Matalab之模糊KMeans原理
对Kmeans方法相信大家都会不陌生,这是一种广泛被应用的基于划分的聚类算法。首先对它的核心思想做一个简单的介绍:
算法把n个向量xj(1,2…,n)分为c个组Gi(i=1,2,…,c),并求每组的聚类中心,使得非相似性(或距离)指标的价值函数(或目标函数)达到最小。当选择欧几里德距离为组j中向量xk与相应聚类中心ci间的非相似性指标时,价值函数可定义为:
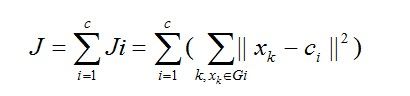 (1.1)
(1.1)
这里Ji是组i内的价值函数。这样Ji的值依赖于Gi的几何特性和ci的位置。一般来说,可用一个通用距离函数d(xk,ci)代替组I中的向量xk,则相应的总价值函数可表示为:
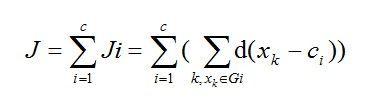 (1.2)
(1.2)
划分过的组一般用一个c×n的二维隶属矩阵U来定义。如果第j个数据点X(j)属于组i,则U中的元素U(i,j)为1;否则,该元素取0。一旦确定聚类中心v(i),可导出如下使式(1.1)最小:
 (1.3)
(1.3)
强调一点,如果v(i)是X(j)的最近的聚类中心,那么X(j)属于i组。由于一个给定数据只能属于一个组,所以隶属矩阵U具有如下性质:
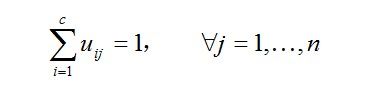 (1.4)
(1.4)
Kmeans虽然简单实用,但是对于一些实际问题在功能上还是略显逊色,同时它还有一个先天的不足,那就是它是一种硬性的划分方法。FCM算法是对硬性划分的一种改进,其核心思想如下:
FCM把n个向量xi(i=1,2,…,n)分为c个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。FCM与HCM的主要区别在于FCM用模糊划分,使得每个给定数据点用值在0,1间的隶属度来确定其属于各个组的程度。与引入模糊划分相适应,隶属矩阵U允许有取值在0,1间的元素。不过,加上归一化规定,一个数据集的隶属度的和总等于1:
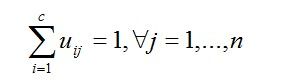 (2.1)
(2.1)
那么,FCM的价值函数(或目标函数)就是式(1.1)的一般化形式:
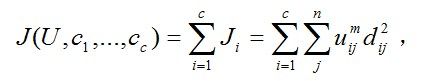 (2.2)
(2.2)
这里U(i,j)介于0,1之间;C(i)为模糊组I的聚类中心;d(i,j)是模糊组I的聚类中心到第j个数据之间的欧式距离;为了获得使得该目标函数最小值的条件,重新构造目标函数如下:
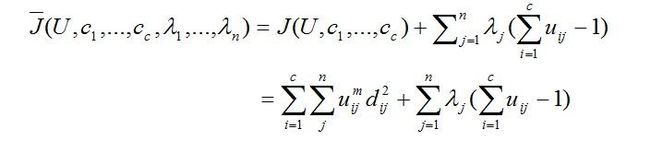 (2.3)
(2.3)
这里lj,j=1到n,是(2.1)式的n个约束式的拉格朗日乘子。对所有输入参量求导,使式(2.2)达到最小的必要条件为:
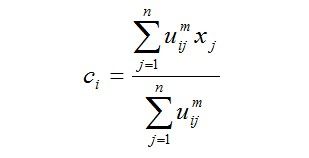 (2.4)
(2.4)
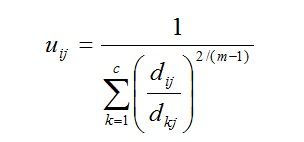 (2.5)
(2.5)
由上述两个必要条件,模糊C均值聚类算法是一个简单的迭代过程。在批处理方式运行时,FCM用下列步骤确定聚类中心ci和隶属矩阵U[1]:
步骤1:用值在0,1间的随机数初始化隶属矩阵U,使其满足式(2.1)中的约束条件
步骤2:用式(2.4)计算c个聚类中心ci,i=1,…,c。
步骤3:根据式(2.2)计算价值函数。如果它小于某个确定的阀值,或它相对上次价值函数值的改变量小于某个阀值,则算法停止。
步骤4:用(2.5)计算新的U矩阵。返回步骤2。
上述算法也可以先初始化聚类中心,然后再执行迭代过程。由于不能确保FCM收敛于一个最优解。算法的性能依赖于初始聚类中心。
关于FCM算法的介绍就到这里了,下讲将会针对一个实际例子给出实现代码