Python应用与实践
目录
1. Python是什么?
1.1. Python语言
1.2. Python哲学
2. Python在工作中的应用
2.1. 实例1:文件批量处理
2.2. 实例2:xml与excel互转
2.3. 总结
3. 为什么选择Python?
3.1. 前途!钱途!
3.2. 开发效率极高
3.3. 总而言之
4. 还有谁在用Python?
4.1. 国外
4.2. 国内
5. 是不是想学习Python了?
入门资料
工具
可能有些标题党,没有针对某些具体的应用与实践。有哪些补充、不足请大家指出。
1. Python是什么?
Life is short, You need python
生命苦短,我用Python
1.1. Python语言
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言,具有20多年的发展历史,成熟且稳定。Python具有以下特点(摘自《A Byte of Python》,中译名《简明Python教程》):
l 简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样。它使你能够专注于解决问题而不是去搞明白语言本身。
l 易学:Python极其容易上手,因为Python有极其简单的。
l 免费、开源。
l 高层语言:用Python语言编写程序的时候无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
l 可移植性:由于它的开源本质,Python已经被移植在几乎所有平台上(经过改动使它能够工作在不同平台上)。
l 解释性:Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。这使得使用Python更加简单。也使得Python程序更加易于移植。
l 面向对象:Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。
l 可扩展性:如果需要一段关键代码运行得更快或者希望某些算法不公开,可以部分程序用C或C++编写,然后在Python程序中使用它们。(胶水语言)
l 可嵌入性:可以把Python嵌入C/C++程序,从而向程序用户提供脚本功能。
l 丰富的库:Python标准库确实很庞大。它可以帮助处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。这被称作Python的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
下面简单介绍下几个关键版本:
l 在1989年圣诞节期间的阿姆斯特丹,吉多为了打发圣诞节的无趣,决心开发一个新的脚本解释编程。之所以选中Python作为编程的名字,是因为他是一个蒙提·派森的飞行马戏团的爱好者。
AI:181-大型语言模型(LLMs)在AIGC中的核心地位_aigc的ll ms-CSDN博客 https://blog.csdn.net/weixin_52908342/article/details/139625891?spm=1001.2100.3001.7377&utm_medium=distribute.pc_feed_blog_category.none-task-blog-classify_tag-4-139625891-null-null.nonecase&depth_1-utm_source=distribute.pc_feed_blog_category.none-task-blog-classify_tag-4-139625891-null-null.nonecase创始人为吉多·范罗苏姆(Guido van Rossum)
l Python 2.0于2000年10月16日发布,主要是实现了完整的垃圾回收,并且支持Unicode。
l Python 3.0于2008年12月3日发布,此版不完全兼容之前的Python源代码。
目前使用最广泛的版本是2.7,最新稳定版本是Python 3.3.1(2013年4月6日)。Django等库开始支持Python3了,也意味着Python3将成为主流。
1.2. Python哲学
图:Python哲学
用过 Python的人,基本上都知道在交互式解释器中输入 import this 就会显示 Tim Peters 的 The Zen of Python。(摘自:《Python之禅》的翻译和解释,http://goo.gl/1joZU)
| The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those! |
翻译和解释
| Python之禅 by Tim Peters 优美胜于丑陋(Python 以编写优美的代码为目标) 明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似) 简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现) 复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁) 扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套) 间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题) 可读性很重要(优美的代码是可读的) 即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上) 不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码) 当存在多种可能,不要尝试去猜测 而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法) 虽然这并不容易,因为你不是 Python 之父(这里的 Dutch 是指 Guido ) 做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量) 如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准) 命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召) |
2. Python在工作中的应用
2.1. 实例1:文件批量处理
如对文件进行批量重命名,将文件夹中所有的文件名的”scroll_1”替换为”scroll_00”。
| 文件批量重命名 |
| import os path = 'C:\\Users\\tylerzhu\\Desktop\\icon' for file in os.listdir(path): if os.path.isfile(os.path.join(path,file))==True: newname = file.replace("scroll_1", "scroll_00") os.rename(os.path.join(path,file),os.path.join(path,newname)) print(file) |
2.2. 实例2:xml与excel互转
Excel转xml
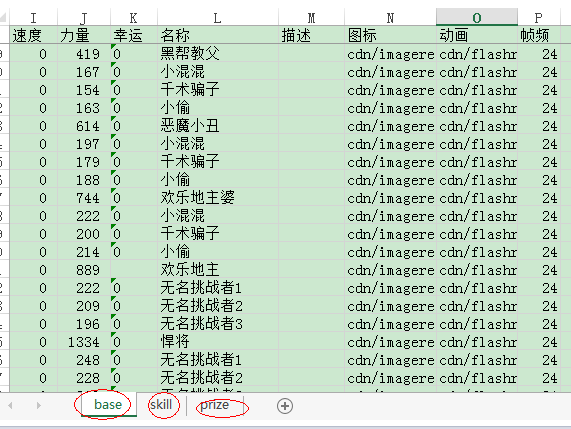
Excel,info_fight_monster.xls包含3个sheet,分别表示怪物的基本信息、技能信息、奖励信息。
XML,info_fight_monster.xml包含怪物的所有信息,格式如下:
| <monster attack="84" attrib="2" classId="20" define="37" desc="" frameRate="24" icon="cdn/imageres/pets/pet_56_20.png" level="4" luck="0" monsterSID="1024" name="被驯服的小火猴" skill="74" speed="0" strength="447" type="0" url="cdn/flashres/pets/pet_20.swf"> <skill skillLevel="2" skillSID="30048"/> <skill skillLevel="2" skillSID="30034"/> <prize desc="" gameID="0" infoType="27" itemSID="80001" itemType="0" level="小火猴的魔法棒" name="" num="1" plusSID="400001" prizeSID="1" type="1"/> monster> |
编写脚本将Excel转换为XML格式。
| Excel转XML |
| #! /usr/bin/env python #coding=utf-8 ''' Created on 2013-3-31 将info_fight_monster.xls转换为XML格式。转换分为以下几步: step1: 读取xml文件,info_fight_monster.xls step2: 解析出怪物基本信息,在base这个sheet里面,并放到一个xml文件中 step3: 解析出怪物的技能信息,并将技能信息插入到对应的xml中 step4:解析出怪物的奖励信息,并插入到对应XML中 step5:保存xml文件 @author: tylerzhu''' from lxml import etree import xlrd3, codecs
attrib = ["monsterSID", "classId", "type", "level", "attrib", # "attack", "skill", "define", "speed", "strength", # "luck", "name", "desc", "icon", "url", "frameRate"];
prize = ["monsterSID", "prizeSID", "type", "infoType", "gameID", "itemType", # "itemSID", "num", "plusSID", "level", "name", "desc", "icon"];
skill = ["monsterSID", "skillSID", "skillLevel"];
info_fight_monster_xml = etree.ElementTree(etree.Element("data"));
def openxls(): excel = xlrd3.open_workbook("xls/info_fight_monster.xls"); base = excel.sheet_by_name("base"); monster = excel.sheet_by_name("skill"); prize = excel.sheet_by_name("prize"); return (base, monster, prize);
def buildMonsterBase(xls): sheet = xls[0]; for row in range(1, sheet.nrows): monsterAttr = {}; for col in range(0, sheet.ncols): if sheet.cell(row, col).value != None and col < len(attrib): monsterAttr[attrib[col]] = sheet.cell(row, col).value; if type(monsterAttr[attrib[col]]) == float: #print(str(round(monsterAttr[attrib[col]]))) monsterAttr[attrib[col]] = str(round(monsterAttr[attrib[col]])); sub = etree.SubElement(info_fight_monster_xml.getroot(), "monster", monsterAttr); sub.tail = "\n" #input()
def buildMonsterSkill(xls): sheet = xls[1]; for row in range(1, sheet.nrows): skillAttr = {}; for col in range(1, sheet.ncols): if sheet.cell(row, col).value != None and col < len(attrib): skillAttr[skill[col]] = sheet.cell(row, col).value; if type(skillAttr[skill[col]]) == float: skillAttr[skill[col]] = str(round(skillAttr[skill[col]])); monsterSID = str(int(sheet.cell(row, 0).value)); monster = info_fight_monster_xml.find("*[@monsterSID='" + monsterSID + "']"); monster.text = ("\n\t"); sub = etree.SubElement(monster, "skill", skillAttr); sub.tail = "\n\t"
def buildMonsterPrize(xls): sheet = xls[2]; for row in range(1, sheet.nrows): prizeAttr = {}; for col in range(1, sheet.ncols): if sheet.cell(row, col).value != None and col < len(attrib): prizeAttr[prize[col]] = sheet.cell(row, col).value; if type(prizeAttr[prize[col]]) == float: prizeAttr[prize[col]] = str(round(prizeAttr[prize[col]])); monsterSID = str(int(sheet.cell(row, 0).value)); monster = info_fight_monster_xml.find("*[@monsterSID='" + monsterSID + "']"); monster.text = ("\n\t"); sub = etree.SubElement(monster, "prize", prizeAttr); sub.tail = "\n\t"
def build(): xls = openxls(); buildMonsterBase(xls); buildMonsterSkill(xls); buildMonsterPrize(xls);
#输出合并之后的配置 ouput = codecs.open('output/info_fight_monster.xml', 'w', 'utf-8'); ouput.write(etree.tounicode(info_fight_monster_xml.getroot())) ouput.close();
if __name__ == '__main__': build(); |
是不是很简单!
Xml转Excel
下面的例子将技能书info_fight_book.xml的数据转换为excel格式,例子只包含一个sheet的,如果有多个sheet同样处理即可。
| XML转Excel |
| #! /usr/bin/env python #encoding=utf-8 ''' Created on 2013-5-6 将技能书info_fight_book。xml转换为excel格式。 例子只包含一个sheet,如果有多个sheet同样处理。 @author: tylerzhu ''' from lxml import etree import xlwt3 as xlwt #写excel标题 #。。。 wb = xlwt.Workbook() ws = wb.add_sheet("技能书")
tree = etree.parse('../xls/info_fight_book.xml') root = tree.getroot() row = 0 col = 0 for item in root: if len(item.attrib) == 0: continue row = row + 1 col = 0 for attr in item.attrib: ws.write(row, col, item.attrib[attr]) col = col + 1
wb.save('../output/技能书.xls') |
2.3. 总结
通过上面例子,发现Python代码有以下特点:
l 第一行是特殊形式的注释:它被称作 组织行 ——源文件的头两个字符是#!,后面跟着一个程序。这行告诉你的Linux/Unix系统当你 执行 你的程序的时候,它应该运行哪个解释器。建议使用这种形式——#!/usr/bin/env python,而不是——#!/usr/bin/python。
l 缩进很重要。Python使用缩进而不是一对花括号来划分语句块。
l 文档字符串,__doc__,没多大用。但是一个好的Python程序,应该要有文档字符串,且一般遵循:“文档字符串的惯例是一个多行字符串,它的首行以大写字母开始,句号结尾。第二行是空行,从第三行开始是详细的描述。”
l python中引入模块后(import)首先就要执行模块的主块,当然模块中可能全是函数。如果要避免使用模块名称:from 模块名 import 符号名,那麽使用该符号名就不用使用模块名+点号+符号名,但是不推荐,容易造成程序不容易读,而且容易出错(特别是在python简洁而简单的语法的基础上)import... as ...起一个别名
l 模块的__name__属性,相当有用,解决了import的缺点,可以实现如果不是运行的本模块而被调用,不调用主块
l 如果你已经厌烦了java、c++的读写文件,那么python会让你重新喜欢上文件读写,python主张解决问题的方案越少越好,写文件就一个f = file(name, 'w'),f.write(...)读文件也一样,f = file(name),f.read或readline,最后close
l ……