Java爬虫,信息抓取的实现
java思想很简单:就是通过Java访问的链接,然后拿到html字符串,然后就是解析链接等需要的数据。
技术上使用Jsoup方便页面的解析,当然Jsoup很方便,也很简单,一行代码就能知道怎么用了:
1 Document doc = Jsoup.connect("http://www.oschina.net/") 2 .data("query", "Java") // 请求参数 3 .userAgent("I ’ m jsoup") // 设置 User-Agent 4 .cookie("auth", "token") // 设置 cookie 5 .timeout(3000) // 设置连接超时时间 6 .post(); // 使用 POST 方法访问 URL
下面介绍整个实现过程:
1、分析需要解析的页面:
网址:http://www1.sxcredit.gov.cn/public/infocomquery.do?method=publicIndexQuery
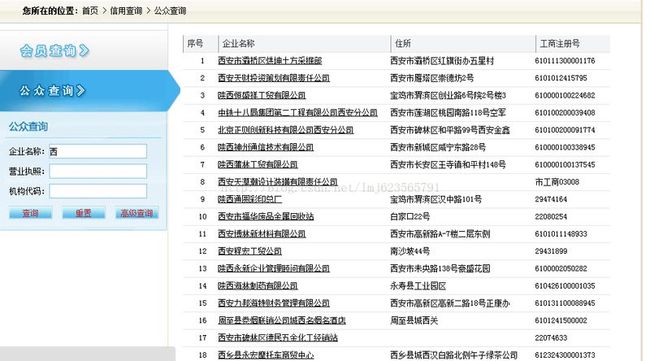
先在这个页面上做一次查询:观察下请求的url,参数,method等。
这里我们使用chrome内置的开发者工具(快捷键F12),下面是查询的结果:
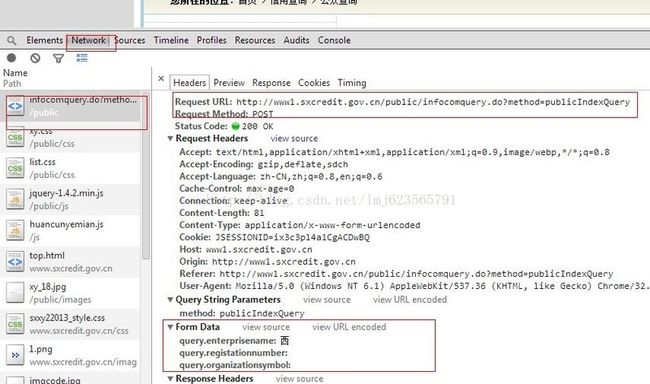
我们可以看到url,method,以及参数。知道了如何或者查询的URL,下面就开始代码了,为了重用与扩展,我定义了几个类:
1、Rule.java用于指定查询url,method,params等
1 package com.zhy.spider.rule; 2 3 /** 4 * 规则类 5 * 6 * @author zhy 7 * 8 */ 9 public class Rule 10 { 11 /** 12 * 链接 13 */ 14 private String url; 15 16 /** 17 * 参数集合 18 */ 19 private String[] params; 20 /** 21 * 参数对应的值 22 */ 23 private String[] values; 24 25 /** 26 * 对返回的HTML,第一次过滤所用的标签,请先设置type 27 */ 28 private String resultTagName; 29 30 /** 31 * CLASS / ID / SELECTION 32 * 设置resultTagName的类型,默认为ID 33 */ 34 private int type = ID ; 35 36 /** 37 *GET / POST 38 * 请求的类型,默认GET 39 */ 40 private int requestMoethod = GET ; 41 42 public final static int GET = 0 ; 43 public final static int POST = 1 ; 44 45 46 public final static int CLASS = 0; 47 public final static int ID = 1; 48 public final static int SELECTION = 2; 49 50 public Rule() 51 { 52 } 53 54 55 public Rule(String url, String[] params, String[] values, 56 String resultTagName, int type, int requestMoethod) 57 { 58 super(); 59 this.url = url; 60 this.params = params; 61 this.values = values; 62 this.resultTagName = resultTagName; 63 this.type = type; 64 this.requestMoethod = requestMoethod; 65 } 66 67 public String getUrl() 68 { 69 return url; 70 } 71 72 public void setUrl(String url) 73 { 74 this.url = url; 75 } 76 77 public String[] getParams() 78 { 79 return params; 80 } 81 82 public void setParams(String[] params) 83 { 84 this.params = params; 85 } 86 87 public String[] getValues() 88 { 89 return values; 90 } 91 92 public void setValues(String[] values) 93 { 94 this.values = values; 95 } 96 97 public String getResultTagName() 98 { 99 return resultTagName; 100 } 101 102 public void setResultTagName(String resultTagName) 103 { 104 this.resultTagName = resultTagName; 105 } 106 107 public int getType() 108 { 109 return type; 110 } 111 112 public void setType(int type) 113 { 114 this.type = type; 115 } 116 117 public int getRequestMoethod() 118 { 119 return requestMoethod; 120 } 121 122 public void setRequestMoethod(int requestMoethod) 123 { 124 this.requestMoethod = requestMoethod; 125 } 126 127 }
简单说一下:这个规则类定义了我们查询过程中需要的所有信息,方便我们的扩展,以及代码的重用,我们不可能针对每个需要抓取的网站写一套代码。
2、需要的数据对象,目前只需要链接,LinkTypeData.java
1 package com.zhy.spider.bean; 2 3 public class LinkTypeData 4 { 5 private int id; 6 /** 7 * 链接的地址 8 */ 9 private String linkHref; 10 /** 11 * 链接的标题 12 */ 13 private String linkText; 14 /** 15 * 摘要 16 */ 17 private String summary; 18 /** 19 * 内容 20 */ 21 private String content; 22 public int getId() 23 { 24 return id; 25 } 26 public void setId(int id) 27 { 28 this.id = id; 29 } 30 public String getLinkHref() 31 { 32 return linkHref; 33 } 34 public void setLinkHref(String linkHref) 35 { 36 this.linkHref = linkHref; 37 } 38 public String getLinkText() 39 { 40 return linkText; 41 } 42 public void setLinkText(String linkText) 43 { 44 this.linkText = linkText; 45 } 46 public String getSummary() 47 { 48 return summary; 49 } 50 public void setSummary(String summary) 51 { 52 this.summary = summary; 53 } 54 public String getContent() 55 { 56 return content; 57 } 58 public void setContent(String content) 59 { 60 this.content = content; 61 } 62 }
3、核心的查询类:ExtractService.java
package com.zhy.spider.core; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.Map; import javax.swing.plaf.TextUI; import org.jsoup.Connection; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import com.zhy.spider.bean.LinkTypeData; import com.zhy.spider.rule.Rule; import com.zhy.spider.rule.RuleException; import com.zhy.spider.util.TextUtil; /** * * @author zhy * */ public class ExtractService { /** * @param rule * @return */ public static List<LinkTypeData> extract(Rule rule) { // 进行对rule的必要校验 validateRule(rule); List<LinkTypeData> datas = new ArrayList<LinkTypeData>(); LinkTypeData data = null; try { /** * 解析rule */ String url = rule.getUrl(); String[] params = rule.getParams(); String[] values = rule.getValues(); String resultTagName = rule.getResultTagName(); int type = rule.getType(); int requestType = rule.getRequestMoethod(); Connection conn = Jsoup.connect(url); // 设置查询参数 if (params != null) { for (int i = 0; i < params.length; i++) { conn.data(params[i], values[i]); } } // 设置请求类型 Document doc = null; switch (requestType) { case Rule.GET: doc = conn.timeout(100000).get(); break; case Rule.POST: doc = conn.timeout(100000).post(); break; } //处理返回数据 Elements results = new Elements(); switch (type) { case Rule.CLASS: results = doc.getElementsByClass(resultTagName); break; case Rule.ID: Element result = doc.getElementById(resultTagName); results.add(result); break; case Rule.SELECTION: results = doc.select(resultTagName); break; default: //当resultTagName为空时默认去body标签 if (TextUtil.isEmpty(resultTagName)) { results = doc.getElementsByTag("body"); } } for (Element result : results) { Elements links = result.getElementsByTag("a"); for (Element link : links) { //必要的筛选 String linkHref = link.attr("href"); String linkText = link.text(); data = new LinkTypeData(); data.setLinkHref(linkHref); data.setLinkText(linkText); datas.add(data); } } } catch (IOException e) { e.printStackTrace(); } return datas; } /** * 对传入的参数进行必要的校验 */ private static void validateRule(Rule rule) { String url = rule.getUrl(); if (TextUtil.isEmpty(url)) { throw new RuleException("url不能为空!"); } if (!url.startsWith("http://")) { throw new RuleException("url的格式不正确!"); } if (rule.getParams() != null && rule.getValues() != null) { if (rule.getParams().length != rule.getValues().length) { throw new RuleException("参数的键值对个数不匹配!"); } } } }
4、里面用了一个异常类:RuleException.java
package com.zhy.spider.rule; public class RuleException extends RuntimeException { public RuleException() { super(); // TODO Auto-generated constructor stub } public RuleException(String message, Throwable cause) { super(message, cause); // TODO Auto-generated constructor stub } public RuleException(String message) { super(message); // TODO Auto-generated constructor stub } public RuleException(Throwable cause) { super(cause); // TODO Auto-generated constructor stub } }
5、最后是测试了:这里使用了两个网站进行测试,采用了不同的规则,具体看代码吧
1 package com.zhy.spider.test; 2 3 import java.util.List; 4 5 import com.zhy.spider.bean.LinkTypeData; 6 import com.zhy.spider.core.ExtractService; 7 import com.zhy.spider.rule.Rule; 8 9 public class Test 10 { 11 @org.junit.Test 12 public void getDatasByClass() 13 { 14 Rule rule = new Rule( 15 "http://www1.sxcredit.gov.cn/public/infocomquery.do?method=publicIndexQuery", 16 new String[] { "query.enterprisename","query.registationnumber" }, new String[] { "兴网","" }, 17 "cont_right", Rule.CLASS, Rule.POST); 18 List<LinkTypeData> extracts = ExtractService.extract(rule); 19 printf(extracts); 20 } 21 22 @org.junit.Test 23 public void getDatasByCssQuery() 24 { 25 Rule rule = new Rule("http://www.11315.com/search", 26 new String[] { "name" }, new String[] { "兴网" }, 27 "div.g-mn div.con-model", Rule.SELECTION, Rule.GET); 28 List<LinkTypeData> extracts = ExtractService.extract(rule); 29 printf(extracts); 30 } 31 32 public void printf(List<LinkTypeData> datas) 33 { 34 for (LinkTypeData data : datas) 35 { 36 System.out.println(data.getLinkText()); 37 System.out.println(data.getLinkHref()); 38 System.out.println("***********************************"); 39 } 40 41 } 42 }
输出结果:
1 深圳市网兴科技有限公司 2 http://14603257.11315.com 3 *********************************** 4 荆州市兴网公路物资有限公司 5 http://05155980.11315.com 6 *********************************** 7 西安市全兴网吧 8 # 9 *********************************** 10 子长县新兴网城 11 # 12 *********************************** 13 陕西同兴网络信息有限责任公司第三分公司 14 # 15 *********************************** 16 西安高兴网络科技有限公司 17 # 18 *********************************** 19 陕西同兴网络信息有限责任公司西安分公司 20 # 21 ***********************************
最后使用一个Baidu新闻来测试我们的代码:说明我们的代码是通用的。
1 /** 2 * 使用百度新闻,只设置url和关键字与返回类型 3 */ 4 @org.junit.Test 5 public void getDatasByCssQueryUserBaidu() 6 { 7 Rule rule = new Rule("http://news.baidu.com/ns", 8 new String[] { "word" }, new String[] { "支付宝" }, 9 null, -1, Rule.GET); 10 List<LinkTypeData> extracts = ExtractService.extract(rule); 11 printf(extracts); 12 }
我们只设置了链接、关键字、和请求类型,不设置具体的筛选条件。
结果:有一定的垃圾数据是肯定的,但是需要的数据肯定也抓取出来了。我们可以设置Rule.SECTION,以及筛选条件进一步的限制。
1 按时间排序 2 /ns?word=支付宝&ie=utf-8&bs=支付宝&sr=0&cl=2&rn=20&tn=news&ct=0&clk=sortbytime 3 *********************************** 4 x 5 javascript:void(0) 6 *********************************** 7 支付宝将联合多方共建安全基金 首批投入4000万 8 http://finance.ifeng.com/a/20140409/12081871_0.shtml 9 *********************************** 10 7条相同新闻 11 /ns?word=%E6%94%AF%E4%BB%98%E5%AE%9D+cont:2465146414%7C697779368%7C3832159921&same=7&cl=1&tn=news&rn=30&fm=sd 12 *********************************** 13 百度快照 14 http://cache.baidu.com/c?m=9d78d513d9d437ab4f9e91697d1cc0161d4381132ba7d3020cd0870fd33a541b0120a1ac26510d19879e20345dfe1e4bea876d26605f75a09bbfd91782a6c1352f8a2432721a844a0fd019adc1452fc423875d9dad0ee7cdb168d5f18c&p=c96ec64ad48b2def49bd9b780b64&newp=c4769a4790934ea95ea28e281c4092695912c10e3dd796&user=baidu&fm=sc&query=%D6%A7%B8%B6%B1%A6&qid=a400f3660007a6c5&p1=1 15 *********************************** 16 OpenSSL漏洞涉及众多网站 支付宝称暂无数据泄露 17 http://tech.ifeng.com/internet/detail_2014_04/09/35590390_0.shtml 18 *********************************** 19 26条相同新闻 20 /ns?word=%E6%94%AF%E4%BB%98%E5%AE%9D+cont:3869124100&same=26&cl=1&tn=news&rn=30&fm=sd 21 *********************************** 22 百度快照 23 http://cache.baidu.com/c?m=9f65cb4a8c8507ed4fece7631050803743438014678387492ac3933fc239045c1c3aa5ec677e4742ce932b2152f4174bed843670340537b0efca8e57dfb08f29288f2c367117845615a71bb8cb31649b66cf04fdea44a7ecff25e5aac5a0da4323c044757e97f1fb4d7017dd1cf4&p=8b2a970d95df11a05aa4c32013&newp=9e39c64ad4dd50fa40bd9b7c5253d8304503c52251d5ce042acc&user=baidu&fm=sc&query=%D6%A7%B8%B6%B1%A6&qid=a400f3660007a6c5&p1=2 24 *********************************** 25 雅虎日本6月起开始支持支付宝付款 26 http://www.techweb.com.cn/ucweb/news/id/2025843 27 ***********************************