MVC&WebForm对照学习:文件下载
说完了WebForm和MVC中的文件上传,就不得不说用户从服务器端下载资源了。那么今天就扯扯在WebForm和MVC中是如何实现文件下载的。说起WebForm中的文件上传,codeshark在他的博文ASP.NET实现文件下载中讲到了ASP.NET中文件下载的4种方式。当然文章主要指的是在WebForm中的实现方式。总结得相当到位,那么这篇,就先来看看MVC中文件下载的方式。然后再回过头来看看它们实现方式的关联。
Part 1 MVC中的文件下载
在mvc中微软封装好了ActionResult的诸多的实现,这使我们根据需要灵活地选择操作结果来响应用户的操作。这其中一个很重要的实现就是.NET Framework 4.0中的FileResult。它 表示一个用于将二进制文件内容发送到响应的基类。FileResult类有三个实现:FileContentResult、FileStreamResult、FilePathResult。mvc中的文件下载就是依赖这三个子类。不扯闲,先来看具体实现。
![]() FileContentResult
FileContentResult
public ActionResult FileDownLoad()
{
FileStream fs = new FileStream(Server.MapPath("~/uploads/Desert.jpg"), FileMode.Open, FileAccess.Read);
byte[] bytes = new byte[fs.Length];
fs.Read(bytes, 0, Convert.ToInt32(bytes.Length));
return File(bytes, "image/jpeg", "Desert.jpg");
}
![]() FileStreamResult
FileStreamResult
public ActionResult FileDownLoad()
{
return File(new FileStream(Server.MapPath("~/uploads/Desert.jpg"), FileMode.Open, FileAccess.Read), "image/jpeg", "Desert.jpg");
}
![]() FilePathResult
FilePathResult
public ActionResult FileDownLoad()
{
return File(Server.MapPath("~/uploads/Desert.jpg"), "image/jpeg", "Desert.jpg");
看了上面的代码是不是感觉这似乎比codeshark文章中讲到的WebForm中的文件下载代码更简洁了?确实!那么我们同时也不禁要问:不是说mvc中的文件下载依赖于FileContentResult、FilePathResult、FileStreamResult吗,为什么这里边无一例外都是return File(......)呢?这个对于接触过mvc的你来说,相信难不倒你,F12一下就全明白了:
 (图1-1)
(图1-1)
原来File(......)方法的背后返回的是FileContentResult、FileStreamResult、FilePathResult的实例。这就不足为怪了。那么也就是说其实上面的3钟实现方式你完全可以改成如下形式:
//FilePathResult
return new FilePathResult(Server.MapPath("~/uploads/Desert.jpg"), "image/jpeg") { FileDownloadName = "Desert.jpg" };
//FileStreamResult
return new FileStreamResult(new FileStream(Server.MapPath("~/uploads/Desert.jpg"), FileMode.Open, FileAccess.Read), "image/jpeg") { FileDownloadName = "Desert.jpg" };
//FileContentResult
return new FileContentResult(System.IO.File.ReadAllBytes(Server.MapPath("~/uploads/Desert.jpg")), "image/jpeg") { FileDownloadName = "Desert.jpg" };
如果你通过ILSpay查看源码的话,你会发现其实对应的return File(......)的内部实现就是如此。
![]() 问题1:不给fileDownloadNane赋值效果会如何
问题1:不给fileDownloadNane赋值效果会如何
回过头来再看下图1-1,我们还会发现FileContentResult、FileStreamResult、FilePathResult的下载方法,还各自对应的存在一个没有第三个参数fileDownloadNane的方法重载。那么这个方法又是用来干嘛呢?小段代码看下便知:
public ActionResult FileDownLoad()
{
return File(Server.MapPath("~/uploads/Desert.jpg")
}
--------------------------------------------------------------------------------运行结果-------------------------------------------------------------------------------------------------------------------

通过运行结果截图一眼就能看出,此时将图片直接输出在页面上,这实现图片的显示功能。那么同时我们也能够知道,同样的这样也是可以的:
return new FilePathResult(Server.MapPath("~/uploads/Desert.jpg"), "image/jpeg") ;
![]() 问题2:加不加fileDownloadNane背后到底做了什么
问题2:加不加fileDownloadNane背后到底做了什么
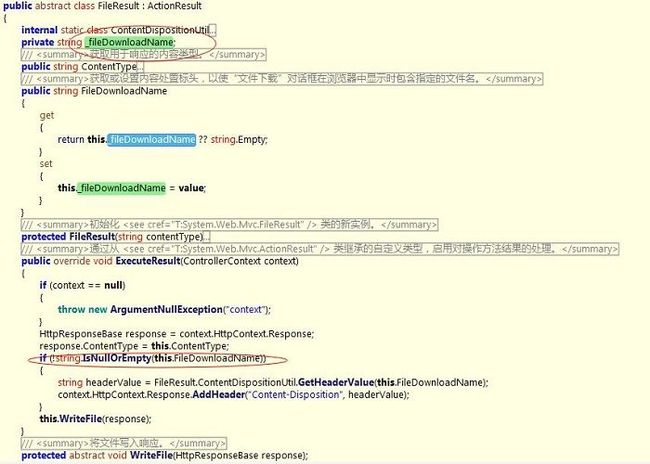
当然其它两种方式同样如此。那么我们不禁要问:为什么给不给fileDownloadName赋值,实现的效果完全不一样呢?那么你肯定想到了在内部肯定做了什么来加以区分。那么就以FilePathResult为例,用ILSpy来看看究竟:
 (图1-2)
(图1-2)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
 (图1-3)
(图1-3)
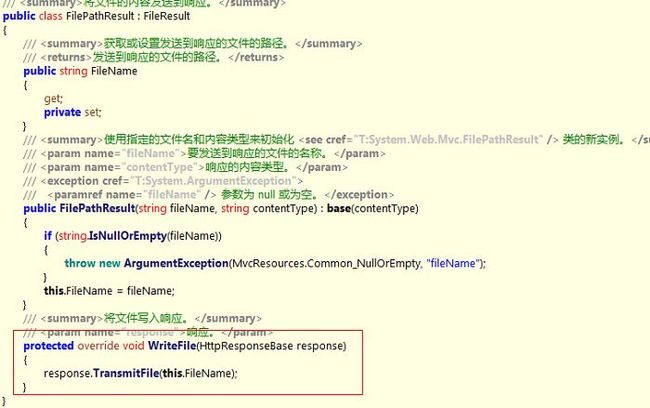
先看图1-2在FileResult类中有一个FileDownloadName公开属性,我们知道ActionResult类最终要执行子类的ExecuteResult方法,而在FileResult的ExecuteResult方法中,对FileDownloadName进行了非空判断。如果不为空则通过Response.AddHeader()方法向客户端浏览器发送文件。如果为空则调用子类FilePathResult的重写方法WriteFile() (图1-3所示)直接向页面输出响应流。当然FileContentResult、FileStreamResult道理相同。
![]() 问题3:FileContentResult、FileStreamResult、FilePathResult文件下载的方式到底有什么不同
问题3:FileContentResult、FileStreamResult、FilePathResult文件下载的方式到底有什么不同
嗯,要回答这个问题,不用说,还是得看看它的内部实现。那么我们就一个个地来看看究竟。
图1-2和图1-3种已经看得很清楚,最终文件下载时指定了FileResult的ExecuteResult方法,而在ExecuteResult方法中调用了FileResult的子类的WriteFile方法。那么我只需要查看每个子类的WriteFile方法便知道了。
FileContentResult

FileStreamResult
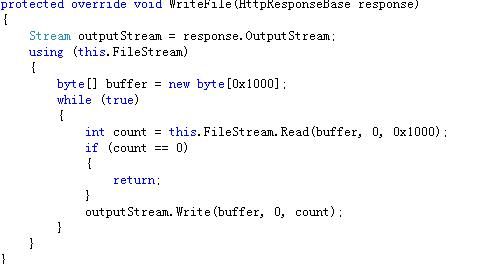
FilePathResult

再去看看codeshark的文章ASP.NET实现文件下载,在这篇文章中他总结了文件下载的4种方式:
方式一:TransmitFile实现下载。将指定的文件直接写入 HTTP 响应输出流,而不在内存中缓冲该文件。
方式二:WriteFile实现下载,将指定的文件直接写入 HTTP 响应输出流。注意:对大型文件使用此方法时,调用此方法可能导致异常。可以使用此方法的文件大小取决于 Web 服务器的硬件配置。
方式三:WriteFile分块下载
方式四:Response.BinaryWrite()流方式下载
那么与mvc中文件下载对照一下,不难发现,FilePathResult实际上是采用的Response.TransmitFile的方式实现下载的;而FileStreamResult是采用的WriteFile分块下载;FileContentResult在文章中没有直接的对照方式,而它采用的是Response.OutputStream.Write的方式。另外Response.BinaryWrite()流的方式在mvc中没有实现。当然在msdn上给出了实现我直接贴出实现代码:
实现代码:
public class BinaryContentResult : ActionResult
{
public BinaryContentResult()
{
}
// Properties for encapsulating http headers.
public string ContentType { get; set; }
public string FileName { get; set; }
public byte[] Content { get; set; }
// The code sets the http headers and outputs the file content.
public override void ExecuteResult(ControllerContext context)
{
context.HttpContext.Response.ClearContent();
context.HttpContext.Response.ContentType = ContentType;
context.HttpContext.Response.AddHeader("content-disposition",
"attachment; filename=" + FileName);
context.HttpContext.Response.BinaryWrite(Content);
context.HttpContext.Response.End();
}
}
调用代码:
public ActionResult Download(string fn)
{
// Check whether the requested file is valid.
string pfn = Server.MapPath("~/App_Data/download/" + fn);
if (!System.IO.File.Exists(pfn))
{
throw new ArgumentException("Invalid file name or file not exists!");
}
// Use BinaryContentResult to encapsulate the file content and return it.
return new BinaryContentResult()
{
FileName = fn,
ContentType = "application/octet-stream",
Content = System.IO.File.ReadAllBytes(pfn)
};
}
![]() 问题4:那么FileContentResult的Response.OutputStream.Write()和Response.WriteFile()又有什么区别昵
问题4:那么FileContentResult的Response.OutputStream.Write()和Response.WriteFile()又有什么区别昵
关于这个问题,我查了很久,没有得到比较满翼的答案,在这里希望大神指点一二!
Part 2 WebForm中的文件下载
看看这篇文章ASP.NET实现文件下载一目了然。四种方式不多说了。到这里,不得不说MVC中的文件下载is so easy!这还得归功于微软的封装。那么问题来了,在WebForm中我们是不是因该也封装一个这样的实现,这样在以后使用的时候不用写(当然一般是copy)重复写这么写这些容易忘记的代码了昵? Of course, just do it! 网上我没有找到一个针对这个实现的封装(有大神代码可以贡献一下)。我索性自己写一个,好不好,就不说了。
1.定义抽象类
先定义一个抽象列FileDownloader,定义公共的下载行为WriteFile方法和执执行下载的Execute方法以及文件下载名_fileDownloadName。代码如下:
public abstract class FileDownloader
{
private string _fileDownloadName;
public FileDownloader(string contentType)
{
if (string.IsNullOrEmpty(contentType))
{
throw new ArgumentException("contentType");
}
this.ContentType = contentType;
}
public void Execute(HttpContext context)
{
if (context == null)
{
throw new ArgumentNullException("context");
}
HttpResponse response = context.Response;
response.ClearContent();
response.ContentType = this.ContentType;
if (!string.IsNullOrEmpty(this.FileDownloadName))
{
context.Response.AddHeader("content-disposition",
"attachment; filename=" + this.FileDownloadName);
}
this.WriteFile(context.Response);
response.Flush();
response.End();
}
protected abstract void WriteFile(HttpResponse response);
public string ContentType { get; private set; }
public string FileDownloadName
{
get
{
return (this._fileDownloadName ?? string.Empty);
}
set
{
this._fileDownloadName = value;
}
}
}
2.创建实现类
此处模拟MVC中的实现方式创建对应的WebForm中的实现方式,为了易于区分说明,我采取和MVC中同样的类名。
MVC中FileContentResult的下载方式(区别于FileStreamResult分区下载),这里实现一下:
public class FileContentResult : FileDownloader
{
public FileContentResult(byte[] fileContents, string contentType)
: base(contentType)
{
if (fileContents == null)
{
throw new ArgumentNullException("fileContents");
}
this.FileContents = fileContents;
}
public byte[] FileContents { get; private set; }
protected override void WriteFile(HttpResponse response)
{
response.OutputStream.Write(this.FileContents, 0, this.FileContents.Length);
}
}
FileStreamResult(分区下载):
public class FileStreamResult : FileDownloader
{
public FileStreamResult(Stream fileStream, string contentType)
: base(contentType)
{
if (fileStream == null)
{
throw new ArgumentNullException("fileStream");
}
this.FileStream = fileStream;
}
public Stream FileStream { get; private set; }
protected override void WriteFile(HttpResponse response)
{
Stream outputStream = response.OutputStream;
using (this.FileStream)
{
byte[] buffer = new byte[4096];
while (true)
{
int num = this.FileStream.Read(buffer, 0, 4096);
if (num == 0)
{
break;
}
outputStream.Write(buffer, 0, num);
}
}
}
}
FIlePathResult:
public class FIlePathResult : FileDownloader
{
public FIlePathResult(string fileName, string contentType)
: base(contentType)
{
if (string.IsNullOrEmpty(fileName))
{
throw new ArgumentNullException("fileName");
}
this.FileName = fileName;
}
public string FileName { get; private set; }
protected override void WriteFile(HttpResponse response)
{
response.TransmitFile(this.FileName);
}
}
另外上面我们也采用了微软上BinaryContentResult的实现,这里同样也实现一下BinaryContentResult:
public class BinaryContentResult : FileDownloader
{
public BinaryContentResult(byte[] fileContents, string contentType)
: base(contentType)
{
if (fileContents == null)
{
throw new ArgumentNullException("fileContents");
}
this.FileContents = fileContents;
}
protected override void WriteFile(HttpResponse response)
{
response.BinaryWrite(FileContents);
}
public byte[] FileContents { get; private set; }
}
另外还有HttpResponse.WriteFile(net 2.0中的提出的,对大型文件使用此方法时,调用此方法可能会引发异常这里姑且称之为旧的实现方式:
public class FilePathOldResult : FileDownloader
{
public FilePathOldResult(string fileName, string contentType)
: base(contentType)
{
if (string.IsNullOrEmpty(fileName))
{
throw new ArgumentNullException("fileName");
}
this.FileName = fileName;
}
public string FileName { get; private set; }
protected override void WriteFile(HttpResponse response)
{
response.WriteFile(this.FileName);
}
Part 3 问题开发
在文件下载中,我们可能需要自动获取文件的MIME类型,这在指定文件的下载类型时。那么如何获取文件的MIME类型呢?在Mitchell Chu的博客.NET获取文件的MIME类型(Content Type)中给出了比较好的答案。这里就不做赘述。
Part 4 The end
回过头来看还是那句话,因为MVC和WebForm都是基于ASP.NET框架,因此文件下载功能的背后还是采用了相同的组件实现。
注:由于个人技术有限,对某些概念的理解可能会存在偏差,如果你发现本文存在什么bug,请指正。谢谢!
完。