Html Agility Pack ── 一个分析HTML的工具
标签:开源
.NET 框架类库本身没有提供工具分析HTML,以前常用的做法是用正则表达式,或者浏览器控件,或者MSHTML组件,甚至SgmlReader。SgmlReader可以将HTML转化成XML,然后你就可以使用System.Xml命名空间下的类对文件进行查询。
CodePlex上有一个Html Agility Pack项目,是原生的.NET项目,不依赖MSHTML或者ActiveX/COM 对象。其中的HtmlDocument可以加载任何HTML文件(即使该文件是不well-formed的HTML),然后允许你使用类似于System.Xml的对象模型对文件进行查询。
官网地址:www.codeplex.com/htmlagilitypack
例如:
HtmlDocument doc = new HtmlDocument();
doc.Load("file.htm");
foreach(HtmlNode link in doc.DocumentElement.SelectNodes("//a[@href"])
{
HtmlAttribute att = link["href"];
att.Value = FixLink(att);
}
doc.Save("file.htm");
解析 HTML:Web 开发人员心中的痛
自从Web 应用程式自1993 年W3C 设立以来就开始发展,而且HTML 也历经了数个版本的演化(1.0 – 2.0 – 3.0 – 3.2 – 4.0 – 4.01),现在也已经成为Web网页或应用程式的最基础,想要学习如何设计Web 网页或开发Web 应用程式,这已经是绝对必须要学的东西了,就算是方便的控制项充斥(例如ASP.NET),但HTML 仍然有学习它的必要性,因此如果不会HTML,就等于没学过Web 网页般。
拜HTML 与Web 浏览器蓬勃发展之赐,各式各样的应用都在网路上迅速发展,举凡电子商务、企业入口、线上下单、企业间协同应用等,乃至于社群、个人化、Web 2.0 等商务与组织运用等能力,而在资讯爆炸的时代,很多资讯整合的应用也随之出炉,而这些资讯整合的应用程式都会连接到不同的网站下载其资讯,并且在重重的HTML 中剖析出想要的资料(例如每股价格、涨跌幅、成交量等)。
但是HTML 本身并不是一个结构严谨的语言,它允许标签(tag)可以在不close 的情况下继续使用。这也是因为浏览器设计的高容错性(Fault Tolerance)所致,如此一来,想要依照规则来剖析HTML 文件几乎变得不可能,而且对方的网站的HTML 结构也可能会随时变化,在这种情况下,剖析HTML 变得非常辛苦,虽然W3C 有另外推展XHTML(遵守XML 严谨格式的HTML),但使用它来设计网页的案例仍为少数,大多数的网站仍然是使用HTML。因此我们会需要一个工具,能够有方法快速的解析HTML 以取出我们需要的资料。
传统解析 HTML 的方法
大家都知道,HTML 本身其实只是一个HTML 标记的字串而已,因此一般说到要解析HTML,第一个会想到的大概就是字串比对(string comparison),自己针对HTML 的结构写一个pattern,然后由函式去做逐一的比对,例如:
- string pattern = "<td id='stockPrice'>";
- html.IndexOf(pattern);
不过传统的字串比对效能太差,也没有一个规则性,因而才发展出规则运算式(Regular Expression)技术,例如下列这样的语法:
- </?\w+((\s+\w+(\s*=\s*(?:".*?"|'.*?'|[^'">\s]+))?)+\s*|\s*)/?>
但Regular Expression 的学习曲线很高,若要使用它来解析HTML,并且再加以客制化(Customization)的话,对于一般开发人员来说,实在没有什么亲和力。
HTML 还有一个特色,就是它是具阶层性(Hierarchy)的,因此浏览器在解译它的时候都会以文件树(document tree)的方式,再用递回(recursive)的方法来处理它,但Regular Expression 没有支援阶层性的剖析,而最接近阶层剖析又好用的工具,莫过于XML Parser 了,它的DOM 以及XPath 的特性,都可以让解析XML 的工作变得轻松,然而XML Parser 无法读取一般的HTML(XHTML 可以),因为一般的HTML 是结构松散的类型,XML Parser 会在读入时检查语法结构是否完整(也就是Well-known 的结构),若读入的是结构松散的内容的话会掷出例外讯息,因此无法直接使用XML Parser 来辅助。
不过,现在已经有人发展出可以在HTML 上面使用类似于XPath 的方式来存取松散结构的HTML 的工具,并且在Codeplex 上以开放原始码的方式公开给外界使用,这个工具就是本文所要介绍的HTML Agility Pack。
HTML Agility Pack 简介
HTML Agility Pack 是由法国的一位软体架构师Simon Mourier 所发展,并且由DarthObiwan 以及Jessynoo 辅助开发出来的一个软体工具,它可以让剖析松散格式HTML 的工作就像剖析XML 一样简单,它也有类似于System.Xml 命名空间中的XML DOM 的许多类别,除了可以使用阶层的方式存取HTML 以外,它也支援使用XPath 的方式来搜寻HTML,这会较以往使用文字比对或是Regular Expression 的比对方式来得更明确,例如:
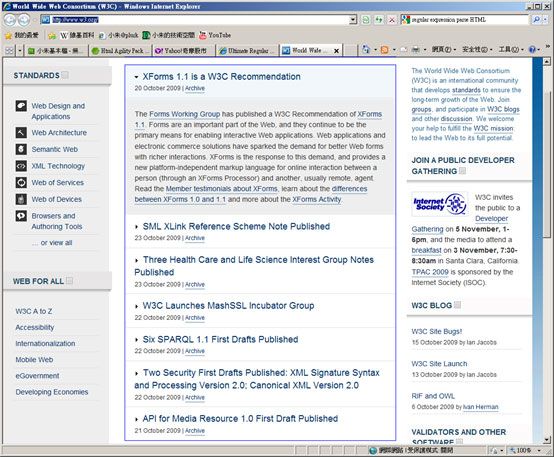
上图中以蓝色方框框住的是W3C 的最新消息公告区,而它的HTML 阶层树是这个样子:
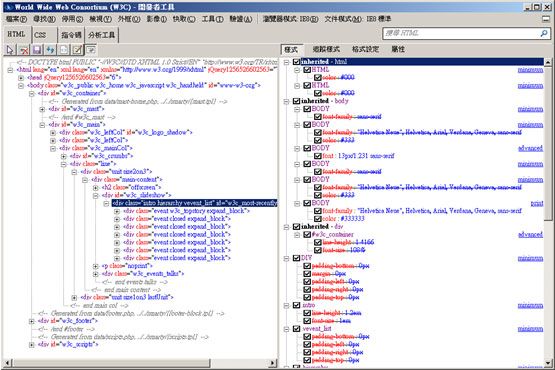
以往要使用Regular Expression 剖析时可能要走很多步骤(Match 会回传很多资料,除非写的够精准),才会到达方框所在的位置,但使用HTML Agility Pack 元件时,我们能用这样的语法:
xpath:
- /html[1]/body[1]/div[1]/div[2]/div[3]/div[2]/div[1]/div[1]/div[1]
就到达我们想要的地点,这个语法和XPath 相当类似,对于熟悉XPath 或是DOM 的开发人员会比较有利。 HTML Agility Pack 元件的类别阶层和XML DOM Parser 其实蛮像的,若先前有用过XML DOM 的开发人员会觉得很熟悉:
如上面的说明,我们可以撰写这样的程式码来读取W3C 首页公布的最新消息的清单:
- using HtmlAgilityPack;
- public static void Main(string[] args)
- {
- HtmlWeb webClient = new HtmlWeb();
- HtmlDocument doc = webClient.Load("http://www.w3.org/");
- HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("/html[1]/body[1]/div[1]/div[2]/div[3]/div[2]/div[1]/div[1]/div[1]/div");
- foreach (HtmlNode node in nodes)
- {
- Console.WriteLine(node.InnerText.Trim());
- }
- doc = null;
- nodes = null;
- webClient = null;
- Console.WriteLine("Completed.");
- Console.ReadLine();
- }
读取W3C 首页中最新公告的程式码(专案类型:主控台应用程式)
HTML Agility Pack 只相依于.NET Framework,因此不需要其他各种HTML 剖析器的任何元件,只要有.NET Framework 即可执行。
使用方式
若要使用HTML Agility Pack 元件,可先上Codeplex 的HTML Agility Pack 网站下载二进位档(同时也提供原始程式码、说明档以及HAP Explorer 工具程式可下载),并解压缩后,在专案加入对HtmlAgilityPack .dll 的参考:
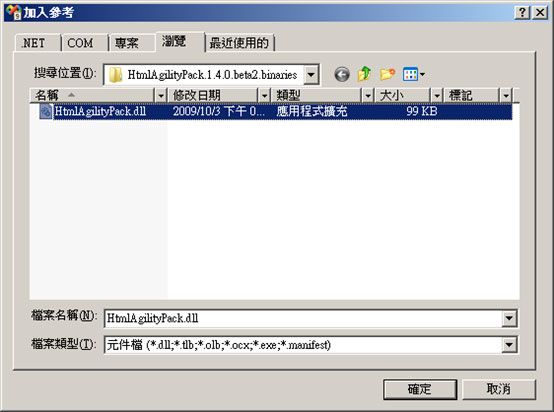
然后在程式宣告加入:
- using HtmlAgilityPack;
即可在程式中使用HTML Agility Pack 的功能。
应用范例:解析Yahoo 奇摩股市的各档股票资讯。
笔者认为这应该是很多撰写股市资料收集的应用程式的主要标的,若是要由证交所取得资料授权可能要一笔费用,但是由Yahoo 奇摩股市中解析并读取资料是免费的,只是Yahoo 奇摩股市的HTML 结构长久以来都是松散型的,不像W3C 是XHTML(之前使用HTML Agility Pack 读取是要展示它的功能),所以要剖析它需要花不少脑力,现在我们可以使用HTML Agility Pack 来将这个工作简化。
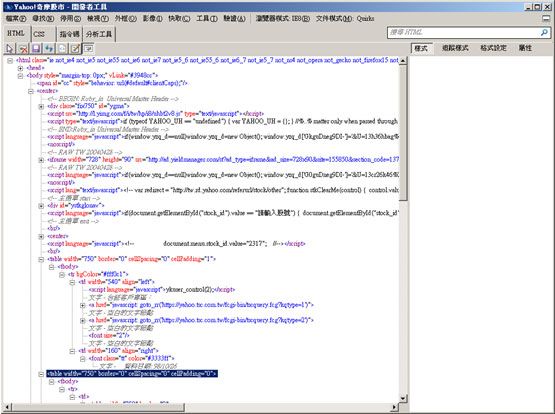
在Yahoo 奇摩股市中,一个个股的资讯是这样:

而它的 HTML 结构则是:

因此如果我们要使用XPath 来解读它,则需要先使用下列XPath 先到达上层table 的位置,再往下取得HTML 中的内容:
- /html[1]/body[1]/center[1]/table[2]/tr[1]/td[1]/table[1]
因此我们可以撰写下列的程式码:
- using System.Net;
- using System.IO;
- using HtmlAgilityPack;
- public static void Main(string[] args)
- {
- // 下载Yahoo 奇摩股市资料(范例为2317 鸿海)
- WebClient client = new WebClient();
- MemoryStream ms = new MemoryStream(client.DownloadData(
- "http://tw.stock.yahoo.com/q/q?s=2317"));
- // 使用预设编码读入 HTML
- HtmlDocument doc = new HtmlDocument();
- doc.Load(ms, Encoding.Default);
- // 装载第一层查询结果
- HtmlDocument docStockContext = new HtmlDocument();
- docStockContext.LoadHtml(doc.DocumentNode.SelectSingleNode(
- "/html[1]/body[1]/center[1]/table[2]/tr[1]/td[1]/table[1]").InnerHtml);
- // 取得个股标头
- HtmlNodeCollection nodeHeaders =
- docStockContext.DocumentNode.SelectNodes("./tr[1]/th");
- // 取得个股数值
- string[] values = docStockContext.DocumentNode.SelectSingleNode(
- "./tr[2]").InnerText.Trim().Split('\n');
- int i = 0;
- // 输出资料
- foreach (HtmlNode nodeHeader in nodeHeaders)
- {
- Console.WriteLine("Header: {0}, Value: {1}",
- nodeHeader.InnerText, values[i].Trim());
- i++;
- }
- doc = null;
- docStockContext = null;
- client = null;
- ms.Close();
- Console.WriteLine("Completed.");
- Console.ReadLine();
- }
读取Yahoo 奇摩个股资料的程式码(专案类型:主控台应用程式)
目前HTML Agility Pack 预设编码应是法文编码,所以如果是读取中文HTML 内容的话,无法直接使用HtmlDocument.LoadHtml() 方法,而要透过MemoryStream 使用HtmlDocument.Load() 方法,才可以指定中文的编码。
此范例的结果输出为:
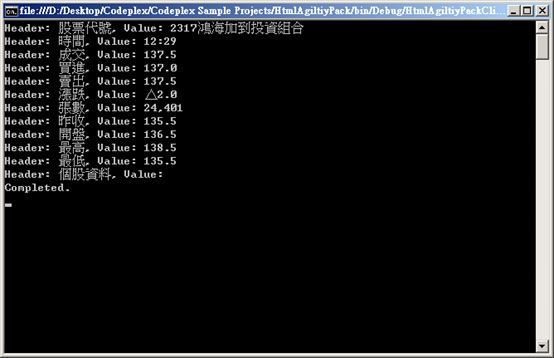
有了这个读取程式后,笔者认为可以做的事就很多了,像是将它以XSLT 转换成不同的HTML 来显示,或是存到资料库中做其他的工作(分析或是图表输出等都可以做到)。
由上列程式可以看出,HTML Agility Pack 的使用其实就和XML DOM 的使用差不了多少,而且也不用再去写不具亲和力的Regular Expression 的指令,就可以轻松的使用XPath 来解析HTML,就算是松散的HTML 也可以解析。
虽然HTML Agility Pack 可以解析成功松散的HTML 文件内容,但是请注意,松散的HTML 内容可能会造成HtmlNode 不是预期的结果,或是在解析表格时,档头和内容不同步的现象,这个部份开发人员可能需要多加注意。
HTML Agility Pack 也可以用来动态产生HTML 的内容,就如同XmlDocument 产生XML 文件内容一样,它也有像是CreateElement()、CreateAttribute()、CreateComments() 与CreateTextNode() 等方法,其使用方式与XmlDocument 不多,因此笔者在此就不赘述,请参考: http://msdn.microsoft.com/zh-tw/library/t058x2df.aspx
本范例程式仅以Yahoo 奇摩作为范例标的,实际上若要应用时请注意其内容授权合约与免责条款,笔者仅以此范例展示HTML Agility Pack 的功能,并不代表使用此范例即等同获得Yahoo 奇摩的内容授权,若要引用则请注意是否有合法的内容授权,如因引用范例程式而导致侵权问题,一切责任由引用者自负。
辅助工具
HTML Agility Pack 本身有提供一个HAP Explorer 的工具,可以让开发人员可以很快的得知要使用的XPath 语法,以利开发人员利用它来解析HTML 的位置资讯。
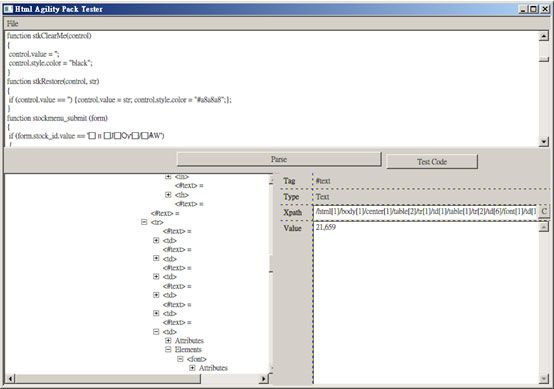
不过笔者认为这套工具太过于阳春(也许Simon Mourier 对Windows Forms 或WPF 不熟),因此笔者建议配合像FireFox 或是IE8 所提供的开发者工具(Developer Tools)来自行建构XPath 会比较适合,而且它们也都提供可以圈选网页的某一个部份并标示其HTML 位置的能力,这样要建构XPath 也会比较快。