Redis7_16 高阶篇 第七章 Redis中的缓存预热/缓存雪崩/缓存击穿/缓存穿透问题详解
大家好! 欢迎来到“孤尘”的Java世界!
️感谢认可!事不宜迟,一起尽情地畅享编程之旅吧!
目录
面试题(文末有答案)
概念(是什么?)
缓存预热
缓存雪崩
缓存击穿
缓存穿透
缓存预热
定义
怎么做?
实现
缓存雪崩
定义
引起缓存雪崩的原因
规避/解决方案
1. Redis中key设置为永不过期或过期时间错开
2. Redis缓存集群实现高可用
3. 多缓存结合预防雪崩
4. 服务降级
5. 使用云服务
缓存击穿
定义
引起缓存击穿的原因
规避/解决方案
方案一 热点数据永不过期
方案二 使用双检加锁策略
Redis7_12 高阶篇 第三章 Redis作为缓存如何实现双写一致性?如何选择更新策略?https://blog.csdn.net/qq_33168558/article/details/139899984
方案三 使用从缓存实现差异失效时间
缓存穿透
定义
引起缓存穿透的原因
规避/解决方案
缓存空结果
使用布隆过滤器
代码实现
总结
面试题(带答案)
1. 缓存预热是什么?
2. 缓存雪崩是什么?
3. 缓存击穿是什么?
4. 缓存穿透是什么?
规避/解决方案
缓存预热
缓存雪崩
缓存击穿
缓存穿透
面试题(文末有答案)
缓存预热、雪崩、穿透、击穿分别是什么?你遇到过那几个情况?
缓存预热你是怎么做的?
如何避免或者减少缓存雪崩?
穿透和击穿有什么区别?他两是一个意思还是截然不同?
穿透和击穿你有什么解决方案?如何避免?
假如出现了缓存不一致,你有哪些修补方案?
概念(是什么?)
缓存预热
缓存预热是指系统启动前,提前将热点数据加载到缓存中的过程。
是为了避免系统启动初期因缓存未命中导致直接访问数据库。
缓存雪崩
缓存雪崩是指在某一个时间点,由于大量的缓存数据同时失效,导致所有的请求都落到数据库上,从而引起数据库访问压力骤增,甚至导致数据库崩溃的现象。
缓存击穿
缓存击穿是指一个热点的key在缓存中失效的瞬间,同时有大量的请求访问这个key,这时这些请求都会落到数据库上,导致数据库短时间内承受巨大压力的现象。
缓存穿透
缓存穿透是指查询一个数据库中不存在的数据,由于缓存不会缓存这样的查询结果,导致每次查询都要访问数据库,如果有大量这样的查询,会对数据库造成不必要的压力。
缓存预热
定义
缓存预热是指系统启动前,提前将热点数据加载到缓存中的过程。本质上,它是为了避免系统启动初期因缓存未命中导致直接访问数据库,从而引起数据库压力过大的问题。通过预热,可以确保系统启动后立即能够提供高效的访问速度。
怎么做?
利用@PostConstruct注解,使得被该注解标识的方法会在类的构造函数执行完毕后,且完成了依赖对象的注入之后被自动调用,这是完成一些初始化工作的常用方式。
实现
package com.atguigu.redis7.filter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
/**
* Description:布隆过滤器白名单初始化工具类,一开始就设置一部分数据为白名单所有,
* 白名单业务默认规定:布隆过滤器有,redis也有。
* Author: fy
* Date: 2024/4/20 21:11
*/
@Component
@Slf4j
public class BloomFilterInit {
@Autowired
private RedisTemplate redisTemplate;
/*
布隆过滤器初始化加载工具
初始化一些白名单的数据。
*/
@PostConstruct
public void init() {
//1.白名单数据的key
String key = "customer:12";
//2.计算哈希,避免负数,取绝对值
long hashValue = Math.abs(key.hashCode());
//3.获取hash值对应的bit位
long bitIndex = (long) (hashValue % (Math.pow(2, 32)));
log.info("key:{},hashValue:{},bitIndex:{}", key, hashValue, bitIndex);
//2024-04-20 21:37:56.713 [main] INFO com.atguigu.redis7.filter.BloomFilterInit- keycustomer:12,hashValue:1772098755,bitIndex:1772098755
//4.设置redis中的bitmap对应位为1
redisTemplate.opsForValue().setBit("whitelistCustomer", bitIndex, true);
}
}
缓存雪崩
定义
缓存雪崩是指在某一个时间点,由于大量的缓存数据同时失效,导致所有的请求都落到数据库上,从而引起数据库访问压力骤增,甚至导致数据库崩溃的现象。本质上,缓存雪崩是由缓存同步失效引起的大规模数据库访问压力问题。
引起缓存雪崩的原因
- 硬件原因 Redis主机宕机(运维方面)
- 大量的key同一时间失效
规避/解决方案
1. Redis中key设置为永不过期或过期时间错开
- 永不过期:对于一些不经常变化的数据,可以设置为永不过期,避免缓存失效带来的问题。
- 过期时间错开:对于需要设置过期时间的数据,可以错开不同key的过期时间,避免大量key同时失效。
2. Redis缓存集群实现高可用
- 主从+哨兵:通过主从复制和哨兵机制,保证Redis的高可用性。
- Redis Cluster:使用Redis Cluster来实现分布式缓存,提升系统的可用性和扩展性。
- 开启Redis持久化机制(AOF/RDB):尽快恢复缓存集群,避免数据丢失。
3. 多缓存结合预防雪崩
- Ehcache本地缓存 + Redis缓存:结合使用本地缓存(如Ehcache)和分布式缓存(如Redis),减少对单一缓存的依赖。
4. 服务降级
- Hystrix或者阿里Sentinel限流&降级:使用熔断器(如Hystrix)或限流降级工具(如阿里Sentinel)来保护系统,防止缓存雪崩导致的系统崩溃。
5. 使用云服务
- 阿里云-云数据库Redis版:使用云服务提供的Redis解决方案,享受其高可用性和自动化运维能力。
- 链接: 阿里云-云数据库Redis版
缓存击穿
定义
缓存击穿是指某些热点数据在缓存中失效后,由于大量并发请求同时访问这些数据,导致这些请求直接落到数据库上,从而引起数据库访问压力骤增的现象。与缓存雪崩不同,缓存击穿通常是针对某个特定的热点数据。
引起缓存击穿的原因
- 热点数据失效:某些访问频率极高的数据在缓存中失效,导致大量请求直接访问数据库。
- 缓存设置不当:缓存过期时间设置不合理,导致热点数据频繁失效。
规避/解决方案
方案一 热点数据永不过期
对于访问频率极高的热点数据,可以设置为永不过期,避免缓存失效带来的问题。
方案二 使用双检加锁策略
热点key开发人员是要做到心中有数的,尤其是他们的过期时间,我们常常会在key自动过期后及时更新缓存的值,否则一定会打垮mysql,更新时有新值我们就加新的值,没有可能一般会让他返回空值,以此提示用户。
双检加锁策略在高阶篇第三章有讲解
Redis7_12 高阶篇 第三章 Redis作为缓存如何实现双写一致性?如何选择更新策略? https://blog.csdn.net/qq_33168558/article/details/139899984
https://blog.csdn.net/qq_33168558/article/details/139899984
方案三 使用从缓存实现差异失效时间
开辟一个从缓存,存放热点key
在自动更新key的过程中,我们总是先更新从缓存,在更新主缓存。
查询时,我们总是先让用户去从缓存查找,查不到再去找主缓存拿旧值。
这样既能保证从key失效-key更新到redis这个过程,用户的访问不会打到mysql,还能保证数据正常的自动更新。
/*
缓存击穿的解决方案一:双捡加锁
此方法是方案二:差异失效 也就是再做一个从缓存(B缓存)当主缓存(A缓存)的key由于失效访问不到时,就去访问
B缓存的key,[因为B缓存的过期时间设置的比A缓存的过期时间要久],所以一般当A过期时,会进行key的更新,如果
更新期间有人访问了key,先去查A,如果还没更新完,那就去B缓存拿旧的值,直到把B缓存更新完成,再更新A缓存的key。
一定要注意顺序.
更新时 先更新从缓存,在更新主缓存
查询时 先去查询主缓存,再去查询从缓存
*/
@PostConstruct
public void initJHSAB(){
log.info("启动AB定时器计划任务淘宝聚划算功能模拟.........."+ DateUtil.now());
new Thread(() -> {
//模拟定时器,定时把数据库的特价商品,刷新到redis中
while (true){
//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
List list=this.getProductsFromMysql();
//先更新B缓存,设置B的key过期时间比A的key多10秒,这十秒时间就是用来更新迭代key的,一般十秒时间就足够了
this.redisTemplate.delete(JHS_KEY_B);
this.redisTemplate.opsForList().leftPushAll(JHS_KEY_B,list);
this.redisTemplate.expire(JHS_KEY_B,86410L,TimeUnit.SECONDS);
//再更新A缓存
this.redisTemplate.delete(JHS_KEY_A);
this.redisTemplate.opsForList().leftPushAll(JHS_KEY_A,list);
this.redisTemplate.expire(JHS_KEY_A,86400L,TimeUnit.DAYS);
//间隔一分钟 执行一遍
try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
log.info("runJhs定时刷新双缓存AB两层..............");
}
},"t1").start();
} 缓存穿透
定义
缓存穿透是指大量请求访问缓存中不存在的数据(通常是非法请求或恶意攻击),这些请求直接落到数据库上,导致数据库访问压力骤增的现象。缓存穿透通常是由于缓存和数据库中都不存在这些数据。
引起缓存穿透的原因
- 恶意攻击:大量请求访问不存在的数据,绕过缓存直接访问数据库。
- 缓存设置不当:缓存未对不存在的数据进行处理,导致每次请求都直接访问数据库。
规避/解决方案
缓存空结果
对于查询结果为空的数据,也将其缓存起来,设置一个较短的过期时间,避免频繁访问数据库。
// 示例代码
Object result = cache.get(key);
if (result == null) {
result = database.load(key);
if (result == null) {
cache.put(key, new NullObject(), shortExpiryTime);
} else {
cache.put(key, result);
}
}
使用布隆过滤器
在缓存前增加布隆过滤器,用于快速判断请求的数据是否存在,过滤掉不存在的数据请求,减少对数据库的访问。
代码实现
注意要引入guava的依赖
com.google.guava
guava
23.0
Service 模拟插入100w条数据 然后再去该过滤器判断是否存在另外10w不存在的数据
package com.atguigu.redis7.service;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
/**
* Description: 测试一下guavaBloomFilter的误判率,
* 插入1-1000000的数字数据,再判断1000001-1100000是否在该过滤器中
* Author: fy
* Date: 2024/4/20 22:59
*/
@Service
@Slf4j
public class GuavaBloomFilterService {
public static final int _1W = 10000;
//布隆过滤器里预计要插入多少数据
public static int size = 100 * _1W;
//误判率,它越小误判的个数也就越少(思考,是不是可以设置的无限小,没有误判岂不更好)
//不带%的值,0.03表示误判率是3%
//fpp the desired [false positive probability]
public static double fpp = 0.03;
// 构建布隆过滤器
private static BloomFilter bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size,fpp);
public void guavaBloomFilter(){
//1 先往布隆过滤器里面插入100万的样本数据
for (int i = 1; i <=size; i++) {
bloomFilter.put(i);
}
//故意取10万个不在过滤器里的值(也就是不合法的数据),看看有多少个会被认为在过滤器里
List list = new ArrayList<>(10 * _1W);
for (int i = size+1; i <= size + (10 *_1W); i++) {
if (bloomFilter.mightContain(i)) {
log.info("被误判了:{}",i);
list.add(i);
}
}
log.info("误判的总数量::{}",list.size());
}
}
测试发现,和我们设置的误判率是吻合的,可以据此将返回为false的数据,直接挡在redis前面,这样的请求连redis都无法到达,对于整个系统来说,能够减轻非常多的压力。
package com.atguigu.redis7.controller;
import com.atguigu.redis7.service.GuavaBloomFilterService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
/**
* Description:
*
* 测试结果
* 2024-04-20 23:04:17.264 [http-nio-7777-exec-3] INFO
* com.atguigu.redis7.service.GuavaBloomFilterService- 误判的总数量::3033
* 查看了10w个布隆过滤器不存在的数据,误判的数据位3033个
* 3033/100000=0.03033≈0.03
* 印证了前面我们再service里设定的误判率 0.03
*
* Author: fy
* Date: 2024/4/20 23:02
*/
@RestController
@Slf4j
@Api("google工具Guava处理布隆过滤器")
public class GuavaBloomFilterController {
@Autowired
private GuavaBloomFilterService guavaBloomFilterService;
@ApiOperation("guava布隆过滤器插入100万样本数据后,测试额外10W是否存在于过滤器")
@RequestMapping(value = "/guavafilter",method = RequestMethod.GET)
public void guavaBloomFilter()
{
guavaBloomFilterService.guavaBloomFilter();
}
}
总结
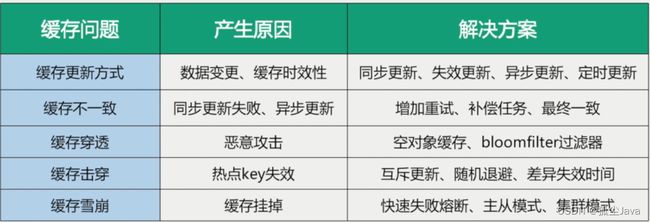
面试题(带答案)
1. 缓存预热是什么?
缓存预热是指系统启动前,提前将热点数据加载到缓存中的过程。本质上,它是为了避免系统启动初期因缓存未命中导致直接访问数据库,从而引起数据库压力过大的问题。通过预热,可以确保系统启动后立即能够提供高效的访问速度。
2. 缓存雪崩是什么?
缓存雪崩是指在某一个时间点,由于大量的缓存数据同时失效,导致所有的请求都落到数据库上,从而引起数据库访问压力骤增,甚至导致数据库崩溃的现象。本质上,缓存雪崩是由缓存同步失效引起的大规模数据库访问压力问题。
3. 缓存击穿是什么?
缓存击穿是指一个热点的key在缓存中失效的瞬间,同时有大量的请求访问这个key,这时这些请求都会落到数据库上,导致数据库短时间内承受巨大压力的现象。与缓存雪崩不同,缓存击穿通常是针对某个特定的热点数据。
4. 缓存穿透是什么?
缓存穿透是指查询一个数据库中不存在的数据,由于缓存不会缓存这样的查询结果,导致每次查询都要访问数据库,如果有大量这样的查询,会对数据库造成不必要的压力。
规避/解决方案
缓存预热
- 利用@PostConstruct注解:在系统启动时,自动调用预热方法,将热点数据加载到缓存中。
@PostConstruct public void init() { // 加载热点数据到缓存 }缓存雪崩
- Redis中key设置为永不过期或过期时间错开:
- Redis缓存集群实现高可用:
- 多缓存结合预防雪崩:
- 服务降级:
- 使用云服务:
缓存击穿
- 热点数据永不过期:
- 使用互斥锁:
- 提前预热缓存:
- 使用高效的缓存更新策略:
缓存穿透
- 缓存空结果:
- 使用布隆过滤器:
感谢大家的陪伴,旅程因你们而精彩!如果文章对你有帮助,我会感到很荣幸!
欢迎您访问主页:孤尘Java-CSDN博客
再见啦,朋友们!保持好奇,保持热情!