方法实时Voxel Cone Tracing based Global Illumination
废话就不多说了,开始。。。
之前很早就看到了UE4中的基于Sparse Voxel Octree的RTGI,效果很酷,始终尝试作些研讨与实现,但苦于没机会。前段无暇,抽时间学习了一下,这里小结一下备忘。
整个算法重要分类几个进程:体素化、Mipmap OCTree、Cone Tracing。
1. Voxelization
体素化整个GI算法的基本。这里体素化可以采取的方法也比较多,重要有以下几种:
- 直接将体素与场景停止碰撞检测。该方法比较原始,效率也较低,虽然也可以借助于GPU停止加速,但是在该特定场所中使用起来还是诸多不便;
- 基于CUDA停止体素操纵,这也是使用GPU停止加速的一种方法。比如这里的一个使用CUDA停止光栅化方法,稍作修改就可以同样用来实现体素化;
- 基于GPU Rasterization的方法,使用这类方法的利益就是不需要特殊的Pipeline,很容易将它往现有的游戏或渲染引擎中停止整合;
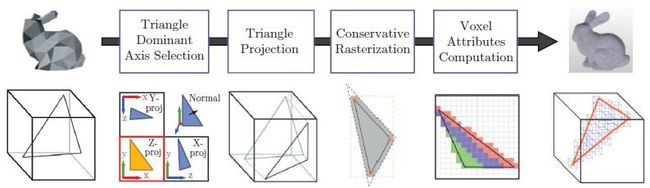
- 使用与体素化细分分辨率相同的正交投影窗口来渲染三维网格中的每一个三角形;
- 对于每一个三角形计算出一个投影面积最大的投影矩阵,然在在此位置上做光栅化,这样使得光栅化效率最大化;光栅化出的每一个像素对应一个该方向上的体素;
- 在光栅化出的每一个像素中执行Shader,利用OGL imageStore或DX11的RWTexture3D方法将像素对应的体素信息写入到3D Texture中;
- 对六个投影轴方向分离停止上述操纵之后失失落6张3D Texture;之后对其停止合并失失落最终的3D Texture,其中就包含了整个场景的完整体素化结果。

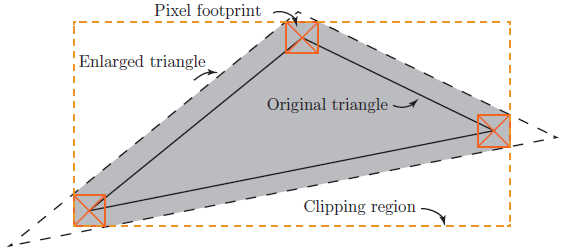

- 最简略的一个方法是直接对于每一集体素生成一个6个面的Cube,然后再绘制,但是这样发生的冗余面就太多了,绘制效率极低;
- 另外一个方法是表面生成(Surface Extraction):其实体素绘制时的有效表面只会发生在相邻两集体素的状态是由非空 变换为 空 的位置上。基于些,对于场景中的体素停止遍历,通过每一集体素及其相邻体素之间的状态切换关系,判断相关位置上是否有体素表面,如果有的话就将其添加表面列表中以待绘制。这可以使体素内部的表面都被省略。不过对于256x256x256的体素分辨率来讲,在上述场景中停止表面生成后也失失落了多达658240集体素表面,数量仍然不小。
2. Mipmap based OCTree
3. Cone Tracing
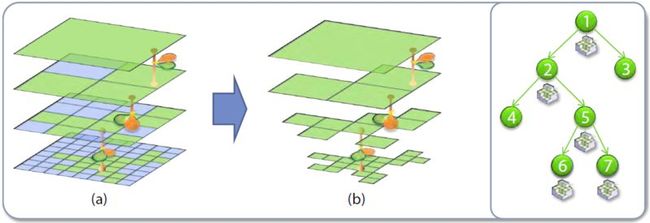
有了场景的基本OCTree结构之后,接下来就到Cone Tracing了,这个是整个方法的核心,其重要是使用多层次的空间近似来下降传统Irridiance计算的庞杂度进而使得实时的倏地计算变得可行。先来看个图示意一下:
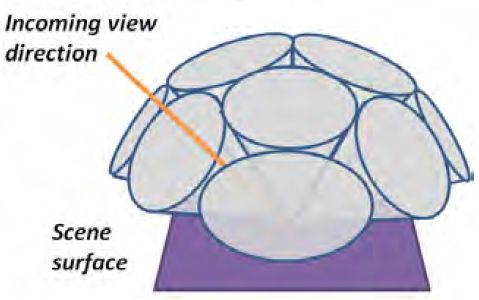
首先,在每一个表面的每一个点上,将传统做GI计算时的半球积分空间给分割成多个独立的Cones,用这些Cones组合失失落的空间(旁边会有重叠或裂隙)来近似原始的半球空间,并在其上做Irridiance的采积。
之后,对于每一个独立的Cone,又使用下述方法再停止近似:
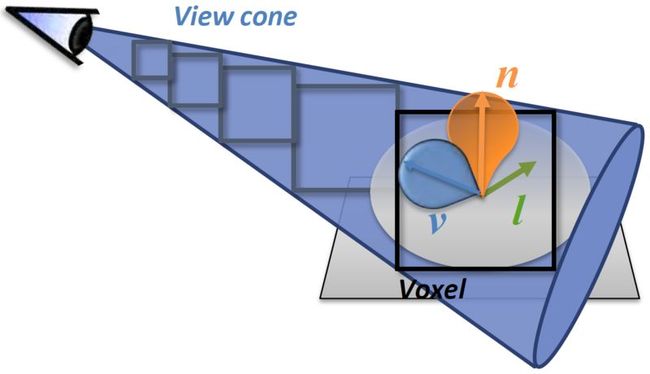
也等于在每一个Cone的内部又将其用多个密布排列的Cube来停止近似,使用Cube的方法是其会使得OCTree的Tracing变得很方便。 每一个Cube巨细的计算就可以根据详细Cone的属性(比如夹角,最大长度等)来停止计算,一般来讲从每一个Cone内部分割出来的Cube个数不会太多.
对于每一个Cube在OCTree中的Tracing,使用的方法也比较简略:直接计算出的Cube的Size,然后根据此Size找出与其最适配的那层Mipmap,这里的原则就是Cube的Size要尽可能地与Mipmap层中的结点Size接近。最后,直接使用此Cube的位置信息来采样Mipmap中的相应位置上的结点值,即可完成对此Cube的Tracing。
对Cone中的每一个Cube完成Tracing之后,以后Cone方向上的Irridiance积累结果就可以认为是Cone中全部Cube采样结果的叠加。这个看起来虽然有些不太公道,但是视觉效果上的近似已很不错了。此外,作者也对该近似方法停止了数学上的分析(step by step pre-integration):将每一个Cube认为是Transparent属性,然后Irridiance会在其中停止不断的传递。详细可以见这论文里边的详细内容。
下面有个简略的试验效果图,Tracing效果还是挺不错的。

整体来讲,基于SVO Cone Tracing的GI是一种蛮好的方法,其算法本身跟CE中的LPV很相似,但增加了对场景的体素化加速结构的实时生成,并且在效率与效果中达到了较为不错的平衡,与现有引擎的集成难度应当不是太大,未来应当还是有很好的发展趋势。
后记. Pure run-time methods VS Hybrid methods
写到了GI,这里顺便也对自己之前所了解的GI情况作一简略总结。目前,主流游戏引擎中对实时GI的支持逐步变得普遍,整体来看,重要使用的实时GI算法应当大体分为这两类:
- 纯实时方法:这类方法的特点是全部GI相关的计算都是在实时更新时完成(这里重要是指核心的计算),其面临的最大挑战是效率与效果的兼顾。该类方法中比较典型的有:Reflective Shadow map(以及各种改进版本)、Light Propgation Volume(CE中使用的方法),SVO GI(UE4中使用的方法);
- 预处理&实时结合方法:这类方法的特点是将实时计算与场景预处理停止结合,在预处理阶段中生成一些额定的信息来加速实时GI更新时的计算,这样的话可以将部分实时更新计算提早,进而减少动态更新部分的压力。该类方法中比较典型的重要是:Enlighten(Frostbite中使用的方法);
- 效果和效率:Hybrid类的方法在GI的效率和质量上都更胜一筹(Enlighten的效果与效率比SVO与LPV都要好),毕竟其将一些庞杂的计算都移动到了预处理阶段,然后在实时更新中直接使用就可以。
- 易用性:这个重要是从制造人员角度斟酌,Hybrid方法需要后期美术资源制造时的付出一些人力本钱用来协助预处理进程,该部分的任务量也会视情况而变;而纯实时的就不需要该部分任务。
- 使用价值:效果较好的Enlighten意味着不菲的使用授权;而上述纯实时的GI算规律都是收费使用(当然,开辟集成也需要少许本钱)。
其实,RTGI对于一款游戏或引擎的意义也要视情况而定,对某些引擎或项目而言这些东西可能毫无意义;但对其它的来讲,这些可能就是浩繁亮点之一,需要辩证地对待吧。
References
文章结束给大家分享下程序员的一些笑话语录: 开发时间
项目经理: 如果我再给你一个人,那可以什么时候可以完工?程序员: 3个月吧!项目经理: 那给两个呢?程序员: 1个月吧!
项目经理: 那100呢?程序员: 1年吧!
项目经理: 那10000呢?程序员: 那我将永远无法完成任务.
--------------------------------- 原创文章 By 方法和实时 ---------------------------------