高等排序——分割与快速排序
快速排序是最经常使用的排序算法,其时间复杂度为O(nlogn),且空间占用为常数
在学习快速排序之前,我们先引入一个题目,学习分割的思想,这是实现快速排序的前提
分割
假定给出一个数组A,要求在下标q至r范围内,将其分割为p到q-1与q+1到r两个部分,并返回下标q的值,其中A[p,q-1]中的所有元素均小于等于A[q],而A[q+1,r]中的所有元素均大于A[q]
我们将A[p,q-1]称作数组C,A[q+1,r}称作数组D,则当一开始A[q]的值确定下来时,C与D的长度是不确定的,因此我们不能先定下A[q]的位置,其位置应该随着C数组长度的变化而变化(就在其下一位)。因此,我们需要先找到所有小于等于A[q]的元素,并将其排列到数组前面,这样,D的元素也就相应地确定了
那么我们如何实现这个操作呢?
一、前后指针法
首先我们需要定下A[q]的值,我们不妨取数组的最后一个元素A[r]作为A[q]的值
我们需要开两个指针p1与p2,p1所指以及其前面的元素均为C数组的元素,而p2所指的前面的元素为D数组的元素。一开始,我们令p1指向p-1(因为C数组一开始为空),p2指向p(D数组也为空),然后我们使p2遍历数组A,当遇到大于A[q]的元素,我们移动到下一位(相当于把它加入到D数组),遇到小于等于A[q]的元素时,我们就需要把它放到C数组去了,具体操作为:p1指向下一位(在移动之前,由于p1到p2之间都是D数组的元素,因此这时p1指向的元素属于D数组),将*p1与*p2对调,这样子,p2所指元素就成功加入了C数组,而p1所指的元素又调换回了D数组
如此循环遍历下去,直到p2指向A[r],我们就成功地排好了C数组和D数组,最后只需要将A[r]插入到数组C与D之间,也就是使p1指向的下一位元素与p2指向的元素对调,即可完成排序
实现代码如下:
void partition1(int* nums, int p, int r){
int i=p-1;//指向数组C
int j=p;//指向数组D
int key=nums[r];
while(jkey){ //归入数组D
j++;
}
else{
int temp=nums[++i];
nums[i]=nums[j];
nums[j++]=temp; //对调归入数组C
}
}
nums[r]=nums[i+1];
nums[i+1]=key; //nums[r]与nums[i+1]位置对调
}
二、左右指针法
第一种方法是开两个指针同时前进,那么我们也可以左右各开一个指针,使C,D两个数组向中间生长
实现代码如下:
void partition2(int* nums, int p, int r) {
int i = p;//左指针
int j = r;//右指针
int key = nums[p];
while (i != j) {
while (nums[j] > key && j > i) {//右指针向左查找,直到找到比key小的元素
j--;
} //j>i防止左指针超过右指针
while (nums[i] <= key && j > i) {//左指针向右查找,直到找到比key大的元素
i++;
}
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp; //左右指针所指元素交换
}
nums[p]=nums[i];
nums[i]=key; //插入键值
}左右指针减少了元素对调次数,更加高效
快速排序
聪明的小伙伴这个时候就发现了,我们通过分割得到两个相对有序的数组,这个结果和归并排序是类似的,那么,我们是不是也可以运用类似的思路,将这两个相对有序的数组继续分割排序,最终使整个数组有序呢?没错,这也就是我们快速排序的实现方法,而且相对于归并排序而言,我们不需要进行合并处理,不需要占用额外的内存
实现代码如下:(采用左右指针法)
void QuickSort(int* nums, int p, int r) {
if (p >= r) {//保证区间存在
return;
}
int i = p;
int j = r;
int key = nums[p];
while (i != j) {
while (nums[j] >key && j > i) {
j--;
}
while (nums[i] <= key && j > i) {
i++;
}
int temp = nums[j];
nums[j] = nums[i];
nums[i] = temp;
}
nums[p] = nums[i];
nums[i] = key;//以上为分割算法
QuickSort(nums, p, i - 1);//递归数组C
QuickSort(nums, i + 1, r);//递归数组D
}总结:
快速排序在分割的过程中会交换不相邻的元素,因此属于不稳定的排序算法
快速排序的效率与key值的选取息息相关,如果在分割时能恰好选到中间值,则整个过程与归并排序一样,大致分为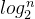 层,平均时间复杂度为O(nlogn),是一般情况下最高效的排序算法。若像我的上述代码(前后指针法)一样,采用固定的方式选取key值,那么当处理某些顺序的数据(如已经排序完毕的数组)的时候,效率会大打折扣,最坏的情况,时间复杂度甚至高达O(
层,平均时间复杂度为O(nlogn),是一般情况下最高效的排序算法。若像我的上述代码(前后指针法)一样,采用固定的方式选取key值,那么当处理某些顺序的数据(如已经排序完毕的数组)的时候,效率会大打折扣,最坏的情况,时间复杂度甚至高达O( ),甚至有可能导致递归的深度过大而栈溢出。因此,我们需要在key值的选取上多加考量,比如随机选择,或者任选出几个元素的值然后取其中间值
),甚至有可能导致递归的深度过大而栈溢出。因此,我们需要在key值的选取上多加考量,比如随机选择,或者任选出几个元素的值然后取其中间值