Mysql-PXC 高可用 Docker部署
mysql ha 部署
方案
PXC
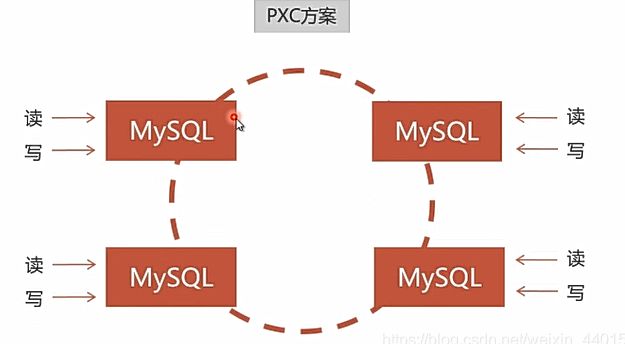
环境
# 127.16网段作为测试网络
docker network create --subnet=172.16.0.0/16 --driver bridge hfnet
| 网段 | 应用 | 宿主映射 | 说明 |
|---|---|---|---|
| 172.19.129.98 | 宿主 host | ||
| 172.16.10.1:3306 | mysql | 3316 | |
| 172.16.10.2:3306 | mysql | 3326 | |
| 172.16.10.3:3306 | mysql | 3336 | |
| 172.16.10.101:3306 | haproxy | 3306 3366(管理) | 均衡10.1 10.2 10.3 |
| 172.16.10.102:3306 | haproxy | 3106 3166(管理) | 均衡10.1 10.2 10.3 |
| 172.19.129.99 | keepalived V-IP | 均衡98:3306 98:3106 |
搭建完成后,在hfnet网段的容器可通过172.16.10.99:3306访问数据库。
部署
镜像下载
docker pull percona/percona-xtradb-cluster:8.0.21
创建网络
docker network create --subnet=172.16.0.0/16 --driver bridge hfnet
创建存储并修改权限
mkdir n1 n2 n3 && chmod -R 777 n1 n2 n3
docker-compose.yml
version: "3.7"
services:
node1:
image: percona/percona-xtradb-cluster:8.0.21
container_name: node1
restart: always
privileged: true
ports:
- "3316:3306"
environment:
- TZ=Asia/Shanghai
- MYSQL_ROOT_PASSWORD=123456
- XTRABACKUP_PASSWORD=123456
# 集群名,要一致
- CLUSTER_NAME=PXC
# 存储数据
volumes:
- ./n1:/var/lib/mysql
networks:
default:
ipv4_address: 172.16.10.1
node2:
image: percona/percona-xtradb-cluster:8.0.21
container_name: node2
restart: always
privileged: true
ports:
# IP不要冲突
- "3326:3306"
environment:
- TZ=Asia/Shanghai
- MYSQL_ROOT_PASSWORD=123456
- XTRABACKUP_PASSWORD=123456
# 集群名,要一致
- CLUSTER_NAME=PXC
# 第2台以后增加此配置
- CLUSTER_JOIN=node1
# 存储数据
volumes:
- ./n2:/var/lib/mysql
networks:
default:
# IP不要相同
ipv4_address: 172.16.10.2
node3:
image: percona/percona-xtradb-cluster:8.0.21
container_name: node3
restart: always
privileged: true
ports:
# IP不要冲突
- "3336:3306"
environment:
- TZ=Asia/Shanghai
- MYSQL_ROOT_PASSWORD=123456
- XTRABACKUP_PASSWORD=123456
# 集群名,要一致
- CLUSTER_NAME=PXC
# 第2台以后增加此配置
- CLUSTER_JOIN=node1
# 存储数据
volumes:
- ./n3:/var/lib/mysql
networks:
default:
# IP不要相同
ipv4_address: 172.16.10.3
networks:
default:
external:
name: hfnet
启动过程
# 先启动node1,能够正常连接后再启动其他节点
docker-compose up -d node1
# 查看日志
docker-compose logs -f node1
# 等3分钟左右,工具连接mysql成功后再做后续步骤
1. 启动node2
docker-compose up -d node2
# 查看日志
docker-compose logs -f node2
# 报ssl证书错误
2. 停止
docker-compose stop node2
3. 复制node1的认证文件,以确保所有node的认证相同(不要在up前复制)
\cp n1/*.pem n2/
4. 重启node
docker-compose up -d node2
5. 工具连接node2,测试是否正常
# 重复以上1-4启动 node3
1. 启动node3
docker-compose up -d node3
# 查看日志
docker-compose logs -f node3
# 报ssl证书错误
2. 停止
docker-compose stop node3
3. 复制node1的认证文件,以确保所有node的认证相同(不要在up前复制)
\cp n1/*.pem n3/
4. 重启node
docker-compose up -d node3
5. 工具连接node2,测试是否正常
附
注意事项
1. 由于pxc只作用于innodb引擎,而mysql自带的系统库(mysql)里面有些表是MyISAM的存储引擎,因此不能直接对系统库(mysql)的表进行dml操作,比如INSERT INTO mysql.user...。而是使用CREATE USER...,这个是没有问题的,而且也是正确的方式。
2. 不支持LOCK TABLES和UNLOCK TABLES语句
mysql> lock tables world write;
ERROR 1105 (HY000): Percona-XtraDB-Cluster prohibits use of LOCK TABLE/FLUSH TABLE <table> WITH READ LOCK/FOR EXPORT with pxc_strict_mode = ENFORCING
3. log_output参数不能是TABLE
4. 不支持分布式事务
5. 新建表必须要有主键,否则对表进行dml操作会报以下错误
ERROR 1105 (HY000): Percona-XtraDB-Cluster prohibits use of DML command on a table (hello.world) without an explicit primary key with pxc_strict_mode = ENFORCING or MASTER
6. 推荐的节点数最小是3个
is not allowed to connect to this MySql ser
docker-compose exec node1 bash
mysql -uroot –p123456
mysql>use mysql;
mysql>update user set host = ‘%’ where user = ‘root’;
mysql>select host, user from user;
mysql>FLUSH RIVILEGES
HaProxy 负载均衡
镜像下载
docker pull haproxy:2.3.4-alpine
创建haproxy用户用于心跳测试
# 1台创建,其他会自动同步
CREATE USER 'haproxy'@'%';
创建haproxy.cfg配置文件
server改为实际mysql配置
global
#工作目录
chroot /usr/local/etc/haproxy
#日志文件,使用rsyslog服务中local5日志设备(/var/log/local5),等级info
log 127.0.0.1 local5 info
#守护进程运行
daemon
defaults
log global
mode http
#日志格式
option httplog
#日志中不记录负载均衡的心跳检测记录
option dontlognull
#连接超时(毫秒)
timeout connect 5000
#客户端超时(毫秒)
timeout client 50000
#服务器超时(毫秒)
timeout server 50000
#监控界面
listen admin_stats
#监控界面的访问的IP和端口
bind 0.0.0.0:6666
#访问协议
mode http
#URI相对地址
stats uri /dbs
#统计报告格式
stats realm Global\ statistics
#登陆帐户信息
stats auth admin:123456
#数据库负载均衡
listen proxy-mysql
#访问的IP和端口
bind 0.0.0.0:3306
#网络协议
mode tcp
#负载均衡算法(轮询算法、后面的权重不会生效)
#轮询算法:roundrobin
#权重算法:static-rr
#最少连接算法:leastconn
#请求源IP算法:source
balance roundrobin
#日志格式
option tcplog
#在MySQL中创建一个没有权限的haproxy用户,密码为空。Haproxy使用这个账户对MySQL数据库心跳检测
option mysql-check user haproxy
server MySQL_1 172.19.129.98:3316 check weight 1 maxconn 2000
server MySQL_2 172.19.129.98:3326 check weight 1 maxconn 2000
server MySQL_3 172.19.129.98:3336 check weight 1 maxconn 2000
#使用keepalive检测死链
option tcpka
docker-compose.yml
version: "3.7"
services:
haproxy:
image: haproxy:2.3.4-alpine
container_name: haproxy
restart: always
privileged: true
ports:
- "3306:3306"
# 管理页面
- "3366:6666"
environment:
- TZ=Asia/Shanghai
- MYSQL_ROOT_PASSWORD=123456
- XTRABACKUP_PASSWORD=123456
# 集群名,要一致
- CLUSTER_NAME=PXC
# 存储数据
volumes:
# haproxy.ini在./haproxy目录下
- ./haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg
访问
- 172.9.129.98:3306 mysql
- http://172.19.129.98:3366/dbs haproxy 管理界面 登录:admin/123456
slave
再运行一个haproxy,做如下修改。
-
docker-compose.yml
# 修改端口 ports: - "3106:3306" # 管理页面 - "3166:6666" -
访问
- 172.19.129.98:3106 mysql
- http://172.19.129.98:3166 管理界面
Keepalive
说明
部署有两种方式,采用docker方式部署比较复杂,不推荐。
- docker运行在现有haproxy容器基础上,增加keepalived应用。
- 此方法仍需宿主机运行keepalived,原因是需要ipavadm.
- docker开启host模式
- 宿主运行 keepalived.
- 配置与docker方式相同
宿主keepalived
安装
yum install -y keepalived
systemctl enable keepalived
systemctl start keepalived
keepalived.conf
/etc/keepalived/keepalived.conf,virtual_ipaddress virtual_server 改为实际ip port
global_defs { #全局定义部分
# notification_email { #设置警报邮箱
# [email protected] #邮箱
# [email protected]
# [email protected]
# }
# notification_email_from [email protected] #设置发件人地址
# smtp_server 192.168.50.1 #设置smtp server地址
# smtp_connect_timeout 30 #设置smtp超时连接时间 以上参数可以不配置
router_id LVS_DEVEL #是Keepalived服务器的路由标识在一个局域网内,这个标识(router_id)是唯一的
}
vrrp_instance VI_1 { # VRRP实例定义区块名字是VI_1
state MASTER # 表示当前实例VI_1的角色状态这个状态只能有MASTER和BACKUP两种状态,并且需要大写这些字符ASTER为正式工作的状态,BACKUP为备用的状态
interface eth0 # 实例绑定的网卡, 用ip a命令查看网卡编号
virtual_router_id 88 # 虚拟路由ID标识,这个标识最好是一个数字(1-255),在一个keepalived.conf配置中是唯一的, MASTER和BACKUP配置中相同实例的virtual_router_id必须是一致的.
priority 100 # 优先级,数字越大优先级越高,在一个实例中主服务器优先级要高于备服务器
advert_int 1 # 主备之间同步检查的时间间隔单位秒
# unicast_src_ip 172.16.10.101 # haproxy 本地 IP
# unicast_peer { # 其他 haproxy IP,可以有多个
# 172.16.10.102
# }
authentication { # authentication为权限认证配置不要改动,
auth_type PASS # 验证类型有两种 PASS和HA
auth_pass 123456 # 同一vrrp实例的MASTER与BACKUP使用相同的密码才能正常通信。
}
# 虚拟IP地址,可以有多个,每行一个
virtual_ipaddress {
172.19.129.99/20 dev eth0 label eth0:2 # 绑定接口为eth0,别名为eth0:2 此格式 `ip a` 显示 ifconfig不显示
}
}
# 至此为止以上为实现高可用配置,如只需使用高可用功能下边配置可删除
# 虚拟服务 宿主IP段
virtual_server 172.19.129.99 3306 { # 设置虚拟服务器,指定虚拟IP和端口
delay_loop 6 # 健康检查时间间隔 6s
lb_algo rr # 设置负载调度算法 rr算法
lb_kind NAT # 设置负载均衡机制, 有NAT,TUN和DR三种模式可选
nat_mask 255.255.255.0 # 非NAT模式注释掉此行 注释用!号
persistence_timeout 50 # 连接保留时间,50秒无响应则重新分配节点
protocol TCP # 指定转发协议为TCP
# 通过调度算法把Master切换到真实的负载均衡服务器上
# 定期进行健康检查 haproxy ,如果MASTER不可用,则切换到备机上
real_server 172.19.129.98 3306 { # RS节点1
weight 1 # 权重
TCP_CHECK { # 节点健康检查
connect_port 3306 # 连接超端口
connect_timeout 3 # 连接超时时间
}
}
real_server 172.19.129.98 3106 { # RS节点1
weight 1 # 权重
TCP_CHECK { # 节点健康检查
connect_port 3106 # 连接超端口
connect_timeout 3 # 连接超时时间
}
}
}
slave
另一台haproxy的机器配置,注意标注 不 同的地方
global_defs { #全局定义部分
# notification_email { #设置警报邮箱
# [email protected] #邮箱
# [email protected]
# [email protected]
# }
# notification_email_from [email protected] #设置发件人地址
# smtp_server 192.168.50.1 #设置smtp server地址
# smtp_connect_timeout 30 #设置smtp超时连接时间 以上参数可以不配置
router_id lb02 #此参数和lb01 MASTER **不**同 #是Keepalived服务器的路由标识在一个局域网内,这个标识(router_id)是唯一的
}
vrrp_instance VI_1 { # 和lb01 MASTER相同
state BACKUP # 此参数和lb01 MASTER **不**同
interface eth0 # 和lb01 MASTER相同
virtual_router_id 88 # 和lb01 MASTER相同
priority 100 # 此参数和lb01 MASTER不同
advert_int 1
# unicast_src_ip 172.16.10.102 # MASTER 中的 unicast_peer
# unicast_peer {
# 172.16.10.101 # 此处为 MASTER 的 unicast_src_ip
# }
authentication { # authentication为权限认证配置不要改动,
auth_type PASS # 验证类型有两种 PASS和HA
auth_pass 123456 # 同一vrrp实例的MASTER与BACKUP使用相同的密码才能正常通信。
}
# 虚拟IP地址,可以有多个,每行一个
virtual_ipaddress {
172.19.129.99/20 dev eth0 label eth0:2 # 绑定接口为eth0,别名为eth0:2 此格式 `ip a` 显示 ifconfig不显示
}
}
################ 以下与 MASTER 相同
# 至此为止以上为实现高可用配置,如只需使用高可用功能下边配置可删除
# 虚拟服务 宿主IP段
virtual_server 172.19.129.99 3306 { # 设置虚拟服务器,指定虚拟IP和端口
delay_loop 6 # 健康检查时间间隔 6s
lb_algo rr # 设置负载调度算法 rr算法
lb_kind NAT # 设置负载均衡机制, 有NAT,TUN和DR三种模式可选
nat_mask 255.255.255.0 # 非NAT模式注释掉此行 注释用!号
persistence_timeout 50 # 连接保留时间,50秒无响应则重新分配节点
protocol TCP # 指定转发协议为TCP
# 通过调度算法把Master切换到真实的负载均衡服务器上
# 定期进行健康检查 haproxy ,如果MASTER不可用,则切换到备机上
real_server 172.19.129.98 3306 { # RS节点1
weight 1 # 权重
TCP_CHECK { # 节点健康检查
connect_port 3306 # 连接超端口
connect_timeout 3 # 连接超时时间
}
}
real_server 172.19.129.98 3106 { # RS节点1
weight 1 # 权重
TCP_CHECK { # 节点健康检查
connect_port 3106 # 连接超端口
connect_timeout 3 # 连接超时时间
}
}
}
重启服务
systemctl restart keepalived
docker(haproxy+keepalived)
docker-entrypoint.sh
原haproxy容器 /usr/local/bin/docker-entrypoint.sh文件内增加运行 keepalived。
#!/bin/sh
set -e
# first arg is `-f` or `--some-option`
if [ "${1#-}" != "$1" ]; then
set -- haproxy "$@"
fi
if [ "$1" = 'haproxy' ]; then
shift # "haproxy"
# if the user wants "haproxy", let's add a couple useful flags
# -W -- "master-worker mode" (similar to the old "haproxy-systemd-wrapper"; allows for reload via "SIGUSR2")
# -db -- disables background mode
set -- haproxy -W -db "$@"
fi
# 增加keepalive运行
/usr/sbin/keepalived -n -l -D -f /etc/keepalived/keepalived.conf --dont-fork --log-console &
exec "$@"
Dockerfile
FROM haproxy:2.3.4-alpine
RUN apk update && apk upgrade
RUN apk add --no-cache bash curl ipvsadm iproute2 openrc keepalived; \
rm -f /var/cache/apk/* /tmp/*;
COPY docker-entrypoint.sh /usr/local/bin/
RUN chmod +x /usr/local/bin/docker-entrypoint.sh
docker build
docker build -t haproxy_keepalived:20210129 .
docker-compose.yml
1.image 改用 haproxy_keepalived:20210129
2.volumes ./keepalived.conf:/etc/keepalived/keepalived.conf
3.增加 `network_mode: host` 以虚拟宿主IP
keepalived.conf
与master用配置相同
slave.yml
1.image 改用 haproxy_keepalived:20210129
2.volumes ./keepalived_slave.conf:/etc/keepalived/keepalived.conf
3.增加 `network_mode: host` 以虚拟宿主IP
keepalived_slave.conf
与slave配置相同
附
修改配置后,重启容器
# 不要用 docker-compose restart
docker-compose down -v
docker-compose up -d
部署后,本地telnet虚拟ip没问题,其他同网段机器无法访问。
可能是云服务器不支持虚拟IP。
docker模式haproxy 6666无法打开
未解决
测试
- pxc
- 数据同步测试
- 单点故障
- 故障恢复
- haproxy集群
- 单点故障
- keepalived访问
测试结果不理想,很容易“脑裂”。转而测试PGPool-II方案。