深度学习--机器学习相关(2)
1.适 应 性 矩 估 计
适应性矩估计(Adaptive Moment Estimation,Adam)是一种可以代替传统的梯度下降 (SGD 和 MBGD) 的优化算法。Adam算法结合了适应性梯度算法和均方根传播的优点。
Momentum 在学习机器学习时是很可能遇到的,是动量的意思。动量不是速度和学习率,应该说是类似于加速度。
AdaGrad(适应性梯度算法)
适应性梯度算法的特点在于:独立地调整每一个参数的学习率。在SGD 中,所有的参数都是用相同的学习率η,而AdaGrad 的特点就是可以独立地调整每一个参数的学习率。AdaGrad 给每一个参数都设置独立的学习率,让梯度大的参数的学习率较小,梯 度小的学习率较大,来加快模型的收敛速度。
RMSProp(均方根传播)
均方根传播的核心是通过指数衰减来丢弃很久以前的信息。这样的话,过去的信息对现在的影响就会不断减弱,保证学习率不会太小。
正则化与范式
正则化(Regularization) 是防止模型过拟合,增强模型的泛化能力。范式(Paradigm), 主要有3个: L0、L1和 L2。在机器学习领域中,范式是一种正则化的方法,正则化还有很多其他方法,比如:数据增强、Dropout 、Earlystopping。
1 . 正 则 化
在一个神经网络中,可以有成百上千的参数,但是并不是每一个参数都是有用的,不是每一个参数都可以体现数据的本质特征。神经网络学习数据的时候,能学到数据的本质,也能学到一些没什么意义的东西。例如,考试卷子上第3个选择题选B, 模型可以学到真正的知识,从而正确地推导这道题的答案,这个就是模型的泛化能力,也是想要的能力;模型也可能学到考试卷子的第3题就选B。 这个就是过拟合情况,没学到本质。正则化就是帮助模型学习泛化能力,避免过拟合的手段。
2.L0 、L1 、L2 范 式
(1)L0范式就是限制模型参数中非零参数的个数;
(2)L1 范式表示每一个参数绝对值的和;
(3)L2 范式表示每一个参数的平方和的开方值。
可以把范式看成附加到模型上的一些限制条件,让模型拘束着去学习泛化能力。L0 范式就是限制参数的非零个数,也可以说这是实现模型参数的稀疏化; L1 和 L2 会让模型的参数值较小。为什么较小参数值好呢?因为神经网络参数很多,没有限制的话,模型会尽可能地让所有的训练集都预测正确,这样往往是过拟合了,通过限制,让模型只能实现大多数
2.L0 、L1 、L2 范 式
(1)LO 范式就是限制模型参数中非零参数的个数;
(2)L1 范式表示每一个参数绝对值的和;
(3)L2 范式表示每一个参数的平方和的开方值。
可以把范式看成附加到模型上的一些限制条件,让模型拘束着去学习泛化能力。LO 范 式就是限制参数的非零个数,也可以说这是实现模型参数的稀疏化; L1 和 L2 会让模型的 参数值较小。为什么较小参数值好呢?因为神经网络参数很多,没有限制的话,模型会尽可 能地让所有的训练集都预测正确,这样往往是过拟合了,通过限制,让模型只能实现大多数样本的正确预测,这样就可以自发地避免一些对噪声数据、异常数据的学习,从而学到真实的正确的本质。
其他的正则化手段
数据增强一般在图像处理中,比如对图像做一些增强处理,常见的有:随机旋转、随机 平移、随机剪裁,让数据集尽可能地丰富多彩一些。Dropout 就是随机让一些神经元失活,不起效果。Earlystopping是让模型提早停止训练。因为实现中不知道模型到底需要训练多少个 epoch才能刚好达到最强泛化能力,而又不过拟合,所以就这是一个Earlystopping,例如让验证集的预测准确率在5个epoch 内都不再提升了,就说明模型训练可以,然后把5个 epoch之前的模型文件作为最终的训练好的模型。
标签平滑正则化
标签平滑正则化(Label Smoothing Regularization,LSR)是通过向标签中添加噪声进行约束的方法。例如, 一个图像分类问题,总共有3个类别,猫狗鸟,假设一个图片是狗,那么类别就是1。把这个标签经过one-hot 编码转换,变成[0,1,0]。LSR 就是平滑了 one-hot 编码,变成 [0.1,1,0.1]。
受限玻尔兹曼机(Restricted Boltzman Machine,RBM)的结构看起来就是两层的全连接层,但略有差别。
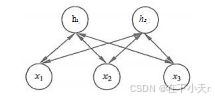
第一层(x 层)称为可见层,也有的称为输入层,第二层称为隐层或者隐藏层。RBM 之 所以称为受限的,是因为同一层之间神经元没有连接。
注意:相比一般的全连接网络来说没有输出层。
RBM中权重是双向的,而一般神经网络中权重一般都是单向的、前向传播 的。这是因为RBM 在训练的时候不仅仅包括前向传播和梯度下降,还多了一个反向传播的过程(此处的反向传播不是常说的反向传播梯度下降的反向传播)。RBM 是一种无监督学习的模型,并且发现 RBM 与 AutoEncoder 特别相近。而深度信念网络(Deep Belief Network,DBN)就是多个 RBM 的堆叠。训练过程主要分两步。先训练第一层和第二层,假装第三层不存在。训练好一、二层之后,固定住一、二层的权重值,然后训练二、三层,就这样把所有层训练完。最后整个DBN 一起训练,进行参数的微调。
RBM现在用的不是很多,RBM 与 AE 相近,而 DBN 与 Stack AE模型非常相近。
3.图片的RGB和 HSV
一张黑白图片是由像素点组成的。把每一个像素点上的黑白颜色划分成256个级别,0 是黑色,255是白色。这样, 一张黑白图片就是一个矩阵,这个矩阵上每一个元素都对应一 个像素的黑白强弱值。而在计算机看到的其实不是人眼看到的图片,而是这些表示图片颜 色强度的矩阵。 一张彩色图片同样是由像素点组成的,但是每一个像素点都是彩色的。任意一种颜色可以通过光的三原色(红色、绿色、蓝色,即Red、Green、Blue)的某种组合来实现,所以类似黑白强度矩阵,彩色图片可以分布三个大小相同的强度矩阵,分别表示红色强度、绿色强度和蓝色强度。这样组合起来就是一张任意色彩的彩色图片。
有时还会看到图片的HSV, 这是根据颜色的直观特性创建的,通俗来讲就是H表示色调,S 表示饱和度,V 表示明度。色调H 取值范围是0°~360°, 0°表示红色,120°是绿色,240°是蓝色,黄色60°,青色180°,品红300°,这个色调就是光谱色。 饱和度S 的取值范围是0%~100%,是光谱色(色调)与白色混合的程度,假如饱和度为 0%,就是白色;如果是100%,就是光谱色。明度V 表示颜色明亮的程度,形容一种反射程度,如果是0,那么没有反射能力,图片是黑色的,如果是1,反射能力非常强,看起来白茫茫 一片。
用Python 来读取一张图片的RGB矩阵
import cv2
import numpy as np
image_path = 'C:\\Users\\hedong\\Pictures\\Saved Pictures\\9.4.webp' # 请确保这里有图片文件的完整路径和文件名
img = cv2.imread(image_path)
if img is not None:
print(img.shape) # 打印图片的维度
else:
print("Error: Image not found or the path is incorrect.")下面把 RGB转换为HSV
import cv2
import numpy as np
image_path = 'C:\\Users\\hedong\\Pictures\\Saved Pictures\\9.4.webp' # 请确保这里有图片文件的完整路径和文件名
img = cv2.imread(image_path)
hsv_img=cv2.cvtColor(img,cv2.COLOR_RGB2HSV)#使用 cv2.cvtColor 函数将图片从 RGB 颜色空间转换到 HSV 颜色空间
print('色调最大值:',np.max(hsv_img[:,:,0]))
print('饱和度最大值:',np.max(hsv_img[:,:,1]))
print('明度最大值:',np.max(hsv_img[:,:,2]))
#使用 numpy 的 np.max 函数分别计算 HSV 图像中色调(Hue)、饱和度(Saturation)、明度(Value)通道的最大值。
#在图像处理中,HSV颜色空间的0、1、2分别代表色调(Hue)、饱和度(Saturation)和亮度(Value)。如果使用Python 的 Matplotplot.pyplot.imshow来绘制 RGB 图片,会出现色差,这是因为读取cv2的图片是RGB 的,而plt.imshow 绘制图片是用BGR 图片,所以,可以这样转换:
#进一步转换
img=img[:,:,[2,1,0]]
#或者
img_hsv=cv2.cvtColor(img,cv2.COLOR_RGB2BGR)在图像处理中,使用 `[:,:,:]` 这种索引方式访问图像数据时,这三个冒号 `:` 表示:
1. 第一个 `:` 表示图像的所有行。
2. 第二个 `:` 表示图像的所有列。
3. 第三个 `:` 表示图像的所有颜色通道。
4.网中网结构
神经网络中的神经网络(Network In Network,NIN)

通过增加1×1卷积和激活函数,来提升模型效果。之前的单个3×3卷积层称为Conv 层。而使用了网中网增加了两组1×1卷积层和激活函数的称为多层感知机(Multiple Layer Perceptron,MLP)。NIN 架构是一种经典的卷积神经网络设计,它通过在卷积层后面添加 1x1 卷积层来增加网络的非线性能力和表征能力。
in_channels:输入特征图的通道数。out_channels:输出特征图的通道数,也就是卷积层的滤波器(卷积核)数量。kernel_size:卷积核的大小,通常是一个整数或一个由两个整数组成的元组(对于正方形卷积核)。stride:卷积操作的步长,它决定了卷积核移动的间隔。padding:边缘填充的大小,用于控制输出特征图的尺寸def NIN_block(in_chanels,out_chanels,kernel_sizeStride,padding): blk=nn.Sequential( nn.Conv2d(in_chanels,out_chanels,kernel_size,Sride,padding), nn.ReLU(), #模拟全连接层的多成感知机 nn.Conv2d(out_chanels,out_chanels,kernel_size=1), nn.ReLU(), nn.Conv2d(out_chanels,out_chanels,kernel_size=1), nn.ReLU(), ) return blk #之前的卷积层 nn.Conv2d(in_chanels,out_chanels,kernel_size,Stride,padding), #现在改成NIN NIN_block(in_chanels,out_chanels,kernel_size,Stride,padding)