3.1 全局存储带宽与合并访问 -- Global Memory(DRAM) bandwidth and memory coalesce
全局存储带宽(DRAM)
全局内存是动态随机访问的方式访问内存.我们希望访问DRAM的时候非常快,实际情况是DRAM中出来的数据非常非常慢,这就好比,理想状态是泄洪,水倾巢而出,气势宏伟,实际取水却像是用吸管在喝饮料,速度非常慢.
通常来看,我们会通过优化算法减少DRAM的访问次数.
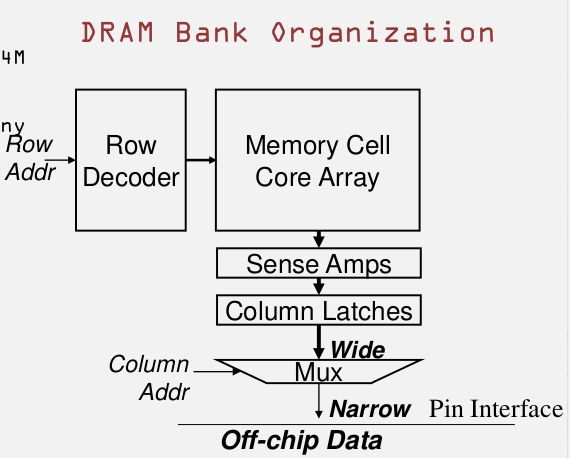
由上图可以看出,用户访问需要的Address会被分成Row addr和Column address, 通过row decoder -> Core Array -> Sense Amps -> Column Latches ->到这里会非常宽,但是到-> Mux 会变得非常窄,然后通过off-chip data bus 给到处理器 .这就是DRAM bank的组织框架.
DRAM 中从core array中读取一个cell是非常慢的,cell是指一个存储单元.
• DDR: Core speed = 1⁄2 interface speed
• DDR2/GDDR3: Core speed = 1⁄4 interface
speed
• DDR3/GDDR4: Core speed = 1⁄8 interface
speed
• ... likely to be worse in the future
随着时间的推移,市场上DDR的容量越来越大,但是访问速度却是越来越慢.
为什么core array中读取非常慢,如下图:
如下图:
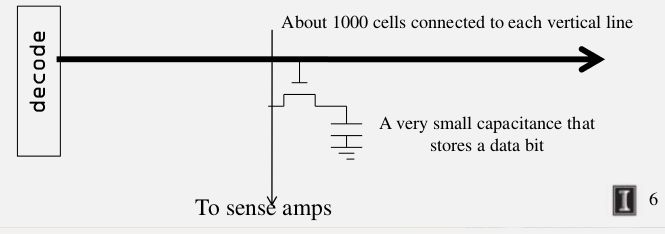
假设我们有1000个cells,在水平方向(因为是行吗)是很长的,当访问其中的一个cell,其实是访问在访问某一个bit,当为1时表示存在,0表示不存在.而这个bit是存储在一个很小的电容里面,当想这个电容的晶体管里面充电,这个值是1,不充电则是0. 这个在纵向会连接到一个检测放大器(sense amplifier),纵向线是一个非常缓慢的过程,记得这个即可.
DRAM Bursting
对于DDR{2,3} cores 核心的频率是接口频率的1/N. 为了提高访问的速度,DRAM中提供更多的端口数目(lanes),类似收费站提供很多的收费口来减轻拥堵问题一样.虽然单一时间慢,但是同时执行的多,所以总的情况会变快.
DDR2/GDDR3: buffer的宽度是借口宽度的4倍
为了降低访问的次数,当处理器访问一段数据时,实际上传递给处理器的是围绕这一段数据的一个更大的数据.这个就是dram burst 设计.所以一个时钟周期访问的数据,其实是把这个之后的几个时钟周期也访问的数据一起取出来,如果CPU不需要这些多余的数据,其实就可以说是浪费了,所以为了充分利用DRAM的这个特性.
上面提到的增加更多的接口数目说的是DRAM bank.
例子:
nVidia GTX280 GPU的极限带宽是141.7GB/s
DDR3的接口速度是1.1GHz, core speed是276Mhz, 是接口速度的1/4.
对于一个64bit的接口,时钟应该是2倍,因为在上升沿和下降沿都由数据传输.
64bit/8 = 8Bytes.
8*2 *1.1 = 17.6GB/s 这个远远达不到141.7.
141.7/17.6 = 8 memory channels . 这样可以达到这个速度.
内存合并访问
为了利用dram burst的特性,所以我们就有了合并内存访问.通过合并内存访问的次数提高访问memory的效率.
GPU的存储是row-major,是以行来组织数据的.

对于GPU来说,由于thread是异步执行的.下面这两种访问模式一种是合并访问的,利用到DRAM,一种是非合并访问:
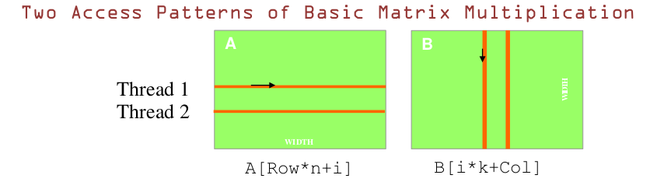
B是合并访问, A不是.B是以纵向的访问方向,A是横向的访问方向.
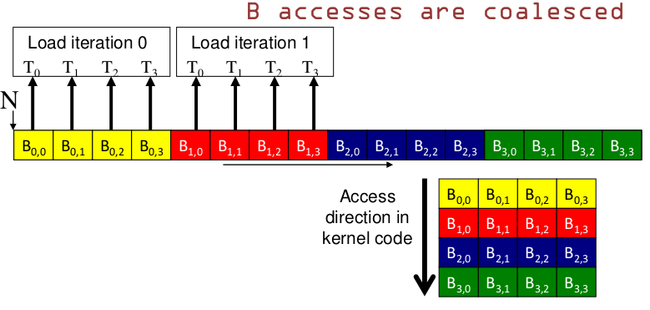
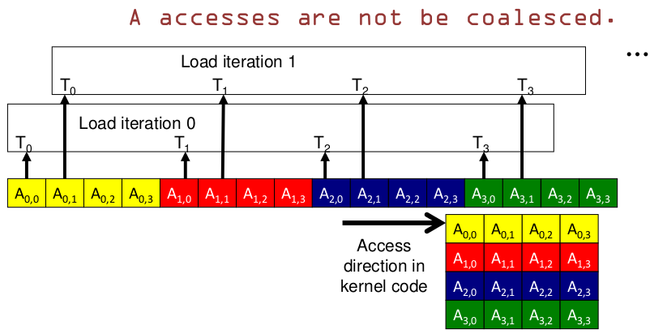
所以总结一条规则是:
GPU纵向访问内存可以实现合并访问的效果.