eb4a86d059f653f86f8a8ac7694393f001728bdccdcc578
content-length: 13
content-type: text/plain
x-amz-content-sha256: 03ba204e50d126e4674c005e04d82e84c21366780af1f43bd54a37816b6ab340
x-amz-date: 20210510T093939Z
x-amz-meta-s3cmd-attrs: atime:1620639558/ctime:1620639558/gid:0/gname:root/md5:8ddd8be4b179a529afa5f2ffae4b9858/mode:33188/mtime:1620639558/uid:0/uname:root
x-amz-storage-class: STANDARD
Hello World!
//RGW返回的内容
HTTP/1.1 200 OK
Content-Length: 0
ETag: "8ddd8be4b179a529afa5f2ffae4b9858"
Accept-Ranges: bytes
x-amz-request-id: tx00000000000000000001d-006098ff5b-3a5a5d-default
Date: Mon, 10 May 2021 09:39:39 GMT
该次交互会向RGW正式提出PUT上传对象的请求。这通过S3接口“PUT / BucketNameDemo/hw”实现。在该请求中,除内容数据“Hello World!”外,还会向RGW一并提交对象所属的存储桶、内容长度、对象类型等辅助信息。
接下来我们重点说明RGW在收到第二次交互,也就是收到PUT请求后的处理情况。
首先是处理请求的回调函数。请求处理回调函数在系统启动阶段设定。
# src\rgw\rgw_civetweb_frontend.cc
int RGWCivetWebFrontend::run()
{
auto& conf_map = conf->get_config_map();
set_conf_default(conf_map, "num_threads",
std::to_string(g_conf->rgw_thread_pool_size));//设定默认线程数
…
/* Initialize the CivetWeb right now. */
struct mg_callbacks cb;
memset((void *)&cb, 0, sizeof(cb));
cb.begin_request = civetweb_callback; //设定处理消息的回调函数
cb.log_message = rgw_civetweb_log_callback;
cb.log_access = rgw_civetweb_log_access_callback;
ctx = mg_start(&cb, this, options.data());
return ! ctx ? -EIO : 0;
} /* RGWCivetWebFrontend::run */
实例hw的PUT操作请求到达后,经过CIVEWEB层的队列调度、工作线程分配等环节后,工作线程会将PUT请求交给回调函数civetweb_callback()处理。回调函数会进一步调用主处理函数process_request()进行处理。
process_request()是RGW处理各类请求的主控函数,它控制着请求处理的全过程,包括处理请求的资源创建、调起和用后的回收等各环节。
# src\rgw\rgw_civetweb_frontend.cc
static int civetweb_callback(struct mg_connection* conn)
{
//req_info后续会被req_state引用
const struct mg_request_info* const req_info = mg_get_request_info(conn);
return static_cast<RGWCivetWebFrontend *>(req_info->user_data)->process(conn);
}
civetweb_callback()进一步调用如下函数:
int RGWCivetWebFrontend::process(struct mg_connection* const conn)
{…
int ret = process_request(env.store, env.rest, &req, env.uri_prefix,
*env.auth_registry, &client_io, env.olog, &http_ret);
…}
RGWCivetWebFrontend::process()又进一步调用主控函数process_request()。
int process_request(RGWRados* const store,…RGWRestfulIO* const client_io)
{…
RGWEnv& rgw_env = client_io->get_env();
RGWUserInfo userinfo;
struct req_state rstate(g_ceph_context, &rgw_env, &userinfo);
struct req_state *s = &rstate;
…
RGWOp* op = nullptr;
int init_error = 0;
bool should_log = false;
RGWRESTMgr *mgr;
RGWHandler_REST *handler = rest->get_handler(store, s,auth_registry,frontend_prefix,
client_io, &mgr, &init_error);
…
op = handler->get_op(store); //根据请求类型构建OP,对于实例将构建RGWPutObj_ObjStore_S3
…
ret = rgw_process_authenticated(handler, op, req, s); //进行认证及数据的实际写入
…
}
进入主控函数process_request()后,会先创建req_state结构,并把操作请求中的基础环境信息存入req_state.info成员变量内。基础环境信息包括请求的方法、host地址、请求的uri等信息,对于实例hw,请求的方法为PUT;此后再从请求uri中提取出目标rgw对象的名称“hw”,存入req_state.object内。req_state是处理本次写请求的关键数据结构,里面存放了所有必要的请求关联信息。CEPH对该结构的英文说明是“Store all the state necessary to complete and respond to an HTTP request”。
接下来调用rest->get_handler()函数查找处理该请求的handler。handler类别分为处理service请求的、处理bucket请求的、处理object请求的三类。get_handler()函数依据req_state.object成员变量(例子中变量值为“hw”)判断出实例为object类别的请求。
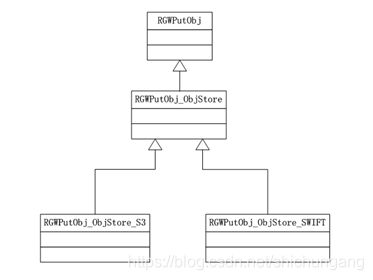
此后调用handler->get_op,依据req_state.info中的请求方法“PUT”,确定最终处理本次请求的类为RGWPutObj_ObjStore_S3。该类属于REST API处理层,它继承自RGWPutObj_ObjStore,RGWPutObj_ObjStore又继承自RGWPutObj类。通过这种继承关系,RGWPutObj_ObjStore_S3类可处理S3协议的特性部分,RGWPutObj类处理通用逻辑。与此类似,当使用SWIFT协议上传对象时其处理类RGWPutObj_ObjStore_SWIFT最终也继承自RGWPutObj类,同样REST层的SWIFT协议特性事项也由RGWPutObj_ObjStore_SWIFT类进行处理,并向下屏蔽协议特性,通用的逻辑处理仍由RGWPutObj类处理。相关类的继承关系如下图所示。
接下来是PUT写请求的实质性执行。RGW处理写请求涉及操作权限验证、对象名验证、bucket验证、quota配额验证等众多条件性处理,但处理写操作请求的本质是内容数据的处理、元数据的构建和数据最终的落盘处理,下面以内容数据、元数据的处理为主线,突出重点环节和关联关系,简明扼要地介绍hw实例的处理过程。
PUT请求处理过程除上述主控函数process_request()、关键数据结构req_state、RESTAPI处理类为RGWPutObj_ObjStore_S3以外,主要涉及整体上传处理器RGWPutObjProcessor_Atomic、操纵librados接口的RGWRados类及其相关子类。其中RESTAPI层的RGWPutObj_ObjStore_S3.execute()是另一个关键函数,配额验证、生成上传处理器、获取内容数据、驱动处理器将数据落盘等主要环节均在其直接驱动下进行。各主要相关部件的关联关系如下图所示。
 (1)获取对象BucketInfo信息,取得配额信息,并检验操作权限
(1)获取对象BucketInfo信息,取得配额信息,并检验操作权限
process_request()主控函数通过rgw_process_authenticated()调用RGWHandler::do_init_permissions()进行权限信息的初始化,这里面会调用RGW-RADOS层的适配接口RGWRados::_get_bucket_info()获取bucketinfo信息,并存放在req_state.bucket_info内。
int RGWRados::_get_bucket_info()
{
bucket_info_entry e;
string bucket_entry;
rgw_make_bucket_entry_name(tenant, bucket_name, bucket_entry);
if (binfo_cache->find(bucket_entry, &e)) { //从cache内获取
info = e.info;
return 0;
}
…
string oid;
get_bucket_meta_oid(entry_point.bucket, oid);
rgw_cache_entry_info cache_info;
ret = get_bucket_instance_from_oid(obj_ctx, oid, e.info, &e.mtime, &e.attrs,
&cache_info, refresh_version); //cache未命中时从RADOS内获取
e.info.ep_objv = ot.read_version;
info = e.info;
…
return 0;
}
上述程序会优先从缓存内查找bucket信息,如果缓存没有命中,则会从RADOS内读取。在RADOS内,bucketinfo信息存放在RADOS对象".bucket.meta.BucketNameDemo:43df4563-c362-4a71-a073-680aa03b811f.3824141.1"内,存储池pool为"default.rgw.meta",命名空间ns为"root"。读取该RADOS对象的LIBRADOS接口为librados::ObjectReadOperation::read()。
其后进行RGWPutObj_ObjStore_S3的初始化。在初始化时,RGWPutObj_ObjStore_S3会调用基类的init_quota()成员函数获取用户和bucket的配额,并存放在RGWPutObj_ObjStore_S3.bucket_quota内。
int RGWOp::init_quota()
{
…
if (s->bucket_info.quota.enabled) {
bucket_quota = s->bucket_info.quota;
} else if (uinfo->bucket_quota.enabled) {
bucket_quota = uinfo->bucket_quota;
} else {
bucket_quota = store->get_bucket_quota();
}…
return 0;
}
上述程序中的s为请求关联信息req_state,程序的主要思路是当请求关联信息req_state中的BucketInfo中的quota启用时,使用req_state的;当请求关联信息中的没有启用时,再判断用户信息uinfo内的quota信息,当上述条件都不成立时,再从系统配置里获取。综合使用这三种方式的目的是及时获取到最新的quota配置信息,避免遗漏。
上述以bucket的quota为例进行说明,其实在此过程中也会获取用户的quota信息,同样存放在RGWPutObj_ObjStore_S3内,以备后续判断写入数据是否超过quota限制时使用。
(2)进入RGWPutObj_ObjStore_S3.execute()主流程,验证配额限制,选择整体上传处理器RGWPutObjProcessor_Atomic,并将BucketInfo等信息传递给处理器
此后RGWPutObj_ObjStore_S3的基类execute()成员函数会将RGWPutObj_ObjStore_S3内的bucket_quota与操作请求中的对象内容长度等信息进行比较,以判断本次PUT操作是否满足配额quota的设定值。
void RGWPutObj::execute()
{…
op_ret = store->check_quota(s->bucket_owner.get_id(), s->bucket,
user_quota, bucket_quota, s->content_length);
…
processor = select_processor(*static_cast<RGWObjectCtx *>(s->obj_ctx), &multipart);
…}
store->check_quota()最终调用quota实现类RGWQuotaHandlerImpl的相关成员函数进行判别,判别操作分别从总对象数量、总对象内容长度两个维度进行比较,程序如下。此处store的类型为RGWRados,是RGW进程启动时已经初始化好的RGW-RADOS适配器,由此可见,其他层与RGW-RADOS适配层之间是按需穿插调用的。
int RGWQuotaHandlerImpl::check_quota(const char * const entity,const RGWQuotaInfo& quota,
const RGWStorageStats& stats,const uint64_t num_objs,const uint64_t size) {…
const auto& quota_applier = RGWQuotaInfoApplier::get_instance(quota);
if (quota_applier.is_num_objs_exceeded(entity, quota, stats, num_objs)) {
return -ERR_QUOTA_EXCEEDED;
}
if (quota_applier.is_size_exceeded(entity, quota, stats, size)) {
return -ERR_QUOTA_EXCEEDED;
}
…
return 0;
}
select_processor()函数根据req_state中的请求信息决定是整体上传还是分段上传,本例为整体上传,在select_processor()内将新建处理器RGWPutObjProcessor_Atomic,并将RGWPutObj_ObjStore_S3的BucketInfo等信息传递给处理器,处理器后续在生成manifest等对象属性信息时会用到BucketInfo信息。
(3)继续RGWPutObj_ObjStore_S3.execute()主流程,预处理RGWPutObjProcessor_Atomic处理器,形成manifest对象属性信息
void RGWPutObj::execute()
{…
processor = select_processor(*static_cast<RGWObjectCtx *>(s->obj_ctx), &multipart);
…
op_ret = processor->prepare(store, NULL);
…}
处理器RGWPutObjProcessor_Atomic负责封装并处理RGW对象的各类属性数据,并暂存RGW对象的内容数据,其中manifest属性描述了RGW对象的大小、首部RADOS对象的大小、对象命名前缀(用于对应RADOS对象的命名和检索)等关键布局信息。manifest属性信息由RGWPutObj_ObjStore_S3调用RGWPutObjProcessor_Atomic::prepare()完成组装。
int RGWPutObjProcessor_Atomic::prepare(RGWRados *store, string *oid_rand)
{…
manifest.set_trivial_rule(max_chunk_size, store->ctx()->_conf->rgw_obj_stripe_size);
r = manifest_gen.create_begin(store->ctx(), &manifest, bucket_info.placement_rule, head_obj.bucket, head_obj);
…
}
manifest_gen.create_begin()根据处理器持有的bucketinfo信息,结合RGW对象名称等信息,依据整体上传对象的逻辑规则,形成manifest属性键值,并存放在RGWPutObjProcessor_Atomic.manifest内。hw实例为新上传对象,因此在构建manifest时将形成对象命名前缀prefix。prefix为长度32的字符串,经由gen_rand_alphanumeric()随机产生。此后将使用该prefix值作为RGW对象的首部RADOS对象名字的组成部分,prefix值也在拼装RADOS对象名称、进而定位RGW对象数据位置查找对应RADOS对象时经常被用到。构建manifest主要结构成员的程序如下。
int RGWObjManifest::generator::create_begin(CephContext *cct, RGWObjManifest *_m, const string& placement_rule, rgw_bucket& _b, rgw_obj& _obj)
{…
if (manifest->get_prefix().empty()) {
char buf[33];
gen_rand_alphanumeric(cct, buf, sizeof(buf) - 1);
string oid_prefix = ".";
oid_prefix.append(buf);
oid_prefix.append("_");
manifest->set_prefix(oid_prefix);}
…}
(4)继续RGWPutObj_ObjStore_S3.execute()主流程,获取内容数据“Hello world!”
接下来继续执行RGWPutObj::execute(),调用get_data()到civetweb内读取内容数据“Hello world!”。
void RGWPutObj::execute()
{…
do {
bufferlist data;
if (fst > lst)
break;
if (copy_source.empty()) {
len = get_data(data);//存放在新申请的bufferlist内
if (need_calc_md5) {
hash.Update((const byte *)data.c_str(), data.length());
}
op_ret = put_data_and_throttle(filter, data, ofs, need_to_wait);
ofs += len;
} while (len > 0);
…}
其中get_data(data)最终是通过req_state的成员(rgw::io::BasicClient)*cio到前端WEB服务器civetweb内获取内容数据。在一般上传对象的操作请求中,内容数据通常比较大,相比在形成操作请求时就读取内容数据,在此处才到Civetweb内读取内容数据有利于减少内容数据在内存中的拷贝次数,因为后续将马上尝试把数据写入RADOS,这样设计有利于提高内存使用效率,在程序设计上也更为合理;同时在前面的配额检查、权限验证等环节也不需要使用内容数据。通过req_state获取内容数据相关程序如下。
static inline rgw::io::RestfulClient* RESTFUL_IO(struct req_state* s) {…
return static_cast<rgw::io::RestfulClient*>(s->cio);
}
int recv_body(struct req_state* const s,char* const buf,const size_t max)
{…
return RESTFUL_IO(s)->recv_body(buf, max);
…}
读取内容数据后马上调用hash.Update()进行内容数据hash值的计算,这里hash算法采用md5。RGW对象所有内容数据的hash值就是RGW对象“user.rgw.etag”属性的属性值,该属性可用来校验对象数据的完整性。此处形成的属性信息将暂存在RGWPutObj_ObjStore_S3. Attrs内,待后续再将其写入RADOS。
计算hash值后,会立即尝试进行内容数据的写入。这通过put_data_and_throttle()调用RGWPutObjProcessor_Atomic处理器的handle_data()成员函数实现。对于内容数据大于4M的RGW对象,大于4M的那部分数据写入采用异步方式,RGWPutObjProcessor_Atomic在handle_data()内将操纵RGWRADOS通过LIBRADOS接口直接提交异步写入RADOS的请求;对于小于等于4M的那部分数据,或者对于hw实例,因为其内容数据只有12个字节,数据量较少,RGW后续会将这部分内容数据与元数据一起采用同步写入的方式提交给RADOS,在这种情况下会将内容数据暂时存放在RGWPutObjProcessor_Atomic处理器内。
int RGWPutObjProcessor_Atomic::handle_data(…)
{
uint64_t max_write_size = MIN(max_chunk_size, (uint64_t)next_part_ofs - data_ofs);
pending_data_bl.claim_append(bl); //将数据暂存在RGWPutObjProcessor_Atomic内
if (pending_data_bl.length() < max_write_size) {
*again = false;
return 0;}
…
ret = write_data(bl, write_ofs, phandle, pobj, exclusive); //提交数据异步写入请求
…}
(5)继续RGWPutObj_ObjStore_S3.execute()主流程,执行RGWPutObjProcessor_Atomic的complete()成员函数,将内容数据和元数据一起提交给RADOS落盘,并更新bucket索引数据。
按照RGW的设计,RGWPutObjProcessor_Atomic.complete()属于整个过程的后处理环节,此时RGW对象的元数据均以形成,在本环节主要是向RADOS提交元数据和少部分内容数据。因为本例的内容数据与元数据一起提交,所以大部分落地数据的处理均在本环节。RGWPutObjProcessor_Atomic::complete()会调用do_complete()将元数据整理进入RGWRados的子类RGWRados::Object::Write。相关主要程序如下。
int RGWPutObjProcessor_Atomic::do_complete(…)
{
RGWRados::Object op_target(store, bucket_info, obj_ctx, head_obj);
op_target.set_versioning_disabled(!versioned_object);
RGWRados::Object::Write obj_op(&op_target);
obj_op.meta.data = &first_chunk; //内容数据“Hello world!”
obj_op.meta.manifest = &manifest;//“user.rgw.manifest”属性
…
r = obj_op.write_meta(obj_len, accounted_size, attrs);//attrs内有“user.rgw.etag”属性
…}
obj_op.write_meta()将进入RGWRADOS层执行,在该层中将调用LIBRADOS接口,执行提交。此处采用librados的同步接口。这种接口的完整操作一般分为配置集群句柄、创建I/O会话、整理I/O操作、提交I/O操作和资源后处理等步骤。其中集群句柄已经在RGW启动与初始化时配置好,存放在store(类型为RGWRados)的成员变量rados(类型为std::vectorlibrados::Rados)内;I/O会话与具体的RADOS POOL相关联,在进行具体I/O操作时创建;I/O操作整理以librados的ObjectWriteOperation类为目标;提交I/O则通过I/O会话的ioctx.operate()实现。具体到本例,obj_op.write_meta()会进一步调用RGWRados::Object::Write::_do_write_meta(),在其内经由get_obj_head_ref()最终调用如下程序创建I/O会话。
int rgw_init_ioctx(librados::Rados *rados, const rgw_pool& pool, IoCtx& ioctx, bool create)
{
int r = rados->ioctx_create(pool.name.c_str(), ioctx);
…
return 0;
}
RGWRados::Object::Write::_do_write_meta()内关键步骤的程序代码摘录如下。
int RGWRados::Object::Write::_do_write_meta(… map<string, bufferlist>& attrs,void *_index_op)
{…
RGWRados::Bucket::UpdateIndex *index_op = static_cast<…>(_index_op);
ObjectWriteOperation op; //librados的写操作类型…
rgw_rados_ref ref;
r = store->get_obj_head_ref(target->get_bucket_info(), obj, &ref);//在其内创建I/O会话
…
if (meta.data) {
op.write_full(*meta.data);//整理待写入的内容数据
}…
if (meta.manifest) {…
bufferlist bl;
::encode(*meta.manifest, bl);
op.setxattr(RGW_ATTR_MANIFEST, bl);}// 整理manifest属性数据
for (iter = attrs.begin(); iter != attrs.end(); ++iter) {
const string& name = iter->first;
bufferlist& bl = iter->second;
op.setxattr(name.c_str(), bl);}//整理待写入的其他属性数据,包括“user.rgw.etag”属性
…
r = ref.ioctx.operate(ref.oid, &op);//向librados提交I/O。
…
r = index_op->complete(poolid, epoch, size,…);//最后更新索引
…}
此处将多项操作整合成为一个LIBRADOS I/O请求,后端RADOS会以一个原子事务的方式进行数据落盘,这个事务要么完整地得到执行,要么完整地不执行,这样有利于保证各项操作的执行完整性,保证数据的一致性。
在完成内容数据与属性数据的同步写操作后,RGWRados::Object::Write::_do_write_meta()还进行了索引数据的更新。更新索引数据采用了异步I/O操作,并使用到了CLS机制。因为索引数据在另一个POOL内,因此会再行创建一个I/O会话,提交远端OSD执行CLS方法的请求,并以异步方式等待远端执行结果。
对于异步I/O操作,因为提交I/O请求和确认I/O结果在同一线程内,如果RGW连续地提交I/O请求,就会导致待确认的I/O结果数量增多,I/O操作状态不能及时评估;如果每提交一个I/O请求后立即确认I/O结果,就不能有效发挥异步I/O的速度优速。所以RGW需要采取一种机制用来维持提交I/O请求的速度和待确认的I/O结果的数量两者之间的平衡。Rgw默认使用throttle方式进行控制。其控制方式为以“待确认的数据长度”作为平衡阈值,当“待确认的数据长度”超过限定值后,则先确认队列中的I/O请求,因为两者在同一线程内执行,此时新的I/O请求则会暂时被推迟提交;当“待确认的数据长度”没有超过限定值时,则直接提交新的IO。其关键实现函数详见RGWPutObjProcessor_Aio::throttle_data()。
(6)process_request()调用client_io->complete_request(),通告执行结果
process_request()在后处理阶段会调用client_io->complete_request()通告执行结果。RGWRestfullIO是与前端进行IO操作的接口,与前述通过req_state读取内容数据的req_state.cio(类型为rgw::io::BasicClient)是同一个结构。此后process_request()还将进行资源回收等收尾工作。
七、RGW的双活机制
Rgw支持跨CEPH集群的多中心同步和集群内多节点多活。这些特性提高了RGW的可靠性,可有效的分担用户负载,有时也用以数据备份。
跨集群的多中心同步在程序实现上需要多个结构支持,并用到了线程与协程机制。对于每个需要同步的RGW节点,均需要一对一的线程进行服务,该线程专门负责该节点的同步。因为多中心同步涉及众多bucket以及大量元数据和内容数据,RGW在同步线程内又将同步任务切分成多个分片,并启用协程机制负责每个分片的数据同步。协程与线程相比,协程的优势是在大量并发同步操作的情况下,不同协程的切换在线程内进行,对操作系统透明,这样协程的切换成本大大降低,非常适合这种需要进行大量数据并发同步的场景。
对于集群内的多节点多活,因为CEPH自身就是分布式存储,在集群内的不同节点上能看到同一份数据,所以多节点多活是RGW固有特性,不需要太多的配置就能实现。
下面就多节点多活的缓存设计和Watch-Notify机制在其中的应用进行详细分析。
(1)集群内多节点多活
在同一CEPH集群内,可以在多个节点上分别启动RGW进程实例,各RGW共同对外提供服务。由于各RGW在同一集群内,可以看到同一份RADOS提供的数据,因此可以实现集群内多节点多活的功能。同一集群内RGW多节点多活示意图如下。
 图中,RGW1与RGW2和RGW3可对外提供同样的对象服务,但各RGW节点对外提供服务的网络端口地址不相同,在实际应用时,可在RGW前面部署负载均衡设备,实现各节点负载均衡分担,优化响应速度,也能提高RGW服务的可靠性。
图中,RGW1与RGW2和RGW3可对外提供同样的对象服务,但各RGW节点对外提供服务的网络端口地址不相同,在实际应用时,可在RGW前面部署负载均衡设备,实现各节点负载均衡分担,优化响应速度,也能提高RGW服务的可靠性。
为了提高单个RGW的I/O性能,系统设计了RGW缓存,并将RGW的BUCKET、USER等元数据信息缓存在其内。RGW缓存功能默认开启,并受rgw_cache_enabled配置参数控制;缓存数据有效期默认900秒,并受配置参数rgw_cache_expiry_interval控制;缓存条目默认最大为10000,并受配置参数rgw_cache_lru_size控制。
在RGW多节点多活的情况下,需要解决RGW缓存面临的多节点缓存数据一致性问题,尤其是在缓存数据被修改时,需要及时通知其他RGW节点及时同步修改或废弃相应的缓存数据,避免因为缓存数据不一致造成对外多节点服务的元数据访问异常。在缓存数据同步方面,RGW使用了RADOS的Watch-Notify机制。
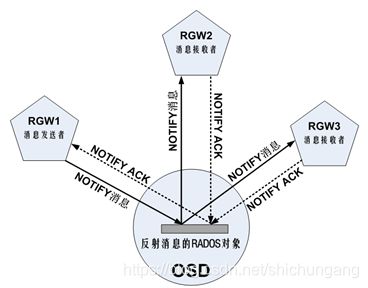
(2)Watch-Notify机制与RGW缓存
Watch-Notify采用的是一种消息反射方法,通过LIBRADOS接口为上层应用提供不同RADOS客户端之间的相互通信功能。RGW就是一种RADOS客户端。其基本用法是先注册watch。Watch注册时需要指定一个RADOS对象,需要获取消息的RGW节点都执行watch操作,并关联到同一个RADOS对象,这个RADOS对象起到了反射消息的作用。当任一RGW节点有缓存数据修改时,由该RGW节点调用notify接口发送消息至该RADOS对象,RADOS对象再将消息转发给所有注册了watch的其他RGW节点,这些RGW节点再修改自己的缓存数据,并返回修改结果,最终确保分布式情形下的缓存数据的一致性。
 RGW节点注册watch是在RGW启动阶段。在RGW启动时RGWRados::initialize()成员函数会调用RGWRados::init_watch()成员函数注册watch。
RGW节点注册watch是在RGW启动阶段。在RGW启动时RGWRados::initialize()成员函数会调用RGWRados::init_watch()成员函数注册watch。
int RGWRados::init_watch()
{…
int r = rgw_init_ioctx(&rados[0], get_zone_params().control_pool, control_pool_ctx, true);
num_watchers = cct->_conf->rgw_num_control_oids; //反射消息用的RADOS对象数,默认为8
notify_oids = new string[num_watchers];
watchers = new RGWWatcher *[num_watchers];
for (int i=0; i < num_watchers; i++) {
string& notify_oid = notify_oids[i];
notify_oid = notify_oid_prefix;
if (!compat_oid) {
char buf[16];
snprintf(buf, sizeof(buf), ".%d", i);
notify_oid.append(buf); } //组合8个RADOS对象名称。名称例如notify.1
r = control_pool_ctx.create(notify_oid, false);
RGWWatcher *watcher = new RGWWatcher(this, i, notify_oid); //其内有设定好的回调函数
watchers[i] = watcher;
r = watcher->register_watch(); //注册watch,其内会调用librados::IoCtx::watch2()
}…
}
register_watch()成员函数最终调用LIBRADOS的接口函数librados::IoCtx::watch2()实现注册。RGW创建了专门用于反射消息的RADOS对象,位于POOL {bucketname}.rgw.control中,默认8个,名称为“notify.0”、“notify.1”、…“notify.7”,这些RADOS对象专门负责反射消息。注册后,注册信息会存放在这些RADOS对象的XATTR属性中,并进行持久化存储,这样OSD设备遇到重启等情况时仍能恢复注册的watch信息。
上述程序中,类RGWWatcher继承自LIBRADOS的类librados::WatchCtx2,其成员函数handle_notify()是对父类成员函数的重写,是响应并处理notify消息的回调函数。
RGW在删除元数据对象(对应函数 RGWCache::delete_system_obj())、上传元数据对象(对应函数RGWCache::put_system_obj_impl()),设置元数据对象属性(对应函数RGWCache::system_obj_set_attrs())、上传元数据对象内容数据(对应函数RGWCache::put_system_obj_data())时均会触发watch-notify机制,发送notify消息。以删除元数据对象为例说明。
int RGWCache<T>::delete_system_obj(rgw_raw_obj& obj, RGWObjVersionTracker *objv_tracker)
{
rgw_pool pool;
string oid;
normalize_pool_and_obj(obj.pool, obj.oid, pool, oid);
string name = normal_name(obj);
cache.remove(name);
ObjectCacheInfo info;
distribute_cache(name, obj, info, REMOVE_OBJ); //先发送notify消息,其内调用librados::IoCtx::notify2()
return T::delete_system_obj(obj, objv_tracker); //然后再进行实际数据的删除
}
在删除元数据时,先通过distribute_cache()调用librados的接口函数librados::IoCtx::notify2()发送消息,等待其他节点执行在watch注册阶段设定的回调函数RGWCache::watch_cb(),从缓存中移除对应的数据。在此期间,接口函数librados::IoCtx::notify2()将使线程处于阻塞状态,直至收到其他节点确认缓存数据已移除的消息,然后再继续执行T::delete_system_obj()删除位于RADOS内的实际数据,确保各RGW节点的缓冲数据一致性。从中也可看出,缓存数据的修改需要在各RGW节点间进行同步修改,中间要基于Watch-Notify机制进行多次网络通信和函数回调处理,这在一定程度上降低了I/O速度,因此RGW缓存适合存放经常读、较少修改的元数据信息。
其他节点移除缓存数据的关键函数为RGWCache::watch_cb(),此函数被之前注册的回调函数RGWWatcher::handle_notify ()调起。
void handle_notify(…) override {…
rados->watch_cb(notify_id, cookie, notifier_id, bl); //执行缓存数据删除操作
bufferlist reply_bl; // empty reply payload
rados->control_pool_ctx.notify_ack(oid, notify_id, cookie, reply_bl); //反馈执行结果
}
int RGWCache<T>::watch_cb(uint64_t notify_id,…)
{
RGWCacheNotifyInfo info;
…
switch (info.op) {
case UPDATE_OBJ:
cache.put(name, info.obj_info, NULL);
break;
case REMOVE_OBJ:
cache.remove(name); //移除缓存数据
break;… }
return 0;
}
此处RGW属于Watch-Notify机制的应用者,Watch-Notify机制的实现主体在OSD内。为保证Watch-Notify机制的有效运行,各参与者与OSD节点间还有心跳机制,这些实现细节将在OSD章节中再行介绍。
八、RGW版本管理机制与CLS机制
(1)RGW对象多版本管理
Version版本管理是S3协议提供的功能,让用户可以以同一个文件名,上传多个版本。S3协议服务端会为每个版本赋予一个版本标识,协议客户端可凭此标识访问文件的特定版本。这个功能在保存用户文件历史状态等场景下会用到。
RGW是S3协议的实现者,也实现了版本管理功能。一个用户文件对应一个RGW对象,针对文件的不同版本RGW也会创建不同的RGW对象,这些对象之间又会基于对象名和版本标识建立联系。
版本管理功能针对bucket设定。在bucket启用version功能后,对于用户上传的文件RGW会自动生成版本标识,并将版本标识反馈给S3协议客户端;同一文件可多次上传,RGW会为每此上传的对象分配不同的版本标识。版本标识为一个32字节的随机值。
对象版本以上传时间为序排列,最近上传的对象为当前版本。下载时,如果没有指定版本标识,则默认下载当前版本;指定版本标识时,则下载与版本标识对应的版本对象。
删除时,因为启用了version功能,所以需要指定待删除的对象版本;如果没有指定,则仅会记录一个删除标记DELETE_MARKER,不会删除任何版本的对象,当然也不会删除当前版本对象。
当启用version功能后,RGW对象在RADOS系统中的组织方式有所变化,如下图所示。

为了适应多版本的需要,系统在普通RGW对象的组织方式基础上进行了改动,将原来的首部对象改变为用来专门指示多版本的情况,此时该RADOS对象的命名方式保持不变,但内容数据为空,XATTR属性变更为user.rgw.idtag、user.rgw.olh.idtag、user.rgw.olh.info、user.rgw.olh.ver等属性,其中属性user.rgw.olh.info中存放了指示当前版本的instance,也就是版本标识。使用版本标识可直接找到对应的版本对象。
版本首部对象为RGW对象的具体版本的首部RADOS对象,在图中称为“版本首部对象”,其命名规则为{bucketid}_ :{instance}{对象名字},其中{instance}便是版本标识,为32的随机值,由RGW网关随机生成。根据RGW对象大小,版本首部对象也有相应的分片对象或multipart对象,这些RADOS对象的名字中也加入了版本instance。除名字构成有不同外,其余数据组织方式与未启用version功能时相同。
RGW对象的每一个版本都在bucket索引中存在多个对应的OMAP属性,也就是多个检索项,一个检索项对应version对象自身,OMAP属性的KEY名为{RGW对象名},其他的对应于具体的RGW版本对象,OMAP属性的KEY名为{RGW对象名}+{对象版本标识}。以hw对象为例,其在索引对象中的OMAP属性KEY如下。
hw //对应于version对象
hwv913ijKByOf7patpp4XMTKcjB7obd3JNMSm9 //对应于具体的RGW版本对象
为区分对象的版本状态,系统在索引项OMAP属性值(对应数据结构rgw_bucket_dir_entry)中设计了flag标识位,标识位的取值及含义定义如下:
#define RGW_BUCKET_DIRENT_FLAG_VER 0x1 //对象启用了版本功能
#define RGW_BUCKET_DIRENT_FLAG_CURRENT 0x2 //对象的当前版本
#define RGW_BUCKET_DIRENT_FLAG_DELETE_MARKER 0x4 //对象版本的删除标记
#define RGW_BUCKET_DIRENT_FLAG_VER_MARKER 0x8 //版本对象的预留标志位
当该标志位为0时,表示对象没有启用版本功能。基于这个标志位,RGW可快速检索出bucket内的RGW对象各个版本的状态。在版本检索功能的实现上,RGW使用到了CEPH的cls机制。
(2)Cls扩展模块
Cls是Ceph的一种模块扩展机制。这种扩展机制可从客户端跨越到RADOS内部的OSD,在OSD内部执行客户端规定的数据处理逻辑。在OSD内执行数据处理逻辑有利于减少数据在网络中不必要的移动,充分利用远端OSD的资源,简化功能接口设计,为客户端提供可自定义的功能特性。这些特性对丰富上层应用的功能特性非常有利,因此对分布式统一存储系统而言是十分必要的。Cls的技术本质是OSD加载并调用相应的动态链接库来完成客户端请求的数据处理逻辑。
另外cls支持用C++和Lua Script两种语言实现。Lua是一种简洁、轻量、可扩展的脚本语言,它由标准C编写而成,运行效率较高;为了支持Lua,在OSD内嵌入了LuaJIT VM,并利用脚本语言动态解释执行的特性,实现了一种在客户端用Lua语言编写后端处理逻辑、并将处理逻辑作为参数经由网络发送给OSD并在OSD内动态解释执行的新方式。与传统C++方式相比,这种方式不需要再编译后端用的动态链接库,在应用上更为灵活,详见《Ceph Dynamic Object Interfaces with Lua》【补充网址】。但是在实际应用中大多数客户端仍以C++语言实现自己的CLS模块,本章仍以C++为例进行说明。
Cls使用的基本流程是客户端调用librados的exec()接口,如librados::ObjectOperation::exec(),并在接口中指明后端处理逻辑的动态库名称和其内方法的名称,封装相关参数,形成类型为CEPH_OSD_OP_CALL的操作请求;然后再将操作请求发送给OSD,OSD根据操作请求类型在OSD本地调用动态链接库中相对应的方法进行处理。
下面结合RGW对象的版本检索功能对CLS的实际使用场景和使用效果进行说明。
(3)Cls扩展模块与版本对象检索功能
对象检索功能是RGW最为常用的功能,检索响应速度直接决定了用户体验。由上文可知,对象检索信息存放在对应RADOS对象的OMAP属性内,如果对象太多时,还会进行分片处理,就是将检索信息分散存储在多个RADOS对象内。在未启用版本功能时,对象检索很简单,直接列出对应RADOS对象的OMAP属性值就行。在启用版本功能后,一个RGW对象有多个版本,在RADOS对象内就有多个OMAP属性值,而检索功能默认只需列出RGW对象的当前版本,这时就需要对RADOS对象的OMAP属性值进行过滤。针对这些需求,RGW采用CLS模块处理。
Cls模块的特点是其后端处理逻辑可以在OSD一侧运行,这样可在OSD内依据rgw_bucket_dir_entry.flag过滤掉不需要的数据,并有针对性地向RGW传递其所需要的数据。这部分功能的主体实现在名字为rgw的cls模块内,关键函数为rgw_bucket_list()。这种基于CLS的检索功能实现减少了数据在网络中不必要的移动,充分利用了远端OSD的资源,最大程度地节约了传输带宽,也使得功能接口设计更为合理。
实现检索功能的动态库文件为“libcls_rgw.so”,在OSD启动阶段进行注册,注册的模块名为rgw,注册的实现检索功能的库的方法为RGW_BUCKET_LIST,并由rgw_bucket_list()函数实现该方法。
执行命令“s3cmd la”,或者使用S3接口ListObjectsRequest列出对象时,在RGW一侧,RGW将执行函数issue_bucket_list_op(),在该函数中会向OSD提交远程执行cls模块rgw中的RGW_BUCKET_LIST方法的请求。
static bool issue_bucket_list_op() {
bufferlist in;
struct rgw_cls_list_op call;
call.start_obj = start_obj;
call.filter_prefix = filter_prefix;
call.num_entries = num_entries;
call.list_versions = list_versions;
::encode(call, in); //在in bufferlist中封装rgw_cls_list_op结构数据
librados::ObjectReadOperation op;
op.exec(RGW_CLASS, RGW_BUCKET_LIST,…); //提交远程执行请求。
return manager->aio_operate(io_ctx, oid, &op);
}
在OSD一侧,OSD收到请求后,调用cls模块rgw中的处理函数rgw_bucket_list()处理请求。Cls处理方法的参数是一致的,其中in参数为客户端一侧传入的参数数据,out为输出数据,最终反馈给客户端,in和out的数据格式由应用定义。
int rgw_bucket_list(cls_method_context_t hctx, bufferlist *in, bufferlist *out)
{
bufferlist::iterator iter = in->begin();
struct rgw_cls_list_op op;
try {
::decode(op, iter);
}…
struct rgw_cls_list_ret ret;
struct rgw_bucket_dir& new_dir = ret.dir;
int rc = read_bucket_header(hctx, &new_dir.header);
…
do {
//读取全部的索引项
rc = get_obj_vals(hctx, start_key, op.filter_prefix, left_to_read, &keys, &more);
for (kiter = keys.begin(); kiter != keys.end(); ++kiter) {
struct rgw_bucket_dir_entry entry;
::decode(entry, eiter);
…
//过滤掉非当前版本的索引项
if (!op.list_versions && (!entry.is_visible() || op.start_obj.name == key.name)) {
continue;
}
if (m.size() < op.num_entries) {
m[kiter->first] = entry;
}
left_to_read--;
}
} while (left_to_read > 0 && !done);
ret.is_truncated = more && !done;
::encode(ret, *out);
return 0;
}
在过滤非当前版本的索引项时,使用了结构rgw_bucket_dir_entry中的is_visible(),在其中最终依据rgw_bucket_dir_entry.flags值进行判断。相关代码如下。
struct rgw_bucket_dir_entry {
cls_rgw_obj_key key;
rgw_bucket_entry_ver ver;
bool exists;
uint64_t index_ver;
uint16_t flags; //标志位,表示是否为当前版本或其他状态
uint64_t versioned_epoch;
…
bool is_visible() {
return is_current() && !is_delete_marker();
}
bool is_current() {
int test_flags = RGW_BUCKET_DIRENT_FLAG_VER | RGW_BUCKET_DIRENT_FLAG_CURRENT;
return (flags & RGW_BUCKET_DIRENT_FLAG_VER) == 0 ||
(flags & test_flags) == test_flags;
}
bool is_delete_marker() { return (flags & RGW_BUCKET_DIRENT_FLAG_DELETE_MARKER) != 0; }
}
由上可知,在检索对象时,系统通过cls机制OSD会依据rgw_bucket_dir_entry.flags标志位过滤掉不需要的索引项,仅将必要的数据经由网络反馈给客户端RGW,有效降低了非必要的网络数据传输。Cls机制在RGW中有多处应用。
九、结语
本文从RGW的基本原理出发,着重从整体上描述框架结构,突出关键结构之间的关联关系,从基础代码分析其关键环节的实现细节,以达到清晰说明RGW模块“骨架”的阐述效果。文中的代码节选自CEPH 12.2版本,不同版本间代码实现有差异,但基本原理是一致的。欢迎读者评论,CEPH系统的其余部分将在后续章节分模块逐步详细介绍。