flink---window
Window介绍
DataStream:
https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/datastream/operators/windows/
SQL:
https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/table/sql/queries/window-tvf/
1、为什么需要Window?
在实时计算领域, 经常会有如下的需求:
每隔xx时间, 计算最近xx时间的数据,
如:
每隔10min,计算最近24h的热搜词
每隔5s,计算最近1min的股票行情数据
每隔10min,计算最近1h的广告点击量
....
这些实时需求的实现就需要借助窗口!
2、Window有哪些控制属性?
为了完成上面提到的需求, 需要使用窗口来完成, 但是窗口需要有如下的属性才可以
窗口的长度(大小): 决定了要计算最近多长时间的数据
窗口的间隔: 决定了每隔多久计算一次
3、基于时间的滑动和滚动窗口
窗口的长度(大小) > 窗口的间隔 : 如每隔5s, 计算最近10s的数据 【滑动窗口】

窗口的长度(大小) = 窗口的间隔: 如每隔10s,计算最近10s的数据 【滚动窗口】
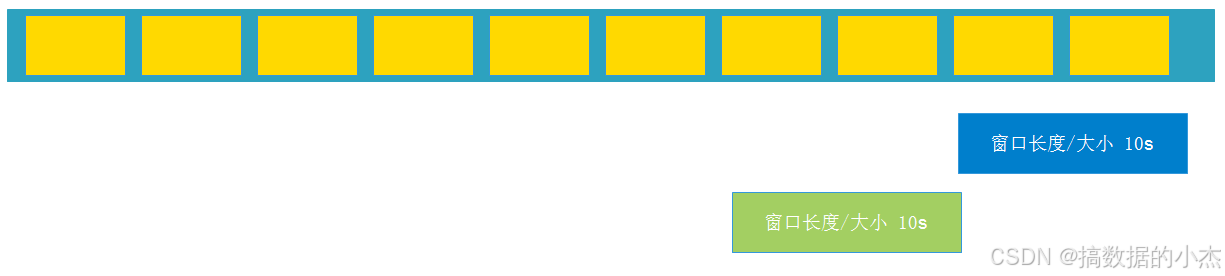
窗口的长度(大小) < 窗口的间隔: 每隔15s,计算最近10s的数据 【没有名字,不用】

滚动窗口 Tumble (DataStream Tumbling Window)
滑动窗口 HOP (DataStream Sliding Window)
累积窗口 Cumulate (DataStream没有)
在实际应用中还会遇到这样一类需求:我们的统计周期可能较长,因此希望中间每隔一段时间就输出一次当前的统计值;与滑动窗口不同的是,在一个统计周期内,我们会多次输出统计值,它们应该是不断叠加累积的。这种特殊的窗口就叫作“累积窗口”(Cumulate Window),它会在一定的统计周期内进行累积计算。累积窗口中有两个核心的参数:最大窗口长度(max window size)和累积步长(step)。所谓的最大窗口长度其实就是我们所说的“统计周期”,最终目的就是统计这段时间内的数据。开始时,创建的第一个窗口大小就是步长 step;之后的每个窗口都会在之前的基础上再扩展 step 的长度,直到达到最大窗口长度。在 SQL 中可以用 CUMULATE()函数来定义,具体如下:
CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOURS, INTERVAL '1' DAYS))这里我们基于时间属性 ts,在表 EventTable 上定义了一个统计周期为 1 天、累积步长为 1 小时的累积窗口。注意第三个参数为步长 step ,第四个参数则是最大窗口长度。
4、processTime Window
/**
*
* {"username":"zs","price":20}
* {"username":"lisi","price":15}
* {"username":"lisi","price":20}
* {"username":"zs","price":20}
* {"username":"zs","price":20}
* {"username":"zs","price":20}
* {"username":"zs","price":20}
*
*/
//窗口触发的条件 1. 系统时间大于等于窗口的结束时间 2. 窗口内有数据
//滚动窗口 TUMBLE(TABLE KafkaTable, DESCRIPTOR(event_time), INTERVAL '10' SECOND)
//滑动窗口 :每隔10秒,计算最近10秒数据。统计每个用户在最近10秒消费的次数和总金额
CREATE TABLE KafkaTable (
`username` STRING,
`price` INT,
`event_time` as proctime() -- 计算列
) WITH (
'connector' = 'kafka',
'topic' = 'topic1',
'properties.bootstrap.servers' = 'hadoop11:9092,hadoop12:9092,hadoop13:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
select username,window_start,window_end,count(*) cnt,sum(price) total_price
from table(TUMBLE(TABLE KafkaTable, DESCRIPTOR(event_time), INTERVAL '10' SECOND))
group by username,window_start,window_end;
//滑动窗口:每隔30秒,计算最近1分钟每隔用户消费次数和消费总金额。
CREATE TABLE KafkaTable (
`username` STRING,
`price` INT,
`event_time` as proctime() -- 计算列
) WITH (
'connector' = 'kafka',
'topic' = 'topic1',
'properties.bootstrap.servers' = 'hadoop11:9092,hadoop12:9092,hadoop13:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
select username,window_start,window_end,count(*) cnt,sum(price) total_price
from table(HOP(TABLE KafkaTable, DESCRIPTOR(event_time), INTERVAL '30' SECOND, INTERVAL '60' SECOND))
group by username,window_start,window_end;