数据结构初阶(C语言)-二叉树-顺序表建堆
一,堆的概念与结构
如果有⼀个关键码的集合,把它的所有元素按完全⼆叉树的顺序存储方式存储,在⼀个⼀维数组中,并满足:![]() ,i=0,1,2...则称为小堆(或⼤堆)。将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。
,i=0,1,2...则称为小堆(或⼤堆)。将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。

堆具有以下性质:
1.堆中某个结点的值总是不大于或不小于其父结点的值
2.堆总是⼀棵完全二叉树。
这里我们说一下完全二叉树的性质:
对于具有 n 个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有结点从0 开始编号,则对于序号为 i 的结点有:
1.若 i>0 ,i 位置结点的双亲序号:(i-1)/2 ,i=0,i 为根结点编号,无双亲结点。
2.若 2i+1
3.若 2i+2
二,堆的实现及
2.1堆的定义
堆底层结构为数组,因此定义堆的结构为:
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;由于堆在本质上是基于顺序表结构去实现的,所以接下来我们所介绍的实现内容重点介绍与顺序表的不同的地方,相同部分则直接给出代码。
2.2堆的初始化函数HeapInit与堆的空间容量检查函数HpCapacheck
void HeapInit(HP* php)
{
assert(php);
php->arr = NULL;
php->capacity = php->size = 0;
}
void HpCapacheck(HP* hp)
{
if (hp->capacity == hp->size)
{
int exchange = hp->capacity == 0 ? 4 : hp->capacity * 2;
HeapDataType* tmp = (HeapDataType*)realloc(hp->arr, sizeof(HeapDataType)* exchange);
if (tmp == NULL)
{
perror("realloc:tmp");
exit(1);
}
hp->arr = tmp;
hp->capacity = exchange;
}
}2.3交换结点数据函数Swap
void Swap(HeapDataType* x, HeapDataType* y)
{
HeapDataType tmp = *x;
*x = *y;
*y = tmp;
}2.4检查堆结构是否为空函数HeapEmpty
bool HeapEmpty(HP* hp)
{
assert(hp);
return (hp->size == 0);
}2.5向队中插入数据函数HeapPush
void HeapPush(HP* hp, HeapDataType x)
{
assert(hp);
HpCapacheck(hp);
hp->arr[hp->size] = x;
AdjustUpHp(hp, hp->size);
hp->size++;
}前面的检查空间函数这里我们需要引用,同时判断传过来的指针是否为有效指针,但这时由于我们的堆是一个完全二叉树,对于我们的顺序表插入数据一般是从尾部插入,所以我们这里就需要用到向上调整法来调整我们的新数据使源数据的堆结构不被破坏:
2.5.1向上调整法
void AdjustUpHp(HP* hp, int child)
{
int parents = (child - 1) / 2;
while (child > 0)
{
if (hp->arr[parents] > hp->arr[child])
{
Swap(&hp->arr[parents], &hp->arr[child]);
}
else
{
break;
}
child = parents;
parents = (child - 1) / 2;
}
}这里我们的向上调整法主要借助了完全二叉树的性质,由于我们新插入的数据是从尾部插入的,那么他的数组对应下标即为size-1,我们是在push之后对size进行的++,所以这里传过去的size即为当前新数据的下标,此时(size-1)/2为当前结点对应的父结点,我们这里建的是小堆,所以于其父结点相比小了便要交换数据,但由于我们先前的堆已经是小堆了,所以只要这里孩子比父大,我们就直接跳出循环,否则继续向上调整。
2.6删除堆中数据函数HeapPop
void HeapPop(HP* hp)
{
assert(hp && !HeapEmpty(hp));
Swap(&hp->arr[hp->size - 1], &hp->arr[0]);
hp->size--;
AdjustDownHp(hp,0);
}对堆的数据删除是从堆的最顶端的数据开始的,所以我们为了最大程度上减轻删除数据后对堆的影响,这里我们可以直接将根结点的数据与堆的最后一个数据交换,这样在尾删就会最小程度的影响堆结构。当然,新的数据到最顶端后,还需要进行调整,恢复堆的结构:
2.6.1向下调整法
void AdjustDownHp(HP* hp, int parents)
{
int child = parents * 2 + 1;
while (child < hp->size)
{
if (child + 1 < hp->size && hp->arr[child] > hp->arr[child + 1])
{
child++;
}
if (hp->arr[child] < hp->arr[parents])
{
Swap(&hp->arr[child], &hp->arr[parents]);
parents = child;
child = parents * 2 + 1;
}
else
{
break;
}
}
}由于我们最开始是从父结点(根结点)开始调整的,所以为了确保不越界访问,我们需要先确认当前父结点是否有右孩子,如果有,他与左孩子相比谁更小就让谁与父结点比较。最后如果两个IF条件均不成立,我们则跳出循环,这时我们的堆结构就恢复完毕了。
2.7向上/向下调整法直接建堆
像上面添加删除的去建堆,有些许麻烦,但如果我们直接给一个现成的数组,并将其整理为堆,或许这样建堆会更简单,这里我们就需要用到我们上面介绍的向上向下建堆法。
2.7.1向下建堆法及其时间复杂度的推导
void adjustdownarr(int* arr, int parents, int size)
{
int child = parents * 2 + 1;
while(child < size)
{
if (child + 1 < size && arr[child] > arr[child + 1])
{
child++;
}
if (arr[child] < arr[parents])
{
Swap(&arr[child], &arr[parents]);
parents = child;
child = parents * 2 + 1;
}
else
{
break;
}
}
}先说向下调整建堆,这里我们这里传过去的parents为根结点,而size便是有效数据的总个数,这也是由我们向下调整法的特性而实现的,毕竟对每个结点进行向下调整后,它所附属的子树及其本身的所有数据会被调整,最后最小的值被放入当前树的根结点中。直到调整到最后一个子树时便可以成堆。
这时我们来计算向下建堆的时间复杂度:先分析

那么我们需要移动的总步数为:(使用错位相减法计算)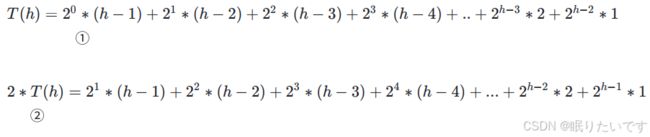
(2)-(1)化简可得:
![]()
据二叉树的性质可得:
![]()
所以我们最终计算出T (n) = n - log2 (n + 1) ≈ n,即向下建堆法的时间复杂度为O(N)。
2.7.2向上建堆法及其时间复杂度
这里与向下建堆法的思想一致,但向上建堆是先从各个子树开始进行调整,到最后将所有的子树调整完毕得到成型的堆,向上建堆法的代码和时间复杂度的推导这里就不给出了,读者可以自行推导,最终求出来的时间复杂度为O(n ∗ log2 n)。。
可见向上建堆法时间复杂度上劣于向下建堆法,由于我们实际上现在的电脑内存基本都很大,所以我们在写代码时,更重要的是时间复杂度而不是以前二者均需了。下篇文章我们介绍链式结构堆的相关内容,去体会下递归的暴力美学。