《数学之美》读书笔记——自然语言处理篇
前言

今年很早就看到网上对《数学之美》一书的评价了,很多技术高手鼎力推荐。本书的作者是曾经编写《浪潮之巅》的吴军博士。于是,在十一期间到网上买了一本。
首先,看到作者简介,发现他的研究方向是语音识别和自然语言处理,这正好是我硕士期间要研究的方向,更加坚定了我读这本书的决心。但是不得不提到的是,虽然里面很多都是关于计算机学科中用到的数学知识,但是这本书面向的读者是大众,而不仅仅是计算机从业者。这也是这本书的优点,用简单易懂的文字阐明在互联网技术中用到的数学原理。
文章总共有29章,每章的篇幅不是很多,把内容层次计较清晰。大致涉及到自然语言处理、语音识别、搜索引擎、文本分类。让读者了解了数学知识在各种技术中的应用。数学是抽象和复杂的,以至于很多学生面对时望而却步,本书让数学简单化和具体化,从现实生活中切入,为各种现象找到合适的数学模型,并解释说明。
自然语言处理
人们的语言交流可以被抽象为一种通信模型,说话者将自己要表达的信息编码成语言,在空气等信道中传输,收听者听到声音后通过自己的大脑将声音解码成自己了解的语意。
早期的自然语言处理是基于文法规则来分析的,通过构建语法分析树来确定句子中的主语、谓语、宾语等成分。但是这种方法的弊端在于语法规则的复杂性对于计算机来说很困难,而且词义的多义性依赖上下文。
基于统计的自然语言处理在今天得到广泛的运用。,其核心模型是通信系统加隐含马尔科夫模型。一个句子是否合理,取决于它的可能性大小。马尔科夫假设每个词的出现的概率和前有限个词有关,于是可能性大小可以根据字符串前后条件概率相乘求出的,也就是用马尔科夫链。至于这些词前后出现的概率是通过大量语料库中统计得出来的。但是马尔科夫假设是有局限性的,它无法解决长程依赖性。在训练之前,需要对语料进行处理,过滤一些噪声。
中文句子中没有明确的分界符,比较简单的分词方法是查字典,但是遇到有歧义的句子就比较麻烦。在统计语言模型中可以解决这问题,最好的方法就是计算各种分词方法的概率,出现的概率最大的分词方法就是正确的方法。这种方法计算量非常大,解决方法是将其看成是动态规划问题,用维特比方法找到最佳分词。
隐含的马尔科夫模型:语音识别中,是通过接收到的观测值来推测原来的信息,实际上是一个计算后验概率最大时,输入序列参数的问题,这个问题就用HMM(隐含的马尔科夫模型)来估计。HMM是马尔科夫链的的一个扩展,任意时刻的状态是不可见的,但是会相应地产生一个观测值。HMM模型有三个基本问题:
- 给定一个模型,如何计算出某个特定输出序列的概率。
- 给定一个模型和某个特定的输出序列,如何找到最有可能产生这个输出的状态序列。
- 给定足够的观测数据,如何估计马尔科夫模型的参数。
第一个问题对应的算法是前向-后向算法,第二个问题可以用维特比算法解决。第三个问题就是模型训练问题,常用的有鲍姆-韦尔奇算法(Baum-Welch)。
关于信息的度量:信息量代表不确定性的大小,信息论的创始人香农指出,信息量的公式为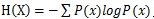 ,这被称为信息熵,当每个P(x)相同时,熵最大。当引入另一个变量Y时,我们可以计算出Y条件下X的条件熵,即
,这被称为信息熵,当每个P(x)相同时,熵最大。当引入另一个变量Y时,我们可以计算出Y条件下X的条件熵,即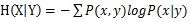 ,进一步来说,三个变量时,
,进一步来说,三个变量时, ,
, 。信息的作用在于消除不确定性,自然语言处理、信息与信号处理的应用就是一个消除不确定性的过程。
。信息的作用在于消除不确定性,自然语言处理、信息与信号处理的应用就是一个消除不确定性的过程。
个人博客地址:http://gujianbo.1kapp.com/
新浪微博:http://weibo.com/gujianbobo
欢迎读者交流讨论并提出宝贵意见。