T4周:猴痘病识别
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊|接辅导、项目定制
Z. 心得感受+知识点补充
1. ModelCheckpoint 讲解
- 函数原型:
tf.keras.callbacks.ModelCheckpoint(
filepath, monitor='val_loss', verbose=0, save_best_only=False,
save_weights_only=False, mode='auto', save_freq='epoch',
options=None, **kwargs
)
filepath: 字符串,保存模型的路径
monitor: 需要监视的值
verbose: 信息展示模式,0或者1
save_best_only: 当设置为True时,监测值有改进时才会保存当前的模型
mode: ‘auto’, ‘min’, 'max’之一,当save_best_only = True时决定性能最佳模型的判准准则
save_weights_only: 若设置为True,则只保存模型权重,否则将保存整个模型
period: CheckPoint之间的间隔的epoch数
一、前期工作
1. 设置GPU
from tensorflow import keras
from tensorflow.keras import layers, models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
gpus = tf.config.list_physical_devices('GPU')
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], 'GPU')
gpus
2. 导入数据
data_dir = './data/'
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:", image_count)
图片总数为: 2142
3. 查看数据
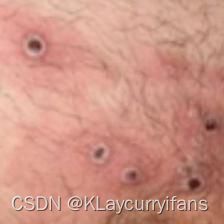
Monkeypox = list(data_dir.glob('Monkeypox/*.jpg'))
PIL.Image.open(str(Monkeypox[0]))
二、数据预处理
1. 加载数据
batch_size = 32
img_height = 224
img_width = 224
#使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset='training',
seed = 123,
image_size=(img_height, img_width),
batch_size=batch_size
)
Found 2142 files belonging to 2 classes.
Using 1714 files for training.
#使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset='validation',
seed = 123,
image_size=(img_height, img_width),
batch_size=batch_size
)
Found 2142 files belonging to 2 classes.
Using 428 files for validation.
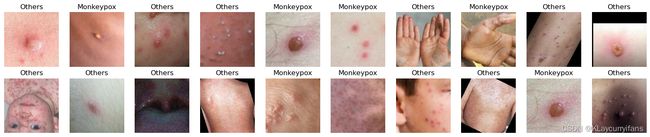
2. 可视化数据
#可以通过class_names输出数据集的标签,标签将按字母顺序对应于目录名称
class_names = train_ds.class_names
print(class_names)
[‘Monkeypox’, ‘Others’]
plt.figure(figsize=(20,10))
for images, labels in train_ds.take(1):
for i in range(20):
# 将整个figure分成5行10列,绘制第i+1个子图
ax = plt.subplot(5, 10, i+1)
#图像展示,cmap为颜色图谱,"plt.cm.binary为matplotlib.cm中的色表"
plt.imshow(images[i].numpy().astype('uint8'))
#设置x轴标签显示为图片对应的数字
plt.title(class_names[labels[i]])
plt.axis('off')
3. 再次检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape) #Image_batch是形状的张量(32, 180, 180, 3)这是一批形状180*180*3的32张图片(最后一维指的是彩色通道RGB)
print(labels_batch.shape) #Label_batch是形状(32, )的张量,这些标签对应32张图片
break
(32, 224, 224, 3)
(32,)
4. 配置数据集
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size = AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三、构建CNN网络模型
#创建并设置卷积神经网络
num_classes = 2
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
#设置二维卷积层1, 设置16个3*3卷积核,激活函数设置为ReLU,input_shape参数将图层的输入形状设置为(32, 32, 3)
layers.Conv2D(16, (3, 3), activation='relu', input_shape = (img_height, img_width, 3)),
#池化层1, 2*2采样
layers.AveragePooling2D((2, 2)),
#设置二维卷积层2,32个3*3卷积核
layers.Conv2D(32, (3, 3), activation='relu'),
#池化层2, 2*2采样
layers.AveragePooling2D((2, 2)),
layers.Dropout(0.3),
layers.Conv2D(64, (3, 3), activation = 'relu'), #卷积层3,卷积核3*3
layers.Dropout(0.3), #让神经元以一定的概率停止工作,防止过拟合,提高模型的泛化能力
layers.Flatten(), #Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), #全连接层,特征进一步提取,128位输出空间的维数
layers.Dense(num_classes) #输出层,输出预期结果
])
model.summary()
Model: “sequential”
Layer (type) Output Shape Param #
rescaling_1 (Rescaling) (None, 224, 224, 3) 0
conv2d_2 (Conv2D) (None, 222, 222, 16) 448
average_pooling2d_2 (Averag (None, 111, 111, 16) 0
ePooling2D)
conv2d_3 (Conv2D) (None, 109, 109, 32) 4640
average_pooling2d_3 (Averag (None, 54, 54, 32) 0
ePooling2D)
dropout (Dropout) (None, 54, 54, 32) 0
conv2d_4 (Conv2D) (None, 52, 52, 64) 18496
dropout_1 (Dropout) (None, 52, 52, 64) 0
flatten (Flatten) (None, 173056) 0
dense (Dense) (None, 128) 22151296
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 22,175,138
Trainable params: 22,175,138
Non-trainable params: 0
四、编译模型
#设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(
#设置Adam优化器
optimizer = 'adam',
#设置损失函数为交叉熵损失交叉熵函数
#from_logits为True时,会将y_pred转换为概率(用softmax),否则不进行转换,通常True结果更稳定
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
五、训练模型
from tensorflow.keras.callbacks import ModelCheckpoint
epochs = 50
checkpointer = ModelCheckpoint(
"best_model.h5",
monitor = 'val_accuracy',
verbose = 1,
save_best_only = True,
save_weights_only = True
)
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks = [checkpointer]
)
from tensorflow.keras.callbacks import ModelCheckpoint
epochs = 50
checkpointer = ModelCheckpoint(
"best_model.h5",
monitor = 'val_accuracy',
verbose = 1,
save_best_only = True,
save_weights_only = True
)
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks = [checkpointer]
)
1
from tensorflow.keras.callbacks import ModelCheckpoint
2
3
epochs = 50
4
5
checkpointer = ModelCheckpoint(
6
"best_model.h5",
7
monitor = 'val_accuracy',
8
verbose = 1,
9
save_best_only = True,
10
save_weights_only = True
11
)
12
13
history = model.fit(
14
train_ds,
15
validation_data=val_ds,
16
epochs=epochs,
17
callbacks = [checkpointer]
18
)
Epoch 1/50
54/54 [==============================] - ETA: 0s - loss: 1.7158 - accuracy: 0.5461
Epoch 1: val_accuracy improved from -inf to 0.53505, saving model to best_model.h5
54/54 [==============================] - 30s 526ms/step - loss: 1.7158 - accuracy: 0.5461 - val_loss: 0.6819 - val_accuracy: 0.5350
Epoch 2/50
54/54 [==============================] - ETA: 0s - loss: 0.6775 - accuracy: 0.5525
Epoch 2: val_accuracy improved from 0.53505 to 0.54673, saving model to best_model.h5
54/54 [==============================] - 27s 496ms/step - loss: 0.6775 - accuracy: 0.5525 - val_loss: 0.6736 - val_accuracy: 0.5467
Epoch 3/50
54/54 [==============================] - ETA: 0s - loss: 0.6639 - accuracy: 0.5858
Epoch 3: val_accuracy improved from 0.54673 to 0.61215, saving model to best_model.h5
54/54 [==============================] - 27s 498ms/step - loss: 0.6639 - accuracy: 0.5858 - val_loss: 0.6638 - val_accuracy: 0.6121
Epoch 4/50
54/54 [==============================] - ETA: 0s - loss: 0.6150 - accuracy: 0.6558
Epoch 4: val_accuracy improved from 0.61215 to 0.72897, saving model to best_model.h5
54/54 [==============================] - 28s 513ms/step - loss: 0.6150 - accuracy: 0.6558 - val_loss: 0.5479 - val_accuracy: 0.7290
Epoch 5/50
54/54 [==============================] - ETA: 0s - loss: 0.5646 - accuracy: 0.7100
Epoch 5: val_accuracy improved from 0.72897 to 0.73364, saving model to best_model.h5
54/54 [==============================] - 27s 496ms/step - loss: 0.5646 - accuracy: 0.7100 - val_loss: 0.5605 - val_accuracy: 0.7336
Epoch 6/50
54/54 [==============================] - ETA: 0s - loss: 0.4960 - accuracy: 0.7631
Epoch 6: val_accuracy improved from 0.73364 to 0.73832, saving model to best_model.h5
54/54 [==============================] - 27s 503ms/step - loss: 0.4960 - accuracy: 0.7631 - val_loss: 0.4943 - val_accuracy: 0.7383
Epoch 7/50
54/54 [==============================] - ETA: 0s - loss: 0.4399 - accuracy: 0.7964
Epoch 7: val_accuracy improved from 0.73832 to 0.76168, saving model to best_model.h5
54/54 [==============================] - 28s 512ms/step - loss: 0.4399 - accuracy: 0.7964 - val_loss: 0.4526 - val_accuracy: 0.7617
Epoch 8/50
54/54 [==============================] - ETA: 0s - loss: 0.4317 - accuracy: 0.7812
Epoch 8: val_accuracy improved from 0.76168 to 0.82477, saving model to best_model.h5
54/54 [==============================] - 27s 510ms/step - loss: 0.4317 - accuracy: 0.7812 - val_loss: 0.4340 - val_accuracy: 0.8248
Epoch 9/50
54/54 [==============================] - ETA: 0s - loss: 0.3956 - accuracy: 0.8180
Epoch 9: val_accuracy did not improve from 0.82477
54/54 [==============================] - 27s 504ms/step - loss: 0.3956 - accuracy: 0.8180 - val_loss: 0.4345 - val_accuracy: 0.7804
Epoch 10/50
54/54 [==============================] - ETA: 0s - loss: 0.3945 - accuracy: 0.8197
Epoch 10: val_accuracy improved from 0.82477 to 0.82710, saving model to best_model.h5
54/54 [==============================] - 27s 504ms/step - loss: 0.3945 - accuracy: 0.8197 - val_loss: 0.3988 - val_accuracy: 0.8271
Epoch 11/50
54/54 [==============================] - ETA: 0s - loss: 0.3428 - accuracy: 0.8553
Epoch 11: val_accuracy did not improve from 0.82710
54/54 [==============================] - 31s 570ms/step - loss: 0.3428 - accuracy: 0.8553 - val_loss: 0.4155 - val_accuracy: 0.8224
Epoch 12/50
54/54 [==============================] - ETA: 0s - loss: 0.3182 - accuracy: 0.8588
Epoch 12: val_accuracy did not improve from 0.82710
54/54 [==============================] - 30s 550ms/step - loss: 0.3182 - accuracy: 0.8588 - val_loss: 0.4010 - val_accuracy: 0.8178
Epoch 13/50
54/54 [==============================] - ETA: 0s - loss: 0.2822 - accuracy: 0.8816
Epoch 13: val_accuracy improved from 0.82710 to 0.84813, saving model to best_model.h5
54/54 [==============================] - 29s 530ms/step - loss: 0.2822 - accuracy: 0.8816 - val_loss: 0.3556 - val_accuracy: 0.8481
Epoch 14/50
54/54 [==============================] - ETA: 0s - loss: 0.2645 - accuracy: 0.8973
Epoch 14: val_accuracy improved from 0.84813 to 0.85047, saving model to best_model.h5
54/54 [==============================] - 30s 555ms/step - loss: 0.2645 - accuracy: 0.8973 - val_loss: 0.4075 - val_accuracy: 0.8505
Epoch 15/50
54/54 [==============================] - ETA: 0s - loss: 0.2466 - accuracy: 0.8909
Epoch 15: val_accuracy improved from 0.85047 to 0.85748, saving model to best_model.h5
54/54 [==============================] - 29s 539ms/step - loss: 0.2466 - accuracy: 0.8909 - val_loss: 0.3756 - val_accuracy: 0.8575
Epoch 16/50
54/54 [==============================] - ETA: 0s - loss: 0.2291 - accuracy: 0.9049
Epoch 16: val_accuracy did not improve from 0.85748
54/54 [==============================] - 31s 569ms/step - loss: 0.2291 - accuracy: 0.9049 - val_loss: 0.4841 - val_accuracy: 0.8107
Epoch 17/50
54/54 [==============================] - ETA: 0s - loss: 0.2415 - accuracy: 0.9043
Epoch 17: val_accuracy did not improve from 0.85748
54/54 [==============================] - 28s 511ms/step - loss: 0.2415 - accuracy: 0.9043 - val_loss: 0.4146 - val_accuracy: 0.8341
Epoch 18/50
54/54 [==============================] - ETA: 0s - loss: 0.2418 - accuracy: 0.9020
Epoch 18: val_accuracy did not improve from 0.85748
54/54 [==============================] - 28s 513ms/step - loss: 0.2418 - accuracy: 0.9020 - val_loss: 0.4829 - val_accuracy: 0.8248
Epoch 19/50
54/54 [==============================] - ETA: 0s - loss: 0.1945 - accuracy: 0.9183
Epoch 19: val_accuracy did not improve from 0.85748
54/54 [==============================] - 27s 506ms/step - loss: 0.1945 - accuracy: 0.9183 - val_loss: 0.4692 - val_accuracy: 0.8248
Epoch 20/50
54/54 [==============================] - ETA: 0s - loss: 0.1950 - accuracy: 0.9218
Epoch 20: val_accuracy did not improve from 0.85748
54/54 [==============================] - 27s 505ms/step - loss: 0.1950 - accuracy: 0.9218 - val_loss: 0.4457 - val_accuracy: 0.8551
Epoch 21/50
54/54 [==============================] - ETA: 0s - loss: 0.1721 - accuracy: 0.9329
Epoch 21: val_accuracy did not improve from 0.85748
54/54 [==============================] - 28s 526ms/step - loss: 0.1721 - accuracy: 0.9329 - val_loss: 0.4579 - val_accuracy: 0.8505
Epoch 22/50
54/54 [==============================] - ETA: 0s - loss: 0.1589 - accuracy: 0.9358
Epoch 22: val_accuracy did not improve from 0.85748
54/54 [==============================] - 28s 520ms/step - loss: 0.1589 - accuracy: 0.9358 - val_loss: 0.4215 - val_accuracy: 0.8505
Epoch 23/50
54/54 [==============================] - ETA: 0s - loss: 0.1280 - accuracy: 0.9522
Epoch 23: val_accuracy improved from 0.85748 to 0.86916, saving model to best_model.h5
54/54 [==============================] - 28s 516ms/step - loss: 0.1280 - accuracy: 0.9522 - val_loss: 0.5170 - val_accuracy: 0.8692
Epoch 24/50
54/54 [==============================] - ETA: 0s - loss: 0.1176 - accuracy: 0.9539
Epoch 24: val_accuracy did not improve from 0.86916
54/54 [==============================] - 28s 522ms/step - loss: 0.1176 - accuracy: 0.9539 - val_loss: 0.5326 - val_accuracy: 0.8575
Epoch 25/50
54/54 [==============================] - ETA: 0s - loss: 0.1159 - accuracy: 0.9574
Epoch 25: val_accuracy did not improve from 0.86916
54/54 [==============================] - 26s 488ms/step - loss: 0.1159 - accuracy: 0.9574 - val_loss: 0.5191 - val_accuracy: 0.8505
Epoch 26/50
54/54 [==============================] - ETA: 0s - loss: 0.1232 - accuracy: 0.9504
Epoch 26: val_accuracy did not improve from 0.86916
54/54 [==============================] - 26s 489ms/step - loss: 0.1232 - accuracy: 0.9504 - val_loss: 0.5187 - val_accuracy: 0.8575
Epoch 27/50
54/54 [==============================] - ETA: 0s - loss: 0.0909 - accuracy: 0.9656
Epoch 27: val_accuracy did not improve from 0.86916
54/54 [==============================] - 26s 488ms/step - loss: 0.0909 - accuracy: 0.9656 - val_loss: 0.5334 - val_accuracy: 0.8598
Epoch 28/50
54/54 [==============================] - ETA: 0s - loss: 0.0768 - accuracy: 0.9667
Epoch 28: val_accuracy improved from 0.86916 to 0.87383, saving model to best_model.h5
54/54 [==============================] - 26s 489ms/step - loss: 0.0768 - accuracy: 0.9667 - val_loss: 0.5541 - val_accuracy: 0.8738
Epoch 29/50
54/54 [==============================] - ETA: 0s - loss: 0.1012 - accuracy: 0.9586
Epoch 29: val_accuracy did not improve from 0.87383
54/54 [==============================] - 26s 486ms/step - loss: 0.1012 - accuracy: 0.9586 - val_loss: 0.5188 - val_accuracy: 0.8645
Epoch 30/50
54/54 [==============================] - ETA: 0s - loss: 0.0842 - accuracy: 0.9708
Epoch 30: val_accuracy did not improve from 0.87383
54/54 [==============================] - 26s 485ms/step - loss: 0.0842 - accuracy: 0.9708 - val_loss: 0.5168 - val_accuracy: 0.8668
Epoch 31/50
54/54 [==============================] - ETA: 0s - loss: 0.0593 - accuracy: 0.9784
Epoch 31: val_accuracy did not improve from 0.87383
54/54 [==============================] - 26s 485ms/step - loss: 0.0593 - accuracy: 0.9784 - val_loss: 0.7652 - val_accuracy: 0.8645
Epoch 32/50
54/54 [==============================] - ETA: 0s - loss: 0.0782 - accuracy: 0.9697
Epoch 32: val_accuracy did not improve from 0.87383
54/54 [==============================] - 27s 491ms/step - loss: 0.0782 - accuracy: 0.9697 - val_loss: 0.5526 - val_accuracy: 0.8715
Epoch 33/50
54/54 [==============================] - ETA: 0s - loss: 0.0634 - accuracy: 0.9737
Epoch 33: val_accuracy did not improve from 0.87383
54/54 [==============================] - 26s 487ms/step - loss: 0.0634 - accuracy: 0.9737 - val_loss: 0.5260 - val_accuracy: 0.8715
Epoch 34/50
54/54 [==============================] - ETA: 0s - loss: 0.0714 - accuracy: 0.9656
Epoch 34: val_accuracy improved from 0.87383 to 0.88318, saving model to best_model.h5
54/54 [==============================] - 27s 498ms/step - loss: 0.0714 - accuracy: 0.9656 - val_loss: 0.6139 - val_accuracy: 0.8832
Epoch 35/50
54/54 [==============================] - ETA: 0s - loss: 0.0815 - accuracy: 0.9662
Epoch 35: val_accuracy did not improve from 0.88318
54/54 [==============================] - 26s 487ms/step - loss: 0.0815 - accuracy: 0.9662 - val_loss: 0.6166 - val_accuracy: 0.8785
Epoch 36/50
54/54 [==============================] - ETA: 0s - loss: 0.0585 - accuracy: 0.9767
Epoch 36: val_accuracy did not improve from 0.88318
54/54 [==============================] - 26s 490ms/step - loss: 0.0585 - accuracy: 0.9767 - val_loss: 0.5639 - val_accuracy: 0.8738
Epoch 37/50
54/54 [==============================] - ETA: 0s - loss: 0.0548 - accuracy: 0.9796
Epoch 37: val_accuracy did not improve from 0.88318
54/54 [==============================] - 27s 500ms/step - loss: 0.0548 - accuracy: 0.9796 - val_loss: 0.7298 - val_accuracy: 0.8785
Epoch 38/50
54/54 [==============================] - ETA: 0s - loss: 0.0508 - accuracy: 0.9772
Epoch 38: val_accuracy improved from 0.88318 to 0.88785, saving model to best_model.h5
54/54 [==============================] - 27s 497ms/step - loss: 0.0508 - accuracy: 0.9772 - val_loss: 0.5394 - val_accuracy: 0.8879
Epoch 39/50
54/54 [==============================] - ETA: 0s - loss: 0.0566 - accuracy: 0.9755
Epoch 39: val_accuracy did not improve from 0.88785
54/54 [==============================] - 26s 491ms/step - loss: 0.0566 - accuracy: 0.9755 - val_loss: 0.8067 - val_accuracy: 0.8668
Epoch 40/50
54/54 [==============================] - ETA: 0s - loss: 0.0571 - accuracy: 0.9767
Epoch 40: val_accuracy did not improve from 0.88785
54/54 [==============================] - 26s 490ms/step - loss: 0.0571 - accuracy: 0.9767 - val_loss: 0.7846 - val_accuracy: 0.8832
Epoch 41/50
54/54 [==============================] - ETA: 0s - loss: 0.0618 - accuracy: 0.9761
Epoch 41: val_accuracy did not improve from 0.88785
54/54 [==============================] - 27s 495ms/step - loss: 0.0618 - accuracy: 0.9761 - val_loss: 0.5678 - val_accuracy: 0.8808
Epoch 42/50
54/54 [==============================] - ETA: 0s - loss: 0.0513 - accuracy: 0.9772
Epoch 42: val_accuracy did not improve from 0.88785
54/54 [==============================] - 28s 512ms/step - loss: 0.0513 - accuracy: 0.9772 - val_loss: 0.6415 - val_accuracy: 0.8879
Epoch 43/50
54/54 [==============================] - ETA: 0s - loss: 0.0499 - accuracy: 0.9743
Epoch 43: val_accuracy did not improve from 0.88785
54/54 [==============================] - 28s 524ms/step - loss: 0.0499 - accuracy: 0.9743 - val_loss: 0.6707 - val_accuracy: 0.8715
Epoch 44/50
54/54 [==============================] - ETA: 0s - loss: 0.0437 - accuracy: 0.9837
Epoch 44: val_accuracy did not improve from 0.88785
54/54 [==============================] - 28s 519ms/step - loss: 0.0437 - accuracy: 0.9837 - val_loss: 0.6325 - val_accuracy: 0.8715
Epoch 45/50
54/54 [==============================] - ETA: 0s - loss: 0.0507 - accuracy: 0.9743
Epoch 45: val_accuracy did not improve from 0.88785
54/54 [==============================] - 28s 519ms/step - loss: 0.0507 - accuracy: 0.9743 - val_loss: 0.6201 - val_accuracy: 0.8715
Epoch 46/50
54/54 [==============================] - ETA: 0s - loss: 0.0403 - accuracy: 0.9813
Epoch 46: val_accuracy did not improve from 0.88785
54/54 [==============================] - 28s 524ms/step - loss: 0.0403 - accuracy: 0.9813 - val_loss: 0.7710 - val_accuracy: 0.8785
Epoch 47/50
54/54 [==============================] - ETA: 0s - loss: 0.0425 - accuracy: 0.9831
Epoch 47: val_accuracy improved from 0.88785 to 0.89486, saving model to best_model.h5
54/54 [==============================] - 28s 523ms/step - loss: 0.0425 - accuracy: 0.9831 - val_loss: 0.6416 - val_accuracy: 0.8949
Epoch 48/50
54/54 [==============================] - ETA: 0s - loss: 0.0480 - accuracy: 0.9802
Epoch 48: val_accuracy did not improve from 0.89486
54/54 [==============================] - 28s 520ms/step - loss: 0.0480 - accuracy: 0.9802 - val_loss: 0.8568 - val_accuracy: 0.8668
Epoch 49/50
54/54 [==============================] - ETA: 0s - loss: 0.0408 - accuracy: 0.9842
Epoch 49: val_accuracy did not improve from 0.89486
54/54 [==============================] - 28s 526ms/step - loss: 0.0408 - accuracy: 0.9842 - val_loss: 0.7252 - val_accuracy: 0.8762
Epoch 50/50
54/54 [==============================] - ETA: 0s - loss: 0.0352 - accuracy: 0.9860
Epoch 50: val_accuracy did not improve from 0.89486
54/54 [==============================] - 29s 533ms/step - loss: 0.0352 - accuracy: 0.9860 - val_loss: 0.7049 - val_accuracy: 0.8808
六、模型预测
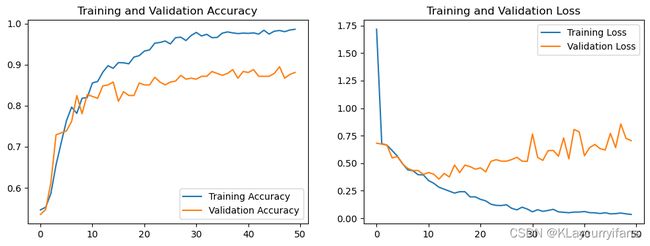
1. Loss与Accuracy图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label = 'Training Accuracy')
plt.plot(epochs_range, val_acc, label = 'Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label = 'Training Loss')
plt.plot(epochs_range, val_loss, label = 'Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2. 指定图片进行预测
#加载效果最好的模型权重
img_array = model.load_weights('best_model.h5')
from PIL import Image
import numpy as np
img = Image.open('./data/Monkeypox/M06_01_00.jpg') #这里选择你需要预测的图片
image = tf.image.resize(img, [224, 224])
img_array = tf.expand_dims(image, 0)
predictions = model.predict(img_array) #这里选用你已经训练好的模型
print('预测结果为:', class_names[np.argmax(predictions)])
预测结果为:Monkeypox